Navicat中导入mysql大数据时出错解决方法
Navicat 自己到处的数据,导入时出现无法导入的情况。
最后选择利用MySQL命令导入方式完成数据导入
用到命令
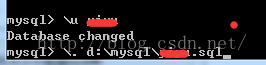
use 快捷方式 \u
source 快捷方式 \.
快捷方式可以通过help查询
mysql>\u dataname mysql>\. d:\mysql\dataname.sql
导入时碰到问题及解决方法
导入时中文乱码
解决方法:
在用Navicat导出时用的是UTF8编码,导入时MySQL用自己默认的编码方式导入,中文产生了乱码
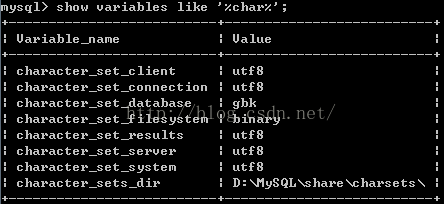
用命令查询
mysql>show variables like '%char%';
查询看到编码是gbk
然后查到的全部用
mysql>set character_set_results=utf8; mysql>set .....(类同都修改成utf8)
再次执行导入,OK!编码正常,成功导入。

相关推荐
-

Navicat中导入mysql大数据时出错解决方法
Navicat 自己到处的数据,导入时出现无法导入的情况. 最后选择利用MySQL命令导入方式完成数据导入 用到命令 use 快捷方式 \u source 快捷方式 \. 快捷方式可以通过help查询 mysql>\u dataname mysql>\. d:\mysql\dataname.sql 导入时碰到问题及解决方法 导入时中文乱码 解决方法: 在用Navicat导出时用的是UTF8编码,导入时MySQL用自己默认的编码方式导入,中文产生了乱码 用命令查询 mysql>show v
-
php 在线导入mysql大数据程序
php 在线导入 mysql 大数据程序 <?php header("content-type:text/html;charset=utf-8"); error_reporting(E_ALL); set_time_limit(0); $file='./test.sql'; $data=file($file); echo "<pre>"; //print_r($data); $data_new=array(); $tmp=array(); fore
-
MySQL 主从复制数据不一致的解决方法
目录 1. 准备工作 1.1 主机配置 1.2 从机配置 2. 数据不一致问题 3. 原因分析 4. 问题解决 5. 小结 今天来说说 MySQL 主从复制数据不一致的问题,通过几个具体的案例,来向小伙伴们展示 binlog 不同 format 之间的区别. 1. 准备工作 以下配置基于 Docker. 我这里有一张简单的图向大伙展示 MySQL 主从的工作方式: 这里,我们准备两台机器: 主机:10.3.50.27:33061 从机:10.3.50.27:33062 1.1 主机配置 主机的配
-
Navicat连接虚拟机mysql常见错误问题及解决方法
问题1 解决 启动服务:service mysqld start; /sbin/iptables -I INPUT -p tcp --dport 8011 -j ACCEPT #开启8011端口 /etc/rc.d/init.d/iptables save #保存配置 /etc/rc.d/init.d/iptables restart #重启服务 #查看端口是否已经开放 /etc/init.d/iptables status 问题2 解决 Mysql -u root -proot(root为密码
-
MySQL 大数据量快速插入方法和语句优化分享
锁定也将降低多连接测试的整体时间,尽管因为它们等候锁定最大等待时间将上升.例如: 复制代码 代码如下: Connection 1 does 1000 inserts Connections 2, 3, and 4 do 1 insert Connection 5 does 1000 inserts 如果不使用锁定,2.3和4将在1和5前完成.如果使用锁定,2.3和4将可能不在1或5前完成,但是整体时间应该快大约40%. INSERT.UPDATE和DELETE操作在MySQL中是很快的,通过为在
-
快速解决mysql导数据时,格式不对、导入慢、丢数据的问题
如果希望一劳永逸的解决慢的问题,不妨把你的mysql升级到mysql8.0吧,mysql8.0默认的字符集已经从latin1改为utf8mb4,因此现在UTF8的速度要快得多,在特定查询时速度提高了1800%! 但是如果时间等不及,就先用下面的办法快速解决一下. 问题一:格式不对(常出现时间格式不对的情况): 方法1:将excel文件另存为csv,再导入数据库: 方法2:导入的第一步时,默认编码方式是65001(UTF-8),可以尝试选择[10008 (MAC - Simplified Chin
-
Mysql大数据量查询优化思路详析
目录 1. 千万级别日志查询的优化 2. 几百万黑名单库的查询优化 3. Mybatis批量插入处理问题 项目场景: Mysql大表查询优化,理论上千万级别以下的数据量Mysql单表查询性能处理都是可以的. 问题描述: 在我们线上环境中,出现了mysql几千万级别的日志查询.几百万级别的黑名单库查询分页查询及条件查询都慢的问题,针对Mysql表优化做了一些优化处理. 原因分析:首先说一下日志查询,在Mysql中如果索引加的比较合适,走索引情况下千万级别查询不会超过一秒,Mysql查询的速度和检索
-
mysql大数据查询优化经验分享(推荐)
正儿八经mysql优化! mysql数据量少,优化没必要,数据量大,优化少不了,不优化一个查询10秒,优化得当,同样查询10毫秒. 这是多么痛的领悟! mysql优化,说程序员的话就是:索引优化和where条件优化. 实验环境:MacBook Pro MJLQ2CH/A,mysql5.7,数据量:212万+ ONE: select * from article INNER JOIN ( SELECT id FROM article WHERE length(content_url) > 0 an
-
浅谈Mysql大数据分页查询解决方案
目录 1.简介 2.分页插件使用 3.sql测试与分析 3.1 limit现象分析 3.2 解决之道 4 测试时走过的坑 4.1 百万数据内容都一样 4.2 写sql时,把"77"写成了77: 4.3 一个有趣的现象 总结 1.简介 之前,面阿里的时候,有个面试官问我有没有使用过分页查询,我说有,他说分页查询是有问题的,怎么解决:后来这个问题我没有回答出来:本着学习的态度,今天来解决一下这个问题: 2.分页插件使用 1.pom文件 <dependency> <grou
-
MYSQL插入数据时检查字段值是否重复的方法详解
项目需求 现有一张u_ps的车位信息表,对应每个小区的车位id ps_id自增长,每个车位又对应车位编号num,车位id由自增长,车位编号可以根据自己小区情况手动添加设置,但是不能重复,车位编号不能重复.这就需要在新增车位信息的时候代码检验新增的该num在u_ps表中是否存在,存在则抛出异常,不存在则做插入操作. 问题关键 不同的小区community_id中车位num可以重复,如果分开设计表设置唯一约束是可行的,但是我们的需求是将所有的小区车位信息放在同一个表中,这就涉及到在插入一条数据的时候