node.js require() 源码解读
2009年,Node.js 项目诞生,所有模块一律为 CommonJS 格式。
时至今日,Node.js 的模块仓库 npmjs.com ,已经存放了15万个模块,其中绝大部分都是 CommonJS 格式。
这种格式的核心就是 require 语句,模块通过它加载。学习 Node.js ,必学如何使用 require 语句。本文通过源码分析,详细介绍 require 语句的内部运行机制,帮你理解 Node.js 的模块机制。
一、require() 的基本用法
分析源码之前,先介绍 require 语句的内部逻辑。如果你只想了解 require 的用法,只看这一段就够了。
下面的内容翻译自《Node使用手册》。
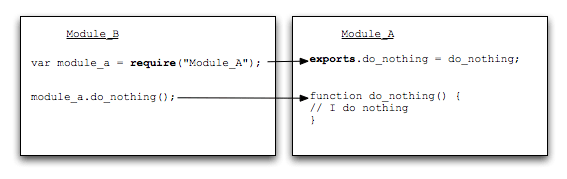
当 Node 遇到 require(X) 时,按下面的顺序处理。
(1)如果 X 是内置模块(比如 require('http'))
a. 返回该模块。
b. 不再继续执行。
(2)如果 X 以 "./" 或者 "/" 或者 "../" 开头
a. 根据 X 所在的父模块,确定 X 的绝对路径。
b. 将 X 当成文件,依次查找下面文件,只要其中有一个存在,就返回该文件,不再继续执行。
X
X.js
X.json
X.node
c. 将 X 当成目录,依次查找下面文件,只要其中有一个存在,就返回该文件,不再继续执行。
X/package.json(main字段)
X/index.js
X/index.json
X/index.node
(3)如果 X 不带路径
a. 根据 X 所在的父模块,确定 X 可能的安装目录。
b. 依次在每个目录中,将 X 当成文件名或目录名加载。
(4) 抛出 "not found"
请看一个例子。
当前脚本文件 /home/ry/projects/foo.js 执行了 require('bar') ,这属于上面的第三种情况。Node 内部运行过程如下。
首先,确定 x 的绝对路径可能是下面这些位置,依次搜索每一个目录。
/home/ry/projects/node_modules/bar
/home/ry/node_modules/bar
/home/node_modules/bar
/node_modules/bar
搜索时,Node 先将 bar 当成文件名,依次尝试加载下面这些文件,只要有一个成功就返回。
bar bar.js bar.json bar.node
如果都不成功,说明 bar 可能是目录名,于是依次尝试加载下面这些文件。
bar/package.json(main字段)
bar/index.js
bar/index.json
bar/index.node
如果在所有目录中,都无法找到 bar 对应的文件或目录,就抛出一个错误。
二、Module 构造函数
了解内部逻辑以后,下面就来看源码。
require 的源码在 Node 的 lib/module.js 文件。为了便于理解,本文引用的源码是简化过的,并且删除了原作者的注释。
function Module(id, parent) {
this.id = id;
this.exports = {};
this.parent = parent;
this.filename = null;
this.loaded = false;
this.children = [];
}
module.exports = Module;
var module = new Module(filename, parent);
上面代码中,Node 定义了一个构造函数 Module,所有的模块都是 Module 的实例。可以看到,当前模块(module.js)也是 Module 的一个实例。
每个实例都有自己的属性。下面通过一个例子,看看这些属性的值是什么。新建一个脚本文件 a.js 。
// a.js
console.log('module.id: ', module.id);
console.log('module.exports: ', module.exports);
console.log('module.parent: ', module.parent);
console.log('module.filename: ', module.filename);
console.log('module.loaded: ', module.loaded);
console.log('module.children: ', module.children);
console.log('module.paths: ', module.paths);
运行这个脚本。
$ node a.js
module.id: .
module.exports: {}
module.parent: null
module.filename: /home/ruanyf/tmp/a.js
module.loaded: false
module.children: []
module.paths: [ '/home/ruanyf/tmp/node_modules',
'/home/ruanyf/node_modules',
'/home/node_modules',
'/node_modules' ]
可以看到,如果没有父模块,直接调用当前模块,parent 属性就是 null,id 属性就是一个点。filename 属性是模块的绝对路径,path 属性是一个数组,包含了模块可能的位置。另外,输出这些内容时,模块还没有全部加载,所以 loaded 属性为 false 。
新建另一个脚本文件 b.js,让其调用 a.js 。
// b.js
var a = require('./a.js');
运行 b.js 。
$ node b.js
module.id: /home/ruanyf/tmp/a.js
module.exports: {}
module.parent: { object }
module.filename: /home/ruanyf/tmp/a.js
module.loaded: false
module.children: []
module.paths: [ '/home/ruanyf/tmp/node_modules',
'/home/ruanyf/node_modules',
'/home/node_modules',
'/node_modules' ]
上面代码中,由于 a.js 被 b.js 调用,所以 parent 属性指向 b.js 模块,id 属性和 filename 属性一致,都是模块的绝对路径。
三、模块实例的 require 方法
每个模块实例都有一个 require 方法。
Module.prototype.require = function(path) {
return Module._load(path, this);
};
由此可知,require 并不是全局性命令,而是每个模块提供的一个内部方法,也就是说,只有在模块内部才能使用 require 命令(唯一的例外是 REPL 环境)。另外,require 其实内部调用 Module._load 方法。
下面来看 Module._load 的源码。
Module._load = function(request, parent, isMain) {
// 计算绝对路径
var filename = Module._resolveFilename(request, parent);
// 第一步:如果有缓存,取出缓存
var cachedModule = Module._cache[filename];
if (cachedModule) {
return cachedModule.exports;
// 第二步:是否为内置模块
if (NativeModule.exists(filename)) {
return NativeModule.require(filename);
}
// 第三步:生成模块实例,存入缓存
var module = new Module(filename, parent);
Module._cache[filename] = module;
// 第四步:加载模块
try {
module.load(filename);
hadException = false;
} finally {
if (hadException) {
delete Module._cache[filename];
}
}
// 第五步:输出模块的exports属性
return module.exports;
};
上面代码中,首先解析出模块的绝对路径(filename),以它作为模块的识别符。然后,如果模块已经在缓存中,就从缓存取出;如果不在缓存中,就加载模块。
因此,Module._load 的关键步骤是两个。
◾Module._resolveFilename() :确定模块的绝对路径
◾module.load():加载模块
四、模块的绝对路径
下面是 Module._resolveFilename 方法的源码。
Module._resolveFilename = function(request, parent) {
// 第一步:如果是内置模块,不含路径返回
if (NativeModule.exists(request)) {
return request;
}
// 第二步:确定所有可能的路径
var resolvedModule = Module._resolveLookupPaths(request, parent);
var id = resolvedModule[0];
var paths = resolvedModule[1];
// 第三步:确定哪一个路径为真
var filename = Module._findPath(request, paths);
if (!filename) {
var err = new Error("Cannot find module '" + request + "'");
err.code = 'MODULE_NOT_FOUND';
throw err;
}
return filename;
};
上面代码中,在 Module.resolveFilename 方法内部,又调用了两个方法 Module.resolveLookupPaths() 和 Module._findPath() ,前者用来列出可能的路径,后者用来确认哪一个路径为真。
为了简洁起见,这里只给出 Module._resolveLookupPaths() 的运行结果。
[ '/home/ruanyf/tmp/node_modules',
'/home/ruanyf/node_modules',
'/home/node_modules',
'/node_modules'
'/home/ruanyf/.node_modules',
'/home/ruanyf/.node_libraries',
'$Prefix/lib/node' ]
上面的数组,就是模块所有可能的路径。基本上是,从当前路径开始一级级向上寻找 node_modules 子目录。最后那三个路径,主要是为了历史原因保持兼容,实际上已经很少用了。
有了可能的路径以后,下面就是 Module._findPath() 的源码,用来确定到底哪一个是正确路径。
Module._findPath = function(request, paths) {
// 列出所有可能的后缀名:.js,.json, .node
var exts = Object.keys(Module._extensions);
// 如果是绝对路径,就不再搜索
if (request.charAt(0) === '/') {
paths = [''];
}
// 是否有后缀的目录斜杠
var trailingSlash = (request.slice(-1) === '/');
// 第一步:如果当前路径已在缓存中,就直接返回缓存
var cacheKey = JSON.stringify({request: request, paths: paths});
if (Module._pathCache[cacheKey]) {
return Module._pathCache[cacheKey];
}
// 第二步:依次遍历所有路径
for (var i = 0, PL = paths.length; i < PL; i++) {
var basePath = path.resolve(paths[i], request);
var filename;
if (!trailingSlash) {
// 第三步:是否存在该模块文件
filename = tryFile(basePath);
if (!filename && !trailingSlash) {
// 第四步:该模块文件加上后缀名,是否存在
filename = tryExtensions(basePath, exts);
}
}
// 第五步:目录中是否存在 package.json
if (!filename) {
filename = tryPackage(basePath, exts);
}
if (!filename) {
// 第六步:是否存在目录名 + index + 后缀名
filename = tryExtensions(path.resolve(basePath, 'index'), exts);
}
// 第七步:将找到的文件路径存入返回缓存,然后返回
if (filename) {
Module._pathCache[cacheKey] = filename;
return filename;
}
}
// 第八步:没有找到文件,返回false
return false;
};
经过上面代码,就可以找到模块的绝对路径了。
有时在项目代码中,需要调用模块的绝对路径,那么除了 module.filename ,Node 还提供一个 require.resolve 方法,供外部调用,用于从模块名取到绝对路径。
require.resolve = function(request) {
return Module._resolveFilename(request, self);
};
// 用法
require.resolve('a.js')
// 返回 /home/ruanyf/tmp/a.js
五、加载模块
有了模块的绝对路径,就可以加载该模块了。下面是 module.load 方法的源码。
Module.prototype.load = function(filename) {
var extension = path.extname(filename) || '.js';
if (!Module._extensions[extension]) extension = '.js';
Module._extensions[extension](this, filename);
this.loaded = true;
};
上面代码中,首先确定模块的后缀名,不同的后缀名对应不同的加载方法。下面是 .js 和 .json 后缀名对应的处理方法。
Module._extensions['.js'] = function(module, filename) {
var content = fs.readFileSync(filename, 'utf8');
module._compile(stripBOM(content), filename);
};
Module._extensions['.json'] = function(module, filename) {
var content = fs.readFileSync(filename, 'utf8');
try {
module.exports = JSON.parse(stripBOM(content));
} catch (err) {
err.message = filename + ': ' + err.message;
throw err;
}
};
这里只讨论 js 文件的加载。首先,将模块文件读取成字符串,然后剥离 utf8 编码特有的BOM文件头,最后编译该模块。
module._compile 方法用于模块的编译。
Module.prototype._compile = function(content, filename) {
var self = this;
var args = [self.exports, require, self, filename, dirname];
return compiledWrapper.apply(self.exports, args);
};
上面的代码基本等同于下面的形式。
(function (exports, require, module, __filename, __dirname) {
// 模块源码
});
也就是说,模块的加载实质上就是,注入exports、require、module三个全局变量,然后执行模块的源码,然后将模块的 exports 变量的值输出。
(完)
相关推荐
-
Node.js中的require.resolve方法使用简介
前言 网上关于NodeJs的论述很多,此处不多说.个人认为,NodeJs的编程思想和客户端Javascript保持了一种理念,没有什么变化,只是增加了"require()"函数,因此只要学好require函数,剩下的问题就是如何更好的使用API了.本文则主要介绍了Node.js中的require.resolve方法,下面来看看详细介绍吧. 简单的说,在 Node.js 中使用 fs 读取文件的时候,经常碰到要拼一个文件的绝对路径的问题 (fs 处理相对路径均以进程执行目录为准). 之前
-
Node.js中require的工作原理浅析
几乎所有的Node.js开发人员可以告诉你`require()`函数做什么,但我们又有多少人真正知道它是如何工作的?我们每天都使用它来加载库和模块,但它的行为,对于我们来说反而是一个谜. 出于好奇,我钻研了node的核心代码来找出在引擎下发生了什么事.但这并不是一个单一的功能,我在node的模块系统的找到了module.js.该文件包含一个令人惊讶的强大的且相对陌生的核心模块,控制每个文件的加载,编译和缓存.`require()`,它的横空出世,只是冰山的一角. module.js 复制代码 代
-
node.js中的require使用详解
代码注释里已经描述的非常的清晰,这里就不多废话了,直接奉上代码: 复制代码 代码如下: /*在node中,可以使用require()函数来加载模块. * require函数使用一个参数,参数值可以带有完整路径的模块的文件名,也可以为模块名.当使用node中提供的模块时,在require函数中只需要指定模块名即可. * */ //建立一个页面2.js;代码如下 var name="思思博士"; exports.name=name; //建立一个页面1.js;代码如下 var two=
-
node.js使用require()函数加载模块
详细说明均以写在注释之中,这里就不啰嗦了,小伙伴们自己详细看吧,千万别吧注释当成空气了. 复制代码 代码如下: /*在node中,可以使用require()函数来加载模块. * require函数使用一个参数,参数值可以带有完整路径的模块的文件名,也可以为模块名.当使用node中提供的模块时,在require函数中只需要指定模块名即可. * */ //建立一个页面2.js;代码如下 var name="思思博士"; exports.name=name; //建立一个页面1.js;代
-
简单模拟node.js中require的加载机制
一.先了解一下,nodejs中require的加载机制 1.require的加载文件顺序 require 加载文件时可以省略扩展名: require('./module'); // 此时文件按 JS 文件执行 require('./module.js'); // 此时文件按 JSON 文件解析 require('./module.json'); // 此时文件预编译好的 C++ 模块执行 require('./module.node'); // 载入目录module目录中的 package.js
-

node.js require() 源码解读
2009年,Node.js 项目诞生,所有模块一律为 CommonJS 格式. 时至今日,Node.js 的模块仓库 npmjs.com ,已经存放了15万个模块,其中绝大部分都是 CommonJS 格式. 这种格式的核心就是 require 语句,模块通过它加载.学习 Node.js ,必学如何使用 require 语句.本文通过源码分析,详细介绍 require 语句的内部运行机制,帮你理解 Node.js 的模块机制. 一.require() 的基本用法 分析源码之前,先介绍 requir
-
Evil.js项目源码解读
目录 引言 源码解析 立即执行函数 为什么要用立即执行函数? includes方法 map方法 filter方法 setTimeout Promise.then JSON.stringify Date.getTime localStorage.getItem 用途 引言 2022年8月18日,一个名叫Evil.js的项目突然走红,README介绍如下: 什么?黑心996公司要让你提桶跑路了? 想在离开前给你们的项目留点小 礼物 ? 偷偷地把本项目引入你们的项目吧,你们的项目会有但不仅限于如下的神
-
Css-In-Js实现classNames库源码解读
目录 引言 使用 源码阅读 兼容性 CommonJS AMD window 浏览器环境 实现 多个参数处理 参数类型处理 数组处理 对象处理 测试用例 Css-in-JS 示例 总结 引言 classNames是一个简单的且实用的JavaScript应用程序,可以有条件的将多个类名组合在一起.它是一个非常有用的工具,可以用来动态的添加或者删除类名. 仓库地址:classNames 使用 根据classNames的README,可以发现库的作者对这个库非常认真,文档和测试用例都非常齐全,同时还有有
-
详解webpack-dev-middleware 源码解读
前言 Webpack 的使用目前已经是前端开发工程师必备技能之一.若是想在本地环境启动一个开发服务,大家只需在 Webpack 的配置中,增加 devServer的配置来启动.devServer 配置的本质是 webpack-dev-server 这个包提供的功能,而 webpack-dev-middleware 则是这个包的底层依赖. 截至本文发表前,webpack-dev-middleware 的最新版本为 webpack-dev-middleware@3.7.2,本文的源码来自于此版本.本
-
Vue3 源码解读之 Teleport 组件使用示例
目录 Teleport 组件解决的问题 Teleport 组件的基本结构 Teleport 组件 process 函数 Teleport 组件的挂载 Teleport 组件的更新 moveTeleport 移动Teleport 组件 hydrateTeleport 服务端渲染 Teleport 组件 总结 Teleport 组件解决的问题 版本:3.2.31 如果要实现一个 “蒙层” 的功能,并且该 “蒙层” 可以遮挡页面上的所有元素,通常情况下我们会选择直接在 标签下渲染 “蒙层” 内容.如果
-
next.js getServerSideProps源码解析
目录 SSR 处理 动态加载处理 总结 SSR 处理 老规矩,昨天写了关于 getServerSideProps 的内容,今天趁热写一下 getServerSideProps 相应的源码,看看 next.js getServerSideProps 是怎么实现的,还有什么从文档无法知晓的细节. 我们先从 SSR 时相关的 getServerSideProps 处理看起,源码排查步骤上一步已经有所介绍,本篇不再多说,在 SSR 时,next.js 会调用 doRender 来进行渲染,其中会再次调用
-
Vite项目自动添加eslint prettier源码解读
目录 引言 使用 源码阅读 总结 引言 vite-pretty-lint库是一个为Vite创建的Vue或React项目初始化eslint和prettier的库. 该库的目的是为了让开发者在创建项目时,不需要手动配置eslint和prettier,而是通过vite-pretty-lint库来自动配置. 源码地址: vite-pretty-lint github1s 直接看 使用 根据vite-pretty-lint库的README.md,使用该库的只需要执行一行命令即可: // NPM npm i
-
通过示例源码解读React首次渲染流程
目录 说明 题目 首次渲染流程 render beginWork completeUnitOfWork commit 准备阶段 before mutation 阶段 mutation 阶段 切换 Fiber Tree layout 阶段 题目解析 总结 说明 本文结论均基于 React 16.13.1 得出,若有出入请参考对应版本源码.参考了 React 技术揭秘. 题目 在开始进行源码分析前,我们先来看几个题目: 题目一: 渲染下面的组件,打印顺序是什么? import React from
-
[转]prototype 源码解读 超强推荐第1/3页
复制代码 代码如下: Prototype is a JavaScript framework that aims to ease development of dynamic web applications. Featuring a unique, easy-to-use toolkit for class-driven development and the nicest Ajax library around, Prototype is quickly becoming the codeb
-
Ajax::prototype 源码解读
AJAX之旅(1):由prototype_1.3.1进入javascript殿堂-类的初探 还是决定冠上ajax的头衔,毕竟很多人会用这个关键词搜索.虽然我认为这只是个炒作的概念,不过不得不承认ajax叫起来要方便多了.所以ajax的意思我就不详细解释了. 写这个教程的起因很简单:经过一段时间的ajax学习,有一些体会,并且越发认识到ajax技术的强大,所以决定记录下来,顺便也是对自己思路的整理.有关这个教程的后续,请关注http://www.x2design.net 前几年,javascri