asp.net c# 抓取页面信息方法介绍
一:网页更新
我们知道,一般网页中的信息是不断翻新的,这也要求我们定期的去抓这些新信息,但是这个“定期”该怎么理解,也就是多长时间需要抓一次该页面,其实这个定期也就是页面缓存时间,在页面的缓存时间内我们再次抓取该网页是没有必要的,反而给人家服务器造成压力。
就比如说我要抓取博客园首页,首先清空页面缓存, 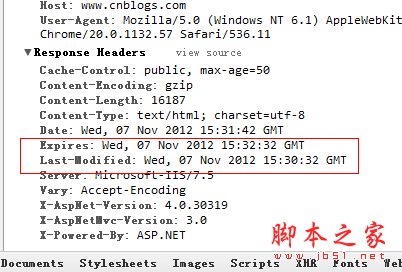
从Last-Modified到Expires,我们可以看到,博客园的缓存时间是2分钟,而且我还能看到当前的服务器时间Date,如果我再次
刷新页面的话,这里的Date将会变成下图中 If-Modified-Since,然后发送给服务器,判断浏览器的缓存有没有过期? 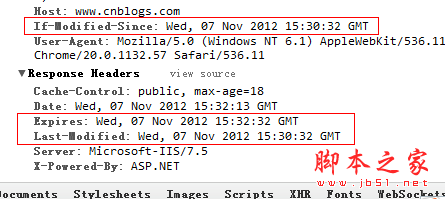
最后服务器发现If-Modified-Since >= Last-Modifined的时间,服务器也就返回304了,不过发现这cookie信息真是贼多啊 。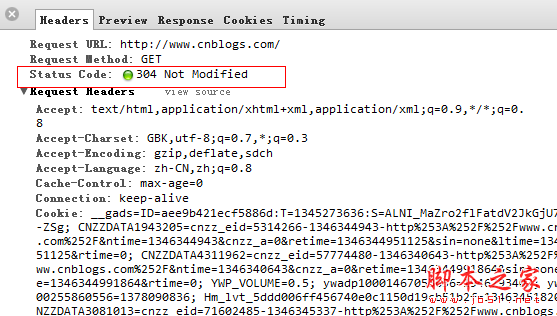
在实际开发中,如果在知道网站缓存策略的情况下,我们可以让爬虫2min爬一次就好了,当然这些都是可以由数据团队来配置维护了, 好了,下面我们用爬虫模拟一下。
代码如下:
using System;
using System.Net;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
DateTime prevDateTime = DateTime.MinValue;
for (int i = 0; i < 10; i++)
{
try
{
var url = "http://cnblogs.com";
var request = (HttpWebRequest)HttpWebRequest.Create(url);
request.Method = "Head";
if (i > 0)
{
request.IfModifiedSince = prevDateTime;
}
request.Timeout = 3000;
var response = (HttpWebResponse)request.GetResponse();
var code = response.StatusCode;
//如果服务器返回状态是200,则认为网页已更新,记得当时的服务器时间
if (code == HttpStatusCode.OK)
{
prevDateTime = Convert.ToDateTime(response.Headers[HttpResponseHeader.Date]);
}
Console.WriteLine("当前服务器的状态码:{0}", code);
}
catch (WebException ex)
{
if (ex.Response != null)
{
var code = (ex.Response as HttpWebResponse).StatusCode;
Console.WriteLine("当前服务器的状态码:{0}", code);
}
}
}
}
}
}

二:网页编码的问题
有时候我们已经抓取到网页了,准备去解析的时候,tmd的全部是乱码,真是操蛋,比如下面这样, 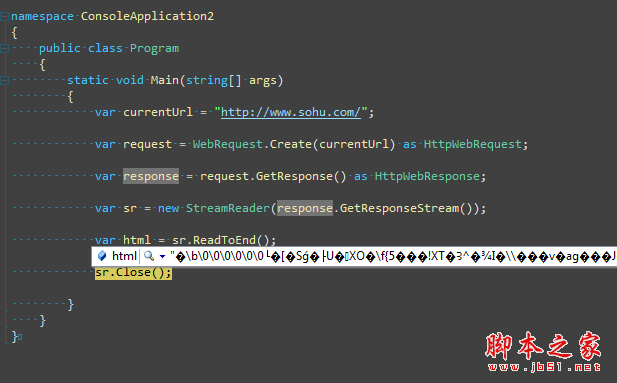
或许我们依稀的记得在html的meta中有一个叫做charset的属性,里面记录的就是编码方式,还有一个要点就是response.CharacterSet这个属性中同样也记录了编码方式,下面我们再来试试看。 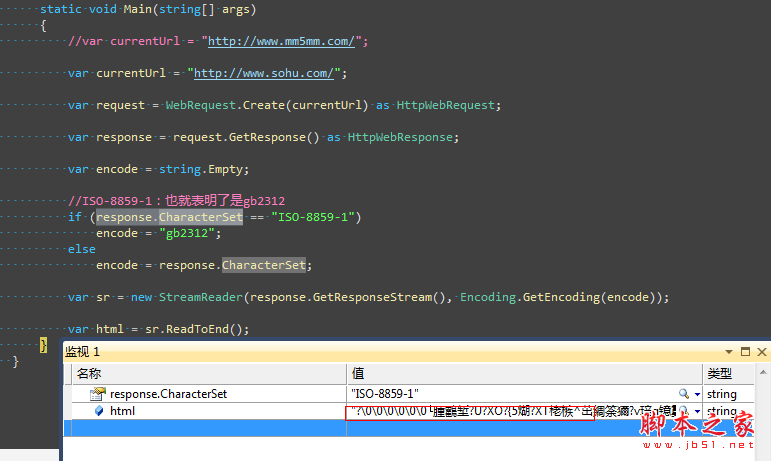
居然还是乱码,蛋疼了,这次需要到官网上面去看一看,到底http头信息里面都交互了些什么,凭什么浏览器能正常显示,爬虫爬过来的就不行。 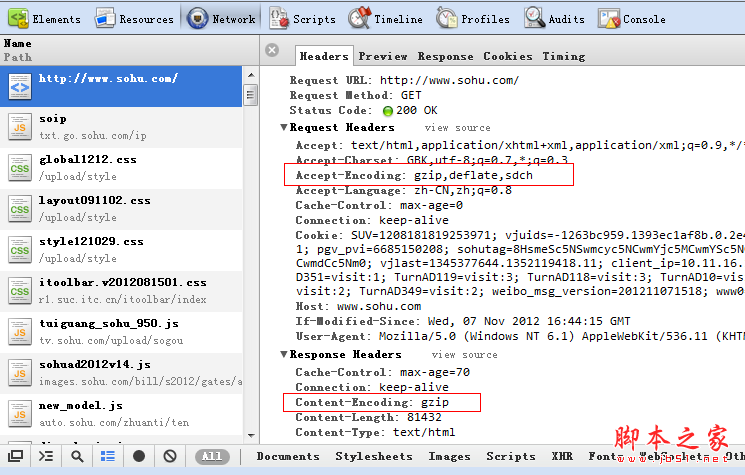
查看了http头信息,终于我们知道了,浏览器说我可以解析gzip,deflate,sdch这三种压缩方式,服务器发送的是gzip压缩,到这里我们也应该知道了常用的web性能优化。
代码如下:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using HtmlAgilityPack;
using System.Text.RegularExpressions;
using System.Net;
using System.IO;
using System.IO.Compression;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
//var currentUrl = "http://www.mm5mm.com/";
var currentUrl = "http://www.sohu.com/";
var request = WebRequest.Create(currentUrl) as HttpWebRequest;
var response = request.GetResponse() as HttpWebResponse;
var encode = string.Empty;
if (response.CharacterSet == "ISO-8859-1")
encode = "gb2312";
else
encode = response.CharacterSet;
Stream stream;
if (response.ContentEncoding.ToLower() == "gzip")
{
stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
}
else
{
stream = response.GetResponseStream();
}
var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
var html = sr.ReadToEnd();
}
}
}
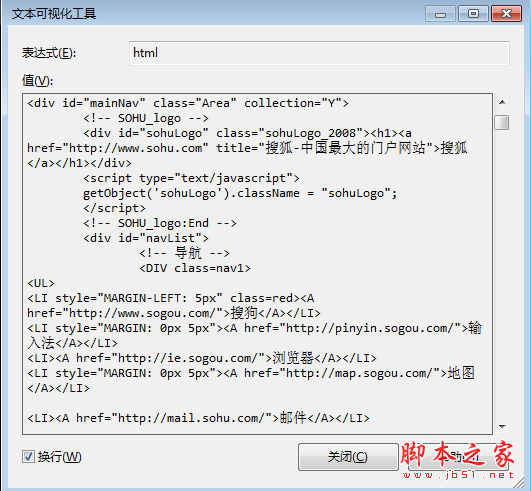
三:网页解析
既然经过千辛万苦拿到了网页,下一个就要解析了,当然正则匹配是个好方法,毕竟工作量还是比较大的,可能业界也比较推崇 HtmlAgilityPack这个解析工具,能够将Html解析成XML,然后可以用XPath去提取指定的内容,大大提高了开发速度,性能也不赖,毕竟Agility也就是敏捷的意思,关于XPath的内容,大家看懂W3CSchool的这两张图就OK了。 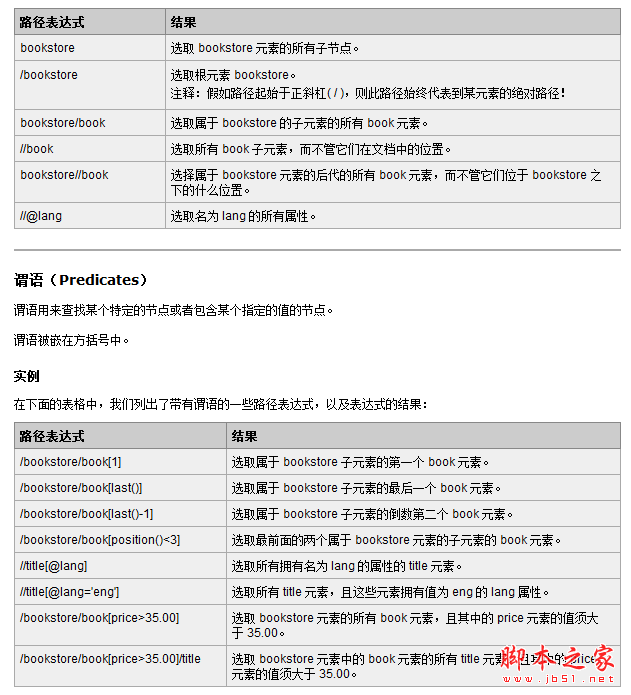
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using HtmlAgilityPack;
using System.Text.RegularExpressions;
using System.Net;
using System.IO;
using System.IO.Compression;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
//var currentUrl = "http://www.mm5mm.com/";
var currentUrl = "http://www.sohu.com/";
var request = WebRequest.Create(currentUrl) as HttpWebRequest;
var response = request.GetResponse() as HttpWebResponse;
var encode = string.Empty;
if (response.CharacterSet == "ISO-8859-1")
encode = "gb2312";
else
encode = response.CharacterSet;
Stream stream;
if (response.ContentEncoding.ToLower() == "gzip")
{
stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
}
else
{
stream = response.GetResponseStream();
}
var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
var html = sr.ReadToEnd();
sr.Close();
HtmlDocument document = new HtmlDocument();
document.LoadHtml(html);
//提取title
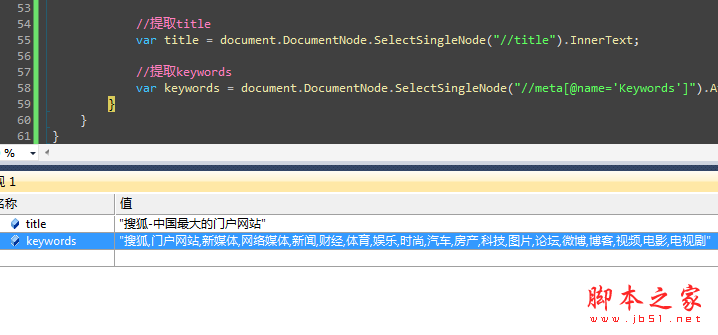
var title = document.DocumentNode.SelectSingleNode("//title").InnerText;
//提取keywords
var keywords = document.DocumentNode.SelectSingleNode("//meta[@name='Keywords']").Attributes["content"].Value;
}
}
}
好了,打完收工,睡觉。。。
相关推荐
-

C#使用HtmlAgilityPack抓取糗事百科内容实例
本文实例讲述了C#使用HtmlAgilityPack抓取糗事百科内容的方法.分享给大家供大家参考.具体实现方法如下: Console.WriteLine("*****************糗事百科24小时热门*******************"); Console.WriteLine("请输入页码,输入0退出"); string page = Console.ReadLine(); while (page!="0") { HtmlWeb h
-
C#抓取网页数据 解析标题描述图片等信息 去除HTML标签
一.首先将网页内容整个抓取下来,数据放在byte[]中(网络上传输时形式是byte),进一步转化为String,以便于对其操作,实例如下: 复制代码 代码如下: private static string GetPageData(string url) { if (url == null || url.Trim() == "") return null; WebClient wc = new WebClient(); wc.Credentials
-
C#实现抓取和分析网页类实例
本文实例讲述了C#实现抓取和分析网页类.分享给大家供大家参考.具体分析如下: 这里介绍了抓取和分析网页的类. 其主要功能有: 1.提取网页的纯文本,去所有html标签和javascript代码 2.提取网页的链接,包括href和frame及iframe 3.提取网页的title等(其它的标签可依此类推,正则是一样的) 4.可以实现简单的表单提交及cookie保存 /* * Author:Sunjoy at CCNU * 如果您改进了这个类请发一份代码给我(ccnusjy 在gmail.com)
-
基于C#实现网络爬虫 C#抓取网页Html源码
最近刚完成一个简单的网络爬虫,开始的时候很迷茫,不知道如何入手,后来发现了很多的资料,不过真正能达到我需要,有用的资料--代码很难找.所以我想发这篇文章让一些要做这个功能的朋友少走一些弯路. 首先是抓取Html源码,并选择<ul class="post_list"> </ul>节点的href:要添加using System.IO;using System.Net; private void Search(string url) { string rl; Web
-
c# HttpWebRequest通过代理服务器抓取网页内容应用介绍
内网用户或代理上网的用户使用 复制代码 代码如下: using System.IO; using System.Net; public string get_html() { string urlStr = "http://www.domain.com"; //設定要獲取的地址 HttpWebRequest hwr = (HttpWebRequest)HttpWebRequest.Create(urlStr); //建立HttpWebRequest對象 hwr.Timeout = 60
-
c#实现抓取高清美女妹纸图片
c#实现抓取高清美女妹纸图片 复制代码 代码如下: private void DoFetch(int pageNum) { ThreadPool.QueueUserWorkItem(_ => { HttpWebRequest request = (HttpWebRequest)WebRequest.Create("http://me2-sex.lofter.com/tag/美女摄影?page=&
-
C#实现通过程序自动抓取远程Web网页信息的代码
通过程序自动的读取其它网站网页显示的信息,类似于爬虫程序.比方说我们有一个系统,要提取BaiDu网站上歌曲搜索排名.分析系统在根据得到的数据进行数据分析.为业务提供参考数据. 为了完成以上的需求,我们就需要模拟浏览器浏览网页,得到页面的数据在进行分析,最后把分析的结构,即整理好的数据写入数据库.那么我们的思路就是: 1.发送HttpRequest请求. 2.接收HttpResponse返回的结果.得到特定页面的html源文件. 3.取出包含数据的那一部分源码. 4.根据html源码生成HtmlD
-
C#抓取当前屏幕并保存为图片的方法
本文实例讲述了C#抓取当前屏幕并保存为图片的方法.分享给大家供大家参考.具体分析如下: 这是一个C#实现的屏幕抓取程序,可以抓取整个屏幕保存为指定格式的图片,并且保存当前控制台缓存到文本 using System; using System.Collections.Generic; using System.ComponentModel; using System.Diagnostics; using System.Drawing; using System.Drawing.Imaging; u
-
c#根据网址抓取网页截屏生成图片的示例
复制代码 代码如下: using System.Drawing;using System.Drawing.Imaging;using System.IO;using System.Threading;using System.Windows.Forms; public class WebsiteToImage{private Bitmap m_Bitmap;private string m_Url;private string m_FileName = string.Empty; public
-
ASP.net(C#)从其他网站抓取内容并截取有用信息的实现代码
1. 需要引用的类库 复制代码 代码如下: using System.Net; using System.IO; using System.Text; using System.Text.RegularExpressions; 2. 获取其他网站网页内容的关键代码 复制代码 代码如下: WebRequest request = WebRequest.Create("http://目标网址.com/"); WebResponse response = request.GetRespons
-
C# 抓取网页内容的方法
1.抓取一般内容 需要三个类:WebRequest.WebResponse.StreamReader 所需命名空间:System.Net.System.IO 核心代码: view plaincopy to clipboardprint? 复制代码 代码如下: WebRequest request = WebRequest.Create("http://www.jb51.net/"); WebResponse response = request.GetResponse(); S