通过java.util.TreeMap源码加强红黑树的理解
在此之前,我们已经为大家整理了很多关于经典问题红黑树的思路和解决办法。本篇文章,是通过分析java.util.TreeMap源码,让大家通过实例来对红黑树这个问题有更加深入的理解。
本篇将结合JDK1.6的TreeMap源码,来一起探索红-黑树的奥秘。红黑树是解决二叉搜索树的非平衡问题。
当插入(或者删除)一个新节点时,为了使树保持平衡,必须遵循一定的规则,这个规则就是红-黑规则:
1) 每个节点不是红色的就是黑色的
2) 根总是黑色的
3) 如果节点是红色的,则它的子节点必须是黑色的(反之倒不一定必须为真)
4) 从跟到叶节点或者空子节点的每条路径,必须包含相同数目的黑色节点
插入一个新节点
红-黑树的插入过程和普通的二叉搜索树基本一致:从跟朝插入点位置走,在每个节点处通过比较节点的关键字相对大小来决定向左走还是向右走。
public V put(K key, V value) {
Entry<K,V> t = root;
int cmp;
Entry<K,V> parent;
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0) {
t = t.left;
} else if (cmp > 0) {
t = t.right;
} else {
// 注意,return退出方法
return t.setValue(value);
}
} while (t != null);
Entry<K,V> e = new Entry<K,V>(key, value, parent);
if (cmp < 0) {
parent.left = e;
} else {
parent.right = e;
}
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
但是,在红-黑树种,找到插入点更复杂,因为有颜色变换和旋转。fixAfterInsertion()方法就是处理颜色变换和旋转,需重点掌握它是如何保持树的平衡(use rotations and the color rules to maintain the tree's balance)。
下面的讨论中,使用X、P、G表示关联的节点。X表示一个特殊的节点, P是X的父,G是P的父。
X is a node that has caused a rule violation. (Sometimes X refers to a newly inserted node, and sometimes to the child node when a parent and child have a redred conflict.)
On the way down the tree to find the insertion point, you perform a color flip whenever you find a black node with two red children (a violation of Rule 2). Sometimes the flip causes a red-red conflict (a violation of Rule 3). Call the red child X and the red parent P. The conflict can be fixed with a single rotation or a double rotation, depending on whether X is an outside or inside grandchild of G. Following color flips and rotations, you continue down to the insertion point and insert the new node.
After you've inserted the new node X, if P is black, you simply attach the new red node. If P is red, there are two possibilities: X can be an outside or inside grandchild of G. If X is an outside grandchild, you perform one rotation, and if it's an inside grandchild, you perform two. This restores the tree to a balanced state.
按照上面的解释,讨论可分为3个部分,按复杂程度排列,分别是:
1) 在下行路途中的颜色变换(Color flips on the way down)
2) 插入节点之后的旋转(Rotations after the node is inserted)
3) 在向下路途上的旋转(Rotations on the way down)
在下行路途中的颜色变换(Color flips on the way down)
Here's the rule: Every time the insertion routine encounters a black node that has two red children, it must change the children to black and the parent to red (unless the parent is the root, which always remains black)
The flip leaves unchanged the number of black nodes on the path from the root on down through P to the leaf or null nodes.
尽管颜色变换不会违背规则4,但是可能会违背规则3。如果P的父是黑色的,则P由黑色变成红色时不会有任何问题,但是,如果P的父是红色的,那么在P的颜色变化之后,就有两个红色节点相连接了。这个问题需要在继续向下沿着路径插入新节点之前解决,可以通过旋转修正这个问题,下文将会看到。
插入节点之后的旋转(Rotations after the node is inserted)
新节点在插入之前,树是符合红-黑规则,在插入新节点之后,树就不平衡了,此时需要通过旋转来调整树的平衡,使之重新符合红-黑规则。
可能性1:P是黑色的,就什么事情也不用做。插入即可。
可能性2:P是红色,X是G的一个外侧子孙节点,则需要一次旋转和一些颜色的变化。
以插入50,25,75,12,6为例,注意节点6是一个外侧子孙节点,它和它的父节点都是红色。
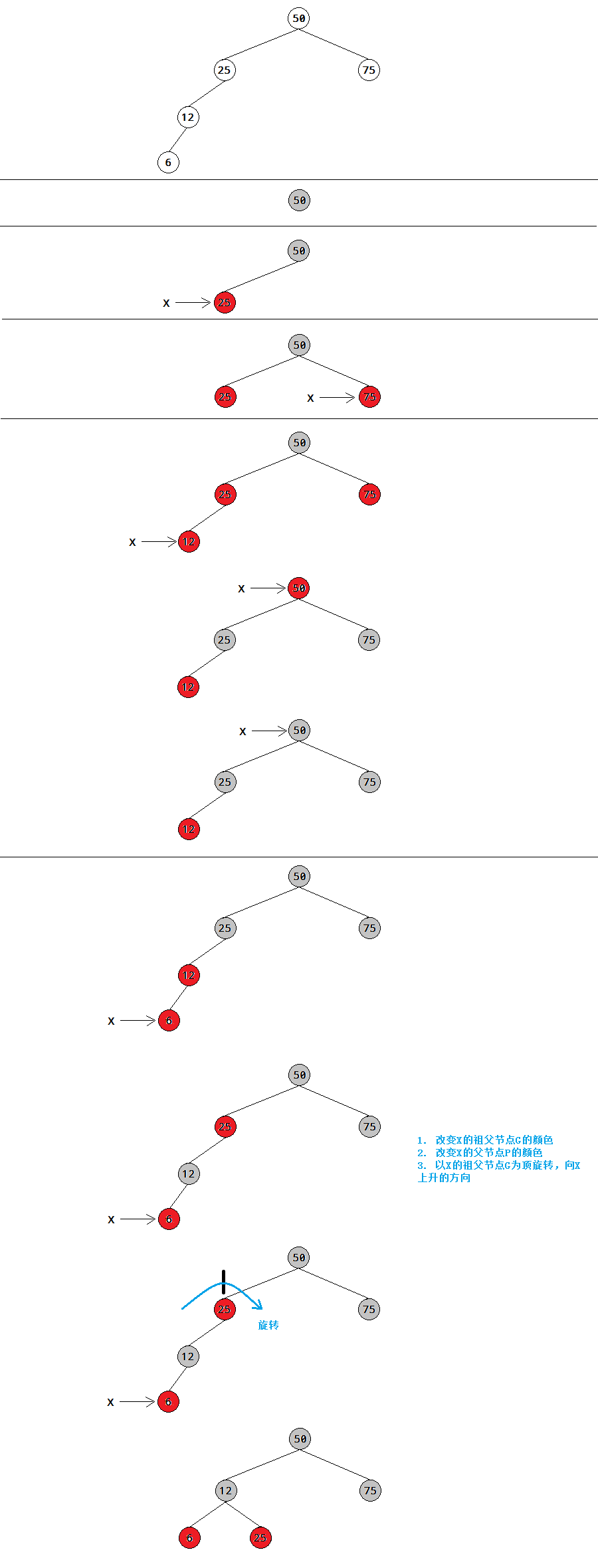
在这个例子中,X是一个外侧子孙节点而且是左子节点,X是外侧子孙节点且为右子节点,是一种与此对称的情况。通过用50,25,75,87,93创建树,同理再画一画图,这里就省略了。
可能性3:P是红色,X是G的一个内侧子孙节点,则需要两次旋转和一些颜色的改变。
以插入50,25,75,12,18为例,注意节点18是一个内侧子孙节点,它和它的父节点都是红色。
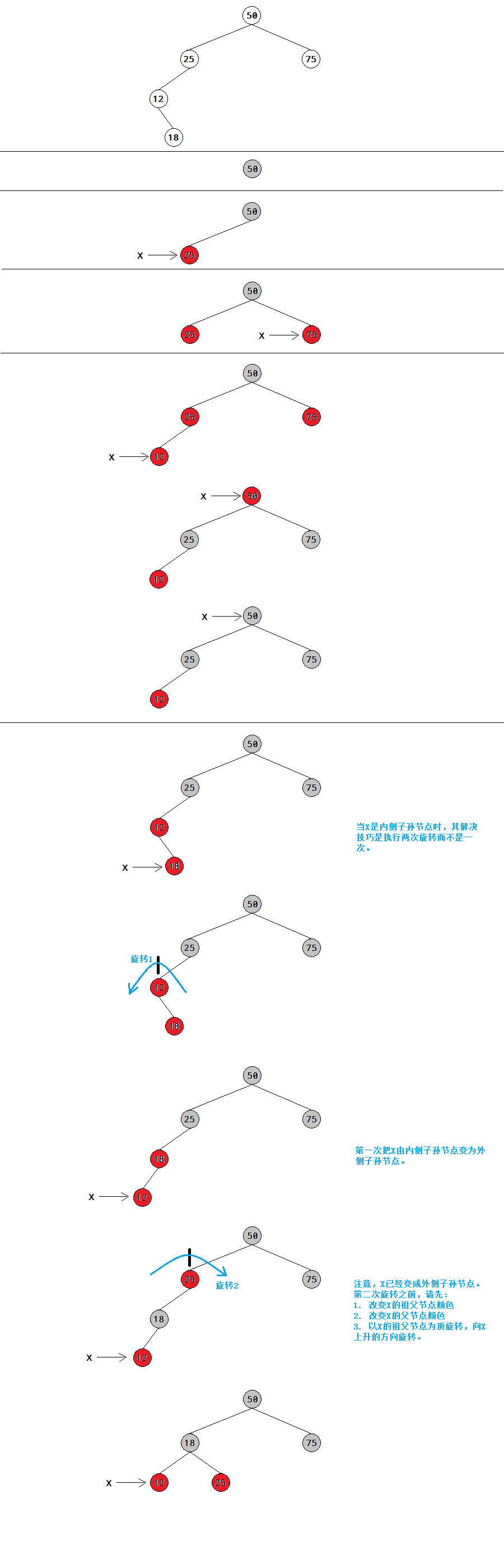
在向下路途上的旋转(Rotations on the way down)
在插入新节点之前,实际上树已经违背了红-黑规则,所以需要插入新节点之前做调整。所以我们本次讨论的主题是“在向下路途准备插入新节点时,上面先进行调整,使上面成为标准的红黑树后,再进行新节点插入”。
外侧子孙节点
以插入50,25,75,12,37,6,18,3为例,例子中违背规则的节点是一个外侧子孙节点。
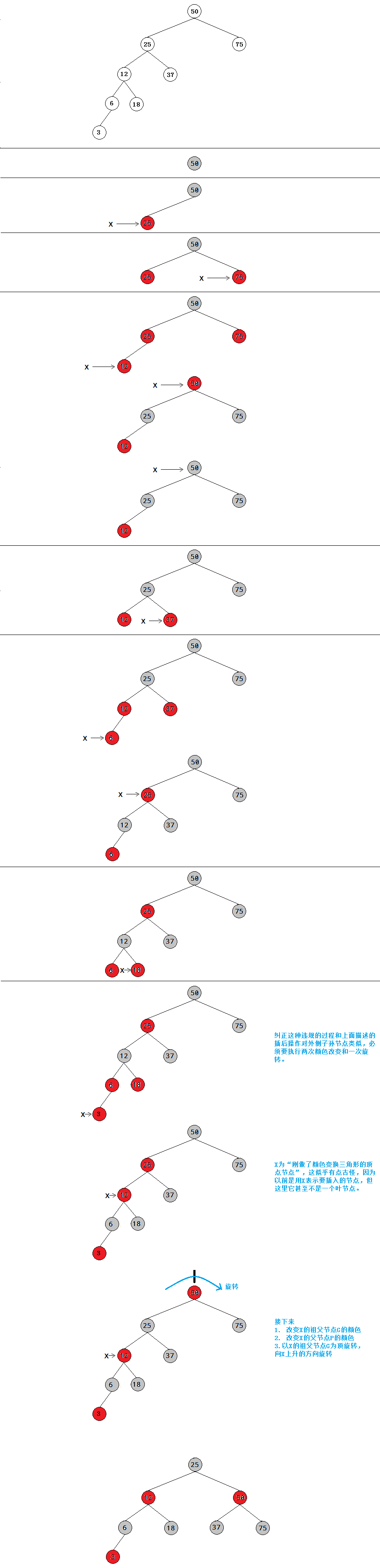
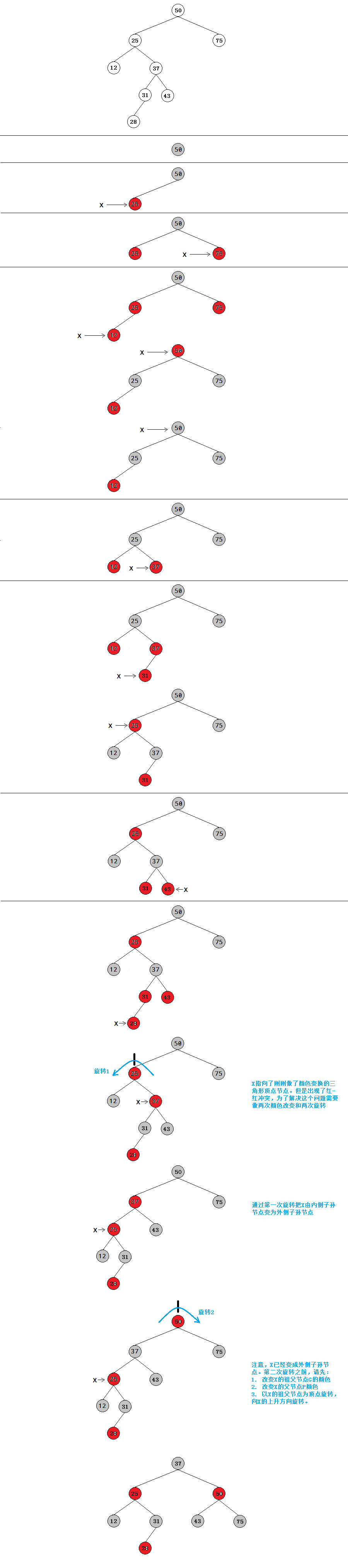
内侧子孙节点
以插入50,25,75,12,37,31,43为例,例子中违背规则的节点是一个内侧子孙节点。
红-黑树的效率
和一般的二叉搜索树类似,红-黑树的查找、插入和删除的时间复杂度为O(log2N)。
红-黑树的查找时间和普通的二叉搜索树的查找时间应该几乎完全一样。因为在查找过程中并没用到红-黑特征。额外的开销只是每个节点的存储空间都稍微增加了一点,来存储红黑颜色(一个boolean变量)。
final Entry<K, V> getEntry(Object key) {Comparable <? super K > k = (Comparable <? super K > ) key;Entry<K, V> p = root;while (p != null) {int cmp = k.compareTo(p.key);if (cmp < 0) {p = p.left;} else if (cmp > 0) {p = p.right;} else {return p;}}return null;}
插入和删除的时间要增加一个常数因子,因为不得不在下行的路径上和插入点执行颜色变换和旋转。平均起来一次插入大约需要一次旋转。
因为在大多数应用中,查找的次数比插入和删除的次数多,所以应用红-黑树取代普通的二叉搜索树总体上不会增加太多的时间开销。
相关推荐
-
java中TreeMap排序的示例代码
1. 定义TreeMap的排序方法 使用Comparator对象作为参数 需要注意的是:排序方法是针对键的,而不是值的.如果想针对值,需要更麻烦的一些方法(重写一些方法) TreeMap<Screen,Integer> res = new TreeMap<Screen, Integer>(new Comparator<Screen>() { @Override public int compare(Screen screen1, Screen t1) { // 定义Tr
-
Java源码解析TreeMap简介
TreeMap是常用的排序树,本文主要介绍TreeMap中,类的注释中对TreeMap的介绍.代码如下. /** * A Red-Black tree based {@link NavigableMap} implementation. * The map is sorted according to the {@linkplain Comparable natural * ordering} of its keys, or by a {@link Comparator} provided at
-
浅谈java中的TreeMap 排序与TreeSet 排序
TreeMap: package com; import java.util.Comparator; import java.util.TreeMap; public class Test5 { /** * @param args */ public static void main(String[] args) { // TODO Auto-generated method stub TreeMap<String, String> tree = new TreeMap<String,
-
Java中HashMap和TreeMap的区别深入理解
首先介绍一下什么是Map.在数组中我们是通过数组下标来对其内容索引的,而在Map中我们通过对象来对对象进行索引,用来索引的对象叫做key,其对应的对象叫做value.这就是我们平时说的键值对. HashMap通过hashcode对其内容进行快速查找,而 TreeMap中所有的元素都保持着某种固定的顺序,如果你需要得到一个有序的结果你就应该使用TreeMap(HashMap中元素的排列顺序是不固定的). HashMap 非线程安全 TreeMap 非线程安全 线程安全 在Java里,线程安全一般体
-
java 中HashMap、HashSet、TreeMap、TreeSet判断元素相同的几种方法比较
java 中HashMap.HashSet.TreeMap.TreeSet判断元素相同的几种方法比较 1.1 HashMap 先来看一下HashMap里面是怎么存放元素的.Map里面存放的每一个元素都是key-value这样的键值对,而且都是通过put方法进行添加的,而且相同的key在Map中只会有一个与之关联的value存在.put方法在Map中的定义如下. V put(K key, V value); 它用来存放key-value这样的一个键值对,返回值是key在Map中存放的旧va
-
java HashMap,TreeMap与LinkedHashMap的详解
java HashMap,TreeMap与LinkedHashMap的详解 今天上午面试的时候 问到了Java,Map相关的事情,我记错了HashMap和TreeMap相关的内容,回来赶紧尝试了几个demo理解下 package Map; import java.util.*; public class HashMaps { public static void main(String[] args) { Map map = new HashMap(); map.put("a", &
-

java中treemap和treeset实现红黑树
TreeMap 的实现就是红黑树数据结构,也就说是一棵自平衡的排序二叉树,这样就可以保证当需要快速检索指定节点. TreeSet 和 TreeMap 的关系 为了让大家了解 TreeMap 和 TreeSet 之间的关系,下面先看 TreeSet 类的部分源代码: public class TreeSet<E> extends AbstractSet<E> implements NavigableSet<E>, Cloneable, java.io.Serializab
-
Java TreeMap排序算法实例
本文实例讲述了Java TreeMap排序算法.分享给大家供大家参考,具体如下: TreeMap 和 HashMap 用法大致相同,但实际需求中,我们需要把一些数据进行排序: 以前在项目中,从数据库查询出来的数据放在List中,顺序都还是对的,但放在HashMap中,顺序就完全乱了. 为了处理排序的问题: 1. 对于一些简单的排序,如:数字,英文字母等 TreeMap hm = new TreeMap<String, String>(new Comparator() { public int
-
java TreeMap源码解析详解
java TreeMap源码解析详解 在介绍TreeMap之前,我们来了解一种数据结构:排序二叉树.相信学过数据结构的同学知道,这种结构的数据存储形式在查找的时候效率非常高. 如图所示,这种数据结构是以二叉树为基础的,所有的左孩子的value值都是小于根结点的value值的,所有右孩子的value值都是大于根结点的.这样做的好处在于:如果需要按照键值查找数据元素,只要比较当前结点的value值即可(小于当前结点value值的,往左走,否则往右走),这种方式,每次可以减少一半的操作,所以效率比较高
-
Java源码解析阻塞队列ArrayBlockingQueue常用方法
本文基于jdk1.8进行分析 ArrayBlockingQueue的功能简介参考https://www.jb51.net/article/154211.htm. 首先看一下ArrayBlockingQueue的成员变量.如下图.最主要的成员变量是items,它是一个Object类型的数组用于保存阻塞队列中的元素.其次是takeIndex,putIndex,count,分别表示了从队列获取元素的位置,往队列里放元素的位置和队列中元素的个数.然后是lock,notEmpty和notFull三个和锁相