如何使用Dapper处理多个结果集与多重映射实例教程
前言
对象关系映射(ORM)已经被使用了很长时间,以解决在编程过程中对象模型与数据模型在关系数据库中不匹配的问题。
Dapper是由Stack OverFlow团队开发的开源的,轻量级的ORM.相比于其他的ORM框架,Dapper速度非常快。
Dapper的设计考虑到了性能以及易用性。它支持使用事务,存储过程或数据批量插入的静态和动态对象绑定。
在本文中,我们将介绍如何使用DAPPER从单个数据库调用中读取数据库中的多个结果集。我们将看看我们可能希望这样做的场景,以及如何使用它的Query和QueryMultiple方法更简洁地实现这一点。 当我们谈论以数据为中心的应用程序时,可能会出现一些场景,在这些场景中我们可能希望从数据库中检索多重结果。多个结果集既可以是相关的,也可以是无关的。要做到这一点,我们不需要对数据库进行多次往返,而是可以在一次数据库调用本身中实际使用dapper检索结果,然后将结果映射到代码中的所需对象。
在我们继续并开始研究如何做到这一点之前,让我们首先试着理解在我们的应用程序中可能希望做到这一点的场景:
1、查询无关实体:所请求的实体根本不相关。
2、查询具有1至多个关系的相关实体:被请求的实体具有1对多的关系,我们需要在代码中处理多个结果集
3、查询具有1至1关系的相关实体:被请求的实体具有1-1关系,我们需要在代码中执行处理多个映射 在第一个场景中,我们有完全不相关的实体,因此基本上,我们只想执行两个独立的查询来检索数据,然后将其映射到这些实体。在第二个场景中,返回的实体与1-多相关,因此我们希望检索数据,然后将结果映射到具有1至多个关系的POCO中。
最后,在第三个场景中,返回的实体是1-1,因此我们希望检索数据,然后将结果映射到具有1-1关系的POCO中。 现在让我们看看一些代码,了解如何使用Dapper来实现这一切。 所有这些都可以通过DAPPER的查询、QueryMultiple和Read方法进行归档。现在让我们把重点放在如何在代码中执行这些操作。
查询无关实体
假设我们想从API中检索书籍和视频列表。我们可以通过两个简单的选择所有查询来实现这一点,数据库结果看起来如
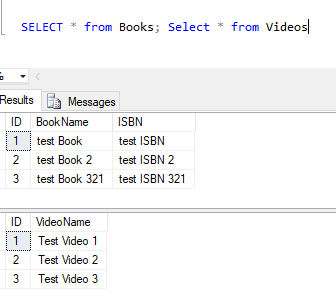
现在,为了能够从代码中执行同样的操作,我们首先需要定义我们的实体:
public class Book
{
public int ID { get; set; }
public string BookName { get; set;}
public string ISBN { get; set; }
}
public class Video
{
public int ID { get; set; }
public string VideoName { get; set; }
}
使用这些模型,让我们看看如何只使用一个数据库调用来使用DAPPER检索这些结果:
public IActionResult Index()
{
// define our SQL query - it contains mulitple queries seprated by ;
var query = "SELECT * from Books; Select * from Videos";
// Execute the query
var results = dbConnection.QueryMultiple(query);
// retrieve the results into the respective models
var books = results.Read<Book>();
var videos = results.Read<Video>();
return Ok(new { Books = books, Videos = videos});
}
现在让我们在POSTMAN中运行,以查看行动中的结果:

注意:我已经创建了一个简单的API控制器来测试这个代码,所有的DB访问代码都在里面运行。这只是为了演示目的和现实世界的应用,这样的代码根本不应该被使用。
查询具有1到多关系的查询相关实体
检索相关实体的另一个典型场景是实体之间存在一对多关系。让我们尝试使用组织和联系人的例子来可视化这一点。组织通常具有与其关联的多个联系人。如果我们想要检索一个组织,并且想要检索所有关联的联系人,我们可以利用QueryMultiple来做到这一点。这就是关系在数据库中的样子。
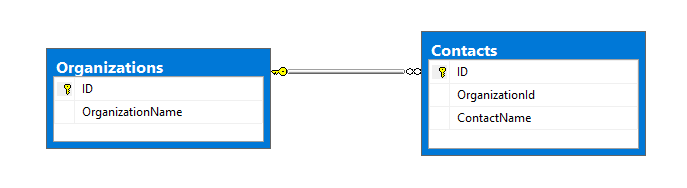
首先让我们检查一下如何使用SQL查询做同样的操作。
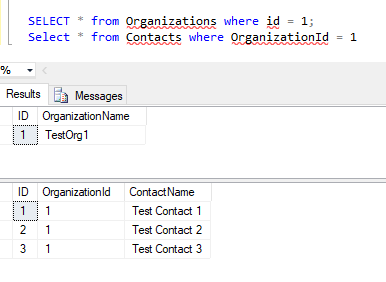
现在,如果我们必须在代码中做同样的事情,我们首先需要定义我们的实体。请注意,我们的实体也将建模一对多关系的方式,每个组织有一个联系人列表。
public class Organization
{
public int ID { get; set; }
public string OrganizationName { get; set; }
public List<contact> Contacts { get; set; }
}
public class Contact
{
public int ID { get; set; }
public int OrganizationId { get; set; }
public string ContactName { get; set; }
}
</contact>
现在让我们看一下用于检索这些相关实体的代码,并了解如何用dapper的QueryMultiple方法填充与1到多个关系相关的实体。
[HttpGet("{id}")]
public IActionResult GetOrganization(int id)
{
// define our SQL query - it contains mulitple queries seprated by ;
var query = @"SELECT* from Organizations where id = @id;
Select * from Contacts where OrganizationId = @id";
// Execute the query
var results = dbConnection.QueryMultiple(query, new { @id = id });
// retrieve the results into the respective models
var org = results.ReadSingle<Organization>();
org.Contacts = results.Read<Contact>().ToList();
return Ok(org);
}
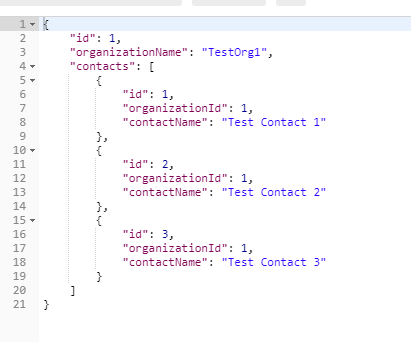
在上面的代码中,我们可以看到我们是如何同时执行2个查询的。我们接受了第一个查询结果并填充了我们的组织对象。第二个查询结果作为同一个组织对象的联系人集合被推送。
现在让我们在POSTMAN中运行,以查看行动中的结果:
具有1到1关系的查询相关实体
前两个场景非常简单,因为它们要求我们编写两个独立的查询,然后独立收集每个查询的结果,以便根据需要创建模型对象。
但是有1到1个关系的场景是很棘手的。从数据库的角度来看,我们可以在单个SQL查询本身中检索相关实体,但是随后我们希望将单个结果集映射到代码中的多个对象中。这可以使用在DAPPER中可用的多重映射特征来完成。让我们在一个例子的帮助下理解这一点。
注意:我们仍然可以使用与1到许多关系相同的方法来检索与1到1相关的数据,但是本节将展示如何使用单个SQL并映射结果。
让我们举一个联系和护照的例子。每个联系人只能有一个护照。让我们先想象一下这个数据库关系。
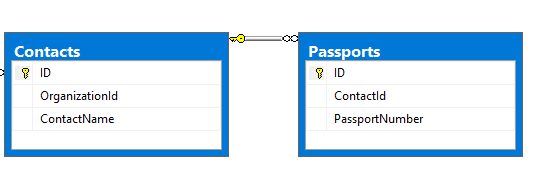
现在,让我们看看是否需要从数据库中检索联系人列表及其护照信息,我们如何用SQL实现这一点。
现在让我们看看我们的实体如何寻找联系和护照。
public class Contact
{
public int ID { get; set; }
public int OrganizationId { get; set; }
public string ContactName { get; set; }
public Passport Passport { get; set; }
}
public class Passport
{
public int ID { get; set; }
public int Contactid { get; set; }
public string PassportNumber { get; set; }
}
现在让我们看看如何从数据库中检索这些相关实体,并使用更简洁的多重映射完整地填充具有相同关系的POCOs。
[HttpGet("{id}")]
public IActionResult GetContact(int id)
{
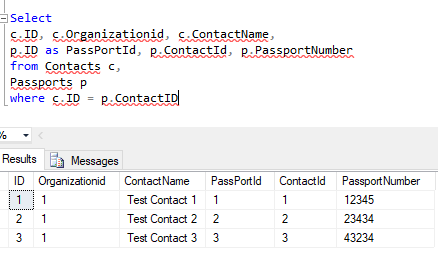
var query = @"Select
c.ID, c.Organizationid, c.ContactName,
p.ID as PassPortId, p.ContactId, p.PassportNumber
from Contacts c,
Passports p
where c.ID = p.ContactID
and c.id = @id";
// Execute the query
var contact = dbConnection.Query<Contact, Passport, Contact>(query, MapResults, new { @id = id }, splitOn: "PassportId");
return Ok(contact);
}
private Contact MapResults(Contact contact, Passport passport)
{
contact.Passport = passport;
return contact;
}
在上面的代码中,我们使用的是查询方法的重载版本,它采用多个类型。传递的类型是我们要映射的每个对象的类型参数,最后一个类型参数是表示该查询将返回的对象类型的附加参数。
因此,在我们的查询中,我们希望将结果映射到类型Contact和Passsport,然后期望结果返回到类型Contact的对象中。
现在,让我们看看在查询方法中传递的实际参数。
第一个参数是SQL查询本身。
第二个参数是映射函数,它将获取结果,将它绑定到相应的类型,然后创建所需的返回类型并返回该返回类型。在我们的代码中,它采用Contact和Passport类型,并将Contact的Passport属性指定为正在传递的Passport值。一旦这样做,结果接触类型返回。
第三个参数是命令参数@ id。
最后一个参数拆分是将告诉DAPPER哪些列必须映射到下一个对象的列名。在我们的示例中,我们将此值作为PassportId传递,这意味着在找到PassportId列之前,所有列都将映射到第一种类型,即Contact,然后随后的列将被映射到下一个参数类型,即Passport。
注意:如果我们有2个以上的对象需要映射,splitOn将是一个逗号分隔的列表,其中每个列名将充当分隔符,并开始下一个对象类型的映射列。
现在让我们在POSTMAN中运行,以查看行动中的结果:
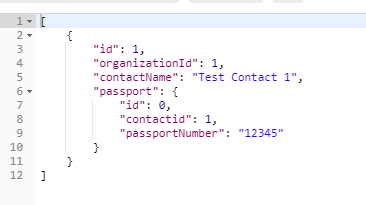
欧了,我们使用DAPPER从数据库中检索多个结果集,以避免数据库往返。
总结:
在本文中,我们讨论了如何使用dapper提供的特性在一次运行中检索多个相关或无关的实体,从而避免多次数据库往返。这是从初学者的角度写的。我希望这有一定的信息性。
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对我们的支持。
相关推荐
-
.net core2.0下使用Identity改用dapper存储数据(实例讲解)
前言. 已经好多天没写博客了,鉴于空闲无聊之时又兴起想写写博客,也当是给自己做个笔记.过了这么些天,我的文笔还是依然那么烂就请多多谅解了.今天主要是分享一下在使用.net core2.0下的实际遇到的情况.在使用webapi时用了identity做用户验证.官方文档是的是用EF存储数据来使用dapper,因为个人偏好原因所以不想用EF.于是乎就去折腾.改成使用dapper做数据存储.于是就有了以下的经验. 一.使用Identity服务 先找到Startup.cs 这个类文件 找到 Configu
-

Asp.net中使用DapperExtensions和反射来实现一个通用搜索
前言 搜索功能是一个很常用的功能,当然这个搜索不是指全文检索,是指网站的后台管理系统或ERP系统列表的搜索功能.常见做法一般就是在搜索栏上加上几个常用字段来搜索.代码可能一般这样实现 StringBuilder sqlStr = new StringBuilder(); if (!string.IsNullOrEmpty(RealName)) { sqlStr.Append(" and RealName = @RealName"); } if (Age != -1) { sqlStr.
-
在C#中如何使用Dapper详解(译)
前言: Dapper是一款轻量级ORM工具.如果你在小的项目中,使用Entity Framework.NHibernate 来处理大数据访问及关系映射,未免有点杀鸡用牛刀.你又觉得ORM省时省力,这时Dapper 将是你不二的选择. 对象关系映射(ORM)已经被使用了很长时间,以解决在编程过程中对象模型与数据模型在关系数据库中不匹配的问题. Dapper是由Stack OverFlow团队开发的开源的,轻量级的ORM.相比于其他的ORM框架,Dapper速度非常快. Dapper的设计考虑到了性
-
基于Dapper实现分页效果 支持筛选、排序、结果集总数等
简介 之前事先搜索了下博客园上关于Dapper分页的实现,有是有,但要么是基于存储过程,要么支持分页,而不支持排序,或者搜索条件不是那么容易维护. 代码 首先先上代码: https://github.com/jinweijie/Dapper.PagingSample 方法定义 以下是我的一个分页的实现,虽然不是泛型(因为考虑到where条件以及sql语句的搭配),但是应该可以算是比较通用的了,方法定义如下: public Tuple<IEnumerable<Log>, int> F
-
如何使用Dapper处理多个结果集与多重映射实例教程
前言 对象关系映射(ORM)已经被使用了很长时间,以解决在编程过程中对象模型与数据模型在关系数据库中不匹配的问题. Dapper是由Stack OverFlow团队开发的开源的,轻量级的ORM.相比于其他的ORM框架,Dapper速度非常快. Dapper的设计考虑到了性能以及易用性.它支持使用事务,存储过程或数据批量插入的静态和动态对象绑定. 在本文中,我们将介绍如何使用DAPPER从单个数据库调用中读取数据库中的多个结果集.我们将看看我们可能希望这样做的场景,以及如何使用它的Query和Qu
-
Mongo复制集同步验证的实例详解
mongo复制集同步验证的实例详解 第一步:在主节点上插入一条数据 Sql代码 rs0:PRIMARY> use imooc switched to db imooc rs0:PRIMARY> db.imooc.insert({"name":"imooc"}) WriteResult({ "nInserted" : 1 }) 第二步:在从节点查看数据,看是否同步 Sql代码 rs0:SECONDARY> use imooc sw
-
Redis集群的搭建图文教程
redis集群的特点: 1.机器多,能够保证redis服务器出现问题后,影响较小 2.自备主从结构,自动的根据算法划分主从结构.动态的实现 3.能够根据主从结构自动的实现高可用 4.实现数据文件的备份 3.Redis集群的搭建步骤: 准备9台服务器 3主6从 一个主机下有2个子节点 7000-7008 2.拷贝redis.conf文件到文件夹中 cp redis.conf 7000/redis-7000.conf mkdir 7000 7001 7002 7003 7004 7005 7006
-
基于redis集群设置密码的实例
注意事项: 1.如果是使用redis-trib.rb工具构建集群,集群构建完成前不要配置密码,集群构建完毕再通过config set + config rewrite命令逐个机器设置密码 2.如果对集群设置密码,那么requirepass和masterauth都需要设置,否则发生主从切换时,就会遇到授权问题,可以模拟并观察日志 3.各个节点的密码都必须一致,否则Redirected就会失败 config set masterauth abc config set requirepass abc
-
VMware + Ubuntu18.04 搭建Hadoop集群环境的图文教程
目录 前言 VMware克隆虚拟机(准备工作,克隆3台虚拟机,一台master,两台node) 1.创建Hadoop用户(在master,node1,node2执行) 2.更新apt下载源(在master,node1,node2执行) 3. 安装SSH.配置SSH免密登录 (在master,node1,node2执行) 4.安装Java环境 (在master,node1,node2执行) 修改主机名(在master,node1,node2执行) 修改IP映射(在master,node1,node
-
Java返回分页结果集的封装代码实例
这篇文章主要介绍了java返回分页结果集的封装代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 代码如下 package com.leyou.common; import java.util.List; public class PageResult<T> { private long total;//总条数 private Integer totalPage;//总页数 private List<T> list; publ
-
redis 分片集群搭建与使用教程
目录 前言 搭建集群架构图 前置准备 搭建步骤 创建集群 Redis散列插槽说明 集群伸缩(添加节点) 故障转移 使用redistemplate访问分片集群 前言 redis可以说在实际项目开发中使用的非常频繁,在redis常用集群中,我们聊到了redis常用的几种集群方案,不同的集群对应着不同的场景,并且详细说明了各种集群的优劣,本篇将以redis 分片集群为切入点,从redis 分片集群的搭建开始,详细说说redis 分片集群相关的技术点: 单点故障: 单机写(高并发写)瓶颈: 单机存储数据
-
C++并查集亲戚(Relations)算法实例
本文实例讲述了C++并查集亲戚(Relations)算法.分享给大家供大家参考.具体分析如下: 题目: 亲戚(Relations) 或许你并不知道,你的某个朋友是你的亲戚.他可能是你的曾祖父的外公的女婿的外甥的表姐的孙子.如果能得到完整的家谱,判断两个人是否亲戚应该是可行的,但如果两个人的最近公共祖先与他们相隔好几代,使得家谱十分庞大,那么检验亲戚关系实非人力所能及.在这种情况下,最好的帮手就是计算机. 为了将问题简化,你将得到一些亲戚关系的信息,如同Marry和Tom是亲戚,Tom和B en是
-
MySQL Cluster集群的初级部署教程
Mysql Cluster概述 MySql Cluster最显著的优点就是高可用性,高实时性,高冗余,扩展性强. 它允许在无共享的系统中部署"内存中"数据库的Cluster.通过无共享体系结构,系统能够使用廉价的硬件.此外,由于每个组件有自己的内存和磁盘,所以不存在单点故障. 它由一组计算机构成,每台计算机上均运行者多种进程,包括mysql服务器,NDB cluster的数据节点,管理服务启,以及专门的数据访问程序 所有的这些节点构成一个完整的mysql集群体系.数据保存在"
-
Google 地图控件集详解及实例代码
Google 地图控件集 Google 地图 - 默认控件集设置: 当使用一个标准的google地图,它的默认设置如下: 1.Zoom-显示一个滑动条来控制map的Zoom级别 2.PPan-地图上显示的是一个平底碗样的控件,点击4个角平移地图 3.MapType-允许用户在map types(roadmap 和 satallite)之间切换 4.StreetView-显示为一个街景小人图标,可拖拽到地图上某个点来打开街景 Google 地图 - 更多控件集 除了以上默认控件集,Google还有