hadoop client与datanode的通信协议分析
本文主要分析了hadoop客户端read和write block的流程. 以及client和datanode通信的协议, 数据流格式等.
hadoop客户端与namenode通信通过RPC协议, 但是client 与datanode通信并没有使用RPC, 而是直接使用socket, 其中读写时的协议也不同, 本文分析了hadoop 0.20.2版本的(0.19版本也是一样的)client与datanode通信的原理与通信协议. 另外需要强调的是0.23及以后的版本中client与datanode的通信协议有所变化, 使用了protobuf作为序列化方式.
Write block
1. 客户端首先通过namenode.create, 向namenode请求创建文件, 然后启动dataStreamer线程
2. client包括三个线程, main线程负责把本地数据读入内存, 并封装为Package对象, 放到队列dataQueue中.
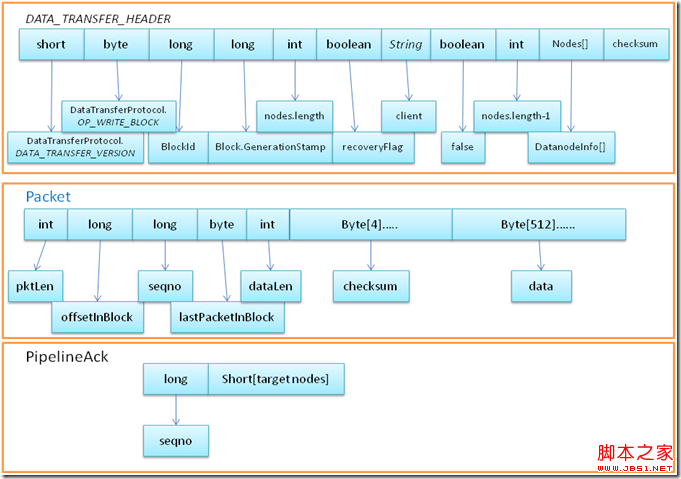
3. dataStreamer线程检测队列dataQueue是否有package, 如果有, 则先创建BlockOutPutStream对象(一个block创建一次, 一个block可能包括多个package), 创建的时候会和相应的datanode通信, 发送DATA_TRANSFER_HEADER信息并获取返回. 然后创建ResponseProcessor线程, 负责接收datanode的返回ack确认信息, 并进行错误处理.
4. dataStreamer从dataQueue中拿出Package对象, 发送给datanode. 然后继续循环判断dataQueue是否有数据…..
下图展示了write block的流程.

下图是报文的格式
Read block
主要在BlockReader类中实现.
初始化newBlockReader时,
1. 通过传入参数sock创建new SocketOutputStream(socket, timeout), 然后写通信信息, 与写block的header不大一样.
//write the header.
out.writeShort( DataTransferProtocol.DATA_TRANSFER_VERSION );
out.write( DataTransferProtocol.OP_READ_BLOCK );
out.writeLong( blockId );
out.writeLong( genStamp );
out.writeLong( startOffset );
out.writeLong( len );
Text.writeString(out, clientName);
out.flush();
2. 创建输入流 new SocketInputStream(socket, timeout)
3. 判断返回消息 in.readShort() != DataTransferProtocol.OP_STATUS_SUCCESS
4. 根据输入流创建checksum : DataChecksum checksum = DataChecksum.newDataChecksum( in )
5. 读取第一个Chunk的位置: long firstChunkOffset = in.readLong()
注: 512个字节为一个chunk计算checksum(4个字节)
6. 接下来在BlockReader的read方法中读取具体数据: result = readBuffer(buf, off, realLen)
7. 一个一个chunk的读取
int packetLen = in.readInt();
long offsetInBlock = in.readLong();
long seqno = in.readLong();
boolean lastPacketInBlock = in.readBoolean();
int dataLen = in.readInt();
IOUtils.readFully(in, checksumBytes.array(), 0,
checksumBytes.limit());
IOUtils.readFully(in, buf, offset, chunkLen);
8. 读取数据后checksum验证; FSInputChecker.verifySum(chunkPos)
相关推荐
-
WebSocket+node.js创建即时通信的Web聊天服务器
本文实例node.js创建即时通信的Web聊天服务器,供大家参考,具体内容如下 1.使用nodejs-websocket nodejs-websocket是基于node.js编写的一个后端实现websocket协议的库, 连接:https://github.com/sitegui/nodejs-websocket. (1)安装 在项目目录下通过npm安装:npm install nodejs-websocket (2)创建服务器 //引入nodejs-websocket var ws
-
基于socket.io和node.js搭建即时通信系统
使用socket.io和nodejs搭建websocket服务器端 socket.io不仅可以搭建客户端的websocket服务,而且支持nodejs服务器端的websocket. 下面让我来介绍一下怎么安装配置nodejs. 进入http://nodejs.org/#download下载msi文件.一直点next安装.最后文件会自动安装在C:\nodejs目录下. 安装完成后,会自动配置环境环境变量.如果没有自动配置,自己手动在path处加上 ;C:\nodejs\. 安装完成后,需要配置np
-
使用DNode实现php和nodejs之间通信的简单实例
一.安装DNode 1, for nodejs, 执行 复制代码 代码如下: $ sudo npm install dnode 2, for php, 利用composer来安装DNode php 执行下列语句下载composer 复制代码 代码如下: $ wget http://getcomposer.org/composer.phar 创建一个文件composer.json,然后填入如下语句, 复制代码 代码如下: { "require": { "
-
详解从Node.js的child_process模块来学习父子进程之间的通信
child_process模块提供了和popen(3)一样的方式来产生自进程,这个功能主要是通过child_process.spawn函数来提供的: const spawn = require('child_process').spawn; const ls = spawn('ls', ['-lh', '/usr']); ls.stdout.on('data', (data) => { console.log(`stdout: ${data}`); }); ls.stderr.on('data'
-
基于Node.js的WebSocket通信实现
node的依赖包 node中实现Websocket的依赖包有很多,websocket.ws均可,本文选取ws来实现,首先安装依赖 npm install ws 聊天室实例 假如A,B,C,D用户均通过客户端连接到Websocket服务,其中每个人发的消息都需要将其通过Websocket转发给其他人,此场景类似于服务端将A的消息广播给组内其他用户. 服务端实现 首先来看服务端程序,具体的工作流程分以下几步: 创建一个WebSocketServer的服务,同时监听8080端口的连接请求. 每当有新的
-

hadoop client与datanode的通信协议分析
本文主要分析了hadoop客户端read和write block的流程. 以及client和datanode通信的协议, 数据流格式等. hadoop客户端与namenode通信通过RPC协议, 但是client 与datanode通信并没有使用RPC, 而是直接使用socket, 其中读写时的协议也不同, 本文分析了hadoop 0.20.2版本的(0.19版本也是一样的)client与datanode通信的原理与通信协议. 另外需要强调的是0.23及以后的版本中client与datanod
-
Hadoop源码分析三启动及脚本剖析
1. 启动 hadoop的启动是通过其sbin目录下的脚本来启动的.与启动相关的叫脚本有以下几个: start-all.sh.start-dfs.sh.start-yarn.sh.hadoop-daemon.sh.yarn-daemon.sh. hadoop-daemon.sh是用来启动与hdfs相关的服务的 yarn-daemon.sh是用来启动和yarn相关的服务 start-dfs.sh是用来启动hdfs集群的 start-yarn.sh是用来启动yarn集群 start-all.sh是用
-
Hadoop 分布式存储系统 HDFS的实例详解
HDFS是Hadoop Distribute File System 的简称,也就是Hadoop的一个分布式文件系统. 一.HDFS的优缺点 1.HDFS优点: a.高容错性 .数据保存多个副本 .数据丢的失后自动恢复 b.适合批处理 .移动计算而非移动数据 .数据位置暴露给计算框架 c.适合大数据处理 .GB.TB.甚至PB级的数据处理 .百万规模以上的文件数据 .10000+的节点 d.可构建在廉价的机器上 .通过多副本存储,提高可靠性 .提供了容错和恢复机制 2.HDFS缺点 a.低延迟数
-
Java访问Hadoop分布式文件系统HDFS的配置说明
配置文件 m103替换为hdfs服务地址. 要利用Java客户端来存取HDFS上的文件,不得不说的是配置文件hadoop-0.20.2/conf/core-site.xml了,最初我就是在这里吃了大亏,所以我死活连不上HDFS,文件无法创建.读取. <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <co
-
Hadoop 2.x与3.x 22点比较,Hadoop 3.x比2.x的改进
问题导读 1.Hadoop3.x通过什么方式来容错? 2.Hadoop3.x存储开销减少了多少? 3.Hadoop3.x MR API是否兼容hadoop1.x? 一.目的 在这篇文章中,我们将讨论Hadoop 2.x与Hadoop 3.x之间的比较. Hadoop3版本中添加了哪些新功能,Hadoop3中兼容的Hadoop 2程序,Hadoop 2和Hadoop 3有什么区别? 二.Hadoop 2.x与Hadoop 3.x比较 本节将讲述Hadoop 2.x与Hadoop 3.x之间的22个
-
利用Java连接Hadoop进行编程
目录 实验环境 实验内容 测试Java远程连接hadoop 实验环境 hadoop版本:3.3.2 jdk版本:1.8 hadoop安装系统:ubuntu18.04 编程环境:IDEA 编程主机:windows 实验内容 测试Java远程连接hadoop 创建maven工程,引入以下依赖: <dependency> <groupId>org.testng</groupId> <artifactId>testng</artifactId> <
-
hadoop常见错误以及处理方法详解
1.hadoop-root-datanode-master.log 中有如下错误:ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: java.io.IOException: Incompatible namespaceIDs in导致datanode启动不了.原因:每次namenode format会重新创建一个namenodeId,而dfs.data.dir参数配置的目录中包含的是上次format创建的id,和dfs.name.dir
-
Python连接Hadoop数据中遇到的各种坑(汇总)
最近准备使用Python+Hadoop+Pandas进行一些深度的分析与机器学习相关工作.(当然随着学习过程的进展,现在准备使用Python+Spark+Hadoop这样一套体系来搭建后续的工作环境),当然这是后话. 但是这项工作首要条件就是将Python与Hadoop进行打通,本来认为很容易的一项工作,没有想到竟然遇到各种坑,花费了整整半天时间.后来也在网上看到大家在咨询相同的问题,但是真正解决这个问题的帖子又几乎没有,所以现在将Python连接Hadoop数据库过程中遇到的各种坑进行一个汇总
-
Hadoop 使用IntelliJ IDEA 进行远程调试代码的配置方法
一 .前言 昨天晚上遇到一个奇葩的问题, 搞好的环境DataNode启动报错. 报错信息提示的模棱两可,没办法定位原因. 办法,开启远程调试- 注意 : 开启远程调试的代码,必须与本地idea的代码必须保持一致. 二 .服务器端配置 2.1. 设置启动远程debug端口 修改 服务器上的配置文件 ${HADOOP_HOME}/etc/hadoop/hadoop-env.sh 增加 环境变量即可. 组件 环境变量设置 NameNode export HADOOP_NAMENODE_OPTS="-a
-
Java操作hdfs文件系统过程
目录 1.前置准备 2.编码环境前置准备 1.导入maven依赖 2.添加一个log4j.properties 文件 3.API使用环节 1.创建hdfs文件目录 2.上传文件到hdfs文件目录 3.从hdfs上面下载文件到本地 4.删除hdfs文件 5.修改hdfs文件名称 6.移动同时修改hdfs文件名称 7.文件查看相关 8.hdfs文件与文件夹的判断 4.整合Java 客户端过程中遇到的几个坑 1.运行程序直接报无法连接问题 2.上传文件情况 1.前置准备 默认服务器上的hadoop服务