利用Python+阿里云实现DDNS动态域名解析的方法
引子
我想大家应该都很熟悉DNS了,这回在DNS前面加了一个D又变成了什么呢?这个D就是Dynamic(动态),也就是说,按照传统,一个域名所对应的IP地址应该是定死的,而使用了DDNS后,域名所对应的IP是可以动态变化的。那这个有什么用呢?
比如,在家里的路由器上连着一个raspberry pi(树莓派),上面跑着几个网站,我应该如和在外网环境下访问网站、登陆树莓派的SSH呢?
还有,家里的NAS(全称Network Attach Storage 网络附属存储,可以理解为私有的百度网盘)上存储着大量的视频、照片,如何在外网环境下和朋友分享呢?
这时,就要靠DDNS了!它会动态侦运营商分配给你的IP变化,并映射到域名上,这时就可以用域名来访问家庭环境中的内容了~
哈!有了域名,走遍天下都不怕有木有
实现效果(因为我已经更新过了,所以它提示IP地址已存在,阿里云是不允许同一个IP重复更新的)
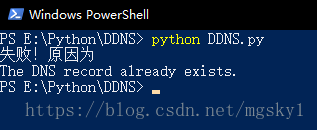
本地:

使用DDNS后,在外网环境下:
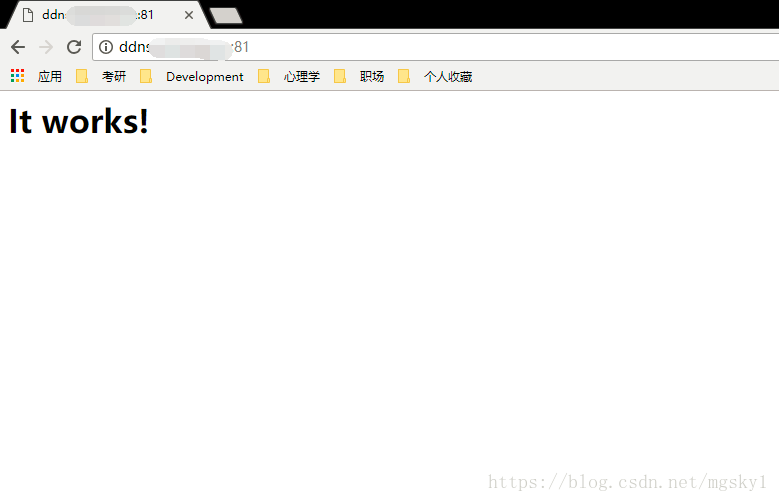
注:
这篇帖子适用于家庭宽带的IP是公网IP的小伙伴,但是注意,这种公网IP是临时的,会不定时进更改。判断方法很简单:先去百度搜索IP,查到自己的IP地址;接着本地开一个网站,比如在Windows下直接启动IIS,Linux下安装一个Apache或者Nginx启动,使用它们的默认页面;然后在路由器上设置好转发规则,公网IP的网络访问端口最好不要用80,80端口可能被运营商封了;最后利用前面查到的公网IP+端口号访问一下,看看能不能显示内网上的页面,如果可以,恭喜你!
本文涉及到的技术点会比较多,比如爬虫啊,设计模式啊,函数修饰符啊等等,可以算是一个综合运用了吧~
实现思路
前面引文已经说的很清楚了,就是探测家庭宽带公网IP的变化,然后利用我们的程序将这个IP更新到它所绑定的二级域名上~
综上,我的思路是这样的:
1、利用Python去网上爬取自己真实的IP地址
2、利用阿里云所提供的接口更新IP
前期准备
1、一个域名(国内需要备案,港澳台和国外听说是不要的,我也没尝试过)
2、将域名的解析设置到阿里云的云解析上
3、为我们的DDNS创建一个二级域名(例如 ddns.expamle.com)
4、安装阿里云Python SDK(具体教程可以去阿里云上找
5、建议先去阅读一下Python SDK的使用示例
6、约定:所有的API请求都返回JSON格式,所以要使用Python的JSON模块进行解析
环境版本
1、Python 3.6
2、网页解析利用BeautifulSoup 4
3、阿里的云解析API和Python SDK直接使用官方最新版本即可
实现步骤
项目结构

注:
AcsClientSingleton.py => 阿里云AcsClient单实例类
CommonRequestSingleton.py => 阿里云CommonRequest的单实例类,获取阿里云Common Request请求类
DDNS.py => 主程序
IpGetter.py =>获取家庭宽带实际的公网IP
Utils.py => 工具类
爬IP
首当其冲的就是要获得我们实际的IP地址,推荐ip138.com
你看到的页面是这样的:
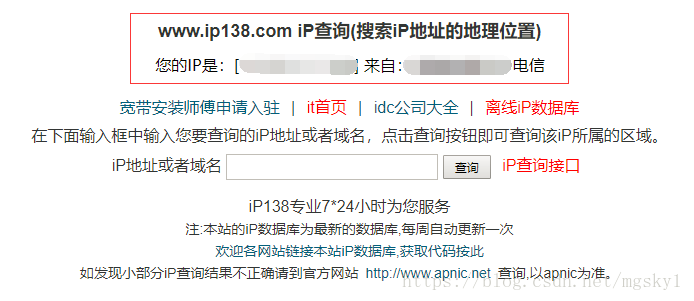
画红框的部分是一个iframe

其中的URL是一直会变化的,所以第一步是要获取这个URL,我这里用到的解析框架是BeautifulSoup,感觉用Scrapy有点大材小用了
#获得IP检测的网页URL
def getIpPage():
url = "http://www.ip138.com/"
response = urllib.request.urlopen(url)
html = response.read().decode("gb2312")
soup = BeautifulSoup(html, "lxml")
_iframe = soup.body.iframe
return _iframe["src"]
获取到检测IP地址的URL后,我们可以观察一下网页结构
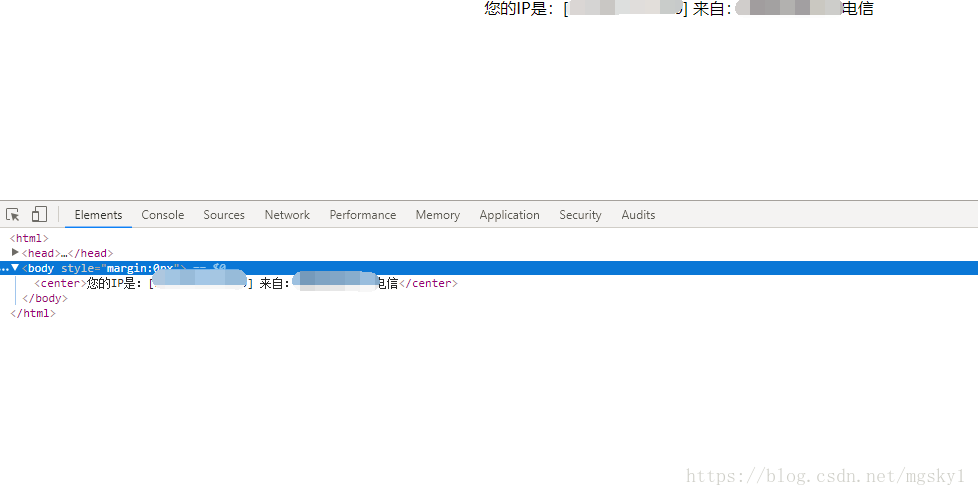
发现,我们只需要获取到center标签的内容,然后用正则提取出IP即可
#获取IP地址
def getRealIp(url):
response = urllib.request.urlopen(url)
html = response.read().decode("gb2312")
pattern = r"(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)"
matchs = re.search(pattern,html)
ip_addr = ""
for i in range(1,5):
ip_addr += matchs.group(i) + "."
return ip_addr[:-1]
然后我们爬的工作就完成了,可以将这个获取IP的过程进行封装,放进工具类里
查文档
阿里云云解析API文档
我们需要用到的是UpdateDomainRecord这个Action。
可以观察一下它的请求参数

在阿里的请求中,有一个公共参数(上面没有提及),里面有一个签名,这个签名虽然官方提供了签名生成的算法,不过如果自己实现很容易出错,所以我们使用它的Python SDK。在签名中,有一个至关重要的是AccessKey,AccessKey的生成可以在管理控制台的AccessKeys模块获取

生成之后一定要保管好这个密钥哦!!!!!
由于云解析官方并没有提供对应的SDK模块,只提供了API,不过我们可以利用SDK中的CommonRequest对象来进行API操作。不知道各位有木有发现在更新域名解析记录的请求参数中有一个RecordId,这个RecordId要利用DescribeDomainRecords这个Action来获取。
如果每次请求都要使用CommonRequest对象,这样难免会造成一定的内存浪费,所以使用面向对象设计模式中的单例模式进行优化。
class CommonRequestSing: #私有类变量 __request = None #该修饰符将实例方法变成类方法 #,因为类方法无法操作私有的类变量,所以使用实例方法进行操作,再进行转换为类方法 @classmethod def getInstance(self): if self.__request is None: self.__request = CommonRequest() return self.__request
同时,在构造请求式,也会用到AcsClient对象,也可使用单例模式优化
class AcsClientSing:
__client = None
@classmethod
def getInstance(self):
if self.__client is None:
self.__client = AcsClient('Your_AccessKeyId', 'Your_AccessKeySecret', 'cn-hangzhou')
return self.__client
这里用到了函数修饰符@classmethod,主要功能是将实例方法转换为类方法。
这两个单实例都可封装进工具类中,直接调用工具类获取实例就可以了,代码会更美观一些。
获取RecordID
利用DescribeDomainRecords 这个Action来获得。
#获取二级域名的RecordId
def getRecordId(domain):
client = Utils.getAcsClient()
request = Utils.getCommonRequest()
request.set_domain('alidns.aliyuncs.com')
request.set_version('2015-01-09')
request.set_action_name('DescribeDomainRecords')
request.add_query_param('DomainName', 'Your_DomainName eg.example.com')
response = client.do_action_with_exception(request)
jsonObj = json.loads(response.decode("UTF-8"))
records = jsonObj["DomainRecords"]["Record"]
for each in records:
if each["RR"] == domain:
return each["RecordId"]
更新解析记录IP,DDNS逻辑核心
def DDNS():
client = Utils.getAcsClient()
recordId = Utils.getRecordId('ddns')
ip = Utils.getRealIP()
request = Utils.getCommonRequest()
request.set_domain('alidns.aliyuncs.com')
request.set_version('2015-01-09')
request.set_action_name('UpdateDomainRecord')
request.add_query_param('RecordId', recordId)
request.add_query_param('RR', 'ddns')
request.add_query_param('Type', 'A')
request.add_query_param('Value', ip)
response = client.do_action_with_exception(request)
return response
if __name__ == "__main__":
try:
result = DDNS()
print("成功!")
except (ServerException,ClientException) as reason:
print("失败!原因为")
print(reason.get_error_msg())
至此结束~然后设置好路由器端口映射,这时候你就可以使用ddns.example.com:XXX来进行访问设置在家庭网络中的资源了~
然后可以将这个Python代码设置为定时任务,比如每天执行一次,或者根据运营商的IP变化策略调整~
源码(最新):https://github.com/mgsky1/DDNS
源码(结构与文章一样的):点击这里
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python assert的用处示例详解
使用assert断言是学习python一个非常好的习惯,python assert 断言句语格式及用法很简单.在没完善一个程序之前,我们不知道程序在哪里会出错,与其让它在运行最崩溃,不如在出现错误条件时就崩溃,这时候就需要assert断言的帮助.本文主要是讲assert断言的基础知识. python assert断言的作用 python assert断言是声明其布尔值必须为真的判定,如果发生异常就说明表达示为假.可以理解assert断言语句为raise-if-not,用来测试表示式,其返回值为
-
Python批量删除只保留最近几天table的代码实例
Python批量删除table,只保留最近几天的table 代码如下: #!/usr/bin/python3 """ 批量删除table,只保留最近几天的table """ import pymysql import re def conn_(host='',usr='',passwd='',db='',port=3306,): conn = pymysql.connect(host, usr, passwd, db, port,charset=
-
Python3字符串encode与decode的讲解
大家好,很久没更新了,也是年底了最近比较忙,同时也在研究python的其他内容,毕竟是python小白,自学道路艰难. 好了今天和大家一起探讨下python3编码过程中对的一些转码事宜. python3中对文本和二进制做了比较清晰的区分.python3默认编码为unicode,由str类型进行表示.二进制数据使用byte类型表示,所以不会将str和byte混在一起.在实际应用中我们经常需要将两者进行互转 有几点需要注意: 1:字符串通过编码转换为字节码,字节码通过解码转换为字符串 str--->
-
python使用Plotly绘图工具绘制散点图、线形图
今天在研究Plotly绘制散点图的方法,供大家参考,具体内容如下 使用Python3.6 + Plotly Plotly版本2.0.0 在开始之前先说说,还需要安装库Numpy,安装方法在我的另一篇博客中有写到:python3.6下Numpy库下载与安装图文教程 因为Plotly没有自己独立的线性图形函数,所以把线性图形与散点图形全部用一个函数实现 这个函数是Scatter函数 下面举几个简单的例子 先画一个纯散点图,代码如下: import plotly import plotly.graph
-
python查询文件夹下excel的sheet名代码实例
本文实例为大家分享了python查询文件夹下excel的sheet的具体代码,供大家参考,具体内容如下 import os,sys,stat,xlrd path=r"F:\360Downloads" sheet = input("sheet name:") def del_file(path): ls = os.listdir(path) for i in ls: c_path = os.path.join(path, i) if os.path.isdir(c_p
-

彻底理解Python中的yield关键字
阅读别人的python源码时碰到了这个yield这个关键字,各种搜索终于搞懂了,在此做一下总结: 通常的for...in...循环中,in后面是一个数组,这个数组就是一个可迭代对象,类似的还有链表,字符串,文件.它可以是mylist = [1, 2, 3],也可以是mylist = [x*x for x in range(3)].它的缺陷是所有数据都在内存中,如果有海量数据的话将会非常耗内存. 生成器是可以迭代的,但只可以读取它一次.因为用的时候才生成.比如 mygenerator = (x*x
-
使用Python操作FTP实现上传和下载的方法
搭建ftp服务器server端 # -*- coding:utf-8 -*- from pyftpdlib.authorizers import DummyAuthorizer from pyftpdlib.handlers import FTPHandler from pyftpdlib.servers import FTPServer # 实例化DummyAuthorizer来创建ftp用户 authorizer = DummyAuthorizer() # 参数:用户名,密码,目录,权限 a
-
浅谈python的输入输出,注释,基本数据类型
1.输入与输出 python中输入与输出函数为:print.input help() 帮助的使用:help() help(print) print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False) Prints the values to a stream, or to sys.stdout by default. Optional keyword arguments: file: a file-like object (s
-
python环境路径配置以及命令行运行脚本
本文实例为大家分享了python环境路径设置方法,以及命令行运行python脚本,供大家参考,具体内容如下 找Python安装目录,设置环境路径以及在命令行运行python脚本 第一点:找Python安装目录 方法一: 方法二: 输入import sys print(sys.path) 化黑线处 第二点:找到安装目录后就可以开始设置环境变量 这里我的安装目录为C:\Program Files\Python36 再字符串的末尾,加一个分号; 然后再输入你安装python的路径,如图所示 一路点确定
-
Python使用os.listdir()和os.walk()获取文件路径与文件下所有目录的方法
在python3.6版本中去掉了os.path.walk()函数 os.walk() 函数声明:walk(top,topdown=True,oneerror=None) 1.参数top表示需要遍历的目录树的路径 2.参数农户topdown默认是"True",表示首先返回根目录树下的文件,然后,再遍历目录树的子目录.topdown的值为"False",则表示先遍历目录树的子目录,返回子目录下的文件,最后返回根目录下的文件 3.参数oneerror的默认值是"