python中学习K-Means和图片压缩
大家在学习python中,经常会使用到K-Means和图片压缩的,我们在此给大家分享一下K-Means和图片压缩的方法和原理,喜欢的朋友收藏一下吧。
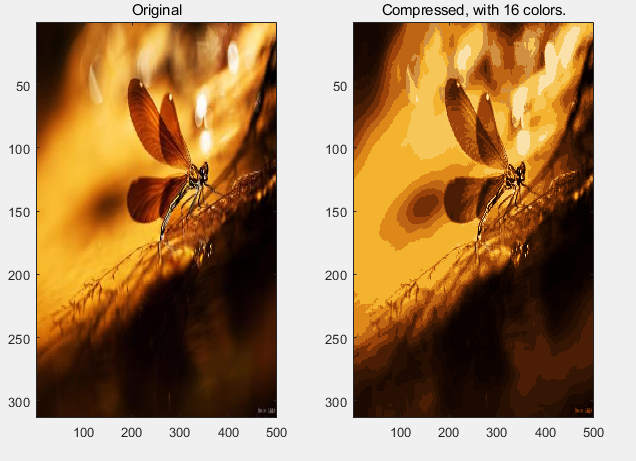
通俗的介绍这种压缩方式,就是将原来很多的颜色用少量的颜色去表示,这样就可以减小图片大小了。下面首先我先介绍下K-Means,当你了解了K-Means那么你也很容易的可以去理解图片压缩了,最后附上图片压缩的核心代码。
K-Means的核心思想

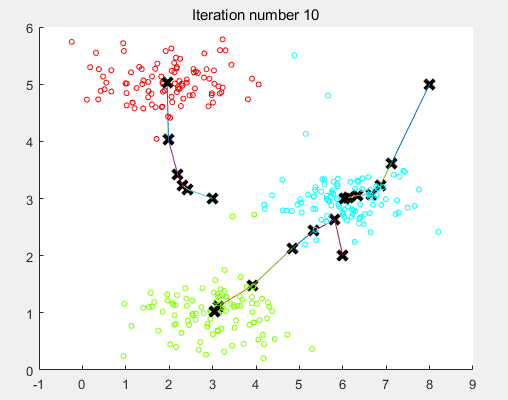
k-means的核心算法也就上面寥寥几句,下面将分三个部分来讲解:初始化簇中心、簇分配、簇中心移动。
初始化簇中心
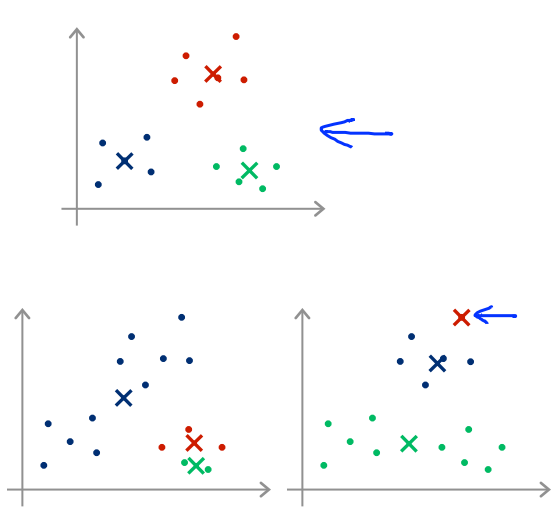
随机取簇中心若是不幸,会出现局部最优的情况;想要打破这种情况,需要多次取值计算来解决这种情况。
代价函数
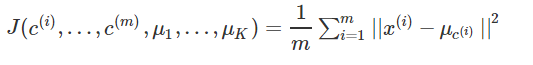
代码实现
J = zeros(100,1); M = size(X,1); min = inf; for i = 1:100 %随机取k个样本点作为簇中心 randidx = randperm(M); initial_centroids = X(randidx(1:K),:); %将所得的中心点进行训练 [centroids0, idx] = runkMeans(X, initial_centroids,10); for k = 1:M J(i) = J(i) + sum((X(k,:) - centroids0(idx(M),:)).^2); end %取最小代价为样本中心点 if(min > J(i)) centroids =centroids0; end end
簇分配
将样本点分配到离它最近的簇中心下
tmp = zeros(K,1); for i = 1:size(X,1) for j = 1:K tmp(j) = sum((X(i,:) - centroids(j,:)).^2); end [mins,index]=min(tmp); idx(i) = index; end
簇中心移动
取当前簇中心下所有样本点的均值为下一个簇中心
for i = 1:m centroids(idx(i),:) = centroids(idx(i),:) + X(i,:); end for j = 1:K centroids(j,:) = centroids(j,:)/sum(idx == j); end
图片压缩
% 加载图片
A = double(imread('dragonfly.jpg'));
% 特征缩减
A = A / 255;
img_size = size(A);
X = reshape(A, img_size(1) * img_size(2), 3);
K = 16;
max_iters = 10;
%开始训练模型
initial_centroids = kMeansInitCentroids(X, K);
[centroids, idx] = runkMeans(X, initial_centroids, max_iters);
%开始压缩图片
idx = findClosestCentroids(X, centroids);
X_recovered = centroids(idx,:);
X_recovered = reshape(X_recovered, img_size(1), img_size(2), 3);
%输出所压缩的图片
subplot(1, 2, 2);
imagesc(X_recovered)
相关推荐
-

python中实现k-means聚类算法详解
算法优缺点: 优点:容易实现 缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢 使用数据类型:数值型数据 算法思想 k-means算法实际上就是通过计算不同样本间的距离来判断他们的相近关系的,相近的就会放到同一个类别中去. 1.首先我们需要选择一个k值,也就是我们希望把数据分成多少类,这里k值的选择对结果的影响很大,Ng的课说的选择方法有两种一种是elbow method,简单的说就是根据聚类的结果和k的函数关系判断k为多少的时候效果最好.另一种则是根据具体的需求确定,比如说进行衬衫尺寸的聚
-
K-means聚类算法介绍与利用python实现的代码示例
聚类 今天说K-means聚类算法,但是必须要先理解聚类和分类的区别,很多业务人员在日常分析时候不是很严谨,混为一谈,其实二者有本质的区别. 分类其实是从特定的数据中挖掘模式,作出判断的过程.比如Gmail邮箱里有垃圾邮件分类器,一开始的时候可能什么都不过滤,在日常使用过程中,我人工对于每一封邮件点选"垃圾"或"不是垃圾",过一段时间,Gmail就体现出一定的智能,能够自动过滤掉一些垃圾邮件了.这是因为在点选的过程中,其实是给每一条邮件打了一个"标签&qu
-
Spark实现K-Means算法代码示例
K-Means算法是一种基于距离的聚类算法,采用迭代的方法,计算出K个聚类中心,把若干个点聚成K类. MLlib实现K-Means算法的原理是,运行多个K-Means算法,每个称为run,返回最好的那个聚类的类簇中心.初始的类簇中心,可以是随机的,也可以是KMean||得来的,迭代达到一定的次数,或者所有run都收敛时,算法就结束. 用Spark实现K-Means算法,首先修改pom文件,引入机器学习MLlib包: <dependency> <groupId>org.apache.
-
python中opencv K均值聚类的实现示例
目录 K均值聚类 K均值聚类的基本步骤 K均值聚类模块 简单例子 K均值聚类 预测的是一个离散值时,做的工作就是“分类”. 预测的是一个连续值时,做的工作就是“回归”. 机器学习模型还可以将训练集中的数据划分为若干个组,每个组被称为一个“簇(cluster)”.这种学习方式被称为“聚类(clusting)”,它的重要特点是在学习过程中不需要用标签对训练样本进行标注.也就是说,学习过程能够根据现有训练集自动完成分类(聚类). 根据训练数据是否有标签,可以将学习划分为监督学习和无监督学习. K近邻.
-
在python中利用opencv简单做图片比对的方法
下面代码中利用了两种比对的方法,一 对图片矩阵(m x m)求解特征值,通过比较特征值是否在一定的范围内,判断图片是否相同.二 对图片矩阵(m x m)中1求和,通过比较sum和来比较图片. # -*- coding: utf-8 -*- import cv2 as cv import numpy as np import os file_dir_a='C:\Users\wt\Desktop\data\image1\\' file_dir_b='C:\Users\wt\Desktop\data\
-
python 中值滤波,椒盐去噪,图片增强实例
受光照.气候.成像设备等因素的影响,灰度化后的图像存在噪声和模糊干扰,直接影响到下一步的文字识别,因此,需要对图像进行增强处理.图片预处理中重要一环就是椒盐去澡,通常用到中值滤波器进行处理,效果很好.中值滤波器是一种非线性滤波器,其基本原理是把数字图像中某点的值用其领域各点值的中值代替. 如求点[i,j]的灰度值计算方法为: (1)按灰度值顺序排列[i,j]领域中的像素点: (2)取排序像素集的中间值作为[i,j]的灰度值.中值滤波技术能有效抑制噪声. 直接上代码,希望给大家有帮助: impor
-
利用Python中Rembg库实现去除图片背景
目录 安装 快速上手 命令行调用 在Python中使用 Python 的 Rembg 库可以去掉图片中的背景,效果如下: 安装 CPU版 pip install rembg GPU版 pip install rembg[gpu] 快速上手 命令行调用 安装成功后,可以在命令行中调动Rembg.如果只对单个图片进行处理 rembg i path/to/input.png path/to/output.png 对多个图片文件处理(批处理), rembg p path/to/input path/to
-
python中学习K-Means和图片压缩
大家在学习python中,经常会使用到K-Means和图片压缩的,我们在此给大家分享一下K-Means和图片压缩的方法和原理,喜欢的朋友收藏一下吧. 通俗的介绍这种压缩方式,就是将原来很多的颜色用少量的颜色去表示,这样就可以减小图片大小了.下面首先我先介绍下K-Means,当你了解了K-Means那么你也很容易的可以去理解图片压缩了,最后附上图片压缩的核心代码. K-Means的核心思想 k-means的核心算法也就上面寥寥几句,下面将分三个部分来讲解:初始化簇中心.簇分配.簇中心移动. 初始化
-
python tensorflow学习之识别单张图片的实现的示例
假设我们已经安装好了tensorflow. 一般在安装好tensorflow后,都会跑它的demo,而最常见的demo就是手写数字识别的demo,也就是mnist数据集. 然而我们仅仅是跑了它的demo而已,可能很多人会有和我一样的想法,如果拿来一张数字图片,如何应用我们训练的网络模型来识别出来,下面我们就以mnist的demo来实现它. 1.训练模型 首先我们要训练好模型,并且把模型model.ckpt保存到指定文件夹 saver = tf.train.Saver() saver.save(s
-
Python中使用PIL库实现图片高斯模糊实例
一.安装PIL PIL是Python Imaging Library简称,用于处理图片.PIL中已经有图片高斯模糊处理类,但有个bug(目前最新的1.1.7bug还存在),就是模糊半径写死的是2,不能设置.在源码ImageFilter.py的第160行: 所以,我们在这里自己改一下就OK了. 项目地址:http://www.pythonware.com/products/pil/ 二.修改后的代码 代码如下: 复制代码 代码如下: #-*- coding: utf-8 -*- from PIL
-
python中ImageTk.PhotoImage()不显示图片却不报错问题解决
发现问题 今天在使用ImageTk.photoImage()显示图片时,当把包含该函数放在自定义函数里时,不能正常显示,移到函数为又可正常显示,所以想到可能是变量不是全局性的缘故,改为全局变量后果然可正常显示,下面贴出前后代码对比 示例代码 ImageTk.photoImage()在自定义函数外使用(正常显示): ImageTk.photoImage()在自定义函数内使用(无法显示): ImageTk.photoImage()在自定义函数内使用(正常显示): 完整代码: 总结 以上就是这篇文章的
-
python中kmeans聚类实现代码
k-means算法思想较简单,说的通俗易懂点就是物以类聚,花了一点时间在python中实现k-means算法,k-means算法有本身的缺点,比如说k初始位置的选择,针对这个有不少人提出k-means++算法进行改进:另外一种是要对k大小的选择也没有很完善的理论,针对这个比较经典的理论是轮廓系数,二分聚类的算法确定k的大小,在最后还写了二分聚类算法的实现,代码主要参考机器学习实战那本书: #encoding:utf-8 ''''' Created on 2015年9月21日 @author: Z
-
在Python中使用pngquant压缩png图片的教程
说到png图片压缩,可能很多人知道TinyPNG这个网站.但PS插件要钱(虽然有破解的),Developer API要连到他服务器去,不提网络传输速度,Key也是有每月限制的. 但是貌似tinyPNG是使用了来自于 pngquant 的技术,至少在 http://pngquant.org/ 中是如此声称的:TinyPNG and Kraken.io - on-line interfaces for pngquant.如果真是这样,我很想对TinyPNG说呵呵.后者是开源的,连首