java String源码和String常量池的全面解析
1. String 介绍,常用方法源码分析
2. String 常量池分析
常用方法
equals
trim
replace
concat
split
startsWith 和 endsWith
substring
toUpperCase() 和 toLowerCase()
compareTo
String 介绍
String类被final所修饰,也就是说String对象是不可变量,并发程序最喜欢不可变量了。String类实现了Serializable, Comparable, CharSequence接口。
从一段代码说起:
public void stringTest(){
String a = "a"+"b"+1;
String b = "ab1";
System.out.println(a == b);
}
大家猜一猜结果如何?如果你的结论是true。好吧,再来一段代码:
public void stringTest(){
String a = new String("ab1");
String b = "ab1";
System.out.println(a == b);
}
结果如何呢?正确答案是false。
让我们看看经过编译器编译后的代码如何
//第一段代码
public void stringTest() {
String a = "ab1";
String b = "ab1";
System.out.println(a == b);
}
//第二段代码
public void stringTest() {
String a1 = new String("ab1");
String b = "ab1";
System.out.println(a1 == b);
}
也就是说第一段代码经过了编译期优化,原因是编译器发现"a"+"b"+1和"ab1"的效果是一样的,都是不可变量组成。但是为什么他们的内存地址会相同呢?如果你对此还有兴趣,那就一起看看String类的一些重要源码吧。
源码
一、 String属性
String类中包含一个不可变的char数组用来存放字符串,一个int型的变量hash用来存放计算后的哈希值。
/** The value is used for character storage. */ private final char value[]; /** Cache the hash code for the string */ private int hash; // Default to 0 /** use serialVersionUID from JDK 1.0.2 for interoperability */ private static final long serialVersionUID = -6849794470754667710L;
二、 String构造函数
//不含参数的构造函数,一般没什么用,因为value是不可变量
public String() {
this.value = new char[0];
}
//参数为String类型
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
//参数为char数组,使用java.utils包中的Arrays类复制
public String(char value[]) {
this.value = Arrays.copyOf(value, value.length);
}
//从bytes数组中的offset位置开始,将长度为length的字节,以charsetName格式编码,拷贝到value
public String(byte bytes[], int offset, int length, String charsetName)
throws UnsupportedEncodingException {
if (charsetName == null)
throw new NullPointerException("charsetName");
checkBounds(bytes, offset, length);
this.value = StringCoding.decode(charsetName, bytes, offset, length);
}
//调用public String(byte bytes[], int offset, int length, String charsetName)构造函数
public String(byte bytes[], String charsetName)
throws UnsupportedEncodingException {
this(bytes, 0, bytes.length, charsetName);
}
三、 String常用方法
1. equals
boolean equals(Object anObject)
public boolean equals(Object anObject) {
//如果引用的是同一个对象,返回真
if (this == anObject) {
return true;
}
//如果不是String类型的数据,返回假
if (anObject instanceof String) {
String anotherString = (String) anObject;
int n = value.length;
//如果char数组长度不相等,返回假
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
//从后往前单个字符判断,如果有不相等,返回假
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
//每个字符都相等,返回真
return true;
}
}
return false;
}
String e1 = "good"; String e2 = "good everyDay"; e1.equals(e2); // 返回 false
1 首先判断是否 引用同一个对象 == 也就是判断 这两个引用的 内存地址是否相同,如果相同 直接返回 true
2 会判断是否类型 相同,是否是同一种数据类型
3 类型 相同 就会比较 转换成的 字符 数组的长度 是否相同
4 从后往前 比较 每一个字符 是否 相同
判断顺序 =》 1.内存地址 2.数据类型 3.字符数组长度 4.单个字符比较
2. compareTo
int compareTo(String anotherString)
public int compareTo(String anotherString) {
//自身对象字符串长度len1
int len1 = value.length;
//被比较对象字符串长度len2
int len2 = anotherString.value.length;
//取两个字符串长度的最小值lim
int lim = Math.min(len1, len2);
char v1[] = value;
char v2[] = anotherString.value;
int k = 0;
//从value的第一个字符开始到最小长度lim处为止,如果字符不相等,返回自身(对象不相等处字符-被比较对象不相等字符)
while (k < lim) {
char c1 = v1[k];
char c2 = v2[k];
if (c1 != c2) {
return c1 - c2;
}
k++;
}
//如果前面都相等,则返回(自身长度-被比较对象长度)
return len1 - len2;
}
String co1 = "hello" ; String co2 = "hello"; String co3 = "hello you"; System.out.println(co1.compareTo(co2)); // 0 System.out.println(co1.compareTo(co3)); // -4
这个方法写的很巧妙,先从0开始判断字符大小。
如果两个对象能比较字符的地方比较完了还相等,就直接返回自身长度减被比较对象长度,如果两个字符串长度相等,则返回的是0,巧妙地判断了三种情况。
3.hashCode
int hashCode()
public int hashCode() {
int h = hash;
//如果hash没有被计算过,并且字符串不为空,则进行hashCode计算
if (h == 0 && value.length > 0) {
char val[] = value;
//计算过程
//s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
//hash赋值
hash = h;
}
return h;
}
String a = "toyou"; char val[] = a.toCharArray(); char c1 = 't'; char c2 = 'a'; int f = c1; int e = c2; System.out.println(e); // 97 a System.out.println(f); // 116 t System.out.println(31*val[0]); // 3596 System.out.println(31*c1); // 3596 // hashCode 计算中 因为char 字符可以自动转换成对应的 int 整形
String类重写了hashCode方法,Object中的hashCode方法是一个Native调用。
String类的hash采用多项式计算得来,我们完全可以通过不相同的字符串得出同样的hash,所以两个String对象的hashCode相同,并不代表两个String是一样的。
同一个String 对象 hashCode 一定相同, 但是 hashCode相同 ,不一定是同一个对象
4.startsWith
boolean startsWith(String prefix,int toffset)
public boolean startsWith(String prefix, int toffset) {
char ta[] = value;
int to = toffset;
char pa[] = prefix.value;
int po = 0;
int pc = prefix.value.length;
// Note: toffset might be near -1>>>1.
//如果起始地址小于0或者(起始地址+所比较对象长度)大于自身对象长度,返回假
if ((toffset < 0) || (toffset > value.length - pc)) {
return false;
}
//从所比较对象的末尾开始比较
while (--pc >= 0) {
if (ta[to++] != pa[po++]) {
return false;
}
}
return true;
}
public boolean startsWith(String prefix) {
return startsWith(prefix, 0);
}
public boolean endsWith(String suffix) {
return startsWith(suffix, value.length - suffix.value.length);
}
String d = "www.58fxp.com";
System.out.println(d.startsWith("www")); // true
System.out.println(d.endsWith("com")); // true
起始比较和末尾比较都是比较经常用得到的方法,例如在判断一个字符串是不是http协议的,或者初步判断一个文件是不是mp3文件,都可以采用这个方法进行比较。
5.concat
String concat(String str)
public String concat(String str) {
int otherLen = str.length();
//如果被添加的字符串为空,返回对象本身
if (otherLen == 0) {
return this;
}
int len = value.length;
char buf[] = Arrays.copyOf(value, len + otherLen);
str.getChars(buf, len);
return new String(buf, true);
}
String cat = "much";
String newcat = cat.concat(" yes"); // much yes
concat方法也是经常用的方法之一,它先判断被添加字符串是否为空来决定要不要创建新的对象。
1 如果 拼接的字符 长度为0 直接返回 原字符对象
2 拼接的字符 不为空 返回 新的 字符对象
判断字符长度 生成新对象
6.replace
String replace(char oldChar,char newChar)
public String replace(char oldChar, char newChar) {
//新旧值先对比
if (oldChar != newChar) {
int len = value.length;
int i = -1;
char[] val = value; /* avoid getfield opcode */
//找到旧值最开始出现的位置
while (++i < len) {
if (val[i] == oldChar) {
break;
}
}
//从那个位置开始,直到末尾,用新值代替出现的旧值
if (i < len) {
char buf[] = new char[len];
for (int j = 0; j < i; j++) {
buf[j] = val[j];
}
while (i < len) {
char c = val[i];
buf[i] = (c == oldChar) ? newChar : c;
i++;
}
return new String(buf, true);
}
}
return this;
}
String r1 = "how do you do";
String r2 = r1.replace("do","is");
System.out.println(r2); // how is you is
这个方法也有讨巧的地方,例如最开始先找出旧值出现的位置,这样节省了一部分对比的时间。
replace(String oldStr,String newStr)方法通过正则表达式来判断。
7.trim
String trim()
public String trim() {
int len = value.length;
int st = 0;
char[] val = value; /* avoid getfield opcode */
//找到字符串前段没有空格的位置
while ((st < len) && (val[st] <= ' ')) {
st++;
}
//找到字符串末尾没有空格的位置
while ((st < len) && (val[len - 1] <= ' ')) {
len--;
}
//如果前后都没有出现空格,返回字符串本身
return ((st > 0) || (len < value.length)) ? substring(st, len) : this;
}
String t1 = " public void "; // 前后各一个空格
System.out.println("t1:"+t1.length()); // 13 带空格长度
String t2 = t1.trim();
System.out.println("t2:"+t2.length()); // 11 去掉空格
System.out.println(t2);
8.intern
String intern() public native String intern();
String dd = new String("bb").intern();
ntern方法是Native调用,它的作用是在方法区中的常量池里通过equals方法寻找等值的对象,
如果没有找到则在常量池中开辟一片空间存放字符串并返回该对应String的引用,否则直接返回常量池中已存在String对象的引用。
可以为new方法创建的 字符对象 也去强制查看常量池 是否已存在
将引言中第二段代码
//String a = new String("ab1");
//改为
String a = new String("ab1").intern();
则结果为为真,原因在于a所指向的地址来自于常量池,而b所指向的字符串常量默认会调用这个方法,所以a和b都指向了同一个地址空间。
int hash32()
private transient int hash32 = 0;
int hash32() {
int h = hash32;
if (0 == h) {
// harmless data race on hash32 here.
h = sun.misc.Hashing.murmur3_32(HASHING_SEED, value, 0, value.length);
// ensure result is not zero to avoid recalcing
h = (0 != h) ? h : 1;
hash32 = h;
}
return h;
}
在JDK1.7中,Hash相关集合类在String类作key的情况下,不再使用hashCode方式离散数据,而是采用hash32方法。
这个方法默认使用系统当前时间,String类地址,System类地址等作为因子计算得到hash种子,通过hash种子在经过hash得到32位的int型数值。
public int length() {
return value.length;
}
public String toString() {
return this;
}
public boolean isEmpty() {
return value.length == 0;
}
public char charAt(int index) {
if ((index < 0) || (index >= value.length)) {
throw new StringIndexOutOfBoundsException(index);
}
return value[index];
}
以上是一些简单的常用方法。
总结
String对象是不可变类型,返回类型为String的String方法每次返回的都是新的String对象,除了某些方法的某些特定条件返回自身。
String对象的三种比较方式:
==内存比较:直接对比两个引用所指向的内存值,精确简洁直接明了。
equals字符串值比较:比较两个引用所指对象字面值是否相等。
hashCode字符串数值化比较:将字符串数值化。两个引用的hashCode相同,不保证内存一定相同,不保证字面值一定相同。
字符串常量池的设计思想
一.字符串常量池设计初衷
每个字符串都是一个String对象,系统开发中将会频繁使用字符串,如果像其他对像那样创建销毁将极大影响程序的性能。
JVM为了提高性能和减少内存开销,在实例化字符串的时候进行了优化
为字符串开辟了一个字符串常量池,类似于缓存区
创建字符串常量时,首先判断字符串常量池是否存在该字符串
存在该字符串返回引用实例,不存在,实例化字符串,放入池中
实现基础
实现该优化的基础是每个字符串常量都是final修饰的常量,不用担心常量池存在数据冲突
运行时实例创建的全局字符串常量池中有一个表,总是为池中每个唯一的字符串对象维护一个引用,这就意味着它们一直引用着字符串常量池中的对象,所以,在常量池中的这些字符串不会被垃圾收集器回收
堆、栈、方法区
了解字符串常量池,首先看一下 堆栈方法区
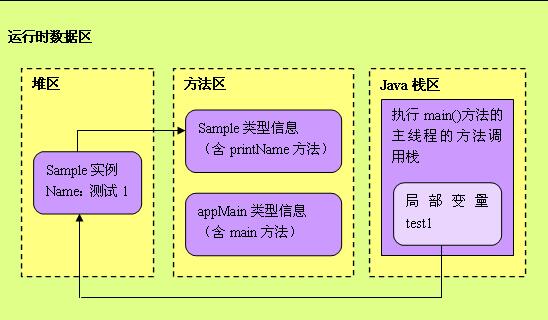
堆
存储的是对象,每个对象都包含一个与之对应的class
JVM只存在一个堆区,被所有线程共享,堆中不存在基本类型和对象引用,只存在对象本身
对象由垃圾回收器负责回收,因此大小和生命周期不需要确定
栈
每个线程都包含一个栈区,栈区只存放基础数据类型对象和自定义对象引用
每个栈中的数据(原始类型和对象引用)都是私有的
栈分为三个部分,基本类型变量区、执行环境上下文、操作指令区(存放操作指令)
数据大小和生命周期是可以确定的,当没有引用指向这个数据时,这个数据就会消失
方法区
静态区,跟堆一样,被所有的线程共享
方法区包含的都是在整个程序中永远唯一的元素,如class、static变量;
字符串常量池
字符串常量池存在于方法区
代码:堆栈方法区存储字符串
String str1 = “abc”; String str2 = “abc”; String str3 = “abc”; String str4 = new String(“abc”); String str5 = new String(“abc”);

面试题
String str4 = new String(“abc”) 创建多少个对象?
拆分: str4 = 、 new String()、"abc"
通过new 可以创建一个新的对象,new 方法创建实例化对象不会去常量池寻找是否已存在,只要new 都会实例化一个新的对象出来
"abc"每个字符串 都是一个String 对象,如果常量池中没有则会创建一个新对象放入常量池,否则返回对象引用
将对象地址赋值给str4,创建一个引用
所以,常量池中没有“abc”字面量则创建两个对象,否则创建一个对象,以及创建一个引用
String str1 = new String("A"+"B") ; 会创建多少个对象? String str2 = new String("ABC") + "ABC" ; 会创建多少个对象?
以上这篇java String源码和String常量池的全面解析就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Java常量池知识点总结
java常量池是一个经久不衰的话题,也是面试官的最爱,题目花样百出,这次好好总结一下. 理论 先拙劣的表达一下jvm虚拟内存分布: 程序计数器是jvm执行程序的流水线,存放一些跳转指令,这个太高深,不懂. 本地方法栈是jvm调用操作系统方法所使用的栈. 虚拟机栈是jvm执行java代码所使用的栈. 方法区存放了一些常量.静态变量.类信息等,可以理解成class文件在内存中的存放位置. 虚拟机堆是jvm执行java代码所使用的堆. Java中的常量池,实际上分为两种形态:静态常量池和运行时常量池.
-
深入探索Java常量池
Java的常量池通常分为两种:静态常量池和运行时常量池 静态常量池:class文件中的常量池,class文件中的常量池包括了字符串(数字)字面值,类和方法的信息,占用了class文件的大部分空间. 运行时常量池:JVM在完成加载类之后将class文件中常量池载入到内存中,并保存在方法区中.平时我们所讲的常量池就是指方法区中的运行时常量池.其相对于CLass文件常量池的另外一个重要特征是具备动态性,Java语言并不要求常量一定只有编译期才能产生,也就是并非预置入CLass文件中常量池的内容才能进入
-
java String类常量池分析及"equals"和"==”区别详细介绍
java "equals"和"=="异同 首先简单说一下"equal"和"==" ==操作对于基本数据类型比较的是两个变量的值是否相等, 对于引用型变量表示的是两个变量在堆中存储的地址是否相同, 即栈中的内容是否相同 equals操作表示的两个变量是否是对同一个对象的引用, 即堆中的内容是否相同. 综上,==比较的是2个对象的地址,而equals比较的是2个对象的内容. 再简单介绍一下String类 String类 又称作不可
-
Java中的字符串常量池详细介绍
Java中字符串对象创建有两种形式,一种为字面量形式,如String str = "droid";,另一种就是使用new这种标准的构造对象的方法,如String str = new String("droid");,这两种方式我们在代码编写时都经常使用,尤其是字面量的方式.然而这两种实现其实存在着一些性能和内存占用的差别.这一切都是源于JVM为了减少字符串对象的重复创建,其维护了一个特殊的内存,这段内存被成为字符串常量池或者字符串字面量池. 工作原理 当代码中出现字
-
浅谈java常量池
java常量池技术 java中常量池技术说的通俗点就是java级别的缓存技术,方便快捷的创建一个对象.当需要一个对象时,从池中去获取(如果池中没有,就创建一个并放入池中),当下次需要相同变量的时候,不用重新创建,从而节省空间. java八种基本类型的包装类和对象池 java中的基本类型的包装类.其中Byte.Boolean.Short.Character.Integer.Long实现了常量池技术,(除了Boolean,都只对小于128的值才支持) 比如,Integer对象 Integer i1
-
Java 中的字符串常量池详解
Java中的字符串常量池 Java中字符串对象创建有两种形式,一种为字面量形式,如String str = "droid";,另一种就是使用new这种标准的构造对象的方法,如String str = new String("droid");,这两种方式我们在代码编写时都经常使用,尤其是字面量的方式.然而这两种实现其实存在着一些性能和内存占用的差别.这一切都是源于JVM为了减少字符串对象的重复创建,其维护了一个特殊的内存,这段内存被成为字符串常量池或者字符串字面量池.
-
Java class文件格式之常量池_动力节点Java学院整理
常量池中各数据项类型详解 常量池中的数据项是通过索引来引用的, 常量池中的各个数据项之间也会相互引用.在这11中常量池数据项类型中, 有两种比较基础, 之所以说它们基础, 是因为这两种类型的数据项会被其他类型的数据项引用. 这两种数据类型就是CONSTANT_Utf8 和 CONSTANT_NameAndType , 其中CONSTANT_NameAndType类型的数据项(CONSTANT_NameAndType_info)也会引用CONSTANT_Utf8类型的数据项(CONSTANT_Ut
-
Java 常量池的实例详解
Java 常量池的实例详解 Java的常量池中包含了类.接口.方法.字符串等一系列常量值.常量池在编译期间就已经确定,并保存在*.class文件中 一.对于相同的常量值,常量池中只保存一份拷贝. 而且,当一个字符串由多个字符串常量链接而成时,多个字符串被组成一个字符串常量. 例如: package lxg; public class main { public static void main(String[] args) { String name = "lengxuegang";
-
java String源码和String常量池的全面解析
1. String 介绍,常用方法源码分析 2. String 常量池分析 常用方法 equals trim replace concat split startsWith 和 endsWith substring toUpperCase() 和 toLowerCase() compareTo String 介绍 String类被final所修饰,也就是说String对象是不可变量,并发程序最喜欢不可变量了.String类实现了Serializable, Comparable, CharSequ
-
Java String源码分析并介绍Sting 为什么不可变
Java String源码分析 什么是不可变对象? 众所周知, 在Java中, String类是不可变的.那么到底什么是不可变的对象呢? 可以这样认为:如果一个对象,在它创建完成之后,不能再改变它的状态,那么这个对象就是不可变的.不能改变状态的意思是,不能改变对象内的成员变量,包括基本数据类型的值不能改变,引用类型的变量不能指向其他的对象,引用类型指向的对象的状态也不能改变. 区分对象和对象的引用 对于Java初学者, 对于String是不可变对象总是存有疑惑.看下面代码: String s =
-
Java String源码contains题解重复叠加字符串匹配
目录 原题 解题思路 Java String contains 函数 原题 重复叠加字符串匹配 解题思路 解题思路已经写在代码中了: class Solution { public: bool contain(string &a, string &b, long long hash_b) { for (int i = 0; i <= a.size() - b.size(); i++) { int k = 0; long long hash_a = 0; while (k < b
-
java集合类源码分析之Set详解
Set集合与List一样,都是继承自Collection接口,常用的实现类有HashSet和TreeSet.值得注意的是,HashSet是通过HashMap来实现的而TreeSet是通过TreeMap来实现的,所以HashSet和TreeSet都没有自己的数据结构,具体可以归纳如下: •Set集合中的元素不能重复,即元素唯一 •HashSet按元素的哈希值存储,所以是无序的,并且最多允许一个null对象 •TreeSet按元素的大小存储,所以是有序的,并且不允许null对象 •Set集合没有ge
-
以武侠形式理解Java LinkedList源码
目录 一.LinkedList 的剖白 二.LinkedList 的内功心法 三.LinkedList 的招式 1)招式一:增 2)招式二:删 3)招式三:改 4)招式四:查 四.LinkedList 的挑战 一.LinkedList 的剖白 大家好,我是 LinkedList,和 ArrayList 是同门师兄弟,但我俩练的内功却完全不同.师兄练的是动态数组,我练的是链表. 问大家一个问题,知道我为什么要练链表这门内功吗? 举个例子来讲吧,假如你们手头要管理一推票据,可能有一张,也可能有一亿张
-
java学习之JVM运行时常量池理解
运行时常量池 运行时常量池是方法区的一部分.Class文件中除了有类的版本.字段.方法.接口等描述信息外,还有一项信息时常量池,用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后进入方法区的运行时常量池中存放. 运行时常量池相对于Class文件常量池的另外一个重要特征是具备动态性,Java语言并不要求常量一定只有编译期才能产生,也就是并非预置入Class文件中常量池的内容才能进入方法区运行时常量池,运行时常量池,运行期间也可能将新的常量放入池中,这种特性被开发人员利用比较多的就是S
-
Java从源码看异步任务计算FutureTask
目录 了解一下什么是FutureTask? FutureTask 是如何实现的呢? FutureTask 运行流程 FutureTask 的使用 前言: 大家是否熟悉FutureTask呢?或者说你有没有异步计算的需求呢?FutureTask就能够很好的帮助你实现异步计算,并且可以实现同步获取异步任务的计算结果.下面我们就一起从源码分析一下FutureTask. 了解一下什么是FutureTask? FutureTask 是一个可取消的异步计算. FutureTask提供了对Future的基本实
-
java TreeMap源码解析详解
java TreeMap源码解析详解 在介绍TreeMap之前,我们来了解一种数据结构:排序二叉树.相信学过数据结构的同学知道,这种结构的数据存储形式在查找的时候效率非常高. 如图所示,这种数据结构是以二叉树为基础的,所有的左孩子的value值都是小于根结点的value值的,所有右孩子的value值都是大于根结点的.这样做的好处在于:如果需要按照键值查找数据元素,只要比较当前结点的value值即可(小于当前结点value值的,往左走,否则往右走),这种方式,每次可以减少一半的操作,所以效率比较高
-
Java集合源码全面分析
Java集合工具包位于Java.util包下,包含了很多常用的数据结构,如数组.链表.栈.队列.集合.哈希表等.学习Java集合框架下大致可以分为如下五个部分:List列表.Set集合.Map映射.迭代器(Iterator.Enumeration).工具类(Arrays.Collections). 从上图中可以看出,集合类主要分为两大类:Collection和Map. Collection是List.Set等集合高度抽象出来的接口,它包含了这些集合的基本操作,它主要又分为两大部分:List和Se
-
Java HashMap源码深入分析讲解
1.HashMap是数组+链表(红黑树)的数据结构. 数组用来存放HashMap的Key,链表.红黑树用来存放HashMap的value. 2.HashMap大小的确定: 1) HashMap的初始大小是16,在下面的源码分析中会看到. 2)如果创建时给定大小,HashMap会通过计算得到1.2.4.8.16.32.64....这样的二进制位作为HashMap数组的大小. //如何做到的呢?通过右移和或运算,最终n = xxx11111.n+1 = xx100000,2的n次方,即为数组大小 s