Discuz!NT数据库读写分离方案详解
目前在Discuz!NT这个产品中,数据库作为数据持久化工具,必定在并发访问频繁且负载压力较大的情况下成 为系统性能的‘瓶颈'。即使使用本地缓存等方式来解决频繁访问数据库的问题,但仍旧会有大量的并发请求要访问动态数据,虽然 SQL2005及2008以上版本中性能不断提升,查询计划和存储过程运行得越来越高效,但最终还是 要面临‘瓶颈'这一问 题。当然这也是许多大型网站不断研究探索各式各样的方案来有效降低数据访问负荷的原 因, 其中的‘读写分离'方案就是一种被广泛采用的方案。
Discuz!NT这个产品在其企业版中提供了对‘读写分离'机制的支持,使对CPU及内存消耗严重的操作(CUD)被 分离到一台或几台性能很高的机器上,而将频繁读取的操作(select)放到几台配置较低的机器上,然后通过‘事务 发布订阅机制',实现了在多个sqlserver数据库之间快速高效同步数据,从而达到了将‘读写请求'按实际负载 情况进行均衡分布的效果。
下面就简要介绍一下其实现思路。注:有关数据同步的工具已在sqlserver中自带了,可以参考这篇文章。
将相应的数据由Master(主)数据库中‘发布'出来,然后使用推送的方式(注:事务发布可以指定是‘通过主 数据库推送' 还是‘订阅服务器去获取')发送到订阅它的数据库中,就实现了数据同步功能。
下面就介绍一下如何通过改变既有代码来实现在‘几个从数据库(类似快照)'间进行读取数据的负载均衡。
原有的代码中因为使用了分层机制,所以我们只要在‘数据访问层'动一下心思就可以了。在这里我的一个设 计思路就是不改变已有的数据库访问接口(包括参数等)的前提下,实现底层自动将现有的数据访问操作进行负载 均衡。这样做的好处不用多说了,同时也让这个负载均衡功能与数据访问层相分离,不要耦合的太紧密,同时如果不晓得底层 的实现原理也可以只通过一个开关(后面会介绍),就可以让自己的sql语句自动实现动态负载均衡。
说到这里,我来对照代码进一步阐述:
首先就是(Discuz.Data\DbHelper.cs)代码,主要变动如下(新增方法部分):
代码如下:
/// <summary>
/// 获取使用的数据库(或快照)链接串
/// </summary>
/// <param name="commandText">存储过程名或都SQL命令文本</param>
/// <returns></returns>
public static string GetRealConnectionString(string commandText)
{
if (DbSnapConfigs.GetConfig() != null && DbSnapConfigs.GetConfig().AppDbSnap)
{
commandText = commandText.Trim().ToLower();
if (commandText.StartsWith("select") || ((commandText.StartsWith(BaseConfigs.GetTablePrefix) && UserSnapDatabase(commandText))))
{
DbSnapInfo dbSnapInfo = GetLoadBalanceScheduling.GetConnectDbSnap();
if (DbSnapConfigs.GetConfig().RecordeLog && snapLogList.Capacity > snapLogList.Count)
snapLogList.Add(string.Format("{{'SouceID' : {0}, 'DbconnectString' : '{1}', 'CommandText' : '{2}', 'PostDateTime' : '{3}'}},",
dbSnapInfo.SouceID,
dbSnapInfo.DbconnectString,
commandText.Replace("'",""),
Discuz.Common.Utils.GetDateTime()));
return dbSnapInfo.DbconnectString;
}
}
return ConnectionString;
}
上面的方法将会对传入的sql语句进行分析,找出其中是CUD操作还是SELECT操作,来区别是读还是写操作。而snapLogList列表则是之前所配置的‘事务发布订阅'模式下的相关‘从数据库'(Slave Database)链接串的列表,例如(dbsnap.config文件的DbSnapInfoList节点):
代码如下:
<?xml version="1.0"?>
<DbSnapAppConfig xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<AppDbSnap>true</AppDbSnap>
<WriteWaitTime>1</WriteWaitTime>
<LoadBalanceScheduling>RoundRobinScheduling</LoadBalanceScheduling> --WeightedRoundRobinScheduling
<RecordeLog>false</RecordeLog>
<DbSnapInfoList>
<DbSnapInfo>
<SouceID>1</SouceID>
<Enable>true</Enable>
<DbconnectString>Data Source=DAIZHJ\DNT_DAIZHJ;User ID=sa;Password=123123;Initial Catalog=dnt_snap;Pooling=true</DbconnectString>
<Weight>4</Weight>
</DbSnapInfo>
<DbSnapInfo>
<SouceID>2</SouceID>
<Enable>true</Enable>
<DbconnectString>Data Source=DAIZHJ-PC\2222;User ID=sa;Password=123;Initial Catalog=tabletest;Pooling=true</DbconnectString>
<Weight>3</Weight>
</DbSnapInfo>
</DbSnapInfoList>
</DbSnapAppConfig>
有关相应配置节点和负载均衡算法会在后面提到,这里为了保持文章内容的连续性暂且跳过,下面接着浏览一下上面调用的‘UserSnapDatabase'方法:
代码如下:
/// <summary>
/// 是否使用快照数据库
/// </summary>
/// <param name="commandText">查询</param>
/// <returns></returns>
private static bool UserSnapDatabase(string commandText)
{
// 如果上次刷新cookie间隔小于5分钟, 则不刷新数据库最后活动时间
if (commandText.StartsWith(BaseConfigs.GetTablePrefix + "create"))
{
Utils.WriteCookie("JumpAfterWrite", Environment.TickCount.ToString());
return false;
}
else if (!String.IsNullOrEmpty(Utils.GetCookie("JumpAfterWrite")) && (Environment.TickCount - TypeConverter.StrToInt(Utils.GetCookie("JumpAfterWrite"), Environment.TickCount)) < DbSnapConfigs.GetConfig().WriteWaitTime * 1000)
return false;
else if (!commandText.StartsWith(BaseConfigs.GetTablePrefix + "get"))
return false;
return true;
}
该方法的作用很简单,就是当数据库有CUD操作时,通过写cookie的方式向客户端写一个键值‘JumpAfterWrite',这个键值很重要,就是提供一个标签(flag)来指示:‘当前用户执行cud操作时,页面跳转到其它页面而主数据库还没来得及将数据推送到从数据库'这一情况而造成的‘数据不同步'问题。
举了例子,当在一个版块中‘发表主题'后系统自动跳转到‘显示该主题页面'时,如果主数据库中插入了一个新主题而从数据库没有被及时更新这一主题信息时,就会报‘主题不存在'这个错误。所以这里加了一个设置,就是下面这一行:
代码如下:
(Environment.TickCount - TypeConverter.StrToInt(Utils.GetCookie("JumpAfterWrite"), Environment.TickCount)) < DbSnapConfigs.GetConfig().WriteWaitTime * 1000)
它所做的就是确保用户cud操作之后,在规定的时间内还是访问主数据库,当时间超过时,才将当前用户的访问请求(select)均衡到其它从数据库中。
当然,在GetRealConnectionString()方法中,还有一行代码很重要,就是下面这一行:
代码如下:
DbSnapInfo dbSnapInfo = GetLoadBalanceScheduling.GetConnectDbSnap();
它的作用就是加载配置文件信息,其中最主要的就是相应的‘负载均衡算法实例'来获取相应的从数据库链接串,下面先看一
下‘静态属性'GetLoadBalanceScheduling的相关信息:
/// <summary>
/// 负载均衡调度接口
/// </summary>
private static ILoadBalanceScheduling m_loadBalanceSche;
/// <summary>
/// 初始化负载均衡调度接口实例
/// </summary>
private static ILoadBalanceScheduling GetLoadBalanceScheduling
{
get
{
if (m_loadBalanceSche == null)
{
try
{
m_loadBalanceSche = (ILoadBalanceScheduling)Activator.CreateInstance(Type.GetType(string.Format("Discuz.EntLib.{0}, Discuz.EntLib", DbSnapConfigs.GetConfig().LoadBalanceScheduling), false, true));
}
catch
{
throw new Exception("请检查config/dbsnap.config中配置是否正确");
}
}
return m_loadBalanceSche;
}
}
它主要是通过反射的方法将Discuz.EntLib.dll文件中的相应负载均衡算法实例进行绑定,然后以m_loadBalanceSche这个静态变量进行保存,而m_loadBalanceSche本身就是ILoadBalanceScheduling接口变量,该接口即是相应负载均衡算法的实现接口。同样因为文章内容的连续性,这里先不深挖相应的实现算法,我会在后面进行介绍。下面再来看一下GetRealConnectionString()中还有一段代码,如下:
代码
代码如下:
if (DbSnapConfigs.GetConfig().RecordeLog && snapLogList.Capacity > snapLogList.Count)
snapLogList.Add(string.Format("{{'SouceID' : {0}, 'DbconnectString' : '{1}', 'CommandText' : '{2}', 'PostDateTime' : '{3}'}},",
dbSnapInfo.SouceID,
dbSnapInfo.DbconnectString,
commandText.Replace("'",""),
Discuz.Common.Utils.GetDateTime()));
return dbSnapInfo.DbconnectString;
上面代码将当前的负载均衡得到的链接串保存到一个snapLogList列表中,该列表声明如下:
代码如下:
List<string> snapLogList = new List<string>(400)
为什么要提供这个列表并进行记录?主要是为了考查负载均衡算法的工作情况,因为在数据访问层获取相应链接串信息并进行记录很不方便,所以我用这个变量记录大约400条‘负载均衡'数据链接串,以便在相应的Discuz.EntLib.ToolKit工具包中进行观察,监视其‘工作情况'。这里我们只要知道通过GetRealConnectionString()方法就实现了对sql语句或存储过程进行分析并进行负载均衡的效果了(注:该操作可能会耗时,所以在DbSnapConfigs中提供了一个开关‘RecordeLog'来进行控制,后面会介绍)。
下面再来简单介绍一下,如何改造DbHelper.cs中原有方法,使其支持负载均衡功能。这里强调一点,就是:
GetRealConnectionString()方法只是造了一个房子,里面的家具还是要自己搬。
而家具就是那些老的方法,比如:
public static object ExecuteScalar(DbConnection connection, CommandType commandType, string commandText, params DbParameter[] commandParameters)
{
if (connection == null) throw new ArgumentNullException("connection");
//connection.Close();
connection.ConnectionString = GetRealConnectionString(commandText);//负载均衡改造完成的方法
connection.Open();
// 创建DbCommand命令,并进行预处理
DbCommand cmd = Factory.CreateCommand();
bool mustCloseConnection = false;
PrepareCommand(cmd, connection, (DbTransaction)null, commandType, commandText, commandParameters, out mustCloseConnection);
// 执行DbCommand命令,并返回结果.
object retval = cmd.ExecuteScalar();
// 清除参数,以便再次使用.
cmd.Parameters.Clear();
if (mustCloseConnection)
connection.Close();
return retval;
}
上面的 ‘connection.ConnectionString ='之前绑定的ConnectionString这个静态属性,而这个属性链接的就是‘主数据库',
这里我们只要将GetRealConnectionString(commandText)赋值给它就可以了,还是那句话,在GetRealConnectionString()就实现了
数据库链接串的负载均衡,呵呵。类似上面的变动在DbHelper.cs还有几处,好在变化不太大,当然更不需要改变原有的数据访问层
(比如IDataProvider.cs文件)了。
其实本文中介绍的数据库层负载均衡实现方法在MYSQL中早有相应的插件实现了,参见这篇文章。 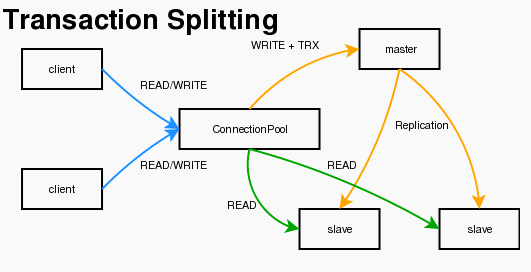
该文章中的LUA脚本实现方式与本文类似,如下:
--发送所有的非事务性SELECT到一个从数据库
代码如下:
if is_in_transaction == 0 and packet:byte() == proxy.COM_QUERY and packet:sub(2, 7) == "SELECT" then
local max_conns = -1
local max_conns_ndx = 0
for i = 1, #proxy.servers do
local s = proxy.servers[i]
-- 选择一个拥有空闲连接的从数据库
if s.type == proxy.BACKEND_TYPE_RO and s.idling_connections > 0 then
if max_conns == -1 or s.connected_clients < max_conns then
max_conns = s.connected_clients
max_conns_ndx = i
end
end
end
.....
接着,我再介绍一下相应的配置文件和负载均衡算法的实现情况:)
配置文件(比如:Discuz.EntLib.ToolKit\config\dbsnap.config):
代码
代码如下:
<?xml version="1.0"?>
<DbSnapAppConfig xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<AppDbSnap>true</AppDbSnap>
<WriteWaitTime>1</WriteWaitTime>
<LoadBalanceScheduling>RoundRobinScheduling</LoadBalanceScheduling> --WeightedRoundRobinScheduling
<RecordeLog>false</RecordeLog>
<DbSnapInfoList>
<DbSnapInfo>
<SouceID>1</SouceID>
<Enable>true</Enable>
<DbconnectString>Data Source=DAIZHJ\DNT_DAIZHJ;User ID=sa;Password=123123;Initial Catalog=dnt_snap;Pooling=true</DbconnectString>
<Weight>4</Weight>
</DbSnapInfo>
<DbSnapInfo>
<SouceID>2</SouceID>
<Enable>true</Enable>
<DbconnectString>Data Source=DAIZHJ-PC\2222;User ID=sa;Password=123;Initial Catalog=tabletest;Pooling=true</DbconnectString>
<Weight>3</Weight>
</DbSnapInfo>
<DbSnapInfo>
<SouceID>3</SouceID>
<Enable>true</Enable>
<DbconnectString>Data Source=DAIZHJ-PC\333333;User ID=sa;Password=123;Initial Catalog=tabletest;Pooling=true</DbconnectString>
<Weight>2</Weight>
</DbSnapInfo>
<DbSnapInfo>
<SouceID>4</SouceID>
<Enable>true</Enable>
<DbconnectString>Data Source=DAIZHJ-PC\44444444;User ID=sa;Password=123;Initial Catalog=tabletest;Pooling=true</DbconnectString>
<Weight>2</Weight>
</DbSnapInfo>
</DbSnapInfoList>
</DbSnapAppConfig>
上面的DbSnapInfoList就是相应的slave数据库链接列表,其中它的相应节点信息说明如下(Discuz.Config\DbSnapInfo.cs):
代码
代码如下:
[Serializable]
public class DbSnapInfo
{
/// <summary>
/// 源ID,用于唯一标识快照在数据库负载均衡中的信息
/// </summary>
private int _souceID;
/// <summary>
/// 源ID,用于唯一标识快照在数据库负载均衡中的信息
/// </summary>
public int SouceID
{
get { return _souceID; }
set { _souceID = value; }
}
/// <summary>
/// 快照是否有效
/// </summary>
private bool _enable;
/// <summary>
/// 是否有效
/// </summary>
public bool Enable
{
get { return _enable; }
set { _enable = value; }
}
/// <summary>
/// 快照链接
/// </summary>
private string _dbConnectString;
/// <summary>
/// 快照链接
/// </summary>
public string DbconnectString
{
get { return _dbConnectString; }
set { _dbConnectString = value; }
}
/// <summary>
/// 权重信息,该值越高则意味着被轮循到的次数越多
/// </summary>
private int _weight;
/// <summary>
/// 权重信息,该值越高则意味着被轮循到的次数越多
/// </summary>
public int Weight
{
get { return _weight; }
set { _weight = value; }
}
}
当然DbSnapAppConfig作为DbSnapInfo列表的容器,其结构如下:
代码
代码如下:
[Serializable]
public class DbSnapAppConfig : Discuz.Config.IConfigInfo
{
private bool _appDbSnap;
/// <summary>
/// 是否启用快照,如不使用,则即使DbSnapInfoList已设置有效快照信息也不会使用。
/// </summary>
public bool AppDbSnap
{
get { return _appDbSnap; }
set { _appDbSnap = value; }
}
private int _writeWaitTime = 6;
/// <summary>
/// 写操作等待时间(单位:秒), 说明:在执行完写操作之后,在该时间内的sql请求依旧会被发往master数据库
/// </summary>
public int WriteWaitTime
{
get { return _writeWaitTime; }
set { _writeWaitTime = value; }
}
private string _loadBalanceScheduling = "WeightedRoundRobinScheduling";
/// <summary>
/// 负载均衡调度算法,默认为权重轮询调度算法 http://www.pcjx.com/Cisco/zhong/209068.html
/// </summary>
public string LoadBalanceScheduling
{
get { return _loadBalanceScheduling; }
set { _loadBalanceScheduling = value; }
}
private bool _recordeLog = false;
/// <summary>
/// 是否记录日志
/// </summary>
public bool RecordeLog
{
get { return _recordeLog; }
set { _recordeLog = value; }
}
private List<DbSnapInfo> _dbSnapInfoList;
/// <summary>
/// 快照轮循列表
/// </summary>
public List<DbSnapInfo> DbSnapInfoList
{
get { return _dbSnapInfoList; }
set { _dbSnapInfoList = value; }
}
}
通过这两个配置文件,就可以实现对数据访问层负载均衡的灵活配置了,不过上面的DbSnapAppConfig还有一个非常重要的
属性没有介绍清楚,就是‘LoadBalanceScheduling',其接口声明如下:
代码
代码如下:
/// <summary>
/// 负载均衡调度接口
/// </summary>
public interface ILoadBalanceScheduling
{
/// <summary>
/// 获取应用当前负载均衡调度算法下的快照链接信息
/// </summary>
/// <returns></returns>
DbSnapInfo GetConnectDbSnap();
}
它就是负载均衡算法的实现接口,为了便于说明在Discuz.EntLib中内置的两个负载均衡算法的实现情况,请先看下图: 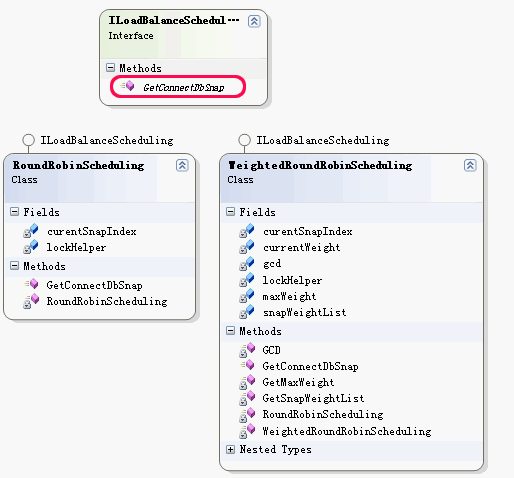
内置的两个负载均衡算法,一个是RoundRobinScheduling,即轮叫调度(Round Robin Scheduling)算法,它的实现比较简单,就是对从数据库链接列表的依次遍历,如下:
代码
代码如下:
/// <summary>
/// 轮叫调度(Round Robin Scheduling)算法
/// </summary>
public class RoundRobinScheduling : ILoadBalanceScheduling
{
private static object lockHelper = new object();
/// <summary>
/// 当前的快照索引和权重信息
/// </summary>
static int curentSnapIndex = 0;
static RoundRobinScheduling()
{}
public DbSnapInfo GetConnectDbSnap()
{
lock (lockHelper)
{
if (curentSnapIndex >= DbSnapConfigs.GetEnableSnapList().Count)
curentSnapIndex = (curentSnapIndex) % DbSnapConfigs.GetEnableSnapList().Count;
return DbSnapConfigs.GetEnableSnapList()[curentSnapIndex++];
}
}
}
而另一种负载均衡算法就相对负载了,不过它也更符合实际的应用场景,它使用了权重的方法来让性能优良的机器分到
更多的任务来均衡整个方案的性能,即权重轮询调度算法,实现代码如下:
代码
代码如下:
/// <summary>
/// 权重轮询调度算法
/// http://www.pcjx.com/Cisco/zhong/209068.html
/// http://id-phatman.spaces.live.com/blog/cns!CA763CA8DB2378D1!627.entry
/// </summary>
public class WeightedRoundRobinScheduling : ILoadBalanceScheduling
{
private static object lockHelper = new object();
/// <summary>
/// 快照的权重列表
/// </summary>
static List<int> snapWeightList = new List<int>();
/// <summary>
/// 当前的快照索引和权重信息
/// </summary>
static int curentSnapIndex, currentWeight;
/// <summary>
/// 快照权重列表中最大的权重值和最大公约数
/// </summary>
static int maxWeight, gcd;
static WeightedRoundRobinScheduling()
{
curentSnapIndex = -1;
currentWeight = 0;
snapWeightList = GetSnapWeightList();
maxWeight = GetMaxWeight(snapWeightList);
gcd = GCD(snapWeightList);
}
/// <summary>
/// 获取应用当前负载均衡调度算法下的快照链接信息
/// </summary>
/// <returns></returns>
public DbSnapInfo GetConnectDbSnap()
{
lock (lockHelper)
{
DbSnapInfo current = RoundRobinScheduling();
if (current != null)
return current;
else
return DbSnapConfigs.GetEnableSnapList()[0];
}
}
/// <summary>
/// 获取快照权重的列表
/// </summary>
/// <returns></returns>
static List<int> GetSnapWeightList()
{
List<int> snapWeightList = new List<int>();
foreach (DbSnapInfo dbSnapInfo in DbSnapConfigs.GetEnableSnapList())
{
snapWeightList.Add(dbSnapInfo.Weight);
}
return snapWeightList;
}
/// <summary>
/// 权重轮询调度算法
/// </summary>
static DbSnapInfo RoundRobinScheduling()
{
while (true)
{
curentSnapIndex = (curentSnapIndex + 1) % DbSnapConfigs.GetEnableSnapList().Count;
if (curentSnapIndex == 0)
{
currentWeight = currentWeight - gcd;
if (currentWeight <= 0)
{
currentWeight = maxWeight;
if (currentWeight == 0)
return null;
}
}
if (DbSnapConfigs.GetEnableSnapList()[curentSnapIndex].Weight >= currentWeight)
return DbSnapConfigs.GetEnableSnapList()[curentSnapIndex];
}
}
/// <summary>
/// 获取最大权重
/// </summary>
/// <param name="snapList"></param>
/// <returns></returns>
static int GetMaxWeight(List<int> snapWeightList)
{
int maxWeight = 0;
foreach (int snapWeight in snapWeightList)
{
if (maxWeight < snapWeight)
maxWeight = snapWeight;
}
return maxWeight;
}
/// <summary>
/// 获取权重的最大公约数
/// </summary>
/// <returns></returns>
static int GCD(List<int> snapWeightList)
{
// 排序,得到数字中最小的一个
snapWeightList.Sort(new WeightCompare());
int minNum = snapWeightList[0];
// 最大公约数肯定大于等于1,且小于等于最小的那个数。
// 依次整除,如果余数全部为0说明是一个约数,直到打出最大的那个约数
int gcd = 1;
for (int i = 1; i <= minNum; i++)
{
bool isFound = true;
foreach (int snapWeight in snapWeightList)
{
if (snapWeight % i != 0)
{
isFound = false;
break;
}
}
if (isFound)
gcd = i;
}
return gcd;
}
/// <summary>
/// 实现IComparer接口,用于对数字列表进行排序
/// </summary>
private class WeightCompare : System.Collections.Generic.IComparer<int>
{
public int Compare(int weightA, int weightB)
{
return weightA - weightB;
}
}
}
到这里,主要的功能代码就介绍的差不多了,我们可以通过对dbsnap.config的相应节点配置,来灵活定制我们的负载均衡方案。同时,对一般开发者而言,这种架构是透明的,大家可以完全在不了解它的情况下开发自己的数据访问功能,并通过相应开关来让自己的代码支持均衡负载。
当然这个方案还有一些没考虑到的问题比如:
1.对‘主从数据库的健康度检查',即如果主或从数据库出现故障的时候该如何处理,当然在sqlserver中还提供了镜像功能来解决类似问题,所以它也可做为一个备选方案。
2.当主数据库被发布出去后,主数据库的表和存储过程就会被‘锁定',其不允许被再次修改了,所以还要继续研究如何解决这一问题。
原文链接:http://www.cnblogs.com/daizhj/archive/2010/06/21/dbsnap_master_slave_database.html
作者: daizhj, 代震军
相关推荐
-

sql server2005实现数据库读写分离介绍
Internet的规模每一百天就会增长一倍,客户希望获得7天×24小时的不间断可用性及较快的系统反应时间,而不愿屡次看到某个站点"Server Too Busy"及频繁的系统故障. 随着业务量的提高,以及访问量和数据流量的快速增长,网络各个核心部分的处理性能和计算强度也相应增大,使得单一设备根本无法承担.在此情况下,如果扔掉现有设备去做大量的硬件升级,必将造成现有资源的浪费,而且下一次业务量的提升,又将导致再一次硬件升级的高额成本投入.于是,负载均衡机制应运而生. 对于负载均衡,笔者经
-
Discuz!NT数据库读写分离方案详解
目前在Discuz!NT这个产品中,数据库作为数据持久化工具,必定在并发访问频繁且负载压力较大的情况下成 为系统性能的'瓶颈'.即使使用本地缓存等方式来解决频繁访问数据库的问题,但仍旧会有大量的并发请求要访问动态数据,虽然 SQL2005及2008以上版本中性能不断提升,查询计划和存储过程运行得越来越高效,但最终还是 要面临'瓶颈'这一问 题.当然这也是许多大型网站不断研究探索各式各样的方案来有效降低数据访问负荷的原 因, 其中的'读写分离'方案就是一种被广泛采用的方案. Discuz
-
Spring AOP切面解决数据库读写分离实例详解
Spring AOP切面解决数据库读写分离实例详解 为了减轻数据库的压力,一般会使用数据库主从(master/slave)的方式,但是这种方式会给应用程序带来一定的麻烦,比如说,应用程序如何做到把数据写到master库,而读取数据的时候,从slave库读取.如果应用程序判断失误,把数据写入到slave库,会给系统造成致命的打击. 解决读写分离的方案很多,常用的有SQL解析.动态设置数据源.SQL解析主要是通过分析sql语句是insert/select/update/delete中的哪一种,从而对
-
Mysql主从复制与读写分离图文详解
文章思维导图 为什么使用主从复制.读写分离 主从复制.读写分离一般是一起使用的.目的很简单,就是为了提高数据库的并发性能. 你想,假设是单机,读写都在一台MySQL上面完成,性能肯定不高. 如果有三台MySQL,一台mater只负责写操作,两台salve只负责读操作,性能不就能大大提高了吗? 所以主从复制.读写分离就是为了数据库能支持更大的并发. 随着业务量的扩展.如果是单机部署的MySQL,会导致I/O频率过高. 采用主从复制.读写分离可以提高数据库的可用性. 主从复制的原理 ①当Master
-
go实现Redis读写分离示例详解
目录 我们为什么需要了解RESP协议? 什么是RESP协议 RESP协议规范 如何使用该协议请求Redis 使用go编写Redis中间件实现读写分离 总结 我们为什么需要了解RESP协议? 本篇文章目的为探究RESP协议,而非编写读写中间件,这点要清楚. 关于这个问题,我想通过一个实例来解释,我们编写Redis中间件,为什么需要了解RESP协议. 以上代码是编写了一个非常简单的TCP服务器,我们监听8888端口,尝试使用redis-cli -p 8888连接服务器后,而后查看打印出来的应用层报文
-
Spring+MyBatis实现数据库读写分离方案
推荐第四种 方案1 通过MyBatis配置文件创建读写分离两个DataSource,每个SqlSessionFactoryBean对象的mapperLocations属性制定两个读写数据源的配置文件.将所有读的操作配置在读文件中,所有写的操作配置在写文件中. 优点:实现简单 缺点:维护麻烦,需要对原有的xml文件进行重新修改,不支持多读,不易扩展 实现方式 <bean id="abstractDataSource" abstract="true" class=
-
MySQL 读写分离实例详解
MySQL 读写分离 MySQL读写分离又一好办法 使用 com.mysql.jdbc.ReplicationDriver 在用过Amoeba 和 Cobar,还有dbware 等读写分离组件后,今天我的一个好朋友跟我讲,MySQL自身的也是可以读写分离的,因为他们提供了一个新的驱动,叫 com.mysql.jdbc.ReplicationDriver 说明文档:http://dev.mysql.com/doc/refman/5.1/en/connector-j-reference-replic
-
详解如何利用amoeba(变形虫)实现mysql数据库读写分离
关于mysql的读写分离架构有很多,百度的话几乎都是用mysql_proxy实现的.由于proxy是基于lua脚本语言实现的,所以网上不少网友表示proxy效率不高,也不稳定,不建议在生产环境使用: amoeba是阿里开发的一款数据库读写分离的项目(读写分离只是它的一个小功能),由于是基于java编写的,所以运行环境需要安装jdk: 前期准备工作: 1.两个数据库,一主一从,主从同步: master: 172.22.10.237:3306 :主库负责写入操作: slave: 10.4.66.58
-
Mysql迁移到TiDB双写数据库兜底方案详解
目录 正文 兼容策略 三种方案比较 Django双写mysql与tidb策略 正文 TiDB 作为开源 NewSQL 数据库的典型代表之一,同样支持 SQL,支持事务 ACID 特性.在通讯协议上,TiDB 选择与 MySQL 完全兼容,并尽可能兼容 MySQL 的语法.因此,基于 MySQL 数据库开发的系统,大多数可以平滑迁移至 TiDB,而几乎不用修改代码.对用户来说,迁移成本极低,过渡自然. 然而,仍有一些 MySQL 的特性和行为,TiDB 目前暂时不支持或表现与 MySQL 有差异.
-
使用Spring AOP实现MySQL数据库读写分离案例分析(附demo)
一.前言 分布式环境下数据库的读写分离策略是解决数据库读写性能瓶颈的一个关键解决方案,更是最大限度了提高了应用中读取 (Read)数据的速度和并发量. 在进行数据库读写分离的时候,我们首先要进行数据库的主从配置,最简单的是一台Master和一台Slave(大型网站系统的话,当然会很复杂,这里只是分析了最简单的情况).通过主从配置主从数据库保持了相同的数据,我们在进行读操作的时候访问从数据库Slave,在进行写操作的时候访问主数据库Master.这样的话就减轻了一台服务器的压力. 在进行读写分离
-
Redis的持久化方案详解
Redis支持RDB与AOF两种持久化机制,持久化可以避免因进程异常退出或down机导致的数据丢失问题,在下次重启时能利用之前的持久化文件实现数据恢复. RDB持久化 RDB持久化即通过创建快照(压缩的二进制文件)的方式进行持久化,保存某个时间点的全量数据.RDB持久化是Redis默认的持久化方式.RDB持久化的触发包括手动触发与自动触发两种方式. 手动触发 save, 在命令行执行save命令,将以同步的方式创建rdb文件保存快照,会阻塞服务器的主进程,生产环境中不要用 bgsave, 在命令