Hadoop2.X/YARN环境搭建--CentOS7.0系统配置
一、我缘何选择CentOS7.0
14年7月7日17:39:42发布了CentOS 7.0.1406正式版,我曾使用过多款Linux,对于Hadoop2.X/YARN的环境配置缘何选择CentOS7.0,其原因有:
1、界面采用RHEL7.0新的GNOME界面风,这可不是CentOS6.5/RHEL6.5所能比的!(当然,Fedora早就采用这种风格的了,但是现在的Fedora缺包已然不成样子了)
2、曾经,我也用了RHEL7.0,它最大的问题就是YUM没法用,而且总会有Warning提示注册购买!为此,必须去修改YUM源,还有修改其他的文件使之不提示才能用,看了这么麻烦,想必有很多童鞋滴心就已经凉了4/7了吧!
3、当然,Ubuntu系列我用过Ubuntu14.04/12.04和elementaryOS,不知为何,一用Ubuntu14.04就觉得好丑呀!!但是有很多人都说CentOS和RHEL更丑,但殊不知哪个才是企业级的,那个才是霸主。
另一方面,要求视觉效果的话,建议去装个elementaryOS试试,当然,elementaryOS也有缺陷:它已经许久没有提供更新了,12年推出的,已逾2年未曾发布新版本的系统,也未曾更新网站,与此同时,elementaryOS的模型Ubuntu早就更新换代了,所以,暴露了不少问题,其中麻烦的是不要随意更新系统,否则黑屏,那就真的纯命令行了,漂亮的系统突然被打回原型,那心铁定疤凉疤凉的,而且它更新后的apt-get是无法安装某些匹配某些,所以elementaryOS只供欣赏把玩!
4、也有人用过openSUSE,据说是最华丽的系统,在我看来,花哨的KDE打开文件/软件时显示的一跳一跳的,我心里就痒痒的,没事儿你弄个没用又难看的东东干嘛??干嘛??另外,最新的openSUSE对中文的设计的确无法令人满意。另外,就是openSUSE的环境不怎么熟悉,欧洲人设计的GNU/Linux还有些难适应,当然,我也不打算改旗易帜向欧洲SUSE倒戈。
其实,GNU/Linux版本众多,选择一个适合自己的一款一直玩下去、用下去就足够了,Linux版本众多,设计各有千秋,但使用大同小异,了解“异”点即可!当然,还是奉劝一句:初学者仅仅跑跑虚拟机看看效果就好,莫要将每款都用会了!毕竟,体验也是学习的动力之一!
二、体验CentOS7与之前版本的“异”
初次启动
装完机后,开机进系统的界面换了,乍一看以为是两个内核,原来有一个是rescue选择,而且按e后,会发现所有的grub.conf的信息全出来了,好不容易找到内核启动的地方,写了个 1(要进单用户模式),然后进了rescue模式。
字符界面
进系统后,是图形界面,想进字符界面,结果找到/etc/inittab,发现几乎是个空文件,文件中提示想改runlevel的话,可以把/lib/systemd/system/runlevel*.target 软连到 /etc/systemd/system/default.target下(当然考过来,覆盖也行),试了一下还行,能改到字符界面runlevel3。
配置网络和主机名
然后,想配置网络,进/etc/sysconfig/network-script/一看,我靠,网卡改名了enp1s5,好有趣,配置完网络后改主机名, 到/etc/sysconfig/network去改名字,发现这个文件也是空的,按原6版本的去修改,重启后没效果,man了一下hostname, 发现7中改名要到/etc/hostname去改名字。
本地yum源和挂载
接着,想配置一个本地yum源,配上后要挂光盘,手动挂上了,然后直接echo“mount ......”到rc.local中,毕竟是启动执行脚本,重启之后竟然没挂上,进去rc.local中看了一下,7中竟然要手动的把chmod +x rc.local, 是的,要手动加执行权限,难道我之前装的6以前的系统中这个都要手动加执行权限,我不记得啊!!!! 当然,加了权限后,开机后启动执行了rc.local的mount命令。
LVM和xfs
后来,想着装一个lvm玩玩,于是啊就分区,格式化(特意格式化为了xfs),pv,vg,lv一步一步,都没问题,然后想着放大,缩小,这时出问题了,执行resize2fs时,怎么一直报superblock什么的出错,这是怎么回事,然后man resize2fs一下,发现这命令只支持ext的文件系统,我艹,那我装系统是怎么是lvm的,这个问题我还没解决,应该有解决方法。
dhcp和服务
接着,想着装一个dhcp玩玩,惊奇的发现所有dhcp的包装上之后,不能service dhcpd start,然后发现/etc/init.d/中竟然没一个dhcp类似的东西,毕竟6之前有dhcpd,dhcpd6,dhcrelay的,然后发现 /sbin/dhcpd有启动文件,难道,难道,以后的服务想service启,都要手动自己编?错了,是在/usr/lib/systemd/system/dhcpd.service,还要修改好多,然后加权限,执行service 服务 restart/stop。。。。。。可以,但是指向了systemctl restart/start/stop 服务.service
iptables
又发现iptables这次也不是作为一个服务在/etc/init.d/下面了,/sbin下有;
防火墙由iptables更换成了firewalld
三、系统配置之关闭防火墙
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
systemctl命令的基本操作格式是:
systemctl 动作 服务名.service动作:start,stop,restart,status,enable,disable,is-enabled
四、配置Linux网络
1、修改hostname
CentOS 7.0的hostname在/etc/hostname中用root用户修改:
[root@hadoop1 ~]# vim /etc/hostname #编辑/etc/hostname[root@hadoop1 ~]# cat /etc/hostname #查看/etc/hostnamehadoop1[root@hadoop1 ~]#
以前版本的CentOS在/etc/sysconfig/network中用root用户修改:
[root@hadoop1 ~]# vim /etcsysconfig/network

"/etc/sysconfig/network"的设定项目如下:
NETWORKING 是否利用网络GATEWAY 默认网关与接下来配置IP的属性文件中默认网关一致IPGATEWAYDEV 默认网关的接口名HOSTNAME 主机名DOMAIN 域名
reboot后hostname生效
2、修改当前机器的IP
Step1:进入配置文件目录
现在已经是root权限了,我们cd到网络配置文件的目录,并列出目录下的文件。

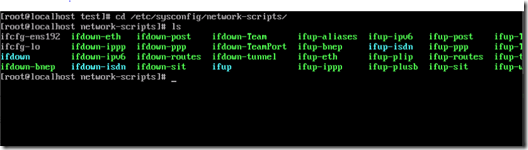
Step2:修改配置文件
该目录下,文件名“ifcfg-ens192”文件就是网络配置的主文件。vi它!
修改或添加一下:
ONBOOT=yes BOOTPROTO=static IPADDR=IP地址 NETMASK=255.255.255.0 #子网掩码 GATEWAY=192.168.30.1 #网关地址
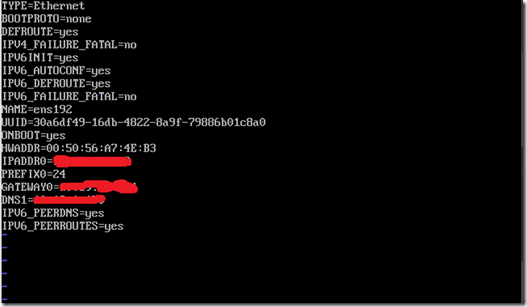
Step3:重启网络服务
修改完配置文件后,:wq!保存退出!然后重启网络。

Step4:测试
通过ifconfig命令查看ip是否设置成功,然后ping一下网络。这个时候应该成功了!
3、修改DNS(看情况,非必选)
若网络环境有DNS要求,则配置,否则,勿配!
格式:
nameserver DNS地址
[root@hadoop1 ~]# vi /etc/resolv.conf nameserver 202.131.80.1 #依需求而定 nameserver 202.131.80.5 #依需求而定
4、配置hosts文件
"/etc/hosts"这个文件是用来配置主机将用的DNS服务器信息,是记载LAN内接续的各主机的对应[HostName和IP]用的。当用户在进行网络连接时,首先查找该文件,寻找对应主机名(或域名)对应的IP地址。
我们要测试两台机器之间知否连通,一般用"ping 机器的IP",如果想用"ping 机器的主机名"发现找不见该名称的机器,解决的办法就是修改"/etc/hosts"这个文件,通过把LAN内的各主机的IP地址和HostName的一一对应写入这个文件的时候,就可以解决问题。
例如:机器为"hadoop1:59.67.107.80"对机器为"hadoop2:59.67.107.79"用命令"ping"记性连接测试。测试结果如下:
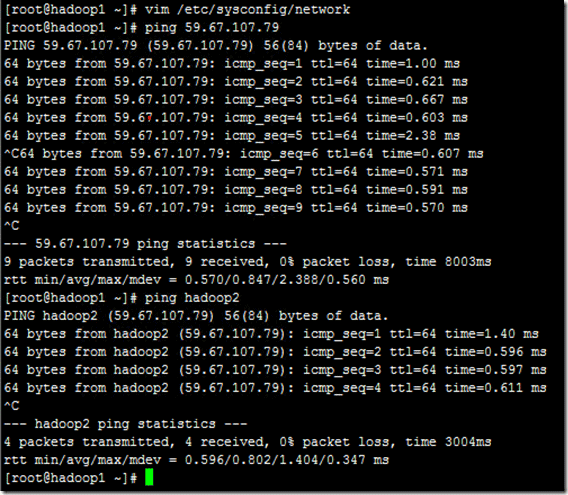
从上图中的值,直接对IP地址进行测试,能够ping通,但是对主机名进行测试,若没有ping通,提示"unknown host——未知主机",这时查看"hadoop1"的"/etc/hosts"文件内容。
若ping hadoop1不通则显示:

若ping hadoop1通则显示:
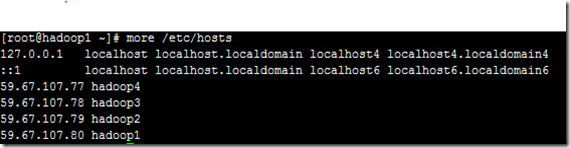
若发现里面没有"59.67.107.79 hadoop2"内容,故而本机器是无法对机器的主机名为"hadoop2" 解析。
在进行Hadoop集群配置中,需要在"/etc/hosts"文件中添加集群中所有机器的IP与主机名,这样Master与所有的Slave机器之间不仅可以通过IP进行通信,而且还可以通过主机名进行通信。所以在所有的机器上的"/etc/hosts"文件末尾中都要添加如下内容:
因为本文以已经配置好的环境说明,所以我的/etc/hosts显示:

一般处于内网下,照此添加(192.168.1.1为网关):
192.168.1.2 hadoop1 192.168.1.3 hadoop2 192.168.1.4 hadoop3 192.168.1.5 hadoop4
用以下命令进行添加:
vim /etc/hosts
现在我们在进行对机器为"hadoop2"的主机名进行ping通测试,看是否能测试成功。
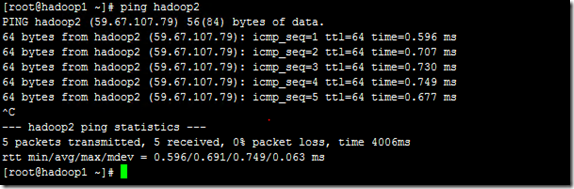
从上图中我们已经能用主机名进行ping通了,说明我们刚才添加的内容,在局域网内能进行DNS解析了,那么现在剩下的事儿就是在其余的Slave机器上进行相同的配置。然后进行测试。
相关推荐
-
hadoop中一些常用的命令介绍
假设Hadoop的安装目录HADOOP_HOME为/home/admin/hadoop.启动与关闭启动Hadoop1.进入HADOOP_HOME目录.2.执行sh bin/start-all.sh 关闭Hadoop1.进入HADOOP_HOME目录.2.执行sh bin/stop-all.sh文件操作Hadoop使用的是HDFS,能够实现的功能和我们使用的磁盘系统类似.并且支持通配符,如*. 查看文件列表查看hdfs中/user/admin/aaron目录下的文件.1.进入HADOOP_HOME
-
hadoop实现grep示例分享
hadoop做的一个简单grep程序,可从文档中提取包含某些字符串的行 复制代码 代码如下: /* * 一个简单grep程序,可从文档中提取包含莫些字符串的行 */ public class grep extends Configured implements Tool{ public static class grepMap extends Mapper<LongWritable, Text, Text,NullWritable>{ public void map(LongWritabl
-
Hadoop1.2中配置伪分布式的实例
1.设置ssh 安装ssh相关软件包: 复制代码 代码如下: sudo apt-get install openssh-client openssh-server 然后使用下面两个命令之一启动/关闭sshd: 复制代码 代码如下: sudo /etc/init.d/ssh start|stopsudo service ssh start|stop 若成功启动sshd,我们能看到如下类似结果: 复制代码 代码如下: $ ps -e | grep ssh 2766 ? 00:00:00
-

hadoop是什么语言
Hadoop是什么?Hadoop是一个开发和运行处理大规模数据的软件平台,是Appach的一个用java语言实现开源软件框架,实现在大量计算机组成的集群中对海量数据进行分布式计算. Hadoop框架中最核心设计就是:HDFS和MapReduce.HDFS提供了海量数据的存储,MapReduce提供了对数据的计算. 数据在Hadoop中处理的流程可以简单的按照下图来理解:数据通过Haddop的集群处理后得到结果. HDFS:Hadoop Distributed File System,Hadoop
-
hadoop map-reduce中的文件并发操作
这样的操作在map端或者reduce端均可.下面以一个实际业务场景中的例子来简要说明. 问题简要描述: 假如reduce输入的key是Text(String),value是BytesWritable(byte[]),不同key的种类为100万个,value的大小平均为30k左右,每个key大概对应 100个value,要求对每一个key建立两个文件,一个用来不断添加value中的二进制数据,一个用来记录各个value在文件中的位置索引.(大量的小文件会影响HDFS的性能,所以最好对这些小文件进行
-
hadoop的hdfs文件操作实现上传文件到hdfs
hdfs文件操作操作示例,包括上传文件到HDFS上.从HDFS上下载文件和删除HDFS上的文件,大家参考使用吧 复制代码 代码如下: import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.*; import java.io.File;import java.io.IOException;public class HadoopFile { private Configuration conf =null
-
Hadoop单机版和全分布式(集群)安装
Hadoop,分布式的大数据存储和计算, 免费开源!有Linux基础的同学安装起来比较顺风顺水,写几个配置文件就可以启动了,本人菜鸟,所以写的比较详细.为了方便,本人使用三台的虚拟机系统是Ubuntu-12.设置虚拟机的网络连接使用桥接方式,这样在一个局域网方便调试.单机和集群安装相差不多,先说单机然后补充集群的几点配置. 第一步,先安装工具软件编辑器:vim 复制代码 代码如下: sudo apt-get install vim ssh服务器: openssh,先安装ssh是为了使用远程终端工
-
用python + hadoop streaming 分布式编程(一) -- 原理介绍,样例程序与本地调试
MapReduce与HDFS简介 什么是Hadoop? Google为自己的业务需要提出了编程模型MapReduce和分布式文件系统Google File System,并发布了相关论文(可在Google Research的网站上获得: GFS . MapReduce). Doug Cutting和Mike Cafarella在开发搜索引擎Nutch时对这两篇论文做了自己的实现,即同名的MapReduce和HDFS,合起来就是Hadoop. MapReduce的Data flow如下图,原始数据
-
用PHP和Shell写Hadoop的MapReduce程序
使得任何支持标准IO (stdin, stdout)的可执行程序都能成为hadoop的mapper或者 reducer.例如: 复制代码 代码如下: hadoop jar hadoop-streaming.jar -input SOME_INPUT_DIR_OR_FILE -output SOME_OUTPUT_DIR -mapper /bin/cat -reducer /usr/bin/wc 在这个例子里,就使用了Unix/Linux自带的cat和wc工具来作为mapper / reducer
-
Hadoop2.X/YARN环境搭建--CentOS7.0系统配置
一.我缘何选择CentOS7.0 14年7月7日17:39:42发布了CentOS 7.0.1406正式版,我曾使用过多款Linux,对于Hadoop2.X/YARN的环境配置缘何选择CentOS7.0,其原因有: 1.界面采用RHEL7.0新的GNOME界面风,这可不是CentOS6.5/RHEL6.5所能比的!(当然,Fedora早就采用这种风格的了,但是现在的Fedora缺包已然不成样子了) 2.曾经,我也用了RHEL7.0,它最大的问题就是YUM没法用,而且总会有Warning提示注册购
-
Hadoop2.X/YARN环境搭建--CentOS7.0 JDK配置
Hadoop是Java写的,他无法使用Linux预安装的OpenJDK,因此安装hadoop前需要先安装JDK(1.6以上) 原材料:在Oracle官网下载的32位JDK: 说明: 1.CentOS 7.0系统现在只有64位的,但是,Hadoop一般支持32位的,在64位环境下有事会有Warning出现,避免真的有神马问题,选择i586的JDK(即32位的),当然,64位的CentOS 7 肯定是兼容32位JDK的,记住:64位系统肯定兼容32位的软件,32位系统不能兼容64位软件.64位只是说
-
Win10 GPU运算环境搭建(CUDA10.0+Cudnn 7.6.5+pytroch1.2+tensorflow1.14.0)
目录 一.深度学习为什么要搭建GPU运算环境? 什么是CUDA? 什么是Cudnn? 二.搭建GPU运算环境 CUDA的下载 Cudnn的下载 三.Ananconda3的安装 什么是Anaconda? 下载Anaconda3 四.Anaconda虚拟环境的搭建 什么是虚拟环境? 虚拟环境的相关操作 五.选择要搭建的深度学习框架 Pytorch的安装 检查环境和GPU运算是否搭建成功 Tensorflow的安装 五.心得和一些建议 一.深度学习为什么要搭建GPU运算环境? 熟悉深度学习的人都知道,
-
Hadoop2.8.1完全分布式环境搭建过程
前言 本文搭建了一个由三节点(master.slave1.slave2)构成的Hadoop完全分布式集群(区别单节点伪分布式集群),并通过Hadoop分布式计算的一个示例测试集群的正确性. 本文集群三个节点基于三台虚拟机进行搭建,节点安装的操作系统为Centos7(yum源),Hadoop版本选取为2.8.0.作者也是初次搭建Hadoop集群,其间遇到了很多问题,故希望通过该博客让读者避免. 实验过程 1.基础集群的搭建 目的:获得一个可以互相通信的三节点集群 下载并安装VMware WorkS
-
Centos7 ftp环境搭建教程详解
没玩过linux,折腾了半天的ftp,好不容易亲测通过了.不容易啊.下面把劳动成果分享到我们平台,感兴趣的朋友参考下吧! 操作环境:vm虚拟机 centos7 首先:搞定网络问题:默认情况下使用ifconfig可以看到虚拟机下是无网络的.(注:虚拟机网络设置为NAT或桥接模式都是可以的) 输入命令nmtui 打开网络配置 回车->回车 将倒数第二项 Automatically connect 勾上 然后就有网络了 然后更新系统:yum update 查看vsftpd是否已安装:vsftpd -v
-
centos7系统nginx服务器下phalcon环境搭建方法详解
本文实例讲述了centos7系统nginx服务器下phalcon环境搭建方法.分享给大家供大家参考,具体如下: 之前我们采用的是Apache服务器,可是每秒响应只能达到2000,听说nginx可以轻易破万, 于是换成nginx试试. phalcon的官网有nginx重写规则的示例,可是却与apache的不一致,被坑了好久. 1.添加nginx源 vi /etc/yum.repos.d/nginx.repo [nginx] name=nginx repo baseurl=http://nginx.
-
Vue2.0 从零开始_环境搭建操作步骤
简要:继项目空闲后,开始着手vue的学习;为此向大家分享其中的艰辛和搭建办法,希望能够跟各位VUE大神学习探索,如果有不对或者好的建议告知下:*~*! 一.什么是VUE? 是一种node.js框架,特点如下: 1.数据绑定 (特性:双向绑定:一旦发生变化,Dom节点实时更新:PS:尽量抛弃JQ,次特点已经可以解决很多特效等问题) 2.组件化(比如:乐高积木一样通过互相引用而组装起来) 二.开发环境 三.环境搭建 1. 包管理器安装 (1) Homebrew安装 (mac 环境,win无法安装)
-
Centos6.5和Centos7 php环境搭建方法
总有人认为linux搭建php环境很复杂,然后尝试安装lnmp一键安装包.其实说白了就是安装一个web服务器,然后支持php即可,很简单的,比起你安装lnmp一键安装包还要简单.不说大话,看实际安装步骤. 首先我们先查看下centos的版本信息 复制代码 代码如下: #适用于所有的linux lsb_release -a #或者 cat /etc/redhat-release #又或者 rpm -q centos-release 以上三种任意一种均可查看centos的版本信息. 这里我们分别在c
-
Microsoft Visual C++ 6.0开发环境搭建教程
上一篇演示的是如何安装VS2010,本文演示的是如何安装Microsoft Visual C++ 6.0 简称VC6. 有同学经常VC6都是很古董的版本了,为啥他还存在,不得不说VC6是微软一个很经典的版本. 现在很多公司都还是采用这个开发环境,不过大多数同学们的系统可能已经是win7或者win8.1了,导致VC6奔溃. 本文演示的VC++6.0绿色版本不存在这样的问题. 1.绿色版,先解压缩VC++6.0绿色版, 2.然后打开 运行.bat 3.输入项目名称 4.选择hello world
-
Centos7.4环境安装lamp-php7.0教程
本文实例讲述了Centos7.4环境安装lamp-php7.0的方法.分享给大家供大家参考,具体如下: 一. 环境准备 桥接模式 能访问外网 #ping www.baidu.com ping得通则能到外网 关闭防火墙 #systemctl disable firewalld //禁用防火墙 #systemctl stop firewalld //关闭防火墙 关闭seLinux #vim /etc/selinux/config 改为: SELINUX=disabled 配置yum源 # cd /e