Hadoop源码分析六启动文件namenode原理详解
1、 namenode启动
在本系列文章三中分析了hadoop的启动文件,其中提到了namenode启动的时候调用的类为
org.apache.hadoop.hdfs.server.namenode.NameNode
其main方法的内容如下:
public static void main(String argv[]) throws Exception {
if (DFSUtil.parseHelpArgument(argv, NameNode.USAGE, System.out, true)) {
System.exit(0);
}
try {
StringUtils.startupShutdownMessage(NameNode.class, argv, LOG);
NameNode namenode = createNameNode(argv, null);
if (namenode != null) {
namenode.join();
}
} catch (Throwable e) {
LOG.error("Failed to start namenode.", e);
terminate(1, e);
}
}
这段代码的重点在第8行,这里createNameNode方法创建了一个namenode对象,然后调用其join方法阻塞等待请求。
createNameNode方法的内容如下:
public static NameNode createNameNode(String argv[], Configuration conf)
throws IOException {
LOG.info("createNameNode " + Arrays.asList(argv));
if (conf == null)
conf = new HdfsConfiguration();
// Parse out some generic args into Configuration.
GenericOptionsParser hParser = new GenericOptionsParser(conf, argv);
argv = hParser.getRemainingArgs();
// Parse the rest, NN specific args.
StartupOption startOpt = parseArguments(argv);
if (startOpt == null) {
printUsage(System.err);
return null;
}
setStartupOption(conf, startOpt);
switch (startOpt) {
case FORMAT: {
boolean aborted = format(conf, startOpt.getForceFormat(),
startOpt.getInteractiveFormat());
terminate(aborted ? 1 : 0);
return null; // avoid javac warning
}
case GENCLUSTERID: {
System.err.println("Generating new cluster id:");
System.out.println(NNStorage.newClusterID());
terminate(0);
return null;
}
case FINALIZE: {
System.err.println("Use of the argument '" + StartupOption.FINALIZE +
"' is no longer supported. To finalize an upgrade, start the NN " +
" and then run `hdfs dfsadmin -finalizeUpgrade'");
terminate(1);
return null; // avoid javac warning
}
case ROLLBACK: {
boolean aborted = doRollback(conf, true);
terminate(aborted ? 1 : 0);
return null; // avoid warning
}
case BOOTSTRAPSTANDBY: {
String toolArgs[] = Arrays.copyOfRange(argv, 1, argv.length);
int rc = BootstrapStandby.run(toolArgs, conf);
terminate(rc);
return null; // avoid warning
}
case INITIALIZESHAREDEDITS: {
boolean aborted = initializeSharedEdits(conf,
startOpt.getForceFormat(),
startOpt.getInteractiveFormat());
terminate(aborted ? 1 : 0);
return null; // avoid warning
}
case BACKUP:
case CHECKPOINT: {
NamenodeRole role = startOpt.toNodeRole();
DefaultMetricsSystem.initialize(role.toString().replace(" ", ""));
return new BackupNode(conf, role);
}
case RECOVER: {
NameNode.doRecovery(startOpt, conf);
return null;
}
case METADATAVERSION: {
printMetadataVersion(conf);
terminate(0);
return null; // avoid javac warning
}
case UPGRADEONLY: {
DefaultMetricsSystem.initialize("NameNode");
new NameNode(conf);
terminate(0);
return null;
}
default: {
DefaultMetricsSystem.initialize("NameNode");
return new NameNode(conf);
}
}
}
这段代码很简单。主要做的操作有三个:
- 1、 创建配置文件对象
- 2、 解析命令行的参数
- 3、 根据参数执行对应方法(switch块)
其中创建的配置文件的为HdfsConfiguration(第5行),这里的HdfsConfiguration继承于Configuration类,它会加载hadoop的配置文件到内存中。然后解析传入main方法的参数,根据这个参数执行具体的方法。正常启动的时候执行的default里的内容。default的内容也很简单,就是创建一个Namenode对象。
这里先从HdfsConfiguration开始分析,详细讲解hdfs的配置文件处理。
首先看HdfsConfiguration的初始化方法如下:
public HdfsConfiguration() {
super();
}
这里是调用其父类的初始化方法。
其父类为Configuration类,它的初始化方法如下:
/** A new configuration. */
public Configuration() {
this(true);
}
这里可以看见他是调用了一个重载方法,传入了一个参数:true。
接着细看这个重载方法:
public Configuration(boolean loadDefaults) {
this.loadDefaults = loadDefaults;
updatingResource = new ConcurrentHashMap<String, String[]>();
synchronized(Configuration.class) {
REGISTRY.put(this, null);
}
}
这里也很简单,这里主要是为两个参数赋值,并将新创建的Configuration添加到REGISTRY中。
至此便创建好了一个配置文件。但是关于配置文件的初始化解析还未完成。在java里可以使用static关键字声明一段代码块,这段代码块在类加载的时候会被执行。在Configuration和HdfsConfiguration中都有静态代码块。
首先在Configuration类中,在第682行有一段静态代码块,其内容如下:

这段代码的重点在第695行和第696行,这里调用了一个addDefaultResource方法,这里传入了两个参数core-default.xml和core-site.xml。其中core-site.xml就是在安装hadoop的时候设置的配置文件。而core-default.xml是hadoop自带的配置文件,这个文件可以在hadoop的官方文档里查到,文档链接如下:https://hadoop.apache.org/docs/r2.7.6/hadoop-project-dist/hadoop-common/core-default.xml
同样在hadoop的源码里也有这个文件,它在hadoop-common-XX.jar中。
接着继续分析调用的addDefaultResource方法
其内容如下:
public static synchronized void addDefaultResource(String name) {
if(!defaultResources.contains(name)) {
defaultResources.add(name);
for(Configuration conf : REGISTRY.keySet()) {
if(conf.loadDefaults) {
conf.reloadConfiguration();
}
}
}
}
这段代码也很简单。首先是第二行先从defaultResources中判断是否已经存在该配置文件,
这里的defaultResources是一个list
其定义如下:
private static final CopyOnWriteArrayList<String> defaultResources =
new CopyOnWriteArrayList<String>();
若defaultResources中不存在这个配置文件,则继续向下执行,将这个配置文件添加到defaultResources中(第3行)。然后遍历REGISTRY中的key(第4行),这里的key就是在上文提到的Configuration对象。然后根据其loadDefaults的值来判断是否执行reloadConfiguration方法。
这里的loadDefaults的值就是上文分析的传入重载方法的值,上文传入的为true,所以其创建的Configuration对象在这里会执行reloadConfiguration方法。
reloadConfiguration方法内容如下:
public synchronized void reloadConfiguration() {
properties = null; // trigger reload
finalParameters.clear(); // clear site-limits
}
这里可以看见这个reloadConfiguration方法并没有真正的重新加载配置文件而是将properties的值设置为空。
同样在HdfsConfiguration也有类似的静态代码块,在第30行,其内容如下:
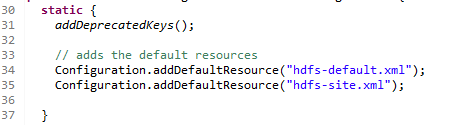
这里首先调用了一个addDeprecatedKeys方法然后调用了一个addDefaultResource。这里的addDefaultResource传了两个文件hdfs-default.xml和hdfs-site.xml。其中hdfs-site.xml是安装时的配置文件,hdfs-default.xml是其自带的默认文件,同上文的core-default.xml一样。官网链接为:https://hadoop.apache.org/docs/r2.7.6/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml。文件位于:hadoop-hdfs-2.7.6.jar。
其中addDeprecatedKeys方法内容如下:
private static void addDeprecatedKeys() {
Configuration.addDeprecations(new DeprecationDelta[] {
new DeprecationDelta("dfs.backup.address",
DFSConfigKeys.DFS_NAMENODE_BACKUP_ADDRESS_KEY),
new DeprecationDelta("dfs.backup.http.address",
DFSConfigKeys.DFS_NAMENODE_BACKUP_HTTP_ADDRESS_KEY),
new DeprecationDelta("dfs.balance.bandwidthPerSec",
DFSConfigKeys.DFS_DATANODE_BALANCE_BANDWIDTHPERSEC_KEY),
new DeprecationDelta("dfs.data.dir",
DFSConfigKeys.DFS_DATANODE_DATA_DIR_KEY),
new DeprecationDelta("dfs.http.address",
DFSConfigKeys.DFS_NAMENODE_HTTP_ADDRESS_KEY),
new DeprecationDelta("dfs.https.address",
DFSConfigKeys.DFS_NAMENODE_HTTPS_ADDRESS_KEY),
new DeprecationDelta("dfs.max.objects",
DFSConfigKeys.DFS_NAMENODE_MAX_OBJECTS_KEY),
new DeprecationDelta("dfs.name.dir",
DFSConfigKeys.DFS_NAMENODE_NAME_DIR_KEY),
new DeprecationDelta("dfs.name.dir.restore",
DFSConfigKeys.DFS_NAMENODE_NAME_DIR_RESTORE_KEY),
new DeprecationDelta("dfs.name.edits.dir",
DFSConfigKeys.DFS_NAMENODE_EDITS_DIR_KEY),
new DeprecationDelta("dfs.read.prefetch.size",
DFSConfigKeys.DFS_CLIENT_READ_PREFETCH_SIZE_KEY),
new DeprecationDelta("dfs.safemode.extension",
DFSConfigKeys.DFS_NAMENODE_SAFEMODE_EXTENSION_KEY),
new DeprecationDelta("dfs.safemode.threshold.pct",
DFSConfigKeys.DFS_NAMENODE_SAFEMODE_THRESHOLD_PCT_KEY),
new DeprecationDelta("dfs.secondary.http.address",
DFSConfigKeys.DFS_NAMENODE_SECONDARY_HTTP_ADDRESS_KEY),
new DeprecationDelta("dfs.socket.timeout",
DFSConfigKeys.DFS_CLIENT_SOCKET_TIMEOUT_KEY),
new DeprecationDelta("fs.checkpoint.dir",
DFSConfigKeys.DFS_NAMENODE_CHECKPOINT_DIR_KEY),
new DeprecationDelta("fs.checkpoint.edits.dir",
DFSConfigKeys.DFS_NAMENODE_CHECKPOINT_EDITS_DIR_KEY),
new DeprecationDelta("fs.checkpoint.period",
DFSConfigKeys.DFS_NAMENODE_CHECKPOINT_PERIOD_KEY),
new DeprecationDelta("heartbeat.recheck.interval",
DFSConfigKeys.DFS_NAMENODE_HEARTBEAT_RECHECK_INTERVAL_KEY),
new DeprecationDelta("dfs.https.client.keystore.resource",
DFSConfigKeys.DFS_CLIENT_HTTPS_KEYSTORE_RESOURCE_KEY),
new DeprecationDelta("dfs.https.need.client.auth",
DFSConfigKeys.DFS_CLIENT_HTTPS_NEED_AUTH_KEY),
new DeprecationDelta("slave.host.name",
DFSConfigKeys.DFS_DATANODE_HOST_NAME_KEY),
new DeprecationDelta("session.id",
DFSConfigKeys.DFS_METRICS_SESSION_ID_KEY),
new DeprecationDelta("dfs.access.time.precision",
DFSConfigKeys.DFS_NAMENODE_ACCESSTIME_PRECISION_KEY),
new DeprecationDelta("dfs.replication.considerLoad",
DFSConfigKeys.DFS_NAMENODE_REPLICATION_CONSIDERLOAD_KEY),
new DeprecationDelta("dfs.replication.interval",
DFSConfigKeys.DFS_NAMENODE_REPLICATION_INTERVAL_KEY),
new DeprecationDelta("dfs.replication.min",
DFSConfigKeys.DFS_NAMENODE_REPLICATION_MIN_KEY),
new DeprecationDelta("dfs.replication.pending.timeout.sec",
DFSConfigKeys.DFS_NAMENODE_REPLICATION_PENDING_TIMEOUT_SEC_KEY),
new DeprecationDelta("dfs.max-repl-streams",
DFSConfigKeys.DFS_NAMENODE_REPLICATION_MAX_STREAMS_KEY),
new DeprecationDelta("dfs.permissions",
DFSConfigKeys.DFS_PERMISSIONS_ENABLED_KEY),
new DeprecationDelta("dfs.permissions.supergroup",
DFSConfigKeys.DFS_PERMISSIONS_SUPERUSERGROUP_KEY),
new DeprecationDelta("dfs.write.packet.size",
DFSConfigKeys.DFS_CLIENT_WRITE_PACKET_SIZE_KEY),
new DeprecationDelta("dfs.block.size",
DFSConfigKeys.DFS_BLOCK_SIZE_KEY),
new DeprecationDelta("dfs.datanode.max.xcievers",
DFSConfigKeys.DFS_DATANODE_MAX_RECEIVER_THREADS_KEY),
new DeprecationDelta("io.bytes.per.checksum",
DFSConfigKeys.DFS_BYTES_PER_CHECKSUM_KEY),
new DeprecationDelta("dfs.federation.nameservices",
DFSConfigKeys.DFS_NAMESERVICES),
new DeprecationDelta("dfs.federation.nameservice.id",
DFSConfigKeys.DFS_NAMESERVICE_ID),
new DeprecationDelta("dfs.client.file-block-storage-locations.timeout",
DFSConfigKeys.DFS_CLIENT_FILE_BLOCK_STORAGE_LOCATIONS_TIMEOUT_MS),
});
}
这段代码很简单,只有一句话。调用了 Configuration的静态方法addDeprecations,并向其中传入了一个参数,参数类型为DeprecationDelta类的数组,并为数组中的数据进行赋值。
以上就是关于Hadoop源码分析启动文件namenode原理详解的详细内容,更多关于Hadoop源码分析的资料请持续关注我们其它相关文章!
相关推荐
-

Hadoop之NameNode Federation图文详解
一. 前言 1.NameNode架构的局限性 (1)Namespace(命名空间)的限制 由于NameNode在内存中存储所有的元数据(metadata),因此单个NameNode所能存储的对象(文件+块)数目受到NameNode所在JVM的heap size的限制.50G的heap能够存储20亿(200million)个对象,这20亿个对象支持4000个DataNode,12PB的存储(假设文件平均大小为40MB).随着数据的飞速增长,存储的需求也随之增长.单个DataNode从4T增长到36
-
Hadoop源码分析三启动及脚本剖析
1. 启动 hadoop的启动是通过其sbin目录下的脚本来启动的.与启动相关的叫脚本有以下几个: start-all.sh.start-dfs.sh.start-yarn.sh.hadoop-daemon.sh.yarn-daemon.sh. hadoop-daemon.sh是用来启动与hdfs相关的服务的 yarn-daemon.sh是用来启动和yarn相关的服务 start-dfs.sh是用来启动hdfs集群的 start-yarn.sh是用来启动yarn集群 start-all.sh是用
-
Hadoop中namenode和secondarynamenode工作机制讲解
1)流程 2)FSImage和Edits nodenode是HDFS的大脑,它维护着整个文件系统的目录树,以及目录树里所有的文件和目录,这些信息以俩种文件存储在文件系统:一种是命名空间镜像(也称为文件系统镜像,File System Image,FSImage),即HDFS元数据的完整快照,每次NameNode启动的时候,默认会加载最新的命名空间镜像,另一种是命令空间镜像的编辑日志(Edit log). FSImage文件其实是文件系统元数据的一个永久性检查点,但并非每一个写操作都会更新这个文件
-
Hadoop源码分析五hdfs架构原理剖析
目录 1. hdfs架构 如果在hadoop配置时写的配置文件不同,启动的服务也有所区别 namenode的下方是三台datanode. namenode左右两边的是两个zkfc. namenode的上方是三台journalnode集群. 2. namenode介绍 namenode作为hdfs的核心,它主要的作用是管理文件的元数据 文件与块的对应关系中的块 namenode负责管理hdfs的元数据 namenode的数据持久化,采用了一种日志加快照的方式 最后还会有一个程序读取这个快照文件和日
-
Hadoop源码分析四远程debug调试
1. hadoop远程debug 从文档(3)中可以知道hadoop启动服务的时候最终都是通过java命令来启动的,其本质是一个java程序.在研究源码的时候debug是一种很重要的工具,但是hadoop是编译好了的代码,直接在liunx中运行的,无法象普通的程序一样可以直接在eclipse之类的工具中直接debug运行. 对于上述情况java提供了一种远程debug的方式. 这种方式需要在java程序启动的时候添加以下参数: -agentlib:jdwp=transport=dt_socket
-
Hadoop源码分析六启动文件namenode原理详解
1. namenode启动 在本系列文章三中分析了hadoop的启动文件,其中提到了namenode启动的时候调用的类为 org.apache.hadoop.hdfs.server.namenode.NameNode 其main方法的内容如下: public static void main(String argv[]) throws Exception { if (DFSUtil.parseHelpArgument(argv, NameNode.USAGE, System.out, true)
-
redis源码分析教程之压缩链表ziplist详解
前言 压缩列表(ziplist)是由一系列特殊编码的内存块构成的列表,它对于Redis的数据存储优化有着非常重要的作用.这篇文章总结一下redis中使用非常多的一个数据结构压缩链表ziplist.该数据结构在redis中说是无处不在也毫不过分,除了链表以外,很多其他数据结构也是用它进行过渡的,比如前面文章提到的SortedSet.下面话不多说了,来一起看看详细的介绍吧. 一.压缩链表ziplist数据结构简介 首先从整体上看下ziplist的结构,如下图: 压缩链表ziplist结构图 可以看出
-
Hadoop源码分析二安装配置过程详解
目录 1. 创建用户 2. 安装jdk 3. 修改hosts 4. 配置ssh免密登录 5. 安装zookeeper 解压: 修改配置文件 修改内容如下: 配置环境变量 启动 6. 安装hadoop 对于三台节点的配置安排如下: 解压: 修改配置文件: 修改core-site.xml 配置hdfs-site.xml 配置mapred-site.xml 配置yarn-site.xml 配置slaves 7. 初始化 在初始化前需要将所有机器都配置好hadoop (1) 启动zookeeper (2
-
Hadoop源码分析一架构关系简介
1. 简介 Hadoop是一个由Apache基金会所开发的分布式系统基础架构 Hadoop起源于谷歌发布的三篇论文:GFS.MapReduce.BigTable.其中GFS是谷歌的分布式文件存储系统,MapReduce是基于这个分布式文件存储系统的一个计算框架,BigTable是一个分布式的数据库.hadoop实现了论文GFS和MapReduce中的内容,Hbase的实现了参考了论文BigTable. 2. hadoop架构 hadoop主要有三个组件 HDFS.YARN和MapReduce.其
-
Spring源码分析容器启动流程
目录 前言 源码解析 1.初始化流程 流程分析 核心代码剖析 2.刷新流程 流程分析 核心代码剖析 前言 本文基于 Spring 的 5.1.6.RELEASE 版本 Spring的启动流程可以归纳为三个步骤: 1.初始化Spring容器,注册内置的BeanPostProcessor的BeanDefinition到容器中 2.将配置类的BeanDefinition注册到容器中 3.调用refresh()方法刷新容器 Spring Framework 是 Java 语言中影响最为深远的框架之一,其
-
Volley源码之使用方式和使用场景详解
概述 Volley是Google在2013年推出的一个网络库,用于解决复杂网络环境下网络请求问题.刚推出的时候是非常火的,现在该项目的变动已经很少了.项目库地址为https://android.googlesource.com/platform/frameworks/volley 通过提交历史可以看到,最后一次修改距离今天已经有一段时间了.而volley包的release版本也已经很久没有更新了. author JeffDavidson<jpd@google.com> SunMar1316:3
-
Web网络安全分析二次注入攻击原理详解
目录 二次注入攻击 二次注入代码分析 二次注入攻击 二次注入攻击的测试地址:http://127.0.0.1/sqli/double1.php?username=test 和 http://127.0.0.1/sqli/double2.php?id=1. 其中,double1.php页面的功能是注册用户名,也是插入SQL语句的地方:double2.php页面的功能是通过参数ID读取用户名和用户信息. 第一步,访问double1.php?username=test',如图40所示. 图40 注册用