详解Mysql order by与limit混用陷阱
在Mysql中我们常常用order by来进行排序,使用limit来进行分页,当需要先排序后分页时我们往往使用类似的写法select * from 表名 order by 排序字段 limt M,N。但是这种写法却隐藏着较深的使用陷阱。在排序字段有数据重复的情况下,会很容易出现排序结果与预期不一致的问题。
如表:

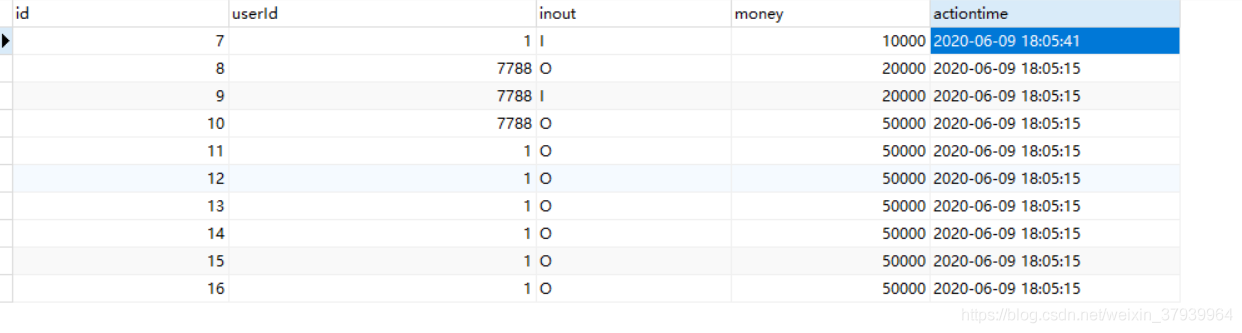
查询第一页跟最后一页时出现:


解决办法:
SELECT * FROM purchaseinfo ORDER BY actiontime,id LIMIT 0,2;
上面的实际执行结果已经证明现实与想像往往是有差距的,实际SQL执行时并不是按照上述方式执行的。这里其实是Mysql会对Limit做优化,具体优化方式见官方文档:https://dev.mysql.com/doc/refman/5.7/en/limit-optimization.html
/*
Navicat MySQL Data Transfer
Source Server : 本地mysql8.0
Source Server Version : 80018
Source Host : localhost:3308
Source Database : baihe
Target Server Type : MYSQL
Target Server Version : 80018
File Encoding : 65001
Date: 2020-06-09 14:47:37
*/
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for purchaseinfo
-- ----------------------------
DROP TABLE IF EXISTS `purchaseinfo`;
CREATE TABLE `purchaseinfo` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`userId` int(11) DEFAULT '0',
`inout` varchar(1) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`money` int(11) DEFAULT NULL,
`actiontime` datetime DEFAULT NULL COMMENT 'jiaoyi',
PRIMARY KEY (`id`),
KEY `UserId` (`userId`)
) ENGINE=InnoDB AUTO_INCREMENT=17 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
-- ----------------------------
-- Records of purchaseinfo
-- ----------------------------
INSERT INTO `purchaseinfo` VALUES ('7', '1', 'I', '10000', '2020-06-09 18:05:41');
INSERT INTO `purchaseinfo` VALUES ('8', '7788', 'O', '20000', '2020-06-09 18:05:15');
INSERT INTO `purchaseinfo` VALUES ('9', '7788', 'I', '20000', '2020-06-09 18:05:15');
INSERT INTO `purchaseinfo` VALUES ('10', '7788', 'O', '50000', '2020-06-09 18:05:15');
INSERT INTO `purchaseinfo` VALUES ('11', '1', 'O', '50000', '2020-06-09 18:05:15');
INSERT INTO `purchaseinfo` VALUES ('12', '1', 'O', '50000', '2020-06-09 18:05:15');
INSERT INTO `purchaseinfo` VALUES ('13', '1', 'O', '50000', '2020-06-09 18:05:15');
INSERT INTO `purchaseinfo` VALUES ('14', '1', 'O', '50000', '2020-06-09 18:05:15');
INSERT INTO `purchaseinfo` VALUES ('15', '1', 'O', '50000', '2020-06-09 18:05:15');
INSERT INTO `purchaseinfo` VALUES ('16', '1', 'O', '50000', '2020-06-09 18:05:15');
到此这篇关于详解Mysql order by与limit混用陷阱的文章就介绍到这了,更多相关Mysql order by与limit混用内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySQL查询优化:连接查询排序limit(join、order by、limit语句)介绍
不知道有没有人碰到过这样恶心的问题:两张表连接查询并limit,SQL效率很高,但是加上order by以后,语句的执行时间变的巨长,效率巨低. 情况是这么一个情况:现在有两张表,team表和people表,每个people属于一个team,people中有个字段team_id. 下面给出建表语句: 复制代码 代码如下: create table t_team ( id int primary key, tname varchar(100) ); create table t_people (
-
Mysql排序和分页(order by&limit)及存在的坑
排序查询(order by) 电商中:我们想查看今天所有成交的订单,按照交易额从高到低排序,此时我们可以使用数据库中的排序功能来完成. 排序语法: select 字段名 from 表名 order by 字段1 [asc|desc],字段2 [asc|desc]; 需要排序的字段跟在order by之后: asc|desc表示排序的规则,asc:升序,desc:降序,默认为asc: 支持多个字段进行排序,多字段排序之间用逗号隔开. 单字段排序 mysql> create table test2(
-

详解Mysql order by与limit混用陷阱
在Mysql中我们常常用order by来进行排序,使用limit来进行分页,当需要先排序后分页时我们往往使用类似的写法select * from 表名 order by 排序字段 limt M,N.但是这种写法却隐藏着较深的使用陷阱.在排序字段有数据重复的情况下,会很容易出现排序结果与预期不一致的问题. 如表: 查询第一页跟最后一页时出现: 解决办法: SELECT * FROM purchaseinfo ORDER BY actiontime,id LIMIT 0,2; 上面的实际执行结果已
-
详解MySQL中Order By排序和filesort排序的原理及实现
目录 1.Order By原理 2.filesort排序算法 3.优化排序 1.Order By原理 MySQL的Order By操作用于排序,并且会有多种不同的排序算法,他们的性能都是不一样的. 假设有一个表,建表的sql如下: CREATE TABLE `obtest` ( `id` BIGINT NOT NULL AUTO_INCREMENT, `a` VARCHAR ( 100 ) NOT NULL, `b` VARCHAR ( 100 ) NOT NULL, `c` VARCHAR (
-
详解MySQL中EXPLAIN解释命令及用法讲解
1,情景描述:同事教我在mysql中用explain,于是查看了一番返回内容的含义 2,现就有用处的内容做如下记录: 1,explain显示了mysql如何使用索引来处理select语句以及连接表.可以帮助选择更好的索引和写出更优化的查询语句. 使用方法,在select语句前加上explain就可以了: explain select count(DISTINCT uc_userid) as user_login from user_char_daily_gameapp_11 where uc_d
-
详解MySQL 慢查询
查询mysql的操作信息 show status -- 显示全部mysql操作信息 show status like "com_insert%"; -- 获得mysql的插入次数; show status like "com_delete%"; -- 获得mysql的删除次数; show status like "com_select%"; -- 获得mysql的查询次数; show status like "uptime";
-
详解mysql DML语句的使用
前言: 在上篇文章中,主要为大家介绍的是DDL语句的用法,可能细心的同学已经发现了.本篇文章将主要聚焦于DML语句,为大家讲解表数据相关操作. 这里说明下DDL与DML语句的分类,可能有的同学还不太清楚. DDL(Data Definition Language):数据定义语言,用于创建.删除.修改.库或表结构,对数据库或表的结构操作.常见的有create,alter,drop等. DML(Data Manipulation Language):数据操纵语言,主要对表记录进行更新(增.删.改).
-
详解MySQL 数据分组
创建分组 分组是在SELECT语句中的GROUP BY 子句中建立的. 例: SELECT vend_id, COUNT(*) AS num_prods FROM products GROUP BY vend_id; GROUP BY GROUP BY子句可以包含任意数目的列,这使得能对分组进行嵌套,为数据分组提供更细致的控制. 如果在GROUP BY子句中嵌套了分组,数据将在最后规定的分组商家进行汇总.换句话说,在建立分组时,指定的所有列都一起计算.(所有不能从个别的列取回数据). GROUP
-
详解MySQL数据库千万级数据查询和存储
百万级数据处理方案 数据存储结构设计 表字段设计 表字段 not null,因为 null 值很难查询优化且占用额外的索引空间,推荐默认数字 0. 数据状态类型的字段,比如 status, type 等等,尽量不要定义负数,如 -1.因为这样可以加上 UNSIGNED,数值容量就会扩大一倍. 可以的话用 TINYINT.SMALLINT 等代替 INT,尽量不使用 BIGINT,因为占的空间更小. 字符串类型的字段会比数字类型占的空间更大,所以尽量用整型代替字符串,很多场景是可以通过编码逻辑来实
-
详解 Mysql查询结果顺序按 in() 中ID 的顺序排列
详解 Mysql查询结果顺序按 in() 中ID 的顺序排列 实例代码: <select id="queryGBStyleByIDs" resultMap="styleMap"> select style_num_id ,style_id,style_title,style_pic FROM gb_style where online = 1 AND is_hide = 0 and style_num_id in <foreach collecti
-
详解 Mysql 事务和Mysql 日志
事务特性 1.原子性(Atomicity):事务开始后所有操作,要么全部做完,要么全部不做,不可能停滞在中间环节. 2.一致性(Consistency):事务开始前和结束后,数据库的完整性约束没有被破坏 .比如A向B转账,不可能A扣了钱,B却没收到. 3.隔离性(Isolation):同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰.比如A正在从一张银行卡中取钱,在A取钱的过程结束前,B不能向这张卡转账. 4.持久性(Durability):事务完成后,事务对数据库的所有更新
-
实例详解mysql子查询
子查询分类 按返回结果集分类 子查询按返回结果集的不同分为4种:表子查询,行子查询,列子查询和标量子查询. 表子查询:返回的结果集是一个行的集合,N行N列(N>=1).表子查询经常用于父查询的FROM子句中. 行子查询:返回的结果集是一个列的集合,一行N列(N>=1).行子查询可以用于福查询的FROM子句和WHERE子句中. 列子查询:返回的结果集是一个行的集合,N行一列(N>=1). 标量子查询:返回的结果集是一个标量集合,一行一列,也就是一个标量值.可以指定一个标量表达式的任何地方,