SpringBoot集成Sharding Jdbc使用复合分片的实践
目录
- 1、Sharing JDBC 简介
- 2、系统改造
- 2.1 对接外部系统的系统
- 2.2 内部系统间的调用
- 3、解决方案
- 4、代码实现
- 4.1 Sharding JDBC 配置
- 4.2 数据源操作类
- 4.3 分片测试类
- 4.4 测试结果
- 参考文章:
最近主要的工作重心是数据库的容量规划。
随着业务的逐渐增大,原有保存在单表的数据量也日益增强。数据库数据会随着业务的发展而不断增多,因此数据操作,如增删改查的开销也会越来越大。再加上物理服务器的资源有限(CPU、磁盘、内存、IO 等)。最终数据库所能承载的数据量、数据处理能力都将遭遇瓶颈。换句话说需要合理的数据库架构来存放不断增长的数据,这个就是分库分表的设计初衷。目的就是为了缓解数据库的压力,大限度提高数据操作的效率。
数据库分库分表中间件是采用的 apache sharding。
1、Sharing JDBC 简介
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、云原生等各种多样化的应用场景。
ShardingSphere定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。 它与NoSQL和NewSQL是并存而非互斥的关系。NoSQL和NewSQL作为新技术探索的前沿,放眼未来,拥抱变化,是非常值得推荐的。反之,也可以用另一种思路看待问题,放眼未来,关注不变的东西,进而抓住事物本质。 关系型数据库当今依然占有巨大市场,是各个公司核心业务的基石,未来也难于撼动,我们目前阶段更加关注在原有基础上的增量,而非颠覆。
ShardingSphere已经在2020年4月16日从Apache孵化器毕业,成为Apache顶级项目。
2、系统改造
因为我们公司属于第三方支付平台,这个改造的点可以分为两类:提供给商户调用的对接系统(比如收银台),系统内部调用的系统(支付引擎)。
- 收银台系统:核心功能是提供给商户提交交易订单,并且对这笔交易订单进行支付的支付订单
- 支付引擎:接收这个支付产品的请求,调用渠道,记账,结算等功能
数据源使用分库分表,在 Sharding JDBC 当中如果进行 修改、删除、查询操作中没有包含分片键就会进行全表扫描。所以在进行业务改造的时候对原有的数据库操作都进行了业务优化,基本改造后的所有的操作都使用了基于分片键进行操作(定时任务除外)。
2.1 对接外部系统的系统
首先讨论一下,提供给商户调用的系统。在进行下单操作的时候,商户必须传递商户号和外部订单号。对于外部订单号第三方支付系统无法控制,只需要商户每次传递过来的时候与历史的外部订单号不重复就可以了。所以这里就涉及到一张映射表,这个表的主要功能如下:
- 把商户的外部订单号映射成内部订单号
- 通过商户号与商户的外部订单号在数据库联合唯一达到幂等处理
- 保存商户请求的原始数据,做为请求凭证
这个时候对交易订单就依赖于外部映射表,把请求映射成内部订单号进行分片就可以了
2.2 内部系统间的调用
当商户下好了交易订单的时候,需要进行支付这个时候就产生了一笔支付订单。交易订单和支付订单是一对多的关系。当用户进行支付的时候会调用支付引擎,这个时候正常情况下一般会生成支付系统的支付订单。然后支付引擎会调用后续的渠道、结算、记账等系统,系统之间的调用图如下:

如果以支付系统的支付订单的订单号做为分片键时:
- 支付引擎的内部系统可以使用分片键查询,会路由到具体的库表当中,没有问题
- 渠道、结算、记账等系统如果涉及到回调支付引擎,在调用的时候会把支付引擎的支付单号传递给后续系统,如果进行回调操作时候,可以回传这个支付单号。会路由到具体的库表当中,没有问题
- 收银台需要根据交易的支付订单查询支付引擎生成的支付单。由于不是根据分片键查询,不能路由到具体的库中的具体表上,会进行全表扫描。就会有问题。
3、解决方案
首先想到的方案可以参考收银台系统,把收银台调用支付引擎看到外部调用。然后添加一张映射表,把收银台生成的支付流水号与支付引擎的支付单号关联起来。当收银台需要查询支付引擎时,可以先通过映射表查询到具体的支付单号,这样就可以进行分片键操作数据源了。这个方案存在一个问题存在以下几个问题:
引入了关联表,添加了系统复杂度进行数据查询的时候会两次查询,先查询映射表,然后再查询支付单
那么有没有其它方案呢?答案是肯定的。
我们来看一下收银台、支付引擎其实这两个系统在支付系统中是同一个纬度的。如果收银台的交易订单进行支付的时候,就会在支付引擎当中下一笔支付单。我们可以把交易单与支付单在同一个水平纬度上进行数据库拆分。
什么叫同一个纬度的数据库拆分呢?
其实就是收银台的支付订单进行分库分表之后,这条数据落在数据库里面的哪一个库,哪一张表就一定了。这个时候支付引擎就可以通过这个单号获取到具体的库表信息。这样就可以把支付引擎生成的的订单号带个具体的库表信息。然后在进行分库分表算法定义的时候根据支付引擎生成的订单号中带的库表信息路由到具体的库表中去了。就样就会解决上面的问题,不需要映射表。同时这种方案也会带来以下的问题:
- 数据上游与下游的分库分表必须一致
- 数据在进行再次扩容会有其它问题
经过讨论决定使用方案二。
4、代码实现
下面通过 Sharding jdbc 的复合分片简单的模拟代码实现。数据库、表准备:
数据库:
- order_0
- order_1
每个数据库的表:
tb_order_0
tb_order_1
tb_order_2
tb_order_3
tb_order_4
tb_order_5
tb_order_6
tb_order_7
# 逻辑表
create table tb_order
(
trade_master_no varchar(16),
pay_order_no varchar(16) ,
);
# 准备数据
# 分库分表规则是前一位代表库,后一位代表表,所以在 order_1.tb_order_1 中添加以下数据
insert into tb_order_1 values('11', '11'),
4.1 Sharding JDBC 配置
下面是针对订单表的 sharding jdbc 的分库分表配置,数据库连接池使用 Hikari 。分片规则:前一位代表库,后一位代表表。使用交易主单号(trade_master_no) 和 支付单号(pay_order_no) 作为复合分片。当查询条件中只要包含一个查询规则时就会路由到具体库表中。
ComplexShardingJDBCConfig.java
@Configuration
public class ComplexShardingJDBCConfig {
@Bean
public DataSource getShardingDataSource(HikariCommonConfig commonConfig) throws SQLException {
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(getShardingMessageTableRuleConfiguration());
Map<String, DataSource> dataSourceMap = new HashMap<>();
dataSourceMap.put("order_0", createDataSource(datasourceOne(commonConfig)));
dataSourceMap.put("order_1", createDataSource(datasourceTwo(commonConfig)));
Properties properties = new Properties();
properties.setProperty(ShardingPropertiesConstant.SQL_SHOW.getKey(), "true");
return ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, properties);
}
private TableRuleConfiguration getShardingMessageTableRuleConfiguration() {
TableRuleConfiguration shardingMessageConfiguration = new TableRuleConfiguration("tb_order", "order_${0..1}.tb_order_${0..7}");
shardingMessageConfiguration.setDatabaseShardingStrategyConfig(messageDatasourceShardingStrategyConfig());
shardingMessageConfiguration.setTableShardingStrategyConfig(messageTableShardingStrategyConfig());
return shardingMessageConfiguration;
}
private ComplexShardingStrategyConfiguration messageDatasourceShardingStrategyConfig(){
return new ComplexShardingStrategyConfiguration("trade_master_no,pay_order_no", new OrderDatasourceComplexKeysShardingAlgorithm());
}
private ShardingStrategyConfiguration messageTableShardingStrategyConfig() {
return new ComplexShardingStrategyConfiguration("trade_master_no,pay_order_no", new OrderTableComplexKeysShardingAlgorithm());
}
@Bean
@ConfigurationProperties(prefix = "spring.datasource.ds1")
public HikariConfig datasourceOne(HikariCommonConfig commonConfig){
HikariConfig hikariConfig = new HikariConfig();
hikariConfig.setMinimumIdle(commonConfig.getMinimumIdle());
hikariConfig.setIdleTimeout(commonConfig.getIdleTimeout());
hikariConfig.setMaximumPoolSize(commonConfig.getMaximumPoolSize());
hikariConfig.setPoolName(commonConfig.getPoolName());
hikariConfig.setMaxLifetime(commonConfig.getMaxLifetime());
hikariConfig.setConnectionTimeout(commonConfig.getConnectionTimeout());
hikariConfig.setConnectionTestQuery(commonConfig.getConnectionTestQuery());
return hikariConfig;
}
@Bean
@ConfigurationProperties(prefix = "spring.datasource.ds2")
public HikariConfig datasourceTwo(HikariCommonConfig commonConfig){
HikariConfig hikariConfig = new HikariConfig();
hikariConfig.setMinimumIdle(commonConfig.getMinimumIdle());
hikariConfig.setIdleTimeout(commonConfig.getIdleTimeout());
hikariConfig.setMaximumPoolSize(commonConfig.getMaximumPoolSize());
hikariConfig.setPoolName(commonConfig.getPoolName());
hikariConfig.setMaxLifetime(commonConfig.getMaxLifetime());
hikariConfig.setConnectionTimeout(commonConfig.getConnectionTimeout());
hikariConfig.setConnectionTestQuery(commonConfig.getConnectionTestQuery());
return hikariConfig;
}
private HikariDataSource createDataSource(HikariConfig hikariConfig) {
HikariDataSource sharding = new HikariDataSource();
BeanUtils.copyProperties(hikariConfig, sharding);
return sharding;
}
}
数据库分片规则:
public class OrderDatasourceComplexKeysShardingAlgorithm implements ComplexKeysShardingAlgorithm<String> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, ComplexKeysShardingValue<String> shardingValue) {
Map<String, Collection<String>> columnNameAndShardingValuesMap = shardingValue.getColumnNameAndShardingValuesMap();
if(columnNameAndShardingValuesMap.containsKey("trade_master_no")){
Collection<String> tradeMasterNos = columnNameAndShardingValuesMap.get("trade_master_no");
String tradeMasterNo = tradeMasterNos.iterator().next();
String datasourceSuffix = tradeMasterNo.substring(0, 1);
for (String availableTargetName : availableTargetNames) {
if(availableTargetName.endsWith(datasourceSuffix)){
return Lists.newArrayList(availableTargetName);
}
}
}
if(columnNameAndShardingValuesMap.containsKey("pay_order_no")){
Collection<String> payOrderNos = columnNameAndShardingValuesMap.get("pay_order_no");
String payOrderNo = payOrderNos.iterator().next();
String datasourceSuffix = payOrderNo.substring(0, 1);
for (String availableTargetName : availableTargetNames) {
if(availableTargetName.endsWith(datasourceSuffix)){
return Lists.newArrayList(availableTargetName);
}
}
}
throw new UnsupportedOperationException();
}
}
数据库中的表分片规则:
public class OrderTableComplexKeysShardingAlgorithm implements ComplexKeysShardingAlgorithm<String> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, ComplexKeysShardingValue<String> shardingValue) {
Map<String, Collection<String>> columnNameAndShardingValuesMap = shardingValue.getColumnNameAndShardingValuesMap();
if(columnNameAndShardingValuesMap.containsKey("trade_master_no")){
Collection<String> tradeMasterNos = columnNameAndShardingValuesMap.get("trade_master_no");
String tradeMasterNo = tradeMasterNos.iterator().next();
String datasourceSuffix = tradeMasterNo.substring(1, 2);
for (String availableTargetName : availableTargetNames) {
if(availableTargetName.endsWith(datasourceSuffix)){
return Lists.newArrayList(availableTargetName);
}
}
}
if(columnNameAndShardingValuesMap.containsKey("pay_order_no")){
Collection<String> payOrderNos = columnNameAndShardingValuesMap.get("pay_order_no");
String payOrderNo = payOrderNos.iterator().next();
String datasourceSuffix = payOrderNo.substring(1, 2);
for (String availableTargetName : availableTargetNames) {
if(availableTargetName.endsWith(datasourceSuffix)){
return Lists.newArrayList(availableTargetName);
}
}
}
throw new UnsupportedOperationException();
}
}
4.2 数据源操作类
这里使用 Mybatis 操作数据源,当然使用其它 ORM 框架操作数据源 sharding jdbc 也是支持的。
public interface OrderMapper {
int countByExample(OrderExample example);
int deleteByExample(OrderExample example);
int insert(Order record);
int insertSelective(Order record);
List<Order> selectByExample(OrderExample example);
int updateByExampleSelective(@Param("record") Order record, @Param("example") OrderExample example);
int updateByExample(@Param("record") Order record, @Param("example") OrderExample example);
}
4.3 分片测试类
通过 Spring boot 定义一个 Controller,使用 Order 对象查询。即可以使用交易单号也可以使用支付单号查询。
@Getter
@Setter
public class Order {
private String tradeMasterNo;
private String payOrderNo;
}
@RestController
@RequestMapping("order")
public class OrderController {
@Resource
private OrderDao orderDao;
@RequestMapping("query")
public Order query(@RequestBody Order order) {
Order orderInDB = orderDao.queryOrder(order);
return orderInDB;
}
}
4.4 测试结果
由于我们在 sharing jdbc 配置当中配置了数据库查询 SQL,我们只需要观察是不是只打印了一条数据库操作语句就可以判断之前的结论是否正确。
通过 Postman 使用交易单号查询:

控制台打印:

然后通过 Postman 使用支付单号查询:

控制台打印:
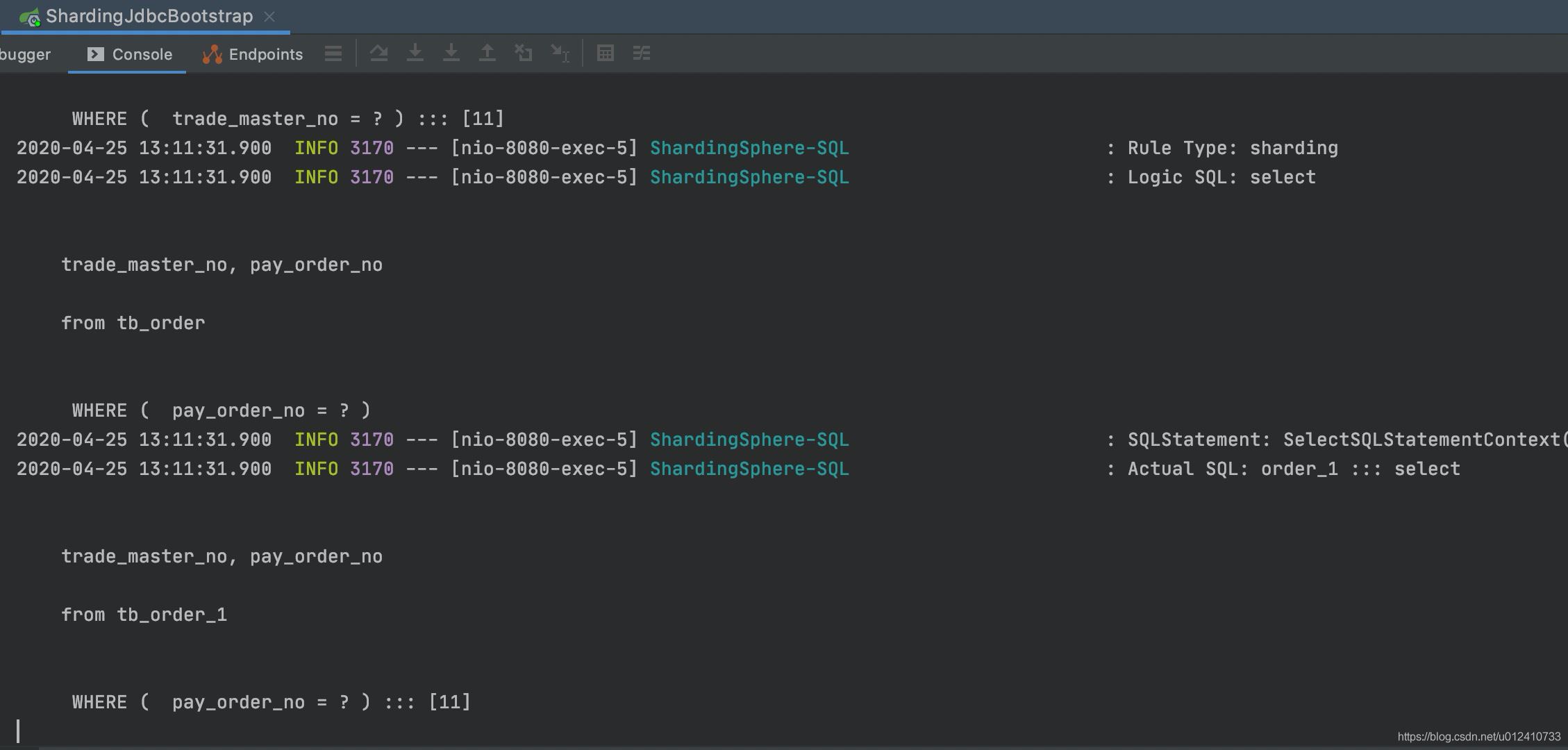
它们查询都是路由到具体的库表当中,说明我们的方案是可以的。
参考文章:
到此这篇关于SpringBoot集成Sharding Jdbc使用复合分片的实践的文章就介绍到这了,更多相关SpringBoot集成Sharding Jdbc复合分片内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
spring boot使用sharding jdbc的配置方式
本文介绍了spring boot使用sharding jdbc的配置方式,分享给大家,具体如下: 说明 要排除DataSourceAutoConfiguration,否则多数据源无法配置 @SpringBootApplication @EnableAutoConfiguration(exclude={DataSourceAutoConfiguration.class}) public class Application { public static void main(String[] arg
-

SpringBoot整合Sharding-JDBC实现MySQL8读写分离
目录 一.前言 二.项目目录结构 三.pom文件 四.配置文件(基于YAML)及SQL建表语句 五.Mapper.xml文件及Mapper接口 六 .Controller及Mocel文件 七.结果 八.Sharding-JDBC不同版本上的配置 一.前言 这是一个基于SpringBoot整合Sharding-JDBC实现读写分离的极简教程,笔者使用到的技术及版本如下: SpringBoot 2.5.2 MyBatis-Plus 3.4.3 Sharding-JDBC 4.1.1 MySQL8集群
-
SpringBoot 2.0 整合sharding-jdbc中间件实现数据分库分表
一.水平分割 1.水平分库 1).概念: 以字段为依据,按照一定策略,将一个库中的数据拆分到多个库中. 2).结果 每个库的结构都一样:数据都不一样: 所有库的并集是全量数据: 2.水平分表 1).概念 以字段为依据,按照一定策略,将一个表中的数据拆分到多个表中. 2).结果 每个表的结构都一样:数据都不一样: 所有表的并集是全量数据: 二.Shard-jdbc 中间件 1.架构图 2.特点 1).Sharding-JDBC直接封装JDBC API,旧代码迁移成本几乎为零. 2).适
-
springboot整合shardingjdbc实现分库分表最简单demo
一.概览 1.1 简介 ShardingSphere-JDBC定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务. 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架. 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC. 支持任何第三方的数据库连接池,如:DBCP,
-
Spring Boot 集成 Sharding-JDBC + Mybatis-Plus 实现分库分表功能
一. Sharding-jdbc简介 " Sharding-jdbc是开源的数据库操作中间件:定位为轻量级Java框架,在Java的JDBC层提供的额外服务.它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架. 官方文档地址:https://shardingsphere.apache.org/document/current/cn/overview/ 本文demo实现了分库分表功能.如有错误,欢迎各位在评论中指出.不
-
详解Spring Boot中整合Sharding-JDBC读写分离示例
在我<Spring Cloud微服务-全栈技术与案例解析>书中,第18章节分库分表解决方案里有对Sharding-JDBC的使用进行详细的讲解. 之前是通过XML方式来配置数据源,读写分离策略,分库分表策略等,之前有朋友也问过我,有没有Spring Boot的方式来配置,既然已经用Spring Boot还用XML来配置感觉有点不协调. 其实吧我个人觉得只要能用,方便看,看的懂就行了,mybatis的SQL不也是写在XML中嘛. 今天就给大家介绍下Spring Boot方式的使用,主要讲解读写分
-
SpringBoot集成Sharding Jdbc使用复合分片的实践
目录 1.Sharing JDBC 简介 2.系统改造 2.1 对接外部系统的系统 2.2 内部系统间的调用 3.解决方案 4.代码实现 4.1 Sharding JDBC 配置 4.2 数据源操作类 4.3 分片测试类 4.4 测试结果 参考文章: 最近主要的工作重心是数据库的容量规划. 随着业务的逐渐增大,原有保存在单表的数据量也日益增强.数据库数据会随着业务的发展而不断增多,因此数据操作,如增删改查的开销也会越来越大.再加上物理服务器的资源有限(CPU.磁盘.内存.IO 等).最终数据库所
-
SpringBoot集成Redis并实现主从架构的实践
目录 一.Windows环境下安装Redis 设置键值对 根据key获取value 二.SpringBoot连接Redis (1)使用Jedis类直接连接Redis服务器 (2)通过配置文件进行连接 三.使用连接池操作Redis 今天这篇文章来和大家分享一下在springboot中如何集成redis,并实现主从架构,进行数据的简单存储. 我的Redis是部署在Windows系统下面的,所以在这里附上Redis在Windows环境下的安装地址和安装说明. 一.Windows环境下安装Redis 首
-
SpringBoot 如何使用sharding jdbc进行分库分表
目录 基于4.0版本,Springboot2.1 在pom里确保有如下引用 里面我profiles.active了另一个 之后手工把表都建好 写个测试代码 需要注意一个坑 基于4.0版本,Springboot2.1 之前写过一篇使用sharding-jdbc进行分库分表的文章,不过当时的版本还比较早,现在已经不能用了.这一篇是基于最新版来写的. 新版已经变成了shardingsphere了,https://shardingsphere.apache.org/. 有点不同的是,这一篇,我们是采用多
-
SpringBoot集成ElaticJob定时器的实现代码
本文介绍了SpringBoot集成ElaticJob定时器的实现代码,分享给大家,具体如下: POM文件配置 <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:sch
-
SpringBoot集成Spring Data JPA及读写分离
相关代码: github OSCchina JPA是什么 JPA(Java Persistence API)是Sun官方提出的Java持久化规范,它为Java开发人员提供了一种对象/关联映射工具 来管理Java应用中的关系数据.它包括以下几方面的内容: 1.ORM映射 支持xml和注解方式建立实体与表之间的映射. 2.Java持久化API 定义了一些常用的CRUD接口,我们只需直接调用,而不需要考虑底层JDBC和SQL的细节. 3.JPQL查询语言 这是持久化操作中很重要的一个方面,通过面向对象
-
springboot集成activemq的实例代码
ActiveMQ ActiveMQ 是Apache出品,最流行的,能力强劲的开源消息总线.ActiveMQ 是一个完全支持JMS1.1和J2EE 1.4规范的 JMS Provider实现,尽管JMS规范出台已经是很久的事情了,但是JMS在当今的J2EE应用中间仍然扮演着特殊的地位. 特性 多种语言和协议编写客户端.语言: Java,C,C++,C#,Ruby,Perl,Python,PHP.应用协议: OpenWire,Stomp REST,WS Notification,XMPP,AMQP
-
SpringBoot集成多数据源解析
一,前面我们介绍了springboot的快速启动,大家肯定对springboot也有所了解,下面我们来介绍一下springboot怎么集成多数据源. 在有的项目开发中需要在一个项目中访问多个数据源或者两个项目之间通信(实质上是互相访问对方的数据库),在这里,我们介绍一下在一个项目中如何集成多个数据源(即访问多个不同的数据库),因为在项目中有时会有这种需求,比如在一个大型项目开发中,一个数据库中保存数据的索引,各种使用频繁的数据,另一个数据库中保存其他的数据. 1.下面我们来讨论一个问题,怎么集成
-
SpringBoot集成JPA的示例代码
本文介绍了SpringBoot集成JPA的示例代码,分享给大家,具体如下: 1.创建新的maven项目 2. 添加必须的依赖 <!--springboot的必须依赖--> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>1.5.9.RELEASE
-
详解springboot集成mybatis xml方式
springboot集成mybatis 关键代码如下: 1,添加pom引用 <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>1.1.1</version> </dependency> <dependency> &l