R语言wilcoxon秩和检验及wilcoxon符号秩检验的操作
说明
wilcoxon秩和及wilcoxon符号秩检验是对原假设的非参数检验,在不需要假设两个样本空间都为正态分布的情况下,测试它们的分布是否完全相同。
操作
#利用mtcars数据
library(stats)
data("mtcars")
boxplot(mtcars$mpg~mtcars$am,ylab='mpg',names = c('automatic','manual))
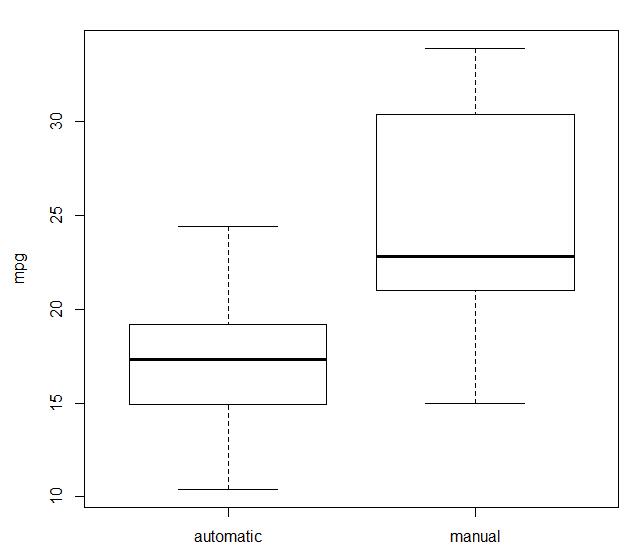
#执行wilcoxon秩和检验验证自动档手动档数据分布是否一致 wilcox.test(mpg~am,data = mtcars) #wilcox.test(mtcars$mpg[mtcars$am==0],mtcars$mpg[mtcars$am==1])(与上面等价) Wilcoxon rank sum test with continuity correction data: mpg by am W = 42, p-value = 0.001871 alternative hypothesis: true location shift is not equal to 0 Warning message: In wilcox.test.default(x = c(21.4, 18.7, 18.1, 14.3, 24.4, 22.8, : 无法精確計算带连结的p值
总结
执行wilcoxon秩和检验(也称Mann-Whitney U检验)这样一种非参数检验 。
t检验假设两个样本的数据集之间的差别符合正态分布(当两个样本集都符合正态分布时,t检验效果最佳),但当服从正态分布的假设并不确定时,我们执行wilcoxon秩和检验来验证数据集中mtcars中自动档与手动档汽车的mpg值的分布是否一致,p值<0.05,原假设不成立。
意味两者分布不同。警告“无法精確計算带连结的p值“这是因为数据中存在重复的值,一旦去掉重复值,警告就不会出现。
补充:R语言差异检验:非参数检验
非参数检验是在总体方差未知或知道甚少的情况下,利用样本数据对总体分布形态进行推断的方法。它利用数据的大小间的次序关系(秩Rank),而不是具体数值信息,得出推断结论。
它是参数检验所需要的某些条件不满足时所使用的方法。
和参数检验相比,非参数检验的优势如下:
稳健性。对总体分布的条件要求放宽
对数据类型要求不严格,适用有序分类变量
适用范围广
劣势:
没有利用实际数值,损失了部分信息,检验的有效性较差。
非参数性检验的方法非常多,基于方法的检验功效性角度,本文只涉及
双独立样本:Mann-Whitney U检验
双配对样本:Wilcoxon配对秩和检验
多独立样本:Kruskal-Wallis检验
多配对样本:Friedman检验
Mann-Whitney U检验
曼-惠特尼U检验(曼-惠特尼秩和检验),是由H.B.Mann和D.R.Whitney于1947年提出的。它假设两个样本分别来自除了总体均值以外完全相同的两个总体,目的是检验这两个总体的均值是否有显著的差别。
适用条件
双独立样本检验
R语言示例
函数及格式:wilcox.test(y~x,data)
其中,y是连续变量,x是一个二分变量。
也可以使用这种形式:
wilcox.test(y1,y2)
其中,y1和y2为变量名。可选参数data的取值为一个包含这些变量的矩阵或数据框。
示例:
#载入MASS包 library(MASS) #使用UScrime数据集 #Prob为监禁率,So为是否南方地区 #检验美国监禁率是否存在南方和非南方差异 #wilcox.test检验 wilcox.test(Prob~So,data = UScrime) #结果 Wilcoxon rank sum test data: Prob by So W = 81, p-value = 8.488e-05 alternative hypothesis: true location shift is not equal to 0 #结果显示P小于0.001,美国监禁率存在南方和非南方地区差异。
Wilcoxon配对秩和检验
Wilcoxon配对秩和检验是对Sign符号检验的改进。它的假设被归结为总体中位数是否为0。
适用条件
双配对样本检验
R语言示例
Wilcoxon配对秩和检验调用函数格式与Mann-Whitney U检验相同。不同之处在于可以添加paired=TRUE参数。
示例:
#u1(14-24岁年龄段城市男性失业率) #u2(35-39岁年龄段城市男性失业率) #检验失业率是否在两个年龄段存在差异 #Wilcoxon配对秩和检验 with(UScrime,wilcox.test(U1,U2,paired = TRUE)) #结果 Wilcoxon signed rank test with continuity correction data: U1 and U2 V = 1128, p-value = 2.464e-09 alternative hypothesis: true location shift is not equal to 0 #结果显示,存在差别。
Kruskal-Wallis检验
由克罗斯考尔和瓦里斯1952年提出,用来解决多独立样本难以满足方差分析条件(独立性、正态性、方差齐性)时统计推断问题。
适用条件
多独立样本检验
R语言示例
函数格式:
kruskal.test(y~A,data)
其中,y为连续变量,A为两个或更多水平的分组变量。
示例:
#检验美国四个地区文盲率是否存在差异 #数据皆来自R自带数据集 #通过state.region数据集获取地区名称,即分组变量。 states <- data.frame(state.region,state.x77) #调用kruskal.test函数 kruskal.test(Illiteracy~state.region,data = states) #结果 Kruskal-Wallis rank sum test data: Illiteracy by state.region Kruskal-Wallis chi-squared = 22.672, df = 3, p-value = 4.726e-05 #结果显示,文盲率存在地区差异。
Friedman检验
Friedman检验也称弗里德曼双向评秩方差分析。由Friedman在1937年提出,基本思想是独立对每一个区组分别对数据进行排秩,消除区组间的差异以检验各种处理之间是否存在差异。
适用条件
多配对样本检验
Fiedman检验在样本量有限的情况下,实际应用价值不大。
R语言示例
函数格式:
friedman.test(y~A|B,data)
其中,y为连续变量,A是一个分组变量,B是一个用以认定匹配观测的区组变量。
或者
friedman.test(data=matrix格式)
其中,data要求矩阵格式。可以通过as.matrix转换
示例:
(虚构)有30名女性分为三组每组10人,试吃三种药。经过一段时间后,药效如下。问三种药药效是否有区别。
药1
4.4,5,5.8,4.6,4.9,4.8,6,5.9,4.3,5.1
药2
6.2,5.2,5.5,5,4.4,5.4,5,6.4,5.8,6.2
药3
7.0,6.2,5.9,6,4.6,6.4,5,6.4,5.8,6.2
#生成数据集
drug1 <- c(4.4,5,5.8,4.6,4.9,4.8,6,5.9,4.3,5.1)
drug2 <- c(6.2,5.2,5.5,5,4.4,5.4,5,6.4,5.8,6.2)
drug3 <- c(7.0,6.2,5.9,6,4.6,6.4,5,6.4,5.8,6.2)
#矩阵
data <- matrix(c(drug1,drug2,drug3),nrow = 10,dimnames = list(ID=1:10,c('drug1','drug2','drug3')))
#查看数据
data
ID drug1 drug2 drug3
1 4.4 6.2 7.0
2 5.0 5.2 6.2
3 5.8 5.5 5.9
4 4.6 5.0 6.0
5 4.9 4.4 4.6
6 4.8 5.4 6.4
7 6.0 5.0 5.0
8 5.9 6.4 6.4
9 4.3 5.8 5.8
10 5.1 6.2 6.2
#调用friedman.test函数
friedman.test(data)
Friedman rank sum test
data: data
Friedman chi-squared = 6.8889, df = 2, p-value =
0.03192
#结果显示,三种药之间存在区别。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
R语言中cbind、rbind和merge函数的使用与区别
cbind: 根据列进行合并,即叠加所有列,m列的矩阵与n列的矩阵cbind()最后变成m+n列,合并前提:cbind(a, c)中矩阵a.c的行数必需相符 rbind: 根据行进行合并,就是行的叠加,m行的矩阵与n行的矩阵rbind()最后变成m+n行,合并前提:rbind(a, c)中矩阵a.c的列数必需相符 > a <- matrix(1:12, 3, 4) > print(a) [,1] [,2] [,3] [,4] [1,] 1 4 7 10 [2,] 2 5 8 11 [3,
-

R语言ARMA模型的参数选择说明
AR(p)模型与MA(q)实际上是ARMA(p,q)模型的特例.它们都统称为ARMA模型,而ARMA(p,q)模型的统计性质也是AR(p)与MA(q)模型的统计性质的有机组合. 平稳系列建模 假如某个观察值序列通过序列预处理可以判定为平稳非白噪声序列,就可以利用ARMA模型对序列建模. 1.求出该观察值序列的样本自相关系数(ACF)与偏相关系数(PACF的值. 2.根据根样本自相关系数和偏自相关系数的性质,选择阶数适当的ARMA(p,q)模型进行拟合. 3.估计模型中未知参数的值 4.检验模型的
-
R语言-如何实现卡方检验
卡方检验 在数据统计中,卡方检验是一种很重要的方法. 通常卡方检验的应用主要为: 1. 卡方拟合优度检验 2.卡方独立性检验 本文主要通过使用自己编程的方法实现相关检验. 卡方拟合优度检验 理论: 1.我们先做出0假设:H0:总体服从假定的理论分布 2.我们再构造一个统计量: 3.当n充分大时 4.我们得到该拒绝域 代码 #Chi_square Goodness Of Fit Test #函数说明: #n为所得样本数据:p为理论概率 #alpha为置信水平,df为自由度 cgoft <- fun
-
解决R语言中install_github中无法安装遇到的问题
首先,让我们来进入常规步骤 我安装的是recharts包,正常的写法呢,就是以下这个样子: install.packages("devtools") #devtools::install_github("madlogos/recharts") 第一个问题: 然而对于今天的我来说,那就太天真了,首先踏入的第一个坑: 无法打开URL'http://yihui.name/xran/src/contrib/PACKAGES' Warning in install.packa
-
R语言-使用ifelse进行数据分组
数据分组,根据数据分析对象的特征,按照一定的数值指标,把数据分析对象划分为不同的区间部分来研究,以揭示内在的联系和规律性: 在R中,我们常用ifelse函数来进行数据的分组,跟excel中的if函数是同一种用法. ifelse(condition,TRUE,FALSE) > data <- read.table('1.csv', sep='|', header=TRUE); > > level <- ifelse( + data$cost<=20, "(0,2
-
R语言 实现选取某一行的最大值
可以先自定义函数 也可以用的时候再定义. > mat <- matrix(c(1:3,7:9,4:6), byrow = T, nc = 3) > mat [,1] [,2] [,3] [1,] 1 2 3 [2,] 7 8 9 [3,] 4 5 6 > apply(mat, 2, function(x){order(x, decreasing=T)[1]}) # 查找每一列 [1] 2 2 2 > apply(mat, 1, function(x){order(x, dec
-
R语言中的fivenum与quantile()函数算法详解
fivenum()函数: 返回五个数据:最小值.下四分位数数.中位数.上四分位数.最大值 对于奇数个数字=5,fivenum()先排序,依次返回最小值.下四分位数.中位数.上四分位数.最大值 > fivenum(c(1,12,40,23,13)) [1] 1 12 13 23 40 对于奇数个数字>5,fivenum()先排序,我们可以求取最小值,最大值,中位数.在排序中,最小值与中位数中间,若为奇数,取其中位数为下四分位数,若为偶数,取最中间两个数的平均值为下四分位数:在排序中,中位数与最大
-
R语言实现用cbind合并两列数据
我有两个数据文件,分别只有一列,这两列数据行数一行,我想把这两列合并到一个数据文件中,方便使用. 我的两个数据文件分别是1.txt,2.txt,保存后的文件名是3.txt. // 代码如下 gow1<-read.table("1.txt",header = FALSE) gow2<-read.table("2.txt",header = FALSE) View(gow1) View(gow2) gow<-cbind(gow1,gow2) View(
-
R语言开发之CSV文件的读写操作实现
在R中,我们可以从存储在R环境外部的文件读取数据,还可以将数据写入由操作系统存储和访问的文件.这个csv文件应该存在于当前工作目录中,以方便R可以读取它, 当然,也可以设置自己的目录,并从那里读取文件. 我们可以使用getwd()函数来检查R工作区指向哪个目录,并且使用setwd()函数设置新的工作目录,如下: 输出结果如下: csv文件是一个文本文件,其中列中的值用逗号分隔,我们可以将以下数据保存入txt文件中,并且修改后缀名称为csv: id,name,salary,start_date,d
-
R语言wilcoxon秩和检验及wilcoxon符号秩检验的操作
说明 wilcoxon秩和及wilcoxon符号秩检验是对原假设的非参数检验,在不需要假设两个样本空间都为正态分布的情况下,测试它们的分布是否完全相同. 操作 #利用mtcars数据 library(stats) data("mtcars") boxplot(mtcars$mpg~mtcars$am,ylab='mpg',names = c('automatic','manual)) #执行wilcoxon秩和检验验证自动档手动档数据分布是否一致 wilcox.test(mpg~am,
-
R语言开发之输出折线图的操作
线形图是通过在多个点之间绘制线段来连接一系列点所形成的图形,这些点按其坐标(通常是x坐标)的值排序,并且它通常用于识别数据趋势. 在R中的通过使用plot()函数来创建线形图,语法如下: plot(v,type,col,xlab,ylab) 参数描述如下: v - 是包含数值的向量. type - 取值"p"表示仅绘制点,"l"表示仅绘制线条,"o"表示仅绘制点和线. xlab - 是x轴的标签. ylab - 是y轴的标签. main - 是图
-
R语言ggplot2x轴顺序设置自定义颜色的操作
先声明一下所用的数据集 第一个图如下 这个图主要在于x轴的顺序设置上,如果按不做任何处理的话>3那个就会在2之前,解决方法是b[,1]<-factor(b[,1],levels=c('2','3',">3")),这句代码可以重新设置因子的级别 完整代码如下: a[,1]<-factor(a[,1],levels=c('2','3',">3")) ggplot(a,aes(x=a[,1],y=a[,2]))+geom_bar(stat=&
-
R语言-修改(替换)因子变量的元素操作
因子变量的核心是水平,通过指定水平来修改. x<-c(1,1,1,1,2,2,2,3,3,3,3,4) xx<-factor(x);xx levels(xx) #得到水平为3的位置 level_3<-which(levels(xx)==3) #重新赋值 levels(xx)[level_3]<-03 xx #由于新值是03,0开头,所以把03当成3处理 levels(xx)[level_3]<-c("03") xx #字符串会自动转换成因子 levels(
-
R语言-进行数据的重新编码(recode)操作
在分析数据时我们经常会遇到将变量值转换成其他的值的情况(如:将连续变量转成分类变量)这时就需要我们对原有数据进行重新编码.本文将介绍R软件中常用的三种重编吗方法: 1.使用逻辑判断式编码. 2.使用cut函数编码. 3.使用car程序包的recode函数. (一)使用逻辑判断式 (1)现假设我们需要将下面的连续型变量x按照10与20分成三个组,新的分组名称为1.2.3: > x2=1*(x<=10)+2*(x>10&x<=20)+3*(x>20) > x2 [1
-
在R语言中实现Logistic逻辑回归的操作
逻辑回归是拟合回归曲线的方法,当y是分类变量时,y = f(x).典型的使用这种模式被预测Ÿ给定一组预测的X.预测因子可以是连续的,分类的或两者的混合. R中的逻辑回归实现 R可以很容易地拟合逻辑回归模型.要调用的函数是glm(),拟合过程与线性回归中使用的过程没有太大差别.在这篇文章中,我将拟合一个二元逻辑回归模型并解释每一步. 数据集 我们将研究泰坦尼克号数据集.这个数据集有不同版本可以在线免费获得,但我建议使用Kaggle提供的数据集. 目标是预测生存(如果乘客幸存,则为1,否则为0)基于
-
R语言 vs Python对比:数据分析哪家强?
什么是R语言? R语言,一种自由软件编程语言与操作环境,主要用于统计分析.绘图.数据挖掘.R本来是由来自新西兰奥克兰大学的罗斯·伊哈卡和罗伯特·杰特曼开发(也因此称为R),现在由"R开发核心团队"负责开发.R基于S语言的一个GNU计划项目,所以也可以当作S语言的一种实现,通常用S语言编写的代码都可以不作修改的在R环境下运行.R的语法是来自Scheme. R的源代码可自由下载使用,亦有已编译的可执行文件版本可以下载,可在多种平台下运行,包括UNIX(也包括FreeBSD和Linux).W
-
R语言数据读取以及数据保存方式
一.R语言读取文本文件: 1.文件目录操作: getwd() : 返回当前工作目录 setwd("d:/data") 更改工作目录 2.常用的读取指令read read.table() : 读取文本文件 read.csv(): 读取csv文件 如果出现缺失值,read.table()会报错,read.csv()读取时会自动在缺失的位置填补NA 3.灵活的读取指令 scan() : 4.读取固定宽度格式的文件: read.fwf() 文本文档中最后一行的回车符很重要,这是一个类似于停止符
-
R语言-实现将向量转换成一个字符串
将向量a,b装换成一个字符串,其中: a=c(1,2,3,4) b=c(2,3,4,5) 为了将其转化成一个字符串可以通过引入包stringr,使用str_c实现,使用paste也一样可以达到目的,如下: library(stringr) a_b=str_c(a,b,collapse='') paste(a,b,sep='') 输出为: [1] "12233445" 在实际的数据处理中看可以用来给数据框建联合索引,比如数据框中需要用到的索引列联接成一列,则在实际中可以方便很多,避免很多