MongoDB聚合group的操作指南
MongoDB 聚合
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似sql语句中的 count(*)。
基本语法为:db.collection.aggregate( [ <stage1>, <stage2>, ... ] )
现在在mycol集合中有以下数据:
{ "_id" : 1, "name" : "tom", "sex" : "男", "score" : 100, "age" : 34 }
{ "_id" : 2, "name" : "jeke", "sex" : "男", "score" : 90, "age" : 24 }
{ "_id" : 3, "name" : "kite", "sex" : "女", "score" : 40, "age" : 36 }
{ "_id" : 4, "name" : "herry", "sex" : "男", "score" : 90, "age" : 56 }
{ "_id" : 5, "name" : "marry", "sex" : "女", "score" : 70, "age" : 18 }
{ "_id" : 6, "name" : "john", "sex" : "男", "score" : 100, "age" : 31 }
1、$sum计算总和。
Sql: select sex,count(*) frommycol group by sex
MongoDb: db.mycol.aggregate([{$group: {_id: '$sex', personCount: {$sum: 1}}}])

Sql: select sex,sum(score) totalScore frommycol group by sex
MongoDb: db.mycol.aggregate([{$group: {_id: '$sex', totalScore: {$sum: '$score'}}}])

2、$avg 计算平均值
Sql: select sex,avg(score) avgScore frommycol group by sex
Mongodb: db.mycol.aggregate([{$group: {_id: '$sex', avgScore: {$avg: '$score'}}}])

3、$max获取集合中所有文档对应值得最大值。
Sql: select sex,max(score) maxScore frommycol group by sex
Mongodb: db.mycol.aggregate([{$group: {_id: '$sex', maxScore: {$max: '$score'}}}])

4、$min 获取集合中所有文档对应值得最小值。
Sql: select sex,min(score) minScore frommycol group by sex
Mongodb: db.mycol.aggregate([{$group: {_id: '$sex', minScore: {$min: '$score'}}}])

5、$push 把文档中某一列对应的所有数据插入值到一个数组中。
Mongodb: db.mycol.aggregate([{$group: {_id: '$sex', scores : {$push: '$score'}}}])

6、$addToSet把文档中某一列对应的所有数据插入值到一个数组中,去掉重复的
db.mycol.aggregate([{$group: {_id: '$sex', scores : {$addToSet: '$score'}}}])

7、 $first根据资源文档的排序获取第一个文档数据。
db.mycol.aggregate([{$group: {_id: '$sex', firstPerson : {$first: '$name'}}}])

8、 $last根据资源文档的排序获取最后一个文档数据。
db.mycol.aggregate([{$group: {_id: '$sex', lastPerson : {$last: '$name'}}}])

9、全部统计null
db.mycol.aggregate([{$group:{_id:null,totalScore:{$push:'$score'}}}])

例子
现在在t2集合中有以下数据:
{ "country" : "china", "province" : "sh", "userid" : "a" }
{ "country" : "china", "province" : "sh", "userid" : "b" }
{ "country" : "china", "province" : "sh", "userid" : "a" }
{ "country" : "china", "province" : "sh", "userid" : "c" }
{ "country" : "china", "province" : "bj", "userid" : "da" }
{ "country" : "china", "province" : "bj", "userid" : "fa" }
需求是统计出每个country/province下的userid的数量(同一个userid只统计一次)
过程如下。
首先试着这样来统计:
db.t2.aggregate([{$group:{"_id":{"country":"$country","prov":"$province"},"number":{$sum:1}}}])
结果是错误的:

原因是,这样来统计不能区分userid相同的情况 (上面的数据中sh有两个 userid = a)
为了解决这个问题,首先执行一个group,其id 是 country, province, userid三个field:
db.t2.aggregate([ { $group: {"_id": { "country" : "$country", "province": "$province" , "uid" : "$userid" } } } ])

可以看出,这步的目的是把相同的userid只剩下一个。
然后第二步,再第一步的结果之上再执行统计:
db.t2.aggregate([
{ $group: {"_id": { "country" : "$country", "province": "$province" , "uid" : "$userid" } } } ,
{ $group: {"_id": { "country" : "$_id.country", "province": "$_id.province" }, count : { $sum : 1 } } }
])
这回就对了

加入一个$project操作符,把_id去掉
db.t2.aggregate([ { $group: {"_id": { "country" : "$country", "province": "$province" , "uid" : "$userid" } } } ,
{ $group: {"_id": { "country" : "$_id.country", "province": "$_id.province" }, count: { $sum : 1 } } },
{ $project : {"_id": 0, "country" : "$_id.country", "province" : "$_id.province", "count" : 1}}
])
最终结果如下:

管道的概念
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
这里我们介绍一下聚合框架中常用的几个操作:
- $project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
- match:用于过滤数据,只输出符合条件的文档。match使用MongoDB的标准查询操作。
- $limit:用来限制MongoDB聚合管道返回的文档数。
- $skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
- $unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
- $group:将集合中的文档分组,可用于统计结果。
- $sort:将输入文档排序后输出。
- $geoNear:输出接近某一地理位置的有序文档。
1、$project实例
db.mycol.aggregate({$project:{name : 1, score : 1}})
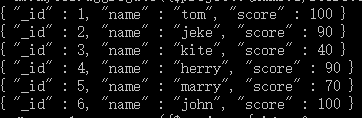
这样的话结果中就只还有_id,name和score三个字段了,默认情况下_id字段是被包含的,如果要想不包含_id话可以这样:
db.mycol.aggregate({$project:{_id : 0, name : 1, score : 1}})
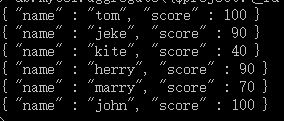
2、$match实例
$match用于获取分数大于30小于并且小于100的记录,然后将符合条件的记录送到下一阶段$group管道操作符进行处理
db.mycol.aggregate([{$match :{score: {$gt: 30, $lt: 100}}},{$group:{_id:'$sex',count:{$sum:1}}}])

总结
到此这篇关于MongoDB聚合group的文章就介绍到这了,更多相关 MongoDB聚合group内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MongoDB 监控工具mongostat和mongotop的使用
MongoDB中自带两个监控的工具,分别是mongostat和mongotop,今天我们看看这两个工具的使用方法. mongostat mongostat工具提供了mongod和mongos的运行状态和数据,可以从mongostat工具的执行结果中获取如下信息: [root@VM-0-14-centos ~]# mongostat --port=27018 -u "yeyz" --authenticationDatabase "admin" -p "123
-
java操作mongodb之多表联查的实现($lookup)
最近在开发的过程中,一个列表的查询,涉及到了多表的关联查询,由于持久层使用的是mongodb,对这个非关系型数据使用的不是很多,所以在实现此功能的过程中出现了不少问题,现在此做记录,一为加深自己的理解,以后遇到此类问题可以快速的解决,二为遇到同样问题的小伙伴提供一点小小的帮助. 全文分为两部分: 使用robo3t编写多表关系的查询语句 将编写的查询语句整合到java项目 多表联查的查询语句: 此处使用的为mongodb的robo3t可视化工具,先说下需求:从A(假如说是日志表)表中查询出符合条件
-
详解MongoDB中的日志模块
今天简单研究了一下MongoDB里面的日志模块,写篇文章记录下. 01 MongoDB日志组件种类及日志等级 每种数据库都有自己的日志模块,MongoDB也不例外,通常情况下,一个数据库的日志中,记录的是数据库的连接信息.存储信息.网络信息.索引信息以及查询信息等.从MongoDB3.0版本开始,MongoDB在日志中引入了日志等级和日志组件的概念,作为DBA来讲,关注的最多的应该是慢查询日志和连接日志. 在MongoDB中,我们可以通过下面的命令,来获取所有的日志组件种类和对应的日志等级: d
-

详解MongoDB的角色管理
NO.1 MongoDB内建角色 内建角色的种类和特点? 想要了解内建角色,还是少不了下面这张图,在MongoDB中,用户的权限是通过角色绑定的方法来分配的.把某个角色绑定在某个用户上,那么这个用户就有这个角色对应的权限了. MongoDB 4.0中的内建角色类型如下: 这里对上面的内建角色所拥有的权限做以说明: 数据库用户角色: read:用于读取所有非系统集合,以及下面三个系统集合: system.indexes.system.js以及system.namesp readWrite:拥有re
-
MongoDB的chunk详解
MongoDB中,在使用到分片的时候,常常会用到chunk的概念,chunk是指一个集合数据中的子集,也可以简单理解成一个数据块,每个chunk都是基于片键的范围取值,区间是左闭右开.例如,我们的片键是姓名的第二个字母,包含了A-Z这26中可能,理想情况下,划分为26个chunk,其中每个字母开头的姓名记录即为一个chunk. 在数据写入的时候,mongos根据片键shard key的值来写入对应的chunk中,chunk可以表示的最小范围是单个唯一的shard key的值,只包含具体的单个片键
-
MongoDB 副本集的搭建过程
今天的内容说下副本集的搭建过程吧. 下面的例子,是我自己在一台腾讯云服务器上搭建的过程,每个操作步骤都有,写出来大家看看. 本次操作是搭建一主,一从.一仲裁的三节点副本集,具体的过程如下: 1.创建节点目录 mkdir -p /data/mongo_28018/{data,log} mkdir -p /data/mongo_28019/{data,log} mkdir -p /data/mongo_28020/{data,log} 2.创建配置文件,配置文件内容如下: storage: db
-
MongoDB 主分片(primary shard)相关总结
01 主分片是什么? 分片集群中的每一个数据库都有一个主分片,这个主分片上保存了当前数据库中没有被分片的集合的数据,主分片(primary shard)和主节点(primary)之间没有任何关联. 主分片是由mongos选择出来的,选择的依据是每当创建新数据库的时候,mongos会从集群中选择包含数据最少的分片作为新数据库的主分片.具体的选择方式是: 选择listDatabase命令返回的totalSize字段作为选择的准则.如下: mongos> db.adminCommand("lis
-
MongoDB 简单入门教程(安装、基本概念、创建用户)
工作方向上的原因,不得不接触部分MongoDB的运维工作,之前有接触过一些MongoDB的内容,基本的运维操作没有什么问题,包括MongoDB的集群搭建.数据分片功能等都测试过.但是时间久了,很多东西不用就忘记了,最近准备出一个系列的MongoDB的运维操作文章,希望把这块儿内容重新拾起来.网上查了查,MongDB讲得好的书也就是<MongoDB权威指南>这本了,但是它引用的MongoDB版本比较旧,所以最好结合着官方文档看,这样收获会更快.MongoDB中文论坛里面也有不少前人总结的好文档,
-
2021最新版windows10系统MongoDB数据库安装及配置环境
一. MongoDB的下载与安装 1.1 下载地址 https://www.mongodb.com/download-center/community?jmp=docs 1.2 安装 创建一个 mongodb文件夹 存放下载好的 zip 二. 配置环境 鼠标右击选择计算机->属性 如下图,我们在新建中输入自己安装的MongoDB的bin文件夹路径然后选择确定即可! 输入命令就可以查看mongoDB的版本了 mongo -version 三. 配置系统服务 在MongoDB解压目录(bin文件同级
-
MongoDB 常用的数据类型和基本操作
NO.1 MongoDB的常用数据类型 MongoDB中的文档类似json,我们知道,在json中,最常用的数据类型有null.bool.数组.字符串.数据.json对象等等.相对比较少,比如对于时间类型的数据,json是无法表示的,而MongoDB中对json进行了简单的优化,像json,但是又不是json.下面我们慢慢说 MongoDB的常用数据类型和MySQL比较像,你可以对比着看.它的常用数据类型有: 1.null 用于表示空值或者不存在的字段 {"x":null} 2.boo