详解Java中的hashcode
一、什么是hash
Hash,一般翻译做散列、杂凑,或音译为哈希,是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
这个说的有点官方,你就可以把它简单的理解为一个key,就像是map的key值一样,是不可重复的。
二、hash有什么用?,在什么地方用到?
1.在散列表
2.map集合
此处只是做了一个简单的介绍,其实远远没有那么简单,如算法里面的散列表,散列函数,以及map的一个不可重复到底是怎么样去判断的,以及hash冲突的问题,都与hash值离不开关系。
三、java中String类的hashcode方法
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
可以看到,String类的hashcode方法是通过,char类型的方式进行一个相加,因为String类的底层就是通过char数组来实现的。
如:String str="ab"; 其实就是一个char数组 char[] str={'a','b'};
如:字符串 String star=“ab”;那么他对应的hash值就是:3105
怎么算出来的呢?
val[0]='a' ; val[1]='b'
a对应的Ascall码值为:97
b对的Ascall码值为:98
那么经过如下代码的循环相加
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
得出:97*31+98=3105;
我们再看: int h = hash;这一个代码,为什么有时候调用hashcode方法返回的hash值是负数呢?
因为如果这个字符串很长?那么h的值就会超过int类型的最大值,有没有想过,如果一个int类型的最大值,超过他的范围之后会怎么样呢?
我们先来看这样一个简单的代码:
int count=0;
while (true){
if (count++<10){
System.out.println("hello world");
}
}
大家认为hello world会输出多少次呢?
正常情况来说count小于10就不会输出了对么?
但是其实并不是这样的,很明确的告诉大家,这是一个死循环。
因为count一直加,最开始if成立,到后面的if不成立,再到后面if会再次成立,为什么会成立呢?因为count变为了负数。
???? 为什么?因为count一直无限制的加,由于是线性增长,计算速度是非常快的,所以,要不了多久,就会超出int类型的最大值。控制输出的count变为了负数,所以呢此时的if条件又成立了。

首先我们来看下int的范围 :int 为4个字节,一个字节为8位,一个int值是需要的存储空间是32位,但是呢?这是一个有符号位的int,需要一个符号位来表示正数和负数,
int值的范围就是:-2^31 ~ 2^31 也就是:-2147483648 到2147483647
我们来看下int最大值对应的二进制位是对少?

全是1? 2147483647最大值不是一个正数么?难道第一位难道不是应该用0表示么?
此时这个0他是省略掉了没写的,由于二进制系统是通过补码来保存数据的。第一位是符号位,0为正,1为负,当正的除了符号位全为1,再加1就进位了,符号位就会变成1,是负数,其他为0。
所以说当int的最大值加一个1,就变为了,最小值
来!口说无凭,没有说服力,我们直接来看代码:

那么我们在反过来想,最小值减1呢?那是不是就是对对应的是我们int类型的最大值了呀?
认真仔细的看完这个,你就知道为什么hashcode方法调用的时候有时候是正数,有时候是负数了吧?所以说底层还是很有意思的,比如往后做大数据开发,那么肯定是需要深入理解这些数据类型的范围,以及他的一个变化规则,否则有时候不知不觉的就犯错了,你还不知道错误在那儿?严重的话就是会损失精度,导致结果和你预期的结果相差甚远。就因为加了个1,就导致结果和预期结果相差十万八千里。
这是String类的hashcode方法的一个具体实现过程。
四、两个对象的 hashCode()相同,则 equals()也一定为 true,对吗?
首先呢?这个肯定是不对的。
因为这两个方法都可以重写,如果是自己的类,那么可以灵活重写,如果是jdk自己的类,那就要看他到底有没有重写这两个方法。
我们以String类的equlas方法为例:我们都知道,如果equlas方法如果没有重写,那就继承Object类的equlas方法,默认比较的是两个对象的内存地址,如果重写了,那就根据我们自己重写的规则来比较两个对象是否相等。
如下是jdkString类中自己重写的equals方法,
public boolean equals(Object anObject) {
// 如果两个String类型的对象内存地址相等直接返回true
if (this == anObject) {
return true;
}
// 如下做的操作就是比较两个字符串中的每一个char类型的数据,如果都完全匹配,那么就是返回true,如果有一个不相同,直接返回false,并且两个字符串的长度要相等,如果不相同,那么肯定也就不可能值一样了嘛
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
再看下String的hashcode方法:就是我们上面刚刚讲过的那个方法
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
1:如果两个String类型的对象内存地址相等直接返回true
2:比较两个字符串中的每一个char类型的数据,如果都完全匹配,那么就是返回true,如果有一个不相同,直接返回false,并且两个字符串的长度要相等,如果不相同,那么肯定也就不可能值一样了嘛
由此可以看出,equals方法是否返回true跟hashcode方法没有半毛钱关系嘛。
接下来我们看下,我们自定义的对象,我创建一个User类,里面有属性id和name
public class User {
int id;
String name;
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}
在没有重写hashcode方法和equals方法的情况下进行比较:
User user1 = new User();
User user2 = new User();
System.out.println(user1.hashCode());
System.out.println(user2.hashCode());
System.out.println(user1.equals(user2));

解答:因为我们没有重写,这两个方法都是继承自Object类的,所以呢?比较的是内存地址,因为我们是通过new的方式去创建的两个user对象,那么他们的内存地址肯定是不相同的,所以直接返回false,而hashcode方法是java的底层语言c++来写的,具体他内部是怎么实现的,封装了,我也就不得而知了,后面再了解,有的人说是跟内存地址相关,但是具体我没有看到具体实现,也不敢苟同,有的东西,需要自己不断的去摸索,自己亲自实践,才是真的,不要相信别人说的。
好的,接下来我们重写User类的hashcode方法:
public class User {
int id;
String name;
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
@Override
public int hashCode() {
return Objects.hash(id, name);
}
}

可以看到的是,我们两个User对象的hashcode方法返回的hash值是完全一致的,但是通过equals方法进行比较,还是false,所以说,两个对象的hashcode方法返回的hash值相同,equlas也一定返回true是完全不成立的,直接推翻。
接下来我们再次重写equlas方法,此时我们规定,只要两个对象的id和name都相同,那么这两个对象就是同一个对象。并且删除掉刚刚我们重写的hashcode方法。
public class User {
int id;
String name;
public User(int i, String name) {
this.id = id;
this.name = name;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return id == user.id &&
name.equals(user.name);
}
}

通过运行结果,我们可以看到,hashcode方法返回的hash值不一致,但是我们的equlas方法依旧返回的是true,因为这个equlas方法是我们重写过了,在调用的时候,就不在去掉Object的equlas方法,进行比较内存地址,而是按照我们的重写规则:如果两个user对象的id和name相同,那么就是同一个对象,所以到这里,你是不是就具体的理解了hashcode方法个equlas之间的关系呢?
如果还是不明白,那再看一次,我们现在把User类的equlas方法和hashcode方法都写上,但是呢?我会创建两i不同的User对象(也就是id和name都不一样)。
public class User {
int id;
String name;
public User(int i, String name) {
this.id = id;
this.name = name;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return id == user.id &&
name.equals(user.name);
}
@Override
public int hashCode() {
return Objects.hash(id, name);
}
}
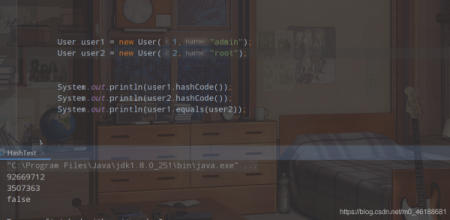
由此可以看到,虽然hashcode方法返回的hash值相同,但是通过equlas方法进行比较,返回的直接就是false。
这里我们说的有点啰嗦了哈,本来三言两语就可以说清楚的,但是怕新手朋友不理解,所以就多啰嗦了几句,这个文章是我个人的理解,如果有不正确的希望你多参考书以及官网进行比对,毕竟眼见为实嘛,我也不敢完全保证我就是对的。
到此这篇关于详解Java中的hashcode的文章就介绍到这了,更多相关Java hashcode内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

关于Java中HashCode方法的深入理解
1.0前言 最近在学习 Go 语言,Go 语言中有指针对象,一个指针变量指向了一个值的内存地址.学习过 C 语言的猿友应该都知道指针的概念.Go 语言语法与 C 相近,可以说是类 C 的编程语言,所以 Go 语言中有指针也是很正常的.我们可以通过将取地址符&放在一个变量前使用就会得到相应变量的内存地址. package main import "fmt" func main() { var a int= 20 /* 声明实际变量 */ var ip *int /* 声明指针变量
-
java 中HashCode重复的可能性
java 中HashCode重复的可能性 今天有同事提议用String的hashcode得到int类型作为主键.其实hashcode重复的可能性超大,下面是java的缺省算法: public int hashCode() { int h = hash; if (h == 0) { int off = offset; char val[] = value; int len = count; for (int i = 0; i < len; i++) { h = 31*h + val[off++];
-
Java中的hashcode方法介绍
哈希表这个数据结构想必大多数人都不陌生,而且在很多地方都会利用到hash表来提高查找效率.在Java的Object类中有一个方法: public native int hashCode(); 根据这个方法的声明可知,该方法返回一个int类型的数值,并且是本地方法,因此在Object类中并没有给出具体的实现. 为何Object类需要这样一个方法?它有什么作用呢?今天我们就来具体探讨一下hashCode方法. 一.hashCode方法的作用 对于包含容器类型的程序设计语言来说,基本上都会涉及到has
-
Java 覆盖equals时总要覆盖hashcode
Java 覆盖equals时总要覆盖hashcode 最近学习java 的基础知识,碰到Java 覆盖equals时总要覆盖hashcode时候有许多疑问,经过和同事直接讨论及上网查询的资料,这里整理下,也好帮助大家理解,代码中有说明. 具体实现代码: package cn.xf.cp.ch02.item9; import java.util.HashMap; import java.util.Map; public class PhoneNumber { private final short
-
细品Java8中hashCode方法的使用
简介 散列函数(英语:Hash function)又称散列算法.哈希函数,是一种从任何一种数据中创建小的数字"指纹"的方法.散列函数把消息或数据压缩成摘要,使得数据量变小,将数据的格式固定下来. Java语言对hashCode的应用 主要用途 hashcode是Object中的函数,所有类都拥有的一个函数,主要返回每个对象的hash值,主要用于哈希表中,如HashMap.HashTable.HashSet. 在这里需要注意的是,他就是为了在一些对象数组里面存储的时候可以节省空间.(我在
-
浅谈Java中的hashcode方法(推荐)
哈希表这个数据结构想必大多数人都不陌生,而且在很多地方都会利用到hash表来提高查找效率.在Java的Object类中有一个方法: public native int hashCode(); 根据这个方法的声明可知,该方法返回一个int类型的数值,并且是本地方法,因此在Object类中并没有给出具体的实现. 为何Object类需要这样一个方法?它有什么作用呢?今天我们就来具体探讨一下hashCode方法. 一.hashCode方法的作用 对于包含容器类型的程序设计语言来说,基本上都会涉及到has
-
Java 中HashCode作用_动力节点Java学院整理
第1 部分 hashCode的作用 Java集合中有两类,一类是List,一类是Set他们之间的区别就在于List集合中的元素师有序的,且可以重复,而Set集合中元素是无序不可重复的.对于List好处理,但是对于Set而言我们要如何来保证元素不重复呢?通过迭代来equals()是否相等.数据量小还可以接受,当我们的数据量大的时候效率可想而知(当然我们可以利用算法进行优化).比如我们向HashSet插入1000数据,难道我们真的要迭代1000次,调用1000次equals()方法吗?hashCod
-
java中为何重写equals时必须重写hashCode方法详解
前言 大家都知道,equals和hashcode是java.lang.Object类的两个重要的方法,在实际应用中常常需要重写这两个方法,但至于为什么重写这两个方法很多人都搞不明白. 在上一篇博文Java中equals和==的区别中介绍了Object类的equals方法,并且也介绍了我们可在重写equals方法,本章我们来说一下为什么重写equals方法的时候也要重写hashCode方法. 先让我们来看看Object类源码 /** * Returns a hash code value for
-
深入理解Java中HashCode方法
关于hashCode,维基百科中: In the Java programming language, every class implicitly or explicitly provides a hashCode() method, which digests the data stored in an instance of the class into a single hash value (a 32-bit signed integer). hashCode就是根据存储在一个对象实例
-
Java重写equals及hashcode方法流程解析
初步探索 首先我们要了解equals方法是什么,hashcode方法是什么. equals方法 equals 是java的obejct类的一个方法,equals的源码如下: public boolean equals(Object paramObject){ return(this == paramObject); } 由此我们可以看到equals是用来比较两个对象的内存地址是否相等. hashCode方法 hashCode方法是本地方法,用于计算出对象的一个散列值,用于判断在集合中对象是否重复
-
java中重写equals()方法的同时要重写hashcode()方法(详解)
object对象中的 public boolean equals(Object obj),对于任何非空引用值 x 和 y,当且仅当 x 和 y 引用同一个对象时,此方法才返回 true: 注意:当此方法被重写时,通常有必要重写 hashCode 方法,以维护 hashCode 方法的常规协定,该协定声明相等对象必须具有相等的哈希码.如下: (1) 当obj1.equals(obj2)为true时,obj1.hashCode() == obj2.hashCode()必须为true (2) 当obj