oracle索引的测试实例代码
前言
在测试oracle索引性能时大意了,没有仔细分析数据特点,将情况特此记录下来。
需求: 对一张100w记录的表的 stuname列进行查询,测试在建立索引与不建立索引的区别. 以下是开始用的创建代码及执行效果.
1. 随机数据生成代码分析
--为测试索引而准备的随机数据生成代码,先分析一下
select rownum as id,
'smith'||trunc(dbms_random.value(0, 100)) as stu_name,
dbms_random.string('x', 20) stu_pwd,
to_char(add_months(sysdate,-DBMS_RANDOM.VALUE(100,200)) + rownum / 24 / 3600, 'yyyy-mm-dd hh24:mi:ss') as birthday ,
decode( TRUNC(DBMS_RANDOM.VALUE(1,5)),1,'湖南省',2,'湖北省',3,'江西省','北京市') as address
from dual
connect by level <= 100;
--先分析以下上面的代码
-- 伪列: rownum
-- dual : 测试表
-- || 字符串联接
--1. 测试生成100条记录 connect by level<=100 :
--a、利用Oracle特有的“connect by”树形连接语法生成测试记录,“level <= 100”表示要生成100记录;
--b、利用rownum虚拟列生成递增的整数数据;
--c、利用sysdate函数加一些简单运算来生成日期数据,本例中是每条记录的时间加1秒;
-- add_months(sysdate,-DBMS_RANDOM.VALUE(100,200)) 用当前时间 减去 至少100个月,最多200个月,来生成生日
--d、利用dbms_random.value函数生成随机的数值型数据,都是double型,所以都加了 trunc( )以截断小数位,本例中是生成0到100之间的随机整数;
--e、利用dbms_random.string函数生成随机的字符型数据,本例中是生成长度为20的随机字符串,字符串中可以包括字符或数字。
2. 生成测试表及数据
--2. 正式生成100W
drop table stu_test_100w; --如果原来有,则先删除原来的表
--创建表及数据
create table stu_test_100w
as
select rownum as id,
'smith'||trunc(dbms_random.value(0, 99)) as stu_name,
dbms_random.string('x', 20) stu_pwd,
to_char(add_months(sysdate,-DBMS_RANDOM.VALUE(100,200)) + rownum / 24 / 3600, 'yyyy-mm-dd hh24:mi:ss') as birthday ,
decode( TRUNC(DBMS_RANDOM.VALUE(1,5)),1,'湖南省',2,'湖北省',3,'江西省','北京市') as address
from dual
connect by level <= 1000000; -- 生成 100w测试数据
-- 查看当前用户模式下所有的表 select * from tab where tname='STU_TEST_100W'; --先执行一次查询, 注意查询所用的时间,此时并没有加入索引 select * from stu_test_100w where stu_name='smith13';
执行结果:
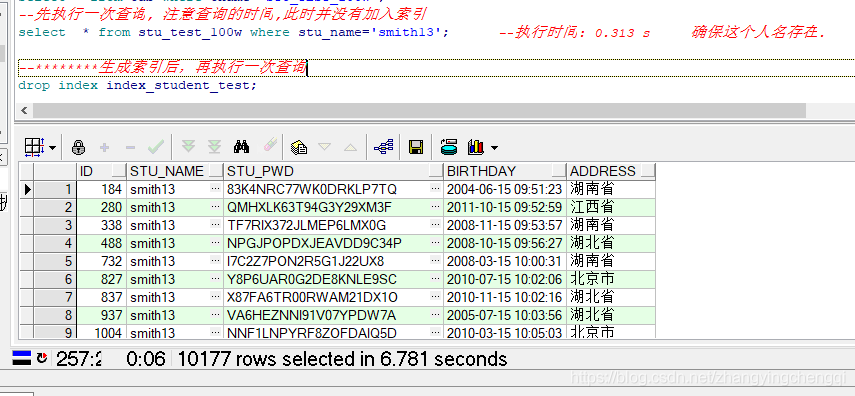
以上是没有用到索引时的执行用时 6.781秒.
下面创建索引后,再用同一查询来测试.
--********生成索引后,再执行一次查询 drop index index_student_test; create index index_student_test on stu_test_100w(stu_name); --索引是针对某个表的某个列 --先执行一次查询, 注意查询的时间,此时加入了索引 select * from stu_test_100w where stu_name='smith13';
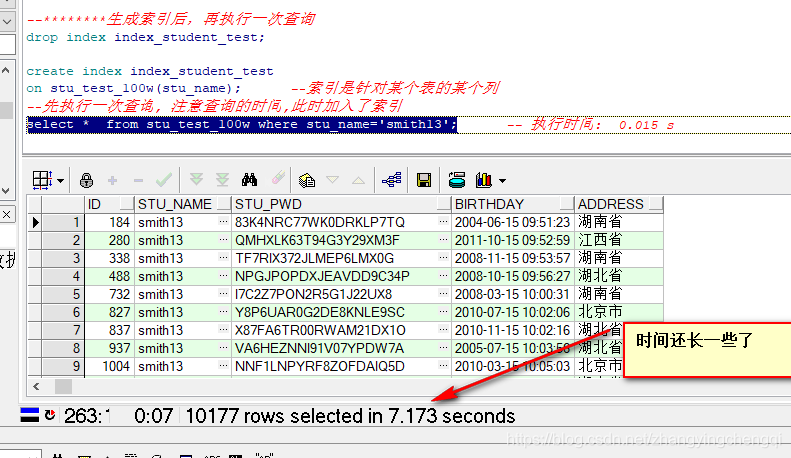
为什么用了索引后时间查询能还下降了呢????
分析如下:
1. 索引生成的字段的值分存得太密集了,查看上面的代码会发现我们stu_name只生成在了 smith0-99之间,即只有100种可能性, 对于100w数据则言,即每个名字都有约1w个.
2。 因为数据太密集了,所以以上查询的花的时间主要在1w条数据的显示上, 所以我们可以观察到不管是否用到了索引,都要共到6-7秒来显示结果.
3. 那为什么用了索引还慢一些呢? 这就与索引的存储结构有关系了.oracle默认使用的是B树索引, 当使用索引列查询时,查询必须先查看索引,通过索引去定位数据,而咱们的数据分布又比较密集,所以使用索引所导致的时间损耗要大于直接磁盘搜索的时间.
那么如何解决呢?
随机生成的姓名分布广一些(这与真实的数据也一样). 即将随机生成代码修改为 'smith'||trunc(dbms_random.value(0, 9999999)) as stu_name,
drop table stu_test_100w; --如果原来有,则先删除原来的表
--重新生成表及随机数据,注意 stu_name列的取值范围加大
create table stu_test_100w
as
select rownum as id,
'smith'||trunc(dbms_random.value(0, 9999999)) as stu_name,
dbms_random.string('x', 20) stu_pwd,
to_char(add_months(sysdate,-DBMS_RANDOM.VALUE(100,200)) + rownum / 24 / 3600, 'yyyy-mm-dd hh24:mi:ss') as birthday ,
decode( TRUNC(DBMS_RANDOM.VALUE(1,5)),1,'湖南省',2,'湖北省',3,'江西省','北京市') as address
from dual
connect by level <= 1000000;
--先执行一次查询, 注意查询的时间,此时并没有加入索引
select * from stu_test_100w where stu_name='smith8821228';
执行结果如下:
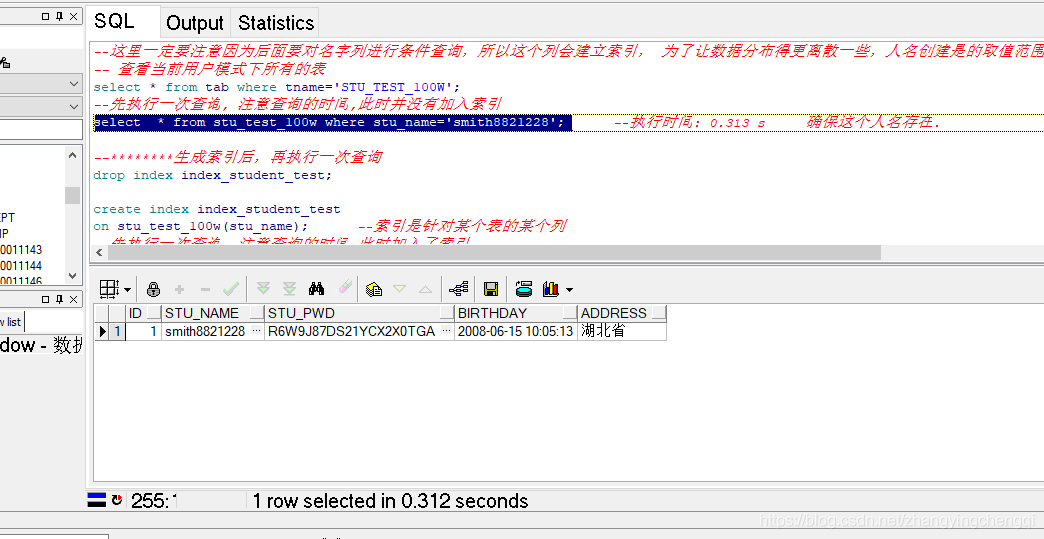
用时 0.312秒.
接着创建索引后,再测试同一个查询
--********生成索引后,再执行一次查询 drop index index_student_test; create index index_student_test on stu_test_100w(stu_name); --索引是针对某个表的某个列 --先执行一次查询, 注意查询的时间,此时加入了索引 select * from stu_test_100w where stu_name='smith8821228';
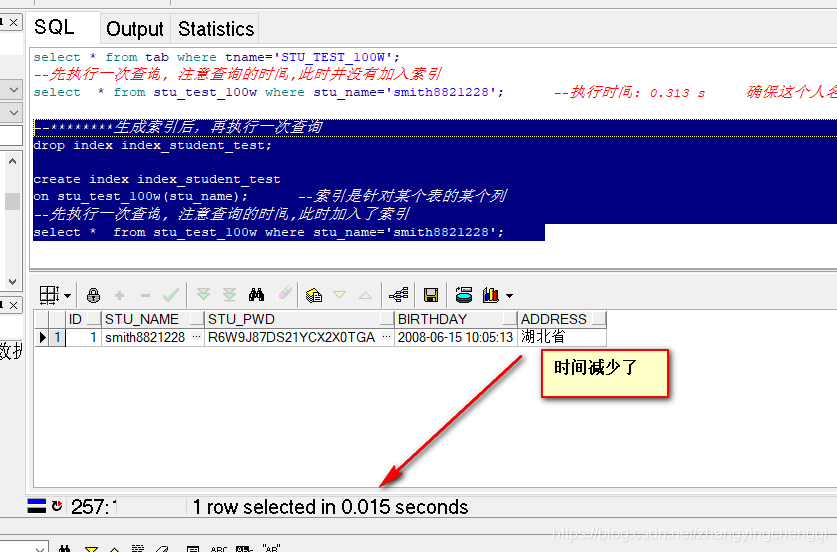
使用索引后,同一个查询只需0.015秒,在原来用时0.312的基础下,下降了n倍.
总结
到此这篇关于oracle索引测试的文章就介绍到这了,更多相关oracle索引测试内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Oracle数据库中建立索引的基本方法讲解
怎样建立最佳索引? 1.明确地创建索引 create index index_name on table_name(field_name) tablespace tablespace_name pctfree 5 initrans 2 maxtrans 255 storage ( minextents 1 maxextents 16382 pctincrease 0 ); 2.创建基于函数的索引 常用与UPPER.LOWER.TO_CHAR(date)等函数分类上,例: create index
-
Oracle 如何创建和使用全文索引
不使用Oracle text功能,也有很多方法可以在Oracle数据库中搜索文本.可以使用标准的INSTR函数和LIKE操作符实现. SELECT *FROM mytext WHERE INSTR (thetext, 'Oracle') > 0; SELECT * FROM mytext WHERE thetext LIKE '%Oracle%'; 有很多时候,使用instr和like是很理想的, 特别是搜索仅跨越很小的表的时候.然而通过这些文本定位的方法将导致全表扫描,对资源来说消耗比较昂贵,
-

Oracle Index索引无效的原因与解决方法
索引无效原因 最近遇到一个Oracle SQL语句的性能问题,修改功能之前的运行时间平均为0.3s,可是添加新功能后,时间达到了4~5s.虽然几张表的数据量都比较大(都在百万级以上),但是也都有正确创建索引,不知道到底慢在了哪里,下面展开调查. 经过几次排除,把问题范围缩小在索引上,首先在确定索引本身没有问题的前提下,考虑索引有没有被使用到,那么新的问题来了,怎么知道指定索引是否被启用. 判断索引是否被执行 1. 分析索引 即将索引至于监控状态下,对索引进行分析.如下对 ID_TT_SHOHOU
-
Oracle中如何把表和索引放在不同的表空间里
因为:1)提高性能:尽量把表和索引的表空间存储在不同在磁盘上,把两类不同IO性质的数据分开放,这样可以提高磁盘的IO总体性能: 2)便于管理:试想一下,如果索引的数据文件损坏,只要创建索引即可,不会引起数据丢失的问题. 下面语句用于移动索引的表空间: 复制代码 代码如下: alter index INDEX_OWNER.INDEX_NAME rebuild tablespace NEW_TBS; 也可以利用以下语句获得某个schema下移动索引表空间的所有语句: 复制代码 代码如下: selec
-
Oracle索引(B*tree与Bitmap)的学习总结
在Oracle中,索引基本分为以下几种:B*Tree索引,反向索引,降序索引,位图索引,函数索引,interMedia全文索引等,其中最常用的是B*Tree索引和Bitmap索引.(1).与索引相关视图查询DBA_INDEXES视图可得到表中所有索引的列表:访问USER_IND_COLUMNS视图可得到一个给定表中被索引的特定列.(2).组合索引概念当某个索引包含有多个已索引的列时,称这个索引为组合(concatented)索引.注意:只有在使用到索引的前导索引时才可以使用组合索引(3).B*T
-
oracle索引介绍(图文详解)
对于数据库来说,索引是一个必选项,但对于现在的各种大型数据库来说,索引可以大大提高数据库的性能,以至于它变成了数据库不可缺少的一部分. 索引分类:逻辑分类single column or concatenated 对一列或多列建所引unique or nonunique 唯一的和非唯一的所引,也就是对某一列或几列的键值(key)是否是唯一的.Function-based 基于某些函数索引,当执行某些函数时需要对其进行计算,可以将某些函数的计算结果事先保存并加以索引,提高效率. Doman
-
Oracle使用强制索引的方法与注意事项
Oracle使用强制索引 在一些场景下,可能ORACLE不会自动走索引,这时候,如果对业务清晰,可以尝试使用强制索引,测试查询语句的性能. 以EMP表为例: 先在EMP表中建立唯一索引,如图. 普通搜索: SELECT * FROM EMP T 查看执行计划: 可以看到,是走的全表扫描. 使用强制索引,在SELECT 后面加上/*.......*/ 中间加上索引的属性,代码如下: SELECT /*+index(t pk_emp)*/* FROM EMP T --强制索引,/*.....*/第一
-
Oracle轻松取得建表和索引的DDL语句
我们都知道在9i之前,要想获得建表和索引的语句是一件很麻烦的事.我们可以通过export with rows=no来得到,但它的输出因为格式的问题并不能直接拿来用.而另一种方法就是写复杂的脚本来查询数据字典,但这对于一稍微复杂的对象,如IOT和嵌套表等,还是无法查到. 从数据字典中获得DDL语句是经常要用的,特别是在系统升级/重建的时候.在Oracle 9i中,我们可以直接通过执行dbms_metadata从数据字典中查处DDL语句.使用这个功能强大的工具,我们可以获得单个对象或整个SCHEMA
-
Oracle关于重建索引争论的总结
索引重建是一个争论不休被不断热烈讨论的议题.当然Oracle官方也有自己的观点,我们很多DBA也是遵循这一准则来重建索引,那就是Oracle建议对于索引深度超过4级以及已删除的索引条目至少占有现有索引条目总数的20% 这2种情形下需要重建索引.近来Oracle也提出了一些与之相反的观点,就是强烈建议不要定期重建索引.本文是参考了1525787.1并进行相应描述. 1.重建索引的理由 a.Oracle的B树索引随着时间的推移变得不平衡(误解) b.索引碎片在不断增加 c.索引不断增
-
oracle 索引不能使用深入解析
较典型的问题有:有时,表明明建有索引,但查询过程显然没有用到相关的索引,导致查询过程耗时漫长,占用资源巨大,问题到底出在哪儿呢?按照以下顺序查找,基本上能发现原因所在. 查找原因的步骤 首先,我们要确定数据库运行在何种优化模式下,相应的参数是:optimizer_mode.可在svrmgrl中运行"showparameteroptimizer_mode"来查看.ORACLEV7以来缺省的设置应是"choose",即如果对已分析的表查询的话选择CBO,否则选择RBO.