Rainbond部署组件Statefulset的使用官方文档
目录
- 前言
- 组件部署类型
- 服务的“状态”
- 处理服务的 “状态”
前言
对于kubernetes老玩家而言,StatefulSet这种资源类型并不陌生。对于很多有状态服务而言,都可以使用 StatefulSet 这种资源类型来部署。那么问题来了:挖掘机技术哪家强?额,不对。
如何在 Rainbond 使用 StatefulSet 资源类型来部署服务呢?
组件部署类型
通过在服务组件的其他设置中,更改 组件部署类型 即可选择使用 StatefulSet 资源类型部署服务,操作之前要注意以下几点:
- 组件需要处于关闭的状态;
- 对于有持久化存储的服务组件,切换组件部署类型会导致存储挂载的变更,一定要做好数据备份;
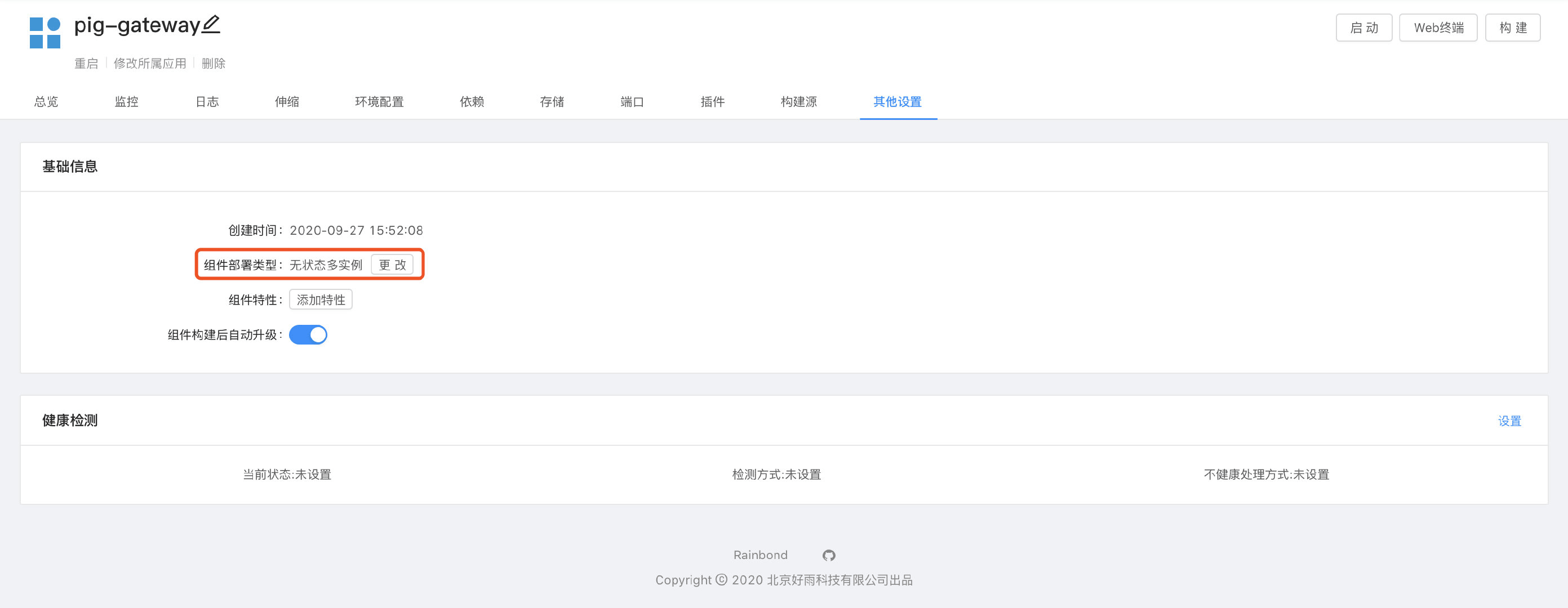
Rainbond 默认提供四种组件部署类型:

- 有状态单实例:使用 StatefulSet 部署服务,不可以进行实例的横向伸缩,实例数量始终为1;
- 有状态多实例:使用 StatefulSet 部署服务,实例数量可以进行横向伸缩;
- 无状态单实例:使用 Deployment 部署服务,不可以进行实例的横向伸缩,实例数量始终为1;
- 无状态多实例:使用 Deployment 部署服务,实例数量可以进行横向伸缩;
当你在 Rainbond 中将组件部署类型指定为有状态 (StatefulSet) 之后,服务组件将体现以下特性:
- 多实例状态下,所有实例将具备顺序性,实例的命名将类似于 gr6ec114-0 gr6ec114-1 ,这一顺序性将体现为全生命周期的层面,顺序的启动、更新、重启、关闭。
- 上述的主机名在集群中将可以被解析,同团队下,尝试在任意 POD 中执行nslookup gr6ec114-0。不同团队下,需要指定命名空间,可解析地址的完全地址为:gr6ec114-0.gr6ec114.3be96e95700a480c9b37c6ef5daf3566.svc.cluster.local 其中 3be96e95700a480c9b37c6ef5daf3566 为命名空间。
- 多实例状态下,每个实例的持久化存储将被单独挂载,这意味着持久化数据在实例之间不再共享。
- 单实例状态下,执行更新操作时,实例将会在完全关闭之后,启动新的实例,这意味着服务会出现中断。
- 出于对持久化数据一致性的保护,运行了有状态服务的 k8s 节点一旦失去和管理节点的联络,处于
notready状态时,其有状态服务的实例不会自动迁移。
整体来看,利用 StatefulSet 资源类型来部署服务,带来了新的特性的同时,会显得呆板了一些,但接下来的探讨,会发现这些限制是有意义的。
细心如你一定会发现,我们将 StatefulSet 这种资源类型和 “有状态” 绑定在了一起。那么,一个新的问题冒了出来:什么是服务的 “状态”。
服务的“状态”
有状态(Stateful)服务 = 无状态(Stateless)的应用程序 + 有状态的数据
从有状态服务的名字就可以看出, 它和 StatefulSet 这种资源类型是有关联的。
单纯说概念,可能很难理解什么是有状态服务。让我来举几个例子:
- 最常见的有状态服务,就是DB类的数据库中间件。
对于常见数据库 Mysql 而言,同一份数据,在同一时刻只可以被一个 Mysql 程序使用。Mysql 在启动后,会在自己的数据目录下生成唯一的锁文件,并把这个文件“锁死”。这样一来,其他想要使用这份数据的 Mysql 程序,会因为发现这个锁文件被“锁死”,而中断启动的过程。这样做的好处,是保证了数据的强一致性,因为同一份数据在同一时刻,绝对只会被同一个 Mysql 应用程序所读写。
请回忆下 StatefulSet 资源类型带来的特性之一就是每个实例都会挂载独立的持久化存储,这样可以确保 Mysql 服务可以被扩展成多个实例运行起来,不会因为锁文件的原因被终止启动,但是因为彼此之间数据不共享,所以本质上实例之间没有什么关系。使用有状态单实例的方式运行 Mysql 看起来是最正确的选择。
情况类似的常见数据库中间件还有 Mongo、Postgresql、Redis、Etcd等。
- 另一种常见的有状态服务场景,是 Web 类的服务提供的粘性
Session。
这种粘性 Session 在某些情况下会保存在内存中,用来提供会话保持,本身也是一种数据。一旦将这种服务扩展多个实例,一旦访问到不正确的实例,那么就会因为找不到 Session 而丢失登陆态。在负载均衡中使用 IP Hash 算法进行流量的分发可以在某种程度上解决这个问题,来自同个 IP 的流量会被分发到指定的实例。但是我们更希望流量的分发是轮询的,这样可以确保每个实例的负载都是相近的,不会出现某个实例负载过高,而其他实例无所事事的情况。
这两种有状态服务场景,都向我们指出,对有状态服务而言,不同实例的数据是相互独立的。数据即“状态”。
相比较而言,无状态的服务就灵活很多。它们没有持久化数据,或者持久化数据支持共享。对于客户端而言,请求哪一个实例获得的返回都是一致的。这样的特性意味着可以随意扩展无状态服务的实例数量,灵活的应对流量。
使用云服务最大的好处之一,就是它提供的弹性和灵活性,在业务遭遇流量高峰时,可以快速扩展实例进行应对。从这个角度出发,我们希望服务都是 “无状态” 的。那么,一个新的问题冒了出来:我们可以去掉服务的 “状态”,使之变成无状态服务么?
处理服务的 “状态”
利用粘性 Session 保持登陆态的这类 Web 服务,其状态是可以被去掉的。
原理比较简单,把 Session 和 Web 应用程序剥离,存储到其他中间件中去即可,比如保存到Mysql、 Redis、Memcached等数据库中间件中去。市面上常见的 Web 框架都会支持这种功能,甚至把这种处理方式作为默认选项,因为这实在太棒了!
处理完的 Web 服务,就变成了无状态服务,可以任意扩展实例数量了。来自客户端的请求无论被分配到哪一个实例,其登陆态都到后端数据库中调取,返回正确的登陆态。在部署时,可以选择无状态多实例进行部署,即使用 Deployment 这种资源类型。
但是对于DB类的数据库中间件而言,其状态是不可以被随意去除的。
原因在于这类数据库中间件使用自己的机制来确保数据强一致性,就比如 Mysql 的锁文件机制,指定的实例只能去读写对应自己的那一份数据。对这一类有状态服务而言,每个实例独享一份持久化数据可以算作是必须的条件。并且随意扩展实例数量,会遭遇很多致命的问题:比如数据不一致,或者程序运行失败等等。这一类的有状态服务只能单点部署吗?
这些数据库中间件的出品厂商或者社区,也都很关注如何实现高可用方案,来解决上述的问题。甚至近些年推出的数据库中间件,在设计阶段就会被设计成分布式架构。比如 Etcd 对自己的定义就是:可靠的强一致性分布式键值数据库。其内部使用 Raft 协议进行实例间选举来明确统一的leader。而对于 Mysql 这样比较老牌的数据库中间件,也具备基于 Binlog 复制实现的主从集群方案。
所以针对这一类无法去除状态的服务而言,我们的思路与宗旨,就是遵循其自身支持的集群方案,来实现高可用以及实例数量扩展。
实际部署这些集群方案时,可以总结出,大多数集群方案需要满足以下条件:
- 每个实例挂载单独的持久化数据;
- 实例间需要获取彼此的通信地址,来进行选举或者数据同步等动作,比如可解析的主机名或域名。获取地址时一定要使用主机名或域名而非实例 IP,因为随着实例的重启,主机名或域名不会改变,但是IP可能会改变,这很重要;
- 实例数量是有要求的,一般情况下选择 3、5、7··· 等奇数,来保证集群不会出现脑裂;
回想一下 StatefulSet 资源类型的特性,它可以满足上述的所有条件,就是为了有状态服务而生的。所以这一类有状态服务,其组件部署类型无论如何要使用有状态单/多实例。
以上就是Rainbond部署组件Statefulset的使用官方文档的详细内容,更多关于Rainbond部署组件Statefulse官方文档的资料请关注我们其它相关文章!
相关推荐
-

Rainbond自动部署初始化Schema的数据库步骤教程
目录 为什么使用Rainbond? Schema初始化在传统模式中一般有两种方案: 目录结构 Dockerfile文件 为什么使用Rainbond? 我们使用容器的方式部署数据库组件,特别是企业有大量的项目开发业务的,部署的开发.测试数据库组件较多时.经常会遇到以下问题: 业务需要使用数据库,但部署完数据库后,需要在数据库中执行创建schema的操作或者一些初始化数据的创建. 开发测试多套部署环境,需要多次重复1的步骤. 项目比较多,时间久了项目需要的数据库Schema不清楚. 项目交付时数据库
-
Rainbond云原生部署开源社区Discourse的配置过程
目录 概述 基于应用市场快速安装 Discourse应用如何制作 获取镜像 环境的要求 获取discourse_docker 配置模版 自定义配置 构建数据库镜像 redis 部署 postgresql部署 部署Discourse_web 建立依赖 访问 一些踩过的坑 邮件配置 数据恢复 概述 Discourse 是一个完全开源的论坛平台.具有丰富的插件库与主题库,适用于开源社区的构建.Rainbond官方社区就是基于Discourse搭建的实际案例. Rainbond官方社区建立之初就已经使用
-
Rainbond云原生快捷部署生产可用的Gitlab步骤详解
目录 Gitlab简介 准备工作 部署步骤 部署Postgresql组件 部署Redis组件 部署Gitlab-Server组件 配置网关访问策略 FAQ Gitlab简介 GitLab是利用 Ruby on Rails 一个开源的版本管理系统,实现一个自托管的Git项目仓库,可通过Web界面进行访问公开的或者私人项目.它拥有与Github类似的功能,能够浏览源代码,管理缺陷和注释.同时Gitlab集成了一系列的CI功能.不得不说,Gitlab在企业中是的使用率非常高. Rainbond非常推荐
-
Rainbond对前端项目Vue及React的持续部署
目录 前言: 部署前检查 1.1 添加 nodestatic.json 文件 1.2 添加 web.conf 文件 1.3 源码部署Vue项目 常见问题 前言: 以往我们在部署 Vue.React 前端项目有几种方法: 项目打包好之后生成dist目录,将其放入nginx中,并进行相应的访问配置. 将项目打包好放入tomcat中. 将项目打包好的dist目录中的static和index.html文件放入springboot项目的resources目录下 直接运行一个前端server,类似本地开发那
-
Rainbond配置组件自动构建部署官方文档讲解
目录 前言 前提条件 基于源代码操作流程 1.开启组件 Git-Webhook 2.配置代码仓库 基于镜像仓库操作流程 1.开启镜像仓库 Webhook 自动构建 2.Tag 触发自动修改策略 3.配置镜像仓库 API 触发自动构建 前言 通过自动构建的功能,可以实现代码或镜像提交后组件自动触发构建和部署,Rainbond 提供了基于代码仓库 Webhooks.镜像仓库 Webhooks 和自定义 API 三种方式触发组件自动部署.自动构建的功能可以辅助开发者便捷的实现敏捷开发. 前提条件 组件
-
Rainbond上部署API Gateway Kong及环境配置教程
目录 什么是Kong 从应用市场快速安装 注意事项 配置Kong 环境变量 注入Nginx配置 注入单个Nginx配置 通过注入的Nginx指令包含文件 Kong应用怎么制作 数据库自动初始化 部署Kong 部署Konga 发布应用 什么是Kong Kong是一个可扩展的开源API平台(也称为API网关,API中间件或微服务服务网格).Kong最初是由Kong Inc.(以前称为Mashape)实现的,用于为其API Marketplace维护.管理和扩展超过15,000个微服务,这些微服务每月
-
Rancher部署配置开源Rainbond云原生应用管理平台
目录 前言 前提条件 开始安装 添加 Rainbond Operator 到应用商店 安装 Rainbond Operator 访问 Rainbond 安装 UI,完善集群配置 基于 Rancher 的 Rainbond 运维参考 查看 Rainbond 各组件运行状态与日志 按需扩容 Rainbond 各组件 Rancher用户使用Rainbond优势 参考视频 常见问题 前言 本文适用于正在使用 Rancher 或对 Rancher 有所了解的用户 Rancher,Kubernetes 生态
-
Rainbond云原生部署SpringCloud应用架构实践
目录 示例项目详情 模块说明: 部署环境说明: 模块构建 部署 Mysql 部署 Redis 部署 pig-ui 依赖与端口梳理 最终成果 示例项目详情 本文档以Pig 快速开发框架为例,演示如何在Rainbond上部署一套完整的Spring Cloud项目. Pig Microservice Architecture V2.1.0: 基于 Spring Cloud Finchley .Spring Security OAuth2 的RBAC权限管理系统 基于数据驱动视图的理念封装 Elemen
-
Rainbond部署组件Statefulset的使用官方文档
目录 前言 组件部署类型 服务的“状态” 处理服务的 “状态” 前言 对于kubernetes老玩家而言,StatefulSet这种资源类型并不陌生.对于很多有状态服务而言,都可以使用 StatefulSet 这种资源类型来部署.那么问题来了:挖掘机技术哪家强?额,不对. 如何在 Rainbond 使用 StatefulSet 资源类型来部署服务呢? 组件部署类型 通过在服务组件的其他设置中,更改 组件部署类型 即可选择使用 StatefulSet 资源类型部署服务,操作之前要注意以下几点: 组
-
Rainbond应用分享与发布官方文档说明
目录 应用分享与发布 应用分享 应用发布流程 完善应用信息 提交发布任务 确认发布 编辑应用发布信息 应用分享与发布 应用分享 应用市场定义了支持大型分布式的数字化业务系统的标准云原生应用模型.它可以包含1-N个服务组件,模型包含其中每个服务组件资源及配置,插件资源及配置,拓扑关系.部署关系等.精心制作完成即可一键发布.一键安装. 在Rainbond中,组件是Rainbond可管理的最小服务单元,用户可以将多个组件组成一个复杂的业务系统,这套业务系统可以对外提供服务,也可以分享给其他组织独立部署
-
Rainbond网络治理插件ServiceMesh官方文档说明
目录 ServiceMesh网络治理插件 插件实践 综合网络治理插件 入站方向 出站方向 出站网络治理插件 ServiceMesh网络治理插件 5.1.5版本后,Rainbond默认提供了综合网络治理插件(同时处理入站和出站网络)和出站网络治理插件两个插件可用. 网络治理插件工作在与业务容器同一个网络空间之中,可以监听一个分配端口,拦截入站的业务流量进行限流.断路等处理再将流量负载到业务服务的实际监听端口之上. 同时也可以工作在出站方向,业务服务需要访问上游服务时,通过访问本地出站治理
-
Vue官方文档梳理之全局配置
本文主要介绍了Vue官方文档梳理之全局配置,分享给大家,也给自己留个笔记.具体如下: optionMergeStrategies 用于自定义选项的合并策略,Vue已经预定义了一些自己配置项的合并策略,如下图所示. 比如props.methods.computed就是同一个策略:子配置项会覆盖父级配置项.源码如下: var strats = config.optionMergeStrategies; strats.props = strats.methods = strats.computed =
-
fullCalendar中文API官方文档
1. 使用方式: 引入相关js, css后, $('#div_name').fullCalendar({//options}); 接受的是一个option对象 2. 普通属性 2.1. year, month, date: 整数, 初始化加载时的日期. 2.2. defaultView: 字符串类型, 默认是'month; 2.2.1. 允许的views: 2.2.1.1. month 一页显示一月, 日历样式 2.2.1.2. basicWeek 一页显示一周, 无特殊样式 2.2.1.3.
-
iPhone X官方文档的适配学习详解
前言 官方文档原文地址:链接,iPhone X在文中均用iPX来表示,iPhone 7在文中均用iP7来表示 屏幕尺寸 iPX的屏幕尺寸是2436px×1125px(812pt×375pt @ 3x),也就是说我们依然使用的是3x的素材应该影响不大,他和iP7在宽度上是一致的,但是高度上多了145个点. 布局 最好在真机上预览一下布局. 布局需要延伸到边缘,另外在纵向高度上最好可以根据不同情境滚动. 状态栏的高度已经改变了,如果布局没有使用系统的导航栏,或者布局是依照导航栏来的,那么需要重新适配
-
深入理解Vue官方文档梳理之全局API
Vue.extend 配置项data必须为function,否则配置无效.data的合并规则(可以看<Vue官方文档梳理-全局配置>)源码如下: 传入非function类型的data(上图中data配置为{a:1}),在合并options时,如果data不是function类型,开发版会发出警告,然后直接返回了parentVal,这意味着extend传入的data选项被无视了. 我们知道实例化Vue的时候,data可以是对象,这里的合并规则不是通用的吗?注意上面有个if(!vm)的判断,实例化
-
利用python查看官方文档
离线版本Python Mannuals,直接开始菜单搜索就行,Module Docs是安装模块的文档,点开在浏览器打开 或者安装Python目录下找Doc点进去 比如查看python内置的函数 像re,tkinter在D:\Python36\lib下,jupyter,mysql安装在D:\Python36\lib\site-packages下 官网点击Docs https://docs.python.org/3/ 到此这篇关于利用python查看官方文档的文章就介绍到这了,更多相关python查
-
pytest官方文档解读fixtures调用fixtures及fixture复用性
目录 fixtures调用其他fixtures及fixture复用性 一.Fixtures调用别的Fixtures 二.Fixtures的复用性 fixtures调用其他fixtures及fixture复用性 pytest最大的优点之一就是它非常灵活. 它可以将复杂的测试需求简化为更简单和有组织的函数,然后这些函数可以根据自身的需求去依赖别的函数. fixtures可以调用别的fixtures正是灵活性的体现之一. 一.Fixtures调用别的Fixtures 直接看一个简单示例: import