Jaeger Client Go入门并实现链路追踪
目录
- Jaeger
- 部署 Jaeger
- 从示例了解 Jaeger Client Go
- 了解 trace、span
- tracer 配置
- Sampler 配置
- Reporter 配置
- 分布式系统与span
- 怎么调、怎么传
- HTTP,跨进程追踪
- 客户端
- Web 服务端
- Tag 、 Log 和 Ref
Jaeger
OpenTracing 是开放式分布式追踪规范,OpenTracing API 是一致,可表达,与供应商无关的API,用于分布式跟踪和上下文传播。
OpenTracing 的客户端库以及规范,可以到 Github 中查看:https://github.com/opentracing/
Jaeger 是 Uber 开源的分布式跟踪系统,详细的介绍可以自行查阅资料。
部署 Jaeger
这里我们需要部署一个 Jaeger 实例,以供微服务以及后面学习需要。
使用 Docker 部署很简单,只需要执行下面一条命令即可:
docker run -d -p 5775:5775/udp -p 16686:16686 -p 14250:14250 -p 14268:14268 jaegertracing/all-in-one:latest
访问 16686 端口,即可看到 UI 界面。
后面我们生成的链路追踪信息会推送到此服务,而且可以通过 Jaeger UI 查询这些追踪信息。

从示例了解 Jaeger Client Go
这里,我们主要了解一些 Jaeger Client 的接口和结构体,了解一些代码的使用。
为了让读者方便了解 Trace、Span 等,可以看一下这个 Json 的大概结构:
{
"traceID": "2da97aa33839442e",
"spans": [
{
"traceID": "2da97aa33839442e",
"spanID": "ccb83780e27f016c",
"flags": 1,
"operationName": "format-string",
"references": [...],
"tags": [...],
"logs": [...],
"processID": "p1",
"warnings": null
},
... ...
],
"processes": {
"p1": {
"serviceName": "hello-world",
"tags": [...]
},
"p2": ...,
"warnings": null
}
创建一个 client1 的项目,然后引入 Jaeger client 包。
go get -u github.com/uber/jaeger-client-go/
然后引入包
import ( "github.com/uber/jaeger-client-go" )
了解 trace、span
链路追踪中的一个进程使用一个 trace 实例标识,每个服务或函数使用一个 span 标识,jaeger 包中有个函数可以创建空的 trace:
tracer := opentracing.GlobalTracer() // 生产中不要使用
然后就是调用链中,生成父子关系的 Span:
func main() {
tracer := opentracing.GlobalTracer()
// 创建第一个 span A
parentSpan := tracer.StartSpan("A")
defer parentSpan.Finish() // 可手动调用 Finish()
}
func B(tracer opentracing.Tracer,parentSpan opentracing.Span){
// 继承上下文关系,创建子 span
childSpan := tracer.StartSpan(
"B",
opentracing.ChildOf(parentSpan.Context()),
)
defer childSpan.Finish() // 可手动调用 Finish()
}
每个 span 表示调用链中的一个结点,每个结点都需要明确父 span。
现在,我们知道了,如何生成 trace{span1,span2},且 span1 -> span2 即 span1 调用 span2,或 span1 依赖于 span2。
tracer 配置
由于服务之间的调用是跨进程的,每个进程都有一些特点的标记,为了标识这些进程,我们需要在上下文间、span 携带一些信息。
例如,我们在发起请求的第一个进程中,配置 trace,配置服务名称等。
// 引入 jaegercfg "github.com/uber/jaeger-client-go/config"
cfg := jaegercfg.Configuration{
ServiceName: "client test", // 对其发起请求的的调用链,叫什么服务
Sampler: &jaegercfg.SamplerConfig{
Type: jaeger.SamplerTypeConst,
Param: 1,
},
Reporter: &jaegercfg.ReporterConfig{
LogSpans: true,
},
}
Sampler 是客户端采样率配置,可以通过 sampler.type 和 sampler.param 属性选择采样类型,后面详细聊一下。
Reporter 可以配置如何上报,后面独立小节聊一下这个配置。
传递上下文的时候,我们可以打印一些日志:
jLogger := jaegerlog.StdLogger
配置完毕后就可以创建 tracer 对象了:
tracer, closer, err := cfg.NewTracer(
jaegercfg.Logger(jLogger),
)
defer closer.Close()
if err != nil {
}
完整代码如下:
import (
"github.com/opentracing/opentracing-go"
"github.com/uber/jaeger-client-go"
jaegercfg "github.com/uber/jaeger-client-go/config"
jaegerlog "github.com/uber/jaeger-client-go/log"
)
func main() {
cfg := jaegercfg.Configuration{
ServiceName: "client test", // 对其发起请求的的调用链,叫什么服务
Sampler: &jaegercfg.SamplerConfig{
Type: jaeger.SamplerTypeConst,
Param: 1,
},
Reporter: &jaegercfg.ReporterConfig{
LogSpans: true,
},
}
jLogger := jaegerlog.StdLogger
tracer, closer, err := cfg.NewTracer(
jaegercfg.Logger(jLogger),
)
defer closer.Close()
if err != nil {
}
// 创建第一个 span A
parentSpan := tracer.StartSpan("A")
defer parentSpan.Finish()
B(tracer,parentSpan)
}
func B(tracer opentracing.Tracer, parentSpan opentracing.Span) {
// 继承上下文关系,创建子 span
childSpan := tracer.StartSpan(
"B",
opentracing.ChildOf(parentSpan.Context()),
)
defer childSpan.Finish()
}
启动后:
2021/03/30 11:14:38 Initializing logging reporter 2021/03/30 11:14:38 Reporting span 689df7e83255d05d:75668e8ed5ec61da:689df7e83255d05d:1 2021/03/30 11:14:38 Reporting span 689df7e83255d05d:689df7e83255d05d:0000000000000000:1 2021/03/30 11:14:38 DEBUG: closing tracer 2021/03/30 11:14:38 DEBUG: closing reporter
Sampler 配置
sampler 配置代码示例:
Sampler: &jaegercfg.SamplerConfig{
Type: jaeger.SamplerTypeConst,
Param: 1,
}
这个 sampler 可以使用 jaegercfg.SamplerConfig,通过 type、param 两个字段来配置采样器。
为什么要配置采样器?因为服务中的请求千千万万,如果每个请求都要记录追踪信息并发送到 Jaeger 后端,那么面对高并发时,记录链路追踪以及推送追踪信息消耗的性能就不可忽视,会对系统带来较大的影响。当我们配置 sampler 后,jaeger 会根据当前配置的采样策略做出采样行为。
详细可以参考:https://www.jaegertracing.io/docs/1.22/sampling/
jaegercfg.SamplerConfig 结构体中的字段 Param 是设置采样率或速率,要根据 Type 而定。
下面对其关系进行说明:
| Type | Param | 说明 |
|---|---|---|
| "const" | 0或1 | 采样器始终对所有 tracer 做出相同的决定;要么全部采样,要么全部不采样 |
| "probabilistic" | 0.0~1.0 | 采样器做出随机采样决策,Param 为采样概率 |
| "ratelimiting" | N | 采样器一定的恒定速率对tracer进行采样,Param=2.0,则限制每秒采集2条 |
| "remote" | 无 | 采样器请咨询Jaeger代理以获取在当前服务中使用的适当采样策略。 |
sampler.Type="remote"/sampler.Type=jaeger.SamplerTypeRemote 是采样器的默认值,当我们不做配置时,会从 Jaeger 后端中央配置甚至动态地控制服务中的采样策略。
Reporter 配置
看一下 ReporterConfig 的定义。
type ReporterConfig struct {
QueueSize int `yaml:"queueSize"`
BufferFlushInterval time.Duration
LogSpans bool `yaml:"logSpans"`
LocalAgentHostPort string `yaml:"localAgentHostPort"`
DisableAttemptReconnecting bool `yaml:"disableAttemptReconnecting"`
AttemptReconnectInterval time.Duration
CollectorEndpoint string `yaml:"collectorEndpoint"`
User string `yaml:"user"`
Password string `yaml:"password"`
HTTPHeaders map[string]string `yaml:"http_headers"`
}
Reporter 配置客户端如何上报追踪信息的,所有字段都是可选的。
这里我们介绍几个常用的配置字段。
- QUEUESIZE,设置队列大小,存储采样的 span 信息,队列满了后一次性发送到 jaeger 后端;defaultQueueSize 默认为 100;
- BufferFlushInterval 强制清空、推送队列时间,对于流量不高的程序,队列可能长时间不能满,那么设置这个时间,超时可以自动推送一次。对于高并发的情况,一般队列很快就会满的,满了后也会自动推送。默认为1秒。
- LogSpans 是否把 Log 也推送,span 中可以携带一些日志信息。
- LocalAgentHostPort 要推送到的 Jaeger agent,默认端口 6831,是 Jaeger 接收压缩格式的 thrift 协议的数据端口。
- CollectorEndpoint 要推送到的 Jaeger Collector,用 Collector 就不用 agent 了。
例如通过 http 上传 trace:
Reporter: &jaegercfg.ReporterConfig{
LogSpans: true,
CollectorEndpoint: "http://127.0.0.1:14268/api/traces",
},
据黑洞大佬的提示,HTTP 走的就是 thrift,而 gRPC 是 .NET 特供,所以 reporter 格式只有一种,而且填写 CollectorEndpoint,我们注意要填写完整的信息。
完整代码测试:
import (
"bufio"
"github.com/opentracing/opentracing-go"
"github.com/uber/jaeger-client-go"
jaegercfg "github.com/uber/jaeger-client-go/config"
jaegerlog "github.com/uber/jaeger-client-go/log"
"os"
)
func main() {
var cfg = jaegercfg.Configuration{
ServiceName: "client test", // 对其发起请求的的调用链,叫什么服务
Sampler: &jaegercfg.SamplerConfig{
Type: jaeger.SamplerTypeConst,
Param: 1,
},
Reporter: &jaegercfg.ReporterConfig{
LogSpans: true,
CollectorEndpoint: "http://127.0.0.1:14268/api/traces",
},
}
jLogger := jaegerlog.StdLogger
tracer, closer, _ := cfg.NewTracer(
jaegercfg.Logger(jLogger),
)
// 创建第一个 span A
parentSpan := tracer.StartSpan("A")
// 调用其它服务
B(tracer, parentSpan)
// 结束 A
parentSpan.Finish()
// 结束当前 tracer
closer.Close()
reader := bufio.NewReader(os.Stdin)
_, _ = reader.ReadByte()
}
func B(tracer opentracing.Tracer, parentSpan opentracing.Span) {
// 继承上下文关系,创建子 span
childSpan := tracer.StartSpan(
"B",
opentracing.ChildOf(parentSpan.Context()),
)
defer childSpan.Finish()
}
运行后输出结果:
2021/03/30 15:04:15 Initializing logging reporter 2021/03/30 15:04:15 Reporting span 715e0af47c7d9acb:7dc9a6b568951e4f:715e0af47c7d9acb:1 2021/03/30 15:04:15 Reporting span 715e0af47c7d9acb:715e0af47c7d9acb:0000000000000000:1 2021/03/30 15:04:15 DEBUG: closing tracer 2021/03/30 15:04:15 DEBUG: closing reporter 2021/03/30 15:04:15 DEBUG: flushed 1 spans 2021/03/30 15:04:15 DEBUG: flushed 1 spans
打开 Jaeger UI,可以看到已经推送完毕(http://127.0.0.1:16686)。
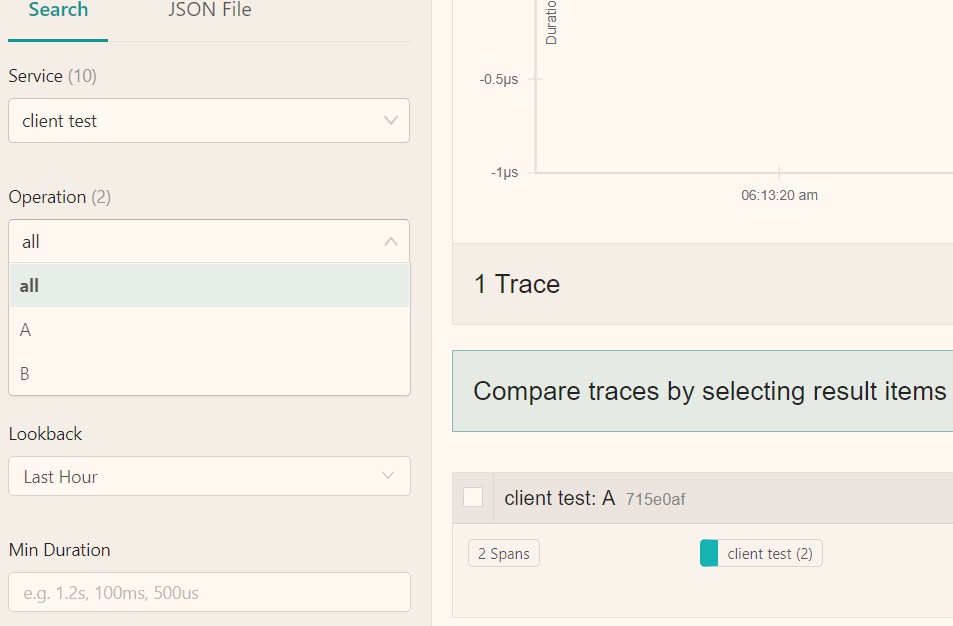
这时,我们可以抽象代码代码示例:
func CreateTracer(servieName string) (opentracing.Tracer, io.Closer, error) {
var cfg = jaegercfg.Configuration{
ServiceName: servieName,
Sampler: &jaegercfg.SamplerConfig{
Type: jaeger.SamplerTypeConst,
Param: 1,
},
Reporter: &jaegercfg.ReporterConfig{
LogSpans: true,
// 按实际情况替换你的 ip
CollectorEndpoint: "http://127.0.0.1:14268/api/traces",
},
}
jLogger := jaegerlog.StdLogger
tracer, closer, err := cfg.NewTracer(
jaegercfg.Logger(jLogger),
)
return tracer, closer, err
}
这样可以复用代码,调用函数创建一个新的 tracer。这个记下来,后面要用。
分布式系统与span
前面介绍了如何配置 tracer 、推送数据到 Jaeger Collector,接下来我们聊一下 Span。请看图。
下图是一个由用户 X 请求发起的,穿过多个服务的分布式系统,A、B、C、D、E 表示不同的子系统或处理过程。
在这个图中, A 是前端,B、C 是中间层、D、E 是 C 的后端。这些子系统通过 rpc 协议连接,例如 gRPC。
一个简单实用的分布式链路追踪系统的实现,就是对服务器上每一次请求以及响应收集跟踪标识符(message identifiers)和时间戳(timestamped events)。
这里,我们只需要记住,从 A 开始,A 需要依赖多个服务才能完成任务,每个服务可能是一个进程,也可能是一个进程中的另一个函数。这个要看你代码是怎么写的。后面会详细说一下如何定义这种关系,现在大概了解一下即可。

怎么调、怎么传
如果有了解过 Jaeger 或读过 分布式链路追踪框架的基本实现原理 ,那么已经大概了解的 Jaeger 的工作原理。
jaeger 是分布式链路追踪工具,如果不用在跨进程上,那么 Jaeger 就失去了意义。而微服务中跨进程调用,一般有 HTTP 和 gRPC 两种,下面将来讲解如何在 HTTP、gPRC 调用中传递 Jaeger 的 上下文。
HTTP,跨进程追踪
A、B 两个进程,A 通过 HTTP 调用 B 时,通过 Http Header 携带 trace 信息(称为上下文),然后 B 进程接收后,解析出来,在创建 trace 时跟传递而来的 上下文关联起来。
一般使用中间件来处理别的进程传递而来的上下文。inject 函数打包上下文到 Header 中,而 extract 函数则将其解析出来。

这里我们分为两步,第一步从 A 进程中传递上下文信息到 B 进程,为了方便演示已经实践,我们使用 client-webserver 的形式,编写代码。
客户端
在 A 进程新建一个方法:
// 请求远程服务,获得用户信息
func GetUserInfo(tracer opentracing.Tracer, parentSpan opentracing.Span) {
// 继承上下文关系,创建子 span
childSpan := tracer.StartSpan(
"B",
opentracing.ChildOf(parentSpan.Context()),
)
url := "http://127.0.0.1:8081/Get?username=痴者工良"
req,_ := http.NewRequest("GET", url, nil)
// 设置 tag,这个 tag 我们后面讲
ext.SpanKindRPCClient.Set(childSpan)
ext.HTTPUrl.Set(childSpan, url)
ext.HTTPMethod.Set(childSpan, "GET")
tracer.Inject(childSpan.Context(), opentracing.HTTPHeaders, opentracing.HTTPHeadersCarrier(req.Header))
resp, _ := http.DefaultClient.Do(req)
_ = resp // 丢掉
defer childSpan.Finish()
}
然后复用前面提到的 CreateTracer 函数。
main 函数改成:
func main() {
tracer, closer, _ := CreateTracer("UserinfoService")
// 创建第一个 span A
parentSpan := tracer.StartSpan("A")
// 调用其它服务
GetUserInfo(tracer, parentSpan)
// 结束 A
parentSpan.Finish()
// 结束当前 tracer
closer.Close()
reader := bufio.NewReader(os.Stdin)
_, _ = reader.ReadByte()
}
完整代码可参考:https://github.com/whuanle/DistributedTracingGo/issues/1
Web 服务端
服务端我们使用 gin 来搭建。
新建一个 go 项目,在 main.go 目录中,执行 go get -u github.com/gin-gonic/gin。
创建一个函数,该函数可以从创建一个 tracer,并且继承其它进程传递过来的上下文信息。
// 从上下文中解析并创建一个新的 trace,获得传播的 上下文(SpanContext)
func CreateTracer(serviceName string, header http.Header) (opentracing.Tracer,opentracing.SpanContext, io.Closer, error) {
var cfg = jaegercfg.Configuration{
ServiceName: serviceName,
Sampler: &jaegercfg.SamplerConfig{
Type: jaeger.SamplerTypeConst,
Param: 1,
},
Reporter: &jaegercfg.ReporterConfig{
LogSpans: true,
// 按实际情况替换你的 ip
CollectorEndpoint: "http://127.0.0.1:14268/api/traces",
},
}
jLogger := jaegerlog.StdLogger
tracer, closer, err := cfg.NewTracer(
jaegercfg.Logger(jLogger),
)
// 继承别的进程传递过来的上下文
spanContext, _ := tracer.Extract(opentracing.HTTPHeaders,
opentracing.HTTPHeadersCarrier(header))
return tracer, spanContext, closer, err
}
为了解析 HTTP 传递而来的 span 上下文,我们需要通过中间件来解析了处理一些细节。
func UseOpenTracing() gin.HandlerFunc {
handler := func(c *gin.Context) {
// 使用 opentracing.GlobalTracer() 获取全局 Tracer
tracer,spanContext, closer, _ := CreateTracer("userInfoWebService", c.Request.Header)
defer closer.Close()
// 生成依赖关系,并新建一个 span、
// 这里很重要,因为生成了 References []SpanReference 依赖关系
startSpan:= tracer.StartSpan(c.Request.URL.Path,ext.RPCServerOption(spanContext))
defer startSpan.Finish()
// 记录 tag
// 记录请求 Url
ext.HTTPUrl.Set(startSpan, c.Request.URL.Path)
// Http Method
ext.HTTPMethod.Set(startSpan, c.Request.Method)
// 记录组件名称
ext.Component.Set(startSpan, "Gin-Http")
// 在 header 中加上当前进程的上下文信息
c.Request=c.Request.WithContext(opentracing.ContextWithSpan(c.Request.Context(),startSpan))
// 传递给下一个中间件
c.Next()
// 继续设置 tag
ext.HTTPStatusCode.Set(startSpan, uint16(c.Writer.Status()))
}
return handler
}
别忘记了 API 服务:
func GetUserInfo(ctx *gin.Context) {
userName := ctx.Param("username")
fmt.Println("收到请求,用户名称为:", userName)
ctx.String(http.StatusOK, "他的博客是 https://whuanle.cn")
}
然后是 main 方法:
func main() {
r := gin.Default()
// 插入中间件处理
r.Use(UseOpenTracing())
r.GET("/Get",GetUserInfo)
r.Run("0.0.0.0:8081") // listen and serve on 0.0.0.0:8080 (for windows "localhost:8080")
}
完整代码可参考:https://github.com/whuanle/DistributedTracingGo/issues/2
分别启动 webserver、client,会发现打印日志。并且打开 jaerger ui 界面,会出现相关的追踪信息。

Tag 、 Log 和 Ref
Jaeger 的链路追踪中,可以携带 Tag 和 Log,他们都是键值对的形式:
{
"key": "http.method",
"type": "string",
"value": "GET"
},
Tag 设置方法是 ext.xxxx,例如 :
ext.HTTPUrl.Set(startSpan, c.Request.URL.Path)
因为 opentracing 已经规定了所有的 Tag 类型,所以我们只需要调用 ext.xxx.Set() 设置即可。
前面写示例的时候忘记把日志也加一下了。。。日志其实很简单的,通过 span 对象调用函数即可设置。
示例(在中间件里面加一下):
startSpan.LogFields(
log.String("event", "soft error"),
log.String("type", "cache timeout"),
log.Int("waited.millis", 1500))

ref 就是多个 span 之间的关系。span 可以是跨进程的,也可以是一个进程内的不同函数中的。
其中 span 的依赖关系表示示例:
"references": [
{
"refType": "CHILD_OF",
"traceID": "33ba35e7cc40172c",
"spanID": "1c7826fa185d1107"
}]
spanID 为其依赖的父 span。
可以看下面这张图。
一个进程中的 tracer 可以包装一些代码和操作,为多个 span 生成一些信息,或创建父子关系。
而 远程请求中传递的是 SpanContext,传递后,远程服务也创建新的 tracer,然后从 SpanContext 生成 span 依赖关系。
子 span 中,其 reference 列表中,会带有 父 span 的 span id。

到此这篇关于Jaeger Client Go入门并实现链路追踪的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

golang生成vcf通讯录格式文件详情
目录 1.源码 2.源码解析 3.运行结果 前言: vcf文件:VCF是通讯录格式文件,一般需要用手机通讯录导入导出的文件格式都是vcf格式. 目的:如果你是卖房销售,或者你是做什么推销的,你可以生成同城的手机号,一个个打电话推销. 1.源码 package number /* @Time : 2021/12/22 17:44 @Author :dengfeng_hu @File : phone @Software: GoLand */ import ( "bufio" &
-
Golang库插件注册加载机制的问题
目录 注册 加载 总结 最近看到一个内部项目的插件加载机制,非常赞.当然这里说的插件并不是指的golang原生的可以在buildmode中加载指定so文件的那种加载机制.而是软件设计上的「插件」.如果你的软件是一个框架,或者一个平台性产品,想要提升扩展性,即可以让第三方进行第三方库开发,最终能像搭积木一样将这些库组装起来.那么就可能需要这种库加载机制. 我们的目标是什么?对第三方库进行某种库规范,只要按照这种库规范进行开发,这个库就可以被加载到框架中. 我们先定义一个插件的数据结构,这里肯定是需
-
关于Java应用日志与Jaeger的trace关联的问题
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS等: 本篇概览 经过[<Jaeger开发入门(java版)>]的实战,相信您已经能将自己的应用接入Jaeger,并用来跟踪定位问题了,本文将介绍Jaeger一个小巧而强大的辅助功能,用少量改动大幅度提升定位问题的便利性:将业务日志与Jaeger的trace关联 在正式开始前,咱们先来看一个具体的问
-
ASP.NET Core利用Jaeger实现分布式追踪详解
前言 最近我们公司的部分.NET Core的项目接入了Jaeger,也算是稍微完善了一下.NET团队的技术栈. 至于为什么选择Jaeger而不是Skywalking,这个问题我只能回答,大佬们说了算. 前段时间也在CSharpCorner写过一篇类似的介绍 Exploring Distributed Tracing Using ASP.NET Core And Jaeger. 下面回到正题,我们先看一下Jaeger的简介 Jaeger的简单介绍 Jaeger是Uber开源的一个分布式追踪的工具,
-
Go语言的变量定义详情
目录 一.变量 声明变量 二.短声明 指针 三.new函数 四.变量的生命期 五.变量的作用域 一.变量 声明变量 go定义变量的方式和c,c++,java语法不一样,如下: var 变量名 类型, 比如 : var a int var在前,变量名在中间,类型在后面 我们以代码举例,如下: var i int = 0 var i = 0 var i int 以上三个表达式均是合法的,第三个表达式会将i初始化为int类型的零值,0:如果i是bool类型,则为false:i是float64类型,则为
-
golang实现浏览器导出excel文件功能
目录 1.依赖包 2.示例 3.分析 3.1先根据需求查询需要的list对象 3.2新建文件,设置文件名,跟列名 3.3设置标题单元格 3.4设置内容单元格 3.5流媒体返回web 1.依赖包 import ( "github.com/tealeg/xlsx" ) 2.示例 func (o *orderController) Export(request *restful.Request, response *restful.Response) { username := reques
-
Go中的gRPC入门详解
Go GRPC 入门 1,安装包 grpc golang-grpc 包提供了 gRPC 相关的代码库,通过这个库我们可以创建 gRPC 服务或客户端,首先需要安装他. go get -u google.golang.org/grpc 协议插件 要玩 gRPC,自然离不开 proto 文件,需要安装两个包,用于支持 protobuf 文件的处理. go get -u github.com/golang/protobuf go get -u github.com/golang/protobuf/pr
-
Jaeger Client Go入门并实现链路追踪
目录 Jaeger 部署 Jaeger 从示例了解 Jaeger Client Go 了解 trace.span tracer 配置 Sampler 配置 Reporter 配置 分布式系统与span 怎么调.怎么传 HTTP,跨进程追踪 客户端 Web 服务端 Tag . Log 和 Ref Jaeger OpenTracing 是开放式分布式追踪规范,OpenTracing API 是一致,可表达,与供应商无关的API,用于分布式跟踪和上下文传播. OpenTracing 的客户端库以及规范
-
Jaeger Client Go入门并实现链路追踪
目录 Jaeger 部署 Jaeger 从示例了解 Jaeger Client Go 了解 trace.span tracer 配置 Sampler 配置 Reporter 配置 分布式系统与span 怎么调.怎么传 HTTP,跨进程追踪 客户端 Web 服务端 Tag . Log 和 Ref Jaeger OpenTracing 是开放式分布式追踪规范,OpenTracing API 是一致,可表达,与供应商无关的API,用于分布式跟踪和上下文传播. OpenTracing 的客户端库以及规范
-
ASP.Net Core中的日志与分布式链路追踪
目录 .NET Core 中的日志 控制台输出 非侵入式日志 Microsoft.Extensions.Logging ILoggerFactory ILoggerProvider ILogger Logging Providers 怎么使用 日志等级 Trace.Debug 链路跟踪 OpenTracing 上下文和跟踪功能 跟踪单个功能 将多个跨度合并到一条轨迹中 传播过程中的上下文 分布式链路跟踪 在不同进程中跟踪 在 ASP.NET Core 中跟踪 OpenTracing API 和
-
Go 分布式链路追踪实现原理解析
目录 为什么需要分布式链路追踪系统 微服务架构给运维.排障带来新挑战 分布式链路追踪系统如何帮助我们 分布式链路追踪系统架构概览 核心概念 一般架构 协议标准和开源实现 应用侧调用链跟踪实现方案概览 应用侧核心任务 基于 OTEL 库实现调用拦截 HttpServer Handler 生成 Span 过程 HttpClient 请求生成 Span 过程 基于 OTEL 库实现调用链跟踪总结 非侵入调用链跟踪实现思路 Go 非侵入链路追踪实现原理 在分布式.微服务架构下,应用一个请求往往贯穿多个分
-
.NET Core分布式链路追踪框架的基本实现原理
分布式追踪 什么是分布式追踪 分布式系统 当我们使用 Google 或者 百度搜索时,查询服务会将关键字分发到多台查询服务器,每台服务器在自己的索引范围内进行搜索,搜索引擎可以在短时间内获得大量准确的搜索结果:同时,根据关键字,广告子系统会推送合适的相关广告,还会从竞价排名子系统获得网站权重.通常一个搜索可能需要成千上万台服务器参与,需要经过许多不同的系统提供服务. 多台计算机通过网络组成了一个庞大的系统,这个系统即是分布式系统. 在微服务或者云原生开发中,一般认为分布式系统是通过各种中间件/服
-
.NET Core分布式链路追踪框架的基本实现原理
目录 分布式追踪 什么是分布式追踪 分布式系统 分布式追踪 分布式追踪有什么用呢 Dapper 分布式追踪系统的实现 跟踪树和 span Jaeger 和 OpenTracing OpenTracing Jaeger 结构 OpenTracing 数据模型 Span 格式 Trace Span OpenTracing API 分布式追踪 什么是分布式追踪 分布式系统 当我们使用 Google 或者 百度搜索时,查询服务会将关键字分发到多台查询服务器,每台服务器在自己的索引范围内进行搜索,搜索引擎
-
spring cloud 分布式链路追踪的方法
一篇讲了微服务之间的调用spring cloud eureka 微服务之间的调用 微服务之间进行调用 那么如果我负责一个模块 别人负责另一个模块 我调用了他的方法 测试那边却报了错 那是我的问题还是他的问题 这个时候大家应该就能想到日志可以解决这个问题 如何使用日志呢 先在配置文件中加 logging: path: D:\logs\poppy-mall #日志的存放地址 最好再加个项目名的文件夹 可以更容易的区分 level: org.poppy.mall: info #日志的级别 org.po
-
SpringBoot+Logback实现一个简单的链路追踪功能
最近线上排查问题时候,发现请求太多导致日志错综复杂,没办法把用户在一次或多次请求的日志关联在一起,所以就利用SpringBoot+Logback手写了一个简单的链路追踪,下面详细介绍下. 一.实现原理 Spring Boot默认使用LogBack日志系统,并且已经引入了相关的jar包,所以我们无需任何配置便可以使用LogBack打印日志. MDC(Mapped Diagnostic Context,映射调试上下文)是log4j和logback提供的一种方便在多线程条件下记录日志的功能. 实现思路
-
SpringBoot 项目添加 MDC 日志链路追踪的执行流程
目录 1. 线程池配置 2. 拦截器配置 3. 日志文件配置 4. 使用方法示例 4.1. 异步使用 4.2. 定时任务 日志链路追踪的意思就是将一个标志跨线程进行传递,在一般的小项目中也就是在你新起一个线程的时候,或者使用线程池执行任务的时候会用到,比如追踪一个用户请求的完整执行流程. 这里用到MDC和ThreadLocal,分别由下面的包提供: java.lang.ThreadLocal org.slf4j.MDC 直接上代码: 1. 线程池配置 如果你直接通过手动新建线程来执行异步任务,想
-
详解如何在Go服务中做链路追踪
目录 1. 使用全局 map 来实现 2. 使用 Context 来实现 3. 小结 使用 Go 语言开发微服务的时候,需要追踪每一个请求的访问链路,这块在 Go 中目前没有很好的解决方案. 在 Java 中解决这个问题比较简单,可以使用 MDC,在一个进程内共享一个请求的 RequestId. 在 Go 中实现链路追踪有两种思路:一种是在项目中使用一个全局的 map, key 是 goroutine 的唯一 Id,value 是 RequestId,另一种思路可以使用 context.Cont