python实现selenium网络爬虫的方法小结
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题,selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器,这里只用到谷歌浏览器。
1.selenium初始化
方法一:会打开网页
# 该方法会打开goole网页 from selenium import webdriver url = '网址' driver = webdriver.Chrome() driver.get(url) driver.maximize_window() # 实现窗口最大化
方法二:不会打开网页
# 该方法会隐式打开goole网页
from selenium import webdriver
url = '网址'
driver = webdriver.ChromeOptions()
driver.add_argument("headless")
driver = webdriver.Chrome(options=driver)
driver.get(url)
driver = webdriver.Chrome()出错是因为没有chromedriver.exe这个文件
2.元素定位
在selenium中,可以有多种方法对元素进行定位,个人通常喜欢用Xpath和selector来定位元素,这样就不用一个一个的去找节点,直接在网页上定位到元素复制就行。
driver.find_element_by_id() # 通过元素ID定位 driver.find_element_by_name() # 通过元素Name定位 driver.find_element_by_class_name() # 通过类名定位 driver.find_element_by_tag_name() # 通过元素TagName定位 driver.find_element_by_link_text() # 通过文本内容定位 driver.find_element_by_partial_link_text() driver.find_element_by_xpath() # 通过Xpath语法定位 driver.find_element_by_css_selector() # 通过选择器定位
注:若寻找多个元素,要记得用复数来选择(element改为elements)
# 例如 [i.text for i in driver.find_elements_by_xpath()]
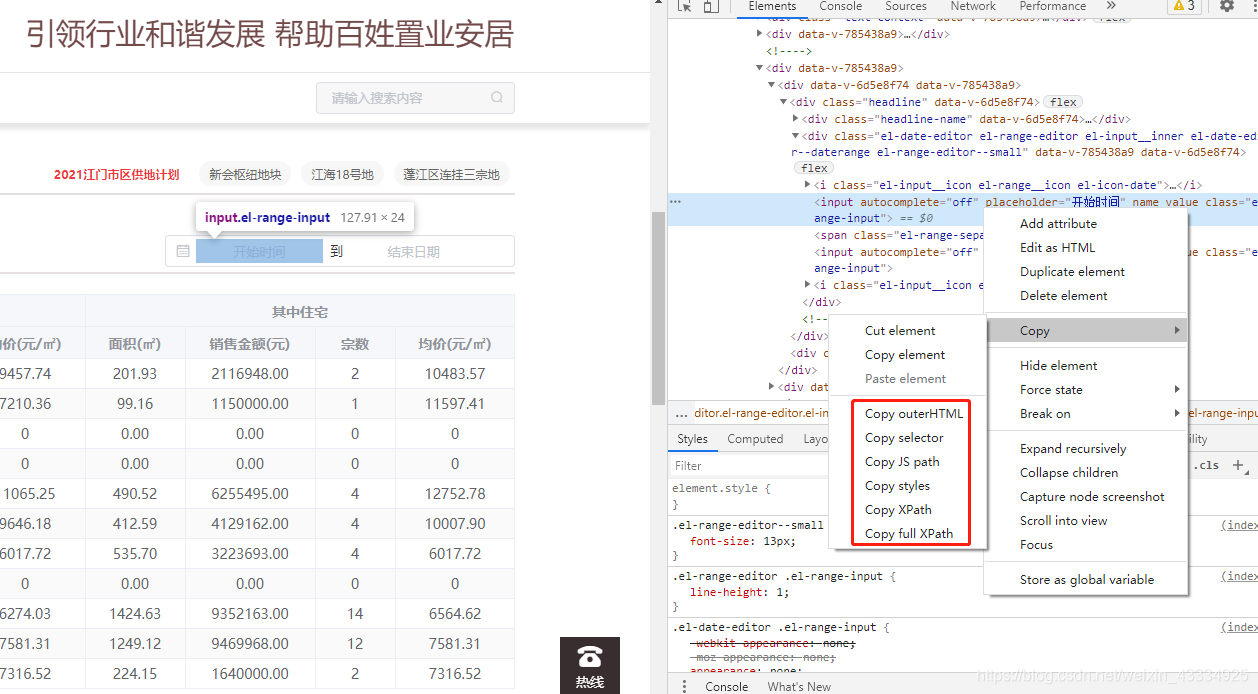
3.建立点击事件
因为有些网站的需求,需建立点击事件,
如下图的这种时间选择,需要设置点击和输入内容,设置的方法也很简单。

driver.find_element_by_css_selector('').click() # 点击
driver.find_element_by_css_selector('').send_keys('2021-3-9') # 输入内容
4.切换窗口
有些网站点击之后会产生新窗口,这时就需要进行窗口的切换才能进行元素定位
win = driver.window_handles # 获取当前浏览器的所有窗口 driver.switch_to.window(win[-1]) # 切换到最后打开的窗口 driver.close() # 关闭当前窗口 driver.switch_to.window(win[0]) # 切换到最初的窗口
5.iframe问题
有些网站会采用iframe来编写页面,这时就需要进入到iframe才可以获取元素,一般有多少个iframe就需要进入多少个iframe。
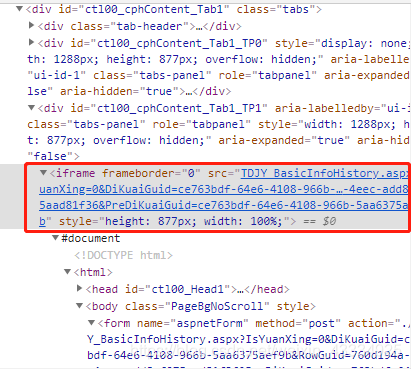
# 有两个iframe,需逐步进入
iframe1 = driver.find_element_by_xpath('')
driver.switch_to.frame(iframe1)
iframe2 = driver.find_element_by_xpath('')
driver.switch_to.frame(iframe2)
到此这篇关于python实现selenium网络爬虫的文章就介绍到这了,更多相关python selenium网络爬虫内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫使用Selenium+PhantomJS抓取Ajax和动态HTML内容
1.引言 在Python网络爬虫内容提取器一文我们详细讲解了核心部件:可插拔的内容提取器类gsExtractor.本文记录了确定gsExtractor的技术路线过程中所做的编程实验.这是第二部分,第一部分实验了用xslt方式一次性提取静态网页内容并转换成xml格式.留下了一个问题:javascript管理的动态内容怎样提取?那么本文就回答这个问题. 2.提取动态内容的技术部件 在上一篇python使用xslt提取网页数据中,要提取的内容是直接从网页的source code里拿到的.但是一些Aja
-
selenium+python设置爬虫代理IP的方法
1. 背景 在使用selenium浏览器渲染技术,爬取网站信息时,一般来说,速度是很慢的.而且一般需要用到这种技术爬取的网站,反爬技术都比较厉害,对IP的访问频率应该有相当的限制.所以,如果想提升selenium抓取数据的速度,可以从两个方面出发: 第一,提高抓取频率,出现验证信息时进行破解,一般是验证码或者用户登录. 第二,使用多线程 + 代理IP, 这种方式,需要电脑有足够的内存和充足稳定的代理IP . 2. 为chrome设置代理IP from selenium import webdri
-
详解Selenium+PhantomJS+python简单实现爬虫的功能
Selenium 一.简介 selenium是一个用于Web应用自动化程序测试的工具,测试直接运行在浏览器中,就像真正的用户在操作一样 selenium2支持通过驱动真实浏览器(FirfoxDriver,IternetExplorerDriver,OperaDriver,ChromeDriver) selenium2支持通过驱动无界面浏览器(HtmlUnit,PhantomJs) 二.安装 Windows 第一种方法是:下载源码安装,下载地址(https://pypi.python.org/py
-
python网络爬虫 Scrapy中selenium用法详解
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现,通过浏览器进行url请求发送则会加载出对应的动态加载出的数据.那么如果我们想要在scrapy也获取动态加载出的数据,则必须使用selenium创建浏览器对象,然后通过该浏览器对象进行请求发送,获取动态加载的数据值. 1.案例分析: - 需求:爬取网易新闻的国内.国际.军事.无人机板块下的新闻数据
-
浅谈python爬虫使用Selenium模拟浏览器行为
前几天有位微信读者问我一个爬虫的问题,就是在爬去百度贴吧首页的热门动态下面的图片的时候,爬取的图片总是爬取不完整,比首页看到的少.原因他也大概分析了下,就是后面的图片是动态加载的.他的问题就是这部分动态加载的图片该怎么爬取到. 分析 他的代码比较简单,主要有以下的步骤:使用BeautifulSoup库,打开百度贴吧的首页地址,再解析得到id为new_list标签底下的img标签,最后将img标签的图片保存下来. headers = { 'User-Agent':'Mozilla/5.0 (Win
-
python实现selenium网络爬虫的方法小结
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题,selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转.输入.点击.下拉等,来拿到网页渲染之后的结果,可支持多种浏览器,这里只用到谷歌浏览器. 1.selenium初始化 方法一:会打开网页 # 该方法会打开goole网页 from selenium import webdriver url = '网址' driver = webdriver.Chrom
-
Python之读取TXT文件的方法小结
方法一: <span style="font-size:14px;">#read txt method one f = open("./image/abc.txt") line = f.readline() while line: print line line = f.readline() f.close() </span> 方法二: #read txt method two f = open("./image/abc.txt&q
-
Python发展史及网络爬虫
Python 简介 Python 是一个高层次的结合了解释性.编译性.互动性和面向对象的脚本语言. Python 的设计具有很强的可读性,相比其他语言经常使用英文关键字,其他语言的一些标点符号,它具有比其他语言更有特色语法结构. Python 是一种解释型语言: 这意味着开发过程中没有了编译这个环节.类似于PHP和Perl语言. Python 是交互式语言: 这意味着,您可以在一个Python提示符,直接互动执行写你的程序. Python 是面向对象语言: 这意味着Python支持面向对象的风格
-
python 修改本地网络配置的方法
本文主要说一下怎么使用Python来修改本地的ip和dns等,因为有本地的ip和dns都是随机获取的,有些时候不是很方便,需要修改,我就稍微的封装了一下,但是随机ip和网关.子网掩码等我都没有设置为参数,因为经常用也懒得改了,可以自己去修改一下. 测试的时候,在win8.1上面需要用管理员身份才能执行,win7似乎是不需要管理员身份的. 使用的Python库是WMI,这个是默认安装了的.如果没有去网上下载即可. 该说的都在注释里,就直接上代码了. # -*- coding: utf-8 -*-
-
Python 矩阵转置的几种方法小结
我就废话不多说了,直接上代码吧! #Python的matrix转置 matrix = [[1,2,3,4],[5,6,7,8],[9,10,11,12]] def printmatrix(m): for ele in m: for i in ele: print("%2d" %i,end = " ") print() #1.利用元祖的特性进行转置 def transformMatrix(m): #此处巧妙的先按照传递的元祖m的列数,生成了r的行数 r = [[] f
-
python求绝对值的三种方法小结
如下所示: 1.条件判断 2.内置函数abs() 3.内置模块 math.fabs abs() 与fabs()的区别 abs()是一个内置函数,而fabs()在math模块中定义的. fabs()函数只适用于float和integer类型,而abs()也适用于复数. abs()返回是float和int类型,math.fabs()返回是float类型 以上这篇python求绝对值的三种方法小结就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
python 字典访问的三种方法小结
定义字典 dic = {'a':"hello",'b':"how",'c':"you"} 方法一: for key in dic: print key,dic[key] print key + str(dic[key]) 结果: a hello ahello c you cyou b how bhow 细节: print key,dic[key],后面有个逗号,自动生成一个空格 print key + str(dic[key]),连接两个字符串,
-
python 解决selenium 中的 .clear()方法失效问题
最近在使用selenium做一个数字货币的自动化脚本时,遇到一个问题就是okex网站的input使用clear()方法居然无法清空,但是后来试了好多次发现方法是可以使用的,而且这个网站修改input的value也没用,必须在文本框里修改才行,本次的目的就是要清除输入框的默认值,然而clear()没有反应,最后还是用了别的方法解决了问题,那就是使用鼠标双击事件,全选后输入内容. from selenium.webdriver.common.action_chains import ActionCh
-
python中绕过反爬虫的方法总结
我们在登山的途中,有不同的路线可以到达终点.因为选择的路线不同,上山的难度也有区别.就像最近几天教大家获取数据的时候,断断续续的讲过header.地址ip等一些的方法.具体的爬取方法相信大家已经掌握住,本篇小编主要是给大家进行应对反爬虫方法的一个梳理,在进行方法回顾的同时查漏补缺,建立系统的爬虫知识框架. 首先分析要爬的网站,本质是一个信息查询系统,提供了搜索页面.例如我想获取某个case,需要利用这个case的id或者name字段,才能搜索到这个case的页面. 出于对安全的考虑,有些网站会做
-
python中判断集合范围的方法小结
我们在比较数值大小的时候,会使用一些比较符号来进行判断.在python集合中也有这样的比较,但有一点要注意的是,我们比较的是集合之间的包容性,而不是简单数值之间的大小比较,这点在文章的开头就进行明确,也是对于我们python初学者的提醒. 集合可以使用大于(>).小于(<).大于等于(>=).小于等于(<=).等于(==).不等于(!=)来判断某个集合是否完全包含于另一个集合,也可以使用子父集判断函数. 定义三个集合s1,s2,s3: >>> s1=set([1,