如何利用python实现kmeans聚类
目录
- 一、先上手撸代码!
- 二、接下来是调库代码!(sklearn)
- 附:对k-means算法的认识
- 总结
一、先上手撸代码!
1、首先是导入所需要的库和数据
import pandas as pd
import numpy as np
import random
import math
import matplotlib.pyplot as plt
# 这两行代码解决 plt 中文显示的问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
df = pd.read_excel('13信科学生成绩.xlsx')
data = np.array(df)
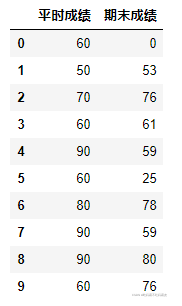
df.head(10)
先给大伙们看看数据集长啥样:
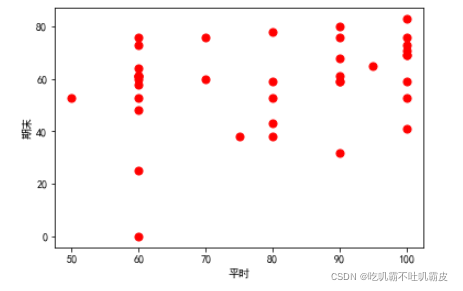
用matplotlib简单的可视化一下初始数据:
# 输入数据
x = data.T[0]
y = data.T[1]
plt.scatter(x, y, s=50, c='r') # 画散点图
plt.xlabel('平时') # 横坐标轴标题
plt.ylabel('期末') # 纵坐标轴标题
plt.show()
2、接下来就是kmeans的核心算法了
k=3
i = 1
min1 = data.min(axis = 0)
max1 = data.max(axis = 0)
#在数据最大最小值中随机生成k个初始聚类中心,保存为t
centre = np.empty((k,2))
for i in range(k):
centre[i][0] = random.randint(min1[0],max1[0])#平时成绩
centre[i][1] = random.randint(min1[1],max1[1])#期末成绩
while i<500:
#计算欧氏距离
def euclidean_distance(List,t):
return math.sqrt(((List[0] - t[0])**2 + (List[1] - t[1])**2))
#每个点到每个中心点的距离矩阵
dis = np.empty((len(data),k))
for i in range(len(data)):
for j in range(k):
dis[i][j] = euclidean_distance(data[i],centre[j])
#初始化分类矩阵
classify = []
for i in range(k):
classify.append([])
#比较距离并分类
for i in range(len(data)):
List = dis[i].tolist()
index = List.index(dis[i].min())
classify[index].append(i)
#构造新的中心点
new_centre = np.empty((k,2))
for i in range(len(classify)):
new_centre[i][0] = np.sum(data[classify[i]][0])/len(classify[i])
new_centre[i][1] = np.sum(data[classify[i]][1])/len(classify[i])
#比较新的中心点和旧的中心点是否一样
if (new_centre == centre).all():
break
else:
centre = new_centre
i = i + 1
# print('迭代次数为:',i)
print('聚类中心为:',new_centre)
print('分类情况为:',classify)
注意!!!这里的k是指分成k类,读者可以自行选取不同的k值做实验

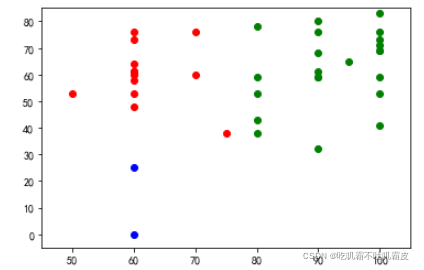
3、可视化部分(将不用类用不同颜色区分开来~~)
mark = ['or', 'ob', 'og', 'ok','sb', 'db', '<b', 'pb'] #红、蓝、绿、黑四种颜色的圆点
#mark=['sb', 'db', '<b', 'pb']
plt.figure(3)#创建图表1
for i in range(0,k):
x=[]
y=[]
for j in range(len(classify[i])):
x.append(data[classify[i][j]][0])
y.append(data[classify[i][j]][1])
plt.xlim(xmax=105,xmin=45)
plt.ylim(ymax=85,ymin=-5)
plt.plot(x,y,mark[i])
#plt.show()
一起来康康可视化结果8!!
二、接下来是调库代码!(sklearn)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn import metrics
df = pd.read_excel('13信科学生成绩.xlsx')
data = np.array(df)
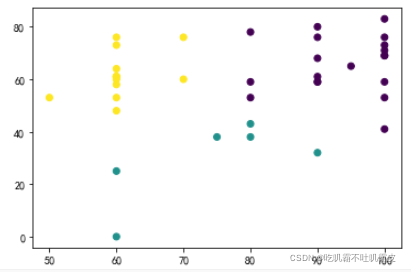
y_pred=KMeans(n_clusters=3,random_state=9).fit_predict(data)
plt.scatter(data[:,0],data[:,1],c=y_pred)
plt.show()
print(metrics.calinski_harabasz_score(data,y_pred))
可视化结果和手撸的结果略有差别,有可能是数据集的问题,也有可能是k值选取的问题,各位亲们不需要担心!!!
附:对k-means算法的认识
1.优点
(1)算法快速、简单。
(2)对大数据集有较高的效率并且是可伸缩性的。
(3)时间复杂度近于线性,而且适合挖掘大规模数据集。K-Means聚类算法的时间复杂度是O(nkt) ,其中n代表数据集中对象的数量,t代表着算法迭代的次数,k代表着簇的数目。
2.缺点
(1)聚类是一种无监督的学习方法,在 K-means 算法中 K 是事先给定的,K均值算法需要用户指定创建的簇数k,但这个 K 值的选定是非常难以估计的。
(2)在 K-means 算法中,首先需要根据初始聚类中心来确定一个初始划分,然后对初始划分进行优化。这个初始聚类中心的选择对聚类结果有较大的影响,一旦初始值选择的不好,可能无法得到有效的聚类结果,这也成为 K-means算法的一个主要问题。
(3)从 K-means 算法框架可以看出,该算法需要不断地进行样本分类调整,不断地计算调整后的新的聚类中心,因此当数据量非常大时,算法的时间开销是非常大的。所以需要对算法的时间复杂度进行分析、改进,提高算法应用范围,而这导致K均值算法在大数据集上收敛较慢。
总结
到此这篇关于如何利用python实现kmeans聚类的文章就介绍到这了,更多相关python实现kmeans聚类内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python实现的KMeans聚类算法实例分析
本文实例讲述了Python实现的KMeans聚类算法.分享给大家供大家参考,具体如下: 菜鸟一枚,编程初学者,最近想使用Python3实现几个简单的机器学习分析方法,记录一下自己的学习过程. 关于KMeans算法本身就不做介绍了,下面记录一下自己遇到的问题. 一 .关于初始聚类中心的选取 初始聚类中心的选择一般有: (1)随机选取 (2)随机选取样本中一个点作为中心点,在通过这个点选取距离其较大的点作为第二个中心点,以此类推. (3)使用层次聚类等算法更新出初始聚类中心 我一开始是使用numpy
-
Kmeans均值聚类算法原理以及Python如何实现
第一步.随机生成质心 由于这是一个无监督学习的算法,因此我们首先在一个二维的坐标轴下随机给定一堆点,并随即给定两个质心,我们这个算法的目的就是将这一堆点根据它们自身的坐标特征分为两类,因此选取了两个质心,什么时候这一堆点能够根据这两个质心分为两堆就对了.如下图所示: 第二步.根据距离进行分类 红色和蓝色的点代表了我们随机选取的质心.既然我们要让这一堆点的分为两堆,且让分好的每一堆点离其质心最近的话,我们首先先求出每一个点离质心的距离.假如说有一个点离红色的质心比例蓝色的质心更近,那么我们则将这个
-
python中kmeans聚类实现代码
k-means算法思想较简单,说的通俗易懂点就是物以类聚,花了一点时间在python中实现k-means算法,k-means算法有本身的缺点,比如说k初始位置的选择,针对这个有不少人提出k-means++算法进行改进:另外一种是要对k大小的选择也没有很完善的理论,针对这个比较经典的理论是轮廓系数,二分聚类的算法确定k的大小,在最后还写了二分聚类算法的实现,代码主要参考机器学习实战那本书: #encoding:utf-8 ''''' Created on 2015年9月21日 @author: Z
-
Python实现Kmeans聚类算法
本节内容:本节内容是根据上学期所上的模式识别课程的作业整理而来,第一道题目是Kmeans聚类算法,数据集是Iris(鸢尾花的数据集),分类数k是3,数据维数是4. 关于聚类 聚类算法是这样的一种算法:给定样本数据Sample,要求将样本Sample中相似的数据聚到一类.有了这个认识之后,就应该了解了聚类算法要干什么了吧.说白了,就是归类. 首先,我们需要考虑的是,如何衡量数据之间的相似程度?比如说,有一群说不同语言的人,我们一般是根据他们的方言来聚类的(当然,你也可以指定以身高来聚类).
-
python kmeans聚类简单介绍和实现代码
一.k均值聚类的简单介绍 假设样本分为c类,每个类均存在一个中心点,通过随机生成c个中心点进行迭代,计算每个样本点到类中心的距离(可以自定义.常用的是欧式距离) 将该样本点归入到最短距离所在的类,重新计算聚类中心,进行下次的重新划分样本,最终类中心不改变时,聚类完成 二.伪代码 三.python代码实现 #!/usr/bin/env python # coding=utf-8 import numpy as np import random import matplotlib.pyplo
-
Python KMeans聚类问题分析
今天用python实现了一下简单的聚类分析,顺便熟悉了numpy数组操作和绘图的一些技巧,在这里做个记录. from pylab import * from sklearn.cluster import KMeans ## 利用numpy.append()函数实现matlab多维数组合并的效果,axis 参数值为 0 时是 y 轴方向合并,参数值为 1 时是 x 轴方向合并,分别对应matlab [A ; B] 和 [A , B]的效果 #创建5个随机的数据集 x1=append(randn(5
-
利用Python实现K-Means聚类的方法实例(案例:用户分类)
目录 K-Means聚类算法介绍 K-Means聚类算法基础原理 K-Means聚类算法实现流程 开始做一个简单的聚类 数据导入 数据探索 开始聚类 查看输出结果 聚类质心 K-Means聚类算法的评估指标 真实标签已知 真实标签未知 实用案例:基于轮廓系数来选择最佳的n_clusters 结果对比 优化方案选择 K-Means聚类算法介绍 K-Means又称为K均值聚类算法,属于聚类算法中的一种,而聚类算法在机器学习算法中属于无监督学习,在业务中常常会结合实际需求与业务逻辑理解来完成建模: 无
-
如何利用python实现kmeans聚类
目录 一.先上手撸代码! 二.接下来是调库代码!(sklearn) 附:对k-means算法的认识 总结 一.先上手撸代码! 1.首先是导入所需要的库和数据 import pandas as pd import numpy as np import random import math import matplotlib.pyplot as plt # 这两行代码解决 plt 中文显示的问题 plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcP
-
python实现k-means聚类算法
k-means聚类算法 k-means是发现给定数据集的k个簇的算法,也就是将数据集聚合为k类的算法. 算法过程如下: 1)从N个文档随机选取K个文档作为质心 2)对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类,我们一般取欧几里得距离 3)重新计算已经得到的各个类的质心 4)迭代步骤(2).(3)直至新的质心与原质心相等或迭代次数大于指定阈值,算法结束 算法实现 随机初始化k个质心,用dict保存质心的值以及被聚类到该簇中的所有data. def initCent(dataSe
-
Python用K-means聚类算法进行客户分群的实现
一.背景 1.项目描述 你拥有一个超市(Supermarket Mall).通过会员卡,你用有一些关于你的客户的基本数据,如客户ID,年龄,性别,年收入和消费分数. 消费分数是根据客户行为和购买数据等定义的参数分配给客户的. 问题陈述:你拥有这个商场.想要了解怎么样的顾客可以很容易地聚集在一起(目标顾客),以便可以给营销团队以灵感并相应地计划策略. 2.数据描述 字段名 描述 CustomerID 客户编号 Gender 性别 Age 年龄 Annual Income (k$) 年收入,单位为千
-
Python实现K-means聚类算法并可视化生成动图步骤详解
K-means算法介绍 简单来说,K-means算法是一种无监督算法,不需要事先对数据集打上标签,即ground-truth,也可以对数据集进行分类,并且可以指定类别数目 牧师-村民模型 K-means 有一个著名的解释:牧师-村民模型: 有四个牧师去郊区布道,一开始牧师们随意选了几个布道点,并且把这几个布道点的情况公告给了郊区所有的村民,于是每个村民到离自己家最近的布道点去听课. 听课之后,大家觉得距离太远了,于是每个牧师统计了一下自己的课上所有的村民的地址,搬到了所有地址的中心地带,并且在海
-
python基于K-means聚类算法的图像分割
1 K-means算法 实际上,无论是从算法思想,还是具体实现上,K-means算法是一种很简单的算法.它属于无监督分类,通过按照一定的方式度量样本之间的相似度,通过迭代更新聚类中心,当聚类中心不再移动或移动差值小于阈值时,则就样本分为不同的类别. 1.1 算法思路 随机选取聚类中心 根据当前聚类中心,利用选定的度量方式,分类所有样本点 计算当前每一类的样本点的均值,作为下一次迭代的聚类中心 计算下一次迭代的聚类中心与当前聚类中心的差距 如4中的差距小于给定迭代阈值时,迭代结束.反之,至2继续下
-
利用Python如何实现K-means聚类算法
目录 前言 算法原理 目标函数 算法流程 Python实现 总结 前言 K-Means 是一种非常简单的聚类算法(聚类算法都属于无监督学习).给定固定数量的聚类和输入数据集,该算法试图将数据划分为聚类,使得聚类内部具有较高的相似性,聚类与聚类之间具有较低的相似性. 算法原理 1. 初始化聚类中心,或者在输入数据范围内随机选择,或者使用一些现有的训练样本(推荐) 2. 直到收敛 将每个数据点分配到最近的聚类.点与聚类中心之间的距离是通过欧几里德距离测量得到的. 通过将聚类中心的当前估计值设置为属于
-
Python机器学习之K-Means聚类实现详解
本文为大家分享了Python机器学习之K-Means聚类的实现代码,供大家参考,具体内容如下 1.K-Means聚类原理 K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.其基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类.通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果.各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开. 算法大致流程为:(1)随机选取k个点作为种子点(这k个点不一定属于数据集)