SpringBoot详解如何实现读写分离
目录
- 前言
- 1.项目引入依赖
- 2.yml配置
- 3.启动
- 4.测试
- 5.中间所遇到的问题
前言
根据公司业务需求,项目需要读写分离,所以记录下读写分离的过程。
分为两个部分:
1.项目的读写分离。
2.mysql数据库的主从复制。
本篇使用的依赖包为sharding-jdbc-spring-boot-starter,也有考虑直接用dynamic-datasource-spring-boot-starter,但是需要在程序中显式的声明所指定的数据源,并且在从库>=2 的时候需要自己写算法进行读库的选择。而sharding-jdbc支持读库的负载均衡策略,sharding会根据语句的关键字来決定是读操作还是写操作
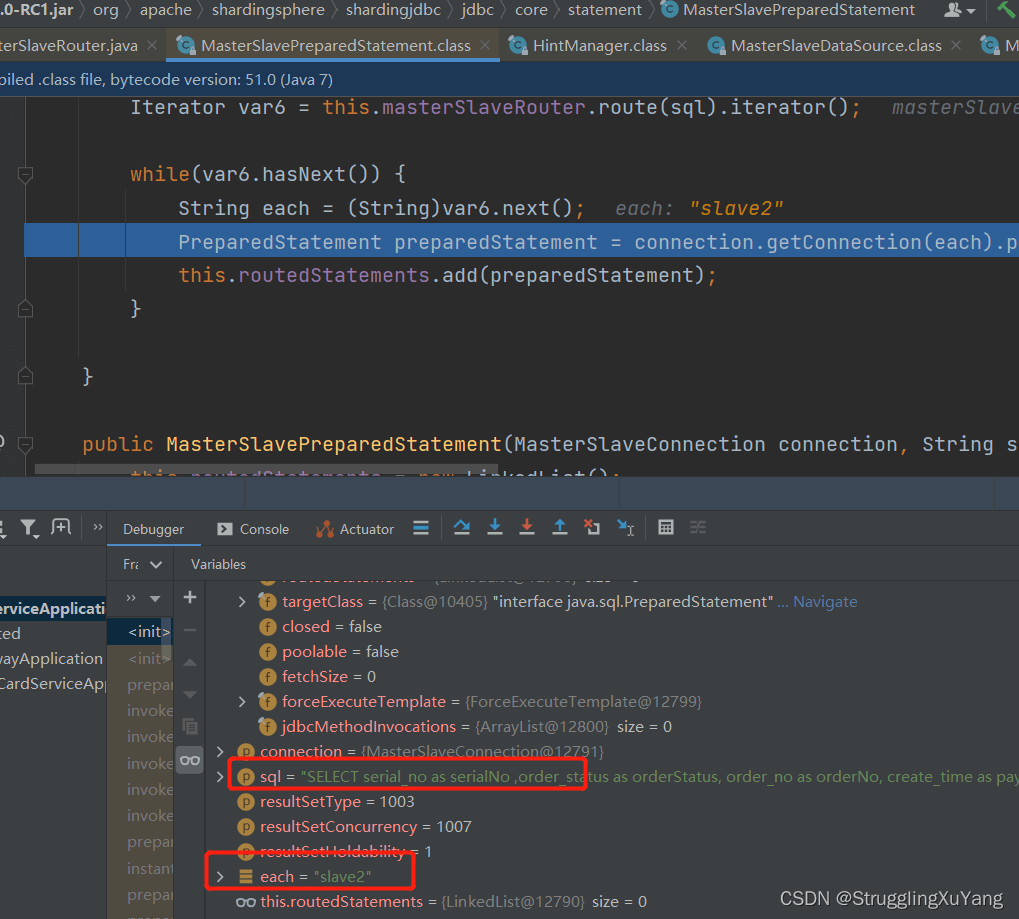
Insert选择主库
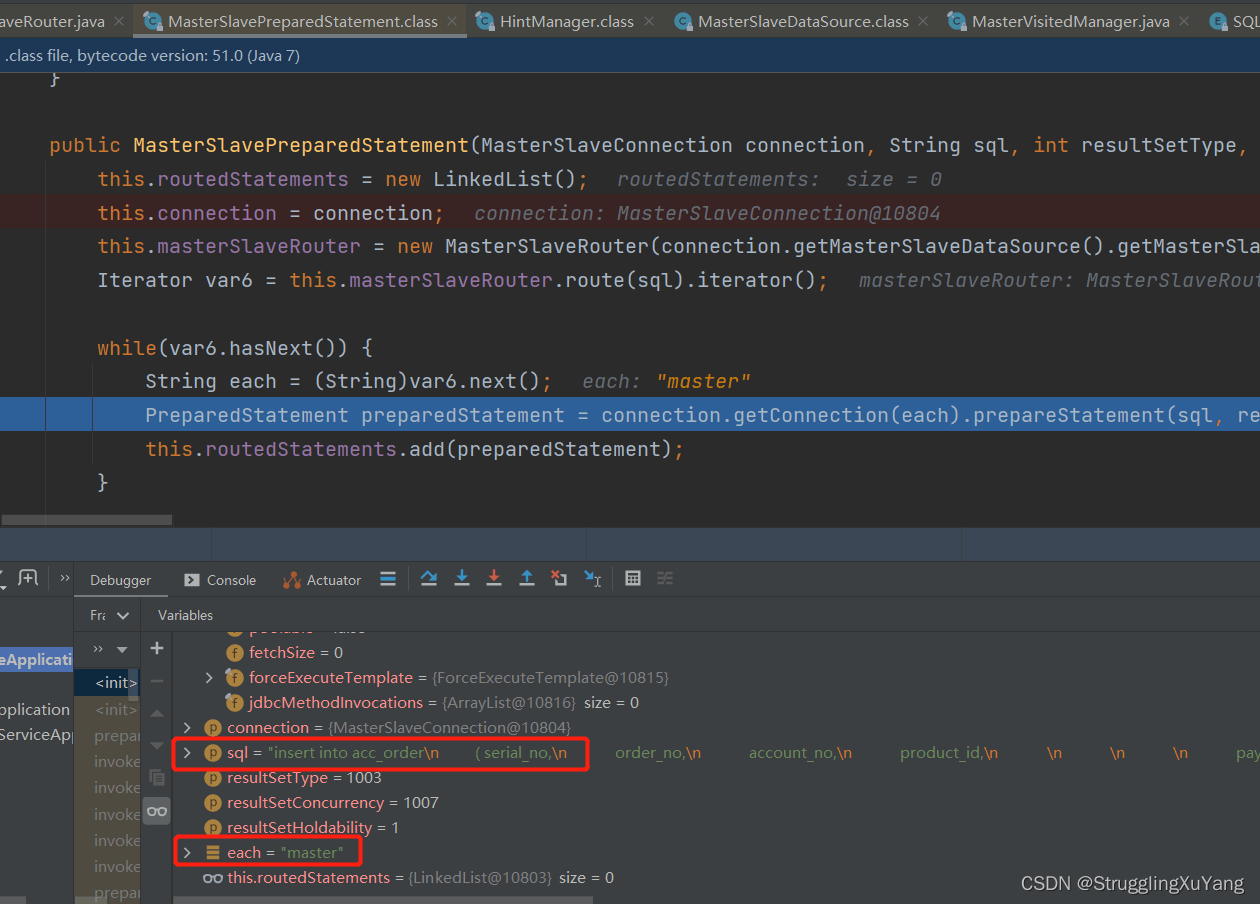
Select选择从库2(由于设置的了轮询,所以下一次就是从库1)
1.项目引入依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
2.yml配置
共有三台机器,
主库一台(127.0.0.1)
从库两台(192.168.1.5 192.168.1.6)
spring:
shardingsphere:
props:
sql:
show: false
sharding:
default-data-source-name: master
masterslave:
name: ms
master-data-source-name: master
slave-data-source-names: slave1,slave2
#配置slave节点的负载均衡均衡策略,采用轮询机制
load-balance-algorithm-type: round_robin
datasource:
names: master,slave1,slave2
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/life_account_db?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: root
maxPoolSize: 100
minPoolSize: 5
slave1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.1.5:3306/life_account_db?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
username: test
password: Houxuyang123!@#
maxPoolSize: 100
minPoolSize: 5
slave2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.1.6:3306/life_account_db?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
username: test
password: Houxuyang123!@#
maxPoolSize: 100
minPoolSize: 5
3.启动

4.测试
第一次读数据(从库1)



第二次读数据(从库2)



主库写

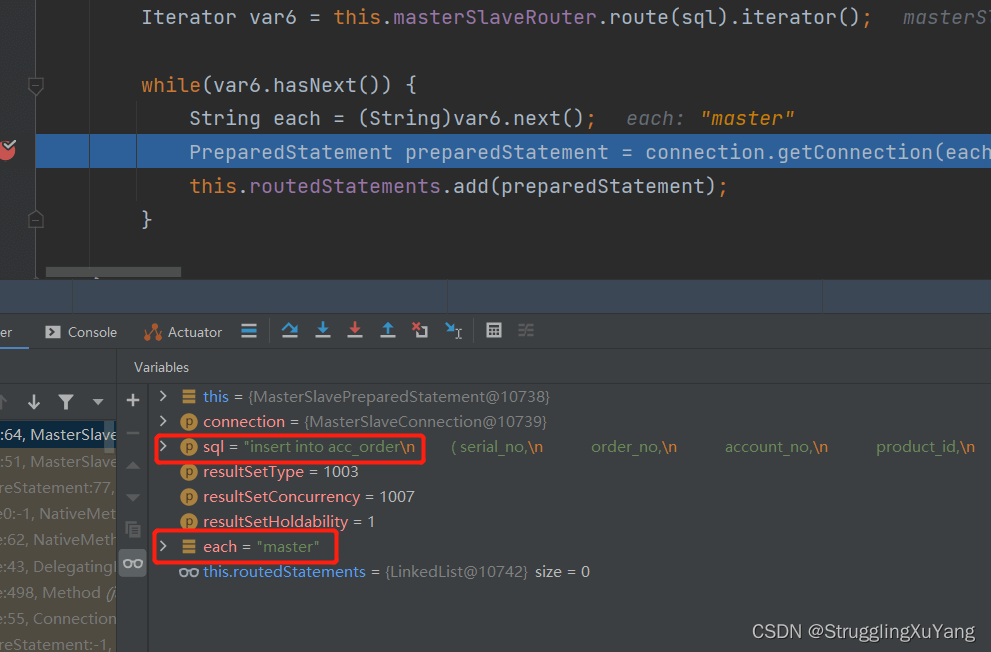

项目读写分离基本实现。
5.中间所遇到的问题
mysql查询问题
Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'life_account_db.acc_order.serial_no' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
原因:
没有遵循原则的sql会被认为是不合法的sql
1.order by后面的列必须是在select后面存在的
2.select、having或order by后面存在的非聚合列必须全部在group by中存在
解决方法:
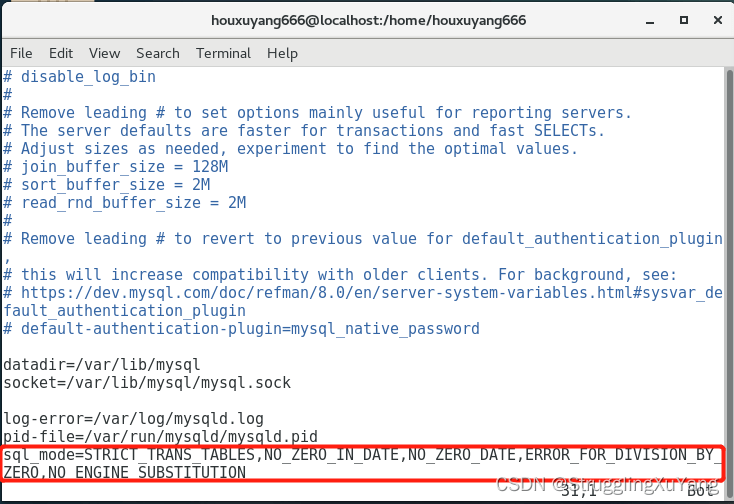
修改配置文件:vim /etc/my.cnf
添加:sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION
重启mysql:systemctl restart mysqld
:wq
到此这篇关于SpringBoot详解如何实现读写分离的文章就介绍到这了,更多相关SpringBoot读写分离内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

SpringBoot+MyBatis+AOP实现读写分离的示例代码
目录 一. MySQL 读写分离 1.1.如何实现 MySQL 的读写分离? 1.2.MySQL 主从复制原理? 1.3.MySQL 主从同步延时问题(精华) 二.SpringBoot+AOP+MyBatis实现MySQL读写分离 2.1.AbstractRoutingDataSource 2.2.如何切换数据源 2.3.如何选择数据源 三 .代码实现 3.0.工程目录结构 3.1.引入Maven依赖 3.2.编写配置文件,配置主从数据源 3.3.Enum类,定义主库从库 3.4.ThreadL
-
SpringBoot整合sharding-jdbc实现分库分表与读写分离的示例
目录 一.前言 二.数据库表准备 三.整合 四.docker-compose部署mysql主从 五.本文案例demo源码 一.前言 本文将基于以下环境整合sharding-jdbc实现分库分表与读写分离 springboot2.4.0 mybatis-plus3.4.3.1 mysql5.7主从 https://github.com/apache/shardingsphere 二.数据库表准备 温馨小提示:此sql执行时,如果之前有存在相应库和表会进行自动删除后再创建! DROP DATABAS
-
SpringBoot整合Sharding-JDBC实现MySQL8读写分离
目录 一.前言 二.项目目录结构 三.pom文件 四.配置文件(基于YAML)及SQL建表语句 五.Mapper.xml文件及Mapper接口 六 .Controller及Mocel文件 七.结果 八.Sharding-JDBC不同版本上的配置 一.前言 这是一个基于SpringBoot整合Sharding-JDBC实现读写分离的极简教程,笔者使用到的技术及版本如下: SpringBoot 2.5.2 MyBatis-Plus 3.4.3 Sharding-JDBC 4.1.1 MySQL8集群
-
SpringBoot+Mybatis-Plus实现mysql读写分离方案的示例代码
1. 引入mybatis-plus相关包,pom.xml文件 2. 配置文件application.property增加多库配置 mysql 数据源配置 spring.datasource.primary.jdbc-url=jdbc:mysql://xx.xx.xx.xx:3306/portal?useUnicode=true&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=
-
基于 SpringBoot 实现 MySQL 读写分离的问题
- 前言 - 首先思考一个问题: 在高并发的场景中,关于数据库都有哪些优化的手段? 常用的实现方法有以下几种:读写分离.加缓存.主从架构集群.分库分表等,在互联网应用中,大部分都是读多写少的场景,设置两个库,主库和读库. 主库的职能是负责写,从库主要是负责读 , 可以建立读库集群 , 通过读写职能在数据源上的隔离达到减少读写冲突. 释压数据库负载.保护数据库的目的.在实际的使用中,凡是涉及到写的部分直接切换到主库,读的部分直接切换到读库,这就是典型的读写分离技术.本文将聚焦读写分
-
springboot结合mysql主从来实现读写分离的方法示例
1.实现的功能 基于springboot框架,application.yml配置多个数据源,使用AOP以及AbstractRootingDataSource.ThreadLocal来实现多数据源切换,以实现读写分离.mysql的主从数据库需要进行设置数据之间的同步. 2.代码实现 application.properties中的配置 spring.datasource.druid.master.driver-class-name=com.mysql.jdbc.Driver spring.data
-
SpringBoot自定义注解使用读写分离Mysql数据库的实例教程
需求场景 为了防止代码中有的SQL慢查询,影响我们线上主数据库的性能.我们需要将sql查询操作切换到从库中进行.为了使用方便,将自定义注解的形式使用. mysql导入的依赖 <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.16</version> </dependency&
-
springboot多数据源配合docker部署mysql主从实现读写分离效果
目录 一.使用docker部署mysql主从 实现主从复制 二.springboot项目多数据源配置,实现读写分离 一.使用docker部署mysql主从 实现主从复制 此次使用的是windows版本docker,mysql版本是5.7 1.使用docker获取mysql镜像 docker pull mysql:5.7.23 #拉取镜像文件 docker images #查看镜像文件 2.使用docker运行mysql master docker run --name mysql-master
-
SpringBoot使用Sharding-JDBC实现数据分片和读写分离的方法
目录 一.Sharding-JDBC简介 二.具体的实现方式 1.maven引用 2.数据库准备 3.Spring配置 4.精准分片算法和范围分片算法的Java代码 5.测试 一.Sharding-JDBC简介 Sharding-JDBC是Sharding-Sphere的一个产品,它有三个产品,分别是Sharding-JDBC.Sharding-Proxy和Sharding-Sidecar,这三个产品提供了标准化的数据分片.读写分离.柔性事务和数据治理功能.我们这里用的是Sharding-JDB
-
SpringBoot详解如何实现读写分离
目录 前言 1.项目引入依赖 2.yml配置 3.启动 4.测试 5.中间所遇到的问题 前言 根据公司业务需求,项目需要读写分离,所以记录下读写分离的过程. 分为两个部分: 1.项目的读写分离. 2.mysql数据库的主从复制. 本篇使用的依赖包为sharding-jdbc-spring-boot-starter,也有考虑直接用dynamic-datasource-spring-boot-starter,但是需要在程序中显式的声明所指定的数据源,并且在从库>=2 的时候需要自己写算法进行读库的选
-
详解MySQL主从复制读写分离搭建
MySQL主从设置 MySQL主从复制,读写分离的设置非常简单: 修改配置my.cnf文件 master 和 slave设置的差不多: [mysqld] log-bin=mysql-bin server-id=222 log-bin=mysql-bin的意思是:启用二进制日志. server-id=222的意思是设置了服务器的唯一ID,默认是1,一般取IP最后一段,可以写成别的,只要不和其他mysql服务器重复就好. 这里,有的MySQL默认的my.cnf文件引用了/etc/mysql/conf
-
springboot详解整合swagger方案
目录 1.Swagger简介 2.整合步骤 1.Swagger简介 Swagger 是一个规范和完整的框架,用于生成.描述.调用和可视化 RESTful 风格的 Web 服务. 官网: ( https://swagger.io/ ) 主要作用是: 1. 使得前后端分离开发更加方便,有利于团队协作 2. 接口的文档在线自动生成,降低后端开发人员编写接口文档的负担 3. 功能测试 Spring已经将Swagger纳入自身的标准,建立了Spring-swagger项目,现在叫 Springfox.通过
-
springBoot详解集成Swagger流程
目录 Swagger简介 SpringBoot集成Swagger 配置Swagger Swagger配置扫描接口 配置是否启动Swagger 配置API文档的分组 实体类配置 常用的注解 小结 目标: 了解Swagger的作用和概念 了解前后端分离 在springBoot中集成Swagger Swagger简介 前后端分离 VUE+springBoot 后端 :后端控制层.服务层.数据访问层 前端 :前端控制层.视图层 前后端通过API进行交互 前后端相对独立,松耦合 可以部署在不同的服务器上
-
springboot基于Mybatis mysql实现读写分离
近日工作任务较轻,有空学习学习技术,遂来研究如果实现读写分离.这里用博客记录下过程,一方面可备日后查看,同时也能分享给大家(网上的资料真的大都是抄来抄去,,还不带格式的,看的真心难受). 完整代码:https://github.com/FleyX/demo-project/tree/master/dxfl 1.背景 一个项目中数据库最基础同时也是最主流的是单机数据库,读写都在一个库中.当用户逐渐增多,单机数据库无法满足性能要求时,就会进行读写分离改造(适用于读多写少),写操作一个库,读操作多个库
-
详解Flask前后端分离项目案例
简介 学习慕课课程,Flask前后端分离API后台接口的实现demo,前端可以接入小程序,暂时已经完成后台API基础架构,使用 postman 调试.git 重构部分: ken校验模块 auths认证模块 scope权限模块,增加全局扫描器(参考flask HTTPExceptions模块) 收获 我们可以接受定义时的复杂,但不能接受调用时的复杂 如果你觉得写代码厌倦,无聊,那你只是停留在功能的实现上,功能的实现很简单,你要追求的是更好的写法,抽象的艺术,不是机械的劳动而是要 创造 ,要有自己的
-
详解Spring Boot 打包分离依赖JAR 和配置文件
1:自定义路径 <properties> <!--自定义路径--> <directory>d:/im/</directory> </properties> 2:把配置文件打包出来 <build> <plugins> <!--上线部署 JAR启动分离依赖lib和配置--> <!--打包jar--> <plugin> <groupId>org.apache.maven.plugi
-
详解Flutter如何读写文本文件
目录 介绍 示例 1:加载内容 预览 完整代码 示例 2: Reading and Writing 获取文件路径 示例预览 完整的代码和解释 介绍 文本文件(具有 .txt扩展名)广泛用于持久存储信息,从数字数据到长文本.今天,我将介绍 2 个使用此文件类型的 Flutter 应用程序示例. 第一个示例快速而简单.它仅使用 rootBundle(来自 services.dart)从 assets 文件夹(或根项目中的另一个文件夹)中的文本加载内容,然后将结果输出到屏幕上.当您只需要读取数据而不需
-
springboot详解实现车险理赔信息管理系统代码
目录 一,项目简介 二,环境介绍 三,系统展示 四,核心代码展示 五,项目总结 一,项目简介 客户的主要功能:个人资料管理,购买的保险信息管理,理赔的申请 事故调查员功能:个人资料管理,事故调查管理,现场勘察管理 管理员功能:个人资料管理,用户管理,理赔审请审核,赔偿金发放管理 二,环境介绍 语言环境:Java: jdk1.8 数据库:Mysql: mysql5.7 应用服务器:Tomcat: tomcat8.5.31 开发工具:IDEA或eclipse 开发技术:后台springboot+sp