Python编程快速上手——正则表达式查找功能案例分析
本文实例讲述了Python正则表达式查找功能。分享给大家供大家参考,具体如下:
题目如下:
- 编写一个程序,打开文件夹中所有的.txt文件,查找匹配用户提供的正则表达式的所有行。结果应该打印到屏幕上。
思路如下:
- 程序需要做的事情如下:
遍历文件夹得到所有.txt文件名
打开所有.txt文件,正则表达式进行模式匹配
查找结果显示到屏幕 - 代码需要做的事情如下:
导入re,os模块
定义正则表达式函数
函数内进行正则表达式匹配,并返回匹配所在行列表
for调用os.listdir(path),生成.txt文件名列表
for循环打开所有.txt文件
用户输入需要查找的字符串
for循环遍历函数返回结果
输出结果到屏幕
代码如下:
import os, re
def fileRex(inputStr,txtLines):
txtRex = re.compile(r'{0}'.format(inputStr)) #正则表达式对象
blockList = []
i = 0
for t in txtLines:
try:
mo1 = txtRex.search(t)
mo1.group()
#search()方法匹配成功生成match对象,group()返回匹配到的对象,匹配成功即表示这一行为需要查找结果,添加到列表
i += 1 #计数
blockList.append(t)
except:
continue
#search()方法未匹配成功会报错,程序崩溃,因此需要except加上continue,进入下一次循环
print("匹配到的模式个数:",i)
return blockList
nameList = [] #创建文件名列表
file = input("请输入文件夹绝对路径(如:C:\\Users\\Administrator\\Desktop\\exam):") #\\转义字符相当于 \
for fileName in os.listdir(file): #os.listdir()方法遍历文件夹
p = 0
if fileName.endswith('.txt'): #enswith方法,判断字符串结尾,检查文件名后缀是不是.txt文本文件
nameList.append(fileName) #添加到文件名列表
p += 1
else:
continue
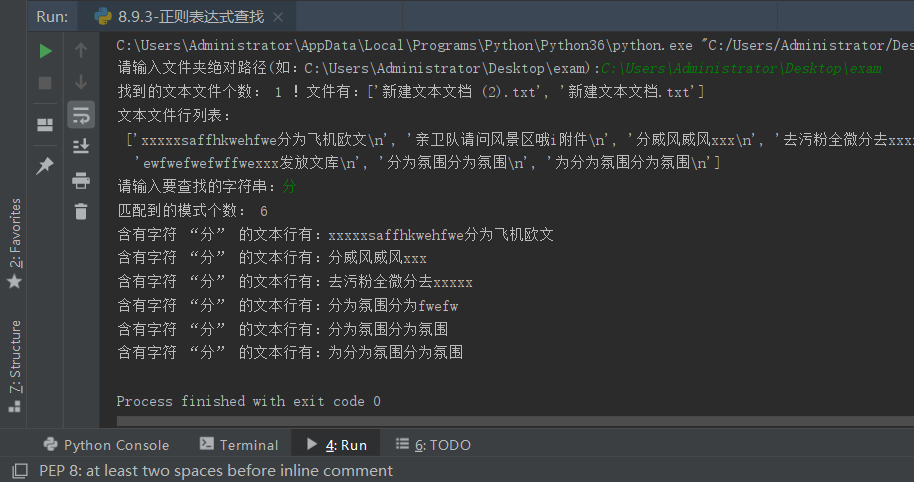
print("找到的文本文件个数: {0} !文件有:{1}".format(p,nameList))
txtLines = [] #创建存放文本行的列表
for i in nameList:
txtFile = open('{0}\\{1}'.format(file,i)) #open函数创建file对象
txtLines += txtFile.readlines() #readlines返回列表,+ 号连接返回的列表
print("文本文件行列表:\n",txtLines) #输出文本行列表
inputStr = input("请输入要查找的字符串:")
for k in fileRex(inputStr,txtLines): #调用函数,循环遍历返回的列表
k = k.strip('\n') #去掉列表字符串中的空格
print("含有字符 “{0}” 的文本行有:{1}".format(inputStr,k)) #输出查找结果
输出结果如下:
PS:这里再为大家提供2款非常方便的正则表达式工具供大家参考使用:
JavaScript正则表达式在线测试工具:
http://tools.jb51.net/regex/javascript
正则表达式在线生成工具:
http://tools.jb51.net/regex/create_reg
更多关于Python相关内容可查看本站专题:《Python正则表达式用法总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。
相关推荐
-

Python中正则表达式的详细教程
1.了解正则表达式 正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符.及这些特定字符的组合,组成一个"规则字符串",这个"规则字符串"用来表达对字符串的一种过滤逻辑. 正则表达式是用来匹配字符串非常强大的工具,在其他编程语言中同样有正则表达式的概念,Python同样不例外,利用了正则表达式,我们想要从返回的页面内容提取出我们想要的内容就易如反掌了. 正则表达式的大致匹配过程是: 1.依次拿出表达式和文本中的字符比较, 2.如果每
-
比较详细Python正则表达式操作指南(re使用)
就其本质而言,正则表达式(或 RE)是一种小型的.高度专业化的编程语言,(在Python中)它内嵌在Python中,并通过 re 模块实现.使用这个小型语言,你可以为想要匹配的相应字符串集指定规则:该字符串集可能包含英文语句.e-mail地址.TeX命令或任何你想搞定的东西.然後你可以问诸如"这个字符串匹配该模式吗?"或"在这个字符串中是否有部分匹配该模式呢?".你也可以使用 RE 以各种方式来修改或分割字符串. 正则表达式模式被编译成一系列的字节码,然後由用 C
-
python的正则表达式re模块的常用方法
1.re的简介 使用python的re模块,尽管不能满足所有复杂的匹配情况,但足够在绝大多数情况下能够有效地实现对复杂字符串的分析并提取出相关信息.python 会将正则表达式转化为字节码,利用 C 语言的匹配引擎进行深度优先的匹配. 复制代码 代码如下: import re print re.__doc__ 可以查询re模块的功能信息,下面会结合几个例子说明. 2.re的正则表达式语法 正则表达式语法表如下: 语法 意义 说明 "." 任意字符 "^" 字符串开始
-
在python中使用正则表达式查找可嵌套字符串组
在网上看到一个小需求,需要用正则表达式来处理.原需求如下: 找出文本中包含"因为--所以"的句子,并以两个词为中心对齐输出前后3个字,中间全输出,如果"因为"和"所以"中间还存在"因为""所以",也要找出来,另算一行,输出格式为: 行号 前面3个字 *因为* 全部 &所以& 后面3个字(标点符号算一个字) 2 还不是 *因为* 这里好, &所以& 没有人 实现方法如下: #e
-
Python 实用技巧之正则表达式查找和替换文本的操作方法
1.需求 我们想对字符串中的文本做查找和替换. 2.解决方案 对于简单的文本模式,使用str.replace()即可. 例如: text='mark ,帅哥,18,183 帅,mark' print(text.replace('18','19')) print(text) 运行结果: mark ,帅哥,19,193 帅,mark mark ,帅哥,18,183 帅,mark 针对更为复杂的模式,可以使用re模块中的sub()函数. 实例:将日期格式从"11/28/2018"改为&quo
-
python利用正则表达式提取字符串
前言 正则表达式的基础知识就不说了,有兴趣的可以点击这里,提取一般分两种情况,一种是提取在文本中提取单个位置的字符串,另一种是提取连续多个位置的字符串.日志分析会遇到这种情况,下面我会分别讲一下对应的方法. 一.单个位置的字符串提取 这种情况我们可以使用(.+?)这个正则表达式来提取. 举例,一个字符串"a123b",如果我们想提取ab之间的值123,可以使用findall配合正则表达式,这样会返回一个包含所以符合情况的list. 代码如下: import re str = "
-
Python基于正则表达式实现检查文件内容的方法【文件检索】
本文实例讲述了Python基于正则表达式实现检查文件内容的方法分享给大家供大家参考,具体如下: 这个是之前就在学python,欣赏python的小巧但是功能强大,是连电池都自带的语言.平时工作中用Java ,觉得python在日常生活中比java用处要大,首先语法没那么复杂,特别是io的操作,java里要写一大坨没关的代码.还有就是不用编译,而且linux系统默认都会自带. 这次遇到的问题是工作当中想要迁移一个系统中的一个模块,这个时候需要评估模块里的代码有没有对其他代码强依赖,就是有没有imp
-
python中redis查看剩余过期时间及用正则通配符批量删除key的方法
具体代码如下所示: # -*- coding: utf-8 -*- import redis import datetime ''' # 1. redis设置过期时间的两种方式 expire函数设置过期时间为10秒.10秒后,ex1将会失效 expireat设置一个具体的时间,15年9月8日15点19分10秒,过了这个时间,ex2将失效 如果设置过期时间成功会返回True,反之返回False ''' pool = redis.ConnectionPool(host='192.168.3.128'
-
PYTHON正则表达式 re模块使用说明
首先,运行 Python 解释器,导入 re 模块并编译一个 RE: #!python Python 2.2.2 (#1, Feb 10 2003, 12:57:01) >>> import re >>> p = re.compile('[a-z]+') >>> p <_sre.SRE_Pattern object at 80c3c28> 现在,你可以试着用 RE 的 [a-z]+ 去匹配不同的字符串.一个空字符串将根本不能匹配,因为 +
-
python通过正则查找微博@(at)用户的方法
本文实例讲述了python通过正则查找微博@(at)用户的方法.分享给大家供大家参考.具体如下: 这段代码用到了python正则的findall方法,查找所有被@的用户,使用数组形式返回用户昵称 import re users = re.findall(r'@([\u4e00-\u9fa5\w\-]+)','nihao @dfugo @jb51 haha') print(users) 返回结果如下: ['dfugo', 'jb51'] 希望本文所述对大家的Python程序设计有所帮助.
-
python正则匹配查询港澳通行证办理进度示例分享
复制代码 代码如下: import socketimport re '''广东省公安厅出入境政务服务网护照,通行证办理进度查询.分析网址格式为 http://www.gdcrj.com/wsyw/tcustomer/tcustomer.do?&method=find&applyid=身份证号码构造socket请求网页html,利用正则匹配出查询结果'''def gethtmlbyidentityid(identityid): s = socket.socket(socket.AF_INET