Python封装数据库连接池详解
目录
- 一、数据库封装
- 1.1数据库基本配置
- 1.2 编写单例模式注解
- 1.3 构建连接池
- 1.4 封装Python操作MYSQL的代码
- 二、连接池测试
- 场景一:同一个实例,执行2次sql
- 场景二:依次创建2个实例,各自执行sql
- 场景三:启动2个线程,但是线程在创建连接池实例时,有时间间隔
- 场景四:启动2个线程,线程在创建连接池实例时,没有时间间隔
前言:
线程安全问题:当2个线程同时用到线程池时,会同时创建2个线程池。如果多个线程,错开用到线程池,就只会创建一个线程池,会共用一个线程池。我用的注解方式的单例模式,感觉就是这个注解的单例方式,解决了多线程问题,但是没解决线程安全问题,需要优化这个单例模式。
主要通过 PooledDB 模块实现。
一、数据库封装
1.1数据库基本配置
db_config.py
# -*- coding: UTF-8 -*- import pymysql # 数据库信息 DB_TEST_HOST = "127.0.0.1" DB_TEST_PORT = 3308 DB_TEST_DBNAME = "bt" DB_TEST_USER = "root" DB_TEST_PASSWORD = "123456" # 数据库连接编码 DB_CHARSET = "utf8" # mincached : 启动时开启的闲置连接数量(缺省值 0 开始时不创建连接) DB_MIN_CACHED = 5 # maxcached : 连接池中允许的闲置的最多连接数量(缺省值 0 代表不闲置连接池大小) DB_MAX_CACHED = 0 # maxshared : 共享连接数允许的最大数量(缺省值 0 代表所有连接都是专用的)如果达到了最大数量,被请求为共享的连接将会被共享使用 DB_MAX_SHARED = 5 # maxconnecyions : 创建连接池的最大数量(缺省值 0 代表不限制) DB_MAX_CONNECYIONS = 300 # blocking : 设置在连接池达到最大数量时的行为(缺省值 0 或 False 代表返回一个错误<toMany......> 其他代表阻塞直到连接数减少,连接被分配) DB_BLOCKING = True # maxusage : 单个连接的最大允许复用次数(缺省值 0 或 False 代表不限制的复用).当达到最大数时,连接会自动重新连接(关闭和重新打开) DB_MAX_USAGE = 0 # setsession : 一个可选的SQL命令列表用于准备每个会话,如["set datestyle to german", ...] DB_SET_SESSION = None # creator : 使用连接数据库的模块 DB_CREATOR = pymysql
设置连接池最大最小为5个。则启动连接池时,就会建立5个连接。
1.2 编写单例模式注解
singleton.py
#单例模式函数,用来修饰类
def singleton(cls,*args,**kw):
instances = {}
def _singleton():
if cls not in instances:
instances[cls] = cls(*args,**kw)
return instances[cls]
return _singleton
1.3 构建连接池
db_dbutils_init.py
from dbutils.pooled_db import PooledDB
import db_config as config
# import random
from singleton import singleton
"""
@功能:创建数据库连接池
"""
class MyConnectionPool(object):
# 私有属性
# 能通过对象直接访问,但是可以在本类内部访问;
__pool = None
# def __init__(self):
# self.conn = self.__getConn()
# self.cursor = self.conn.cursor()
# 创建数据库连接conn和游标cursor
def __enter__(self):
self.conn = self.__getconn()
self.cursor = self.conn.cursor()
# 创建数据库连接池
def __getconn(self):
if self.__pool is None:
# i = random.randint(1, 100)
# print("创建线程池的数量"+str(i))
self.__pool = PooledDB(
creator=config.DB_CREATOR,
mincached=config.DB_MIN_CACHED,
maxcached=config.DB_MAX_CACHED,
maxshared=config.DB_MAX_SHARED,
maxconnections=config.DB_MAX_CONNECYIONS,
blocking=config.DB_BLOCKING,
maxusage=config.DB_MAX_USAGE,
setsession=config.DB_SET_SESSION,
host=config.DB_TEST_HOST,
port=config.DB_TEST_PORT,
user=config.DB_TEST_USER,
passwd=config.DB_TEST_PASSWORD,
db=config.DB_TEST_DBNAME,
use_unicode=False,
charset=config.DB_CHARSET
)
return self.__pool.connection()
# 释放连接池资源
def __exit__(self, exc_type, exc_val, exc_tb):
self.cursor.close()
self.conn.close()
# 关闭连接归还给链接池
# def close(self):
# self.cursor.close()
# self.conn.close()
# 从连接池中取出一个连接
def getconn(self):
conn = self.__getconn()
cursor = conn.cursor()
return cursor, conn
# 获取连接池,实例化
@singleton
def get_my_connection():
return MyConnectionPool()
1.4 封装Python操作MYSQL的代码
mysqlhelper.py
import time
from db_dbutils_init import get_my_connection
"""执行语句查询有结果返回结果没有返回0;增/删/改返回变更数据条数,没有返回0"""
class MySqLHelper(object):
def __init__(self):
self.db = get_my_connection() # 从数据池中获取连接
#
# def __new__(cls, *args, **kwargs):
# if not hasattr(cls, 'inst'): # 单例
# cls.inst = super(MySqLHelper, cls).__new__(cls, *args, **kwargs)
# return cls.inst
# 封装执行命令
def execute(self, sql, param=None, autoclose=False):
"""
【主要判断是否有参数和是否执行完就释放连接】
:param sql: 字符串类型,sql语句
:param param: sql语句中要替换的参数"select %s from tab where id=%s" 其中的%s就是参数
:param autoclose: 是否关闭连接
:return: 返回连接conn和游标cursor
"""
cursor, conn = self.db.getconn() # 从连接池获取连接
count = 0
try:
# count : 为改变的数据条数
if param:
count = cursor.execute(sql, param)
else:
count = cursor.execute(sql)
conn.commit()
if autoclose:
self.close(cursor, conn)
except Exception as e:
pass
return cursor, conn, count
# 释放连接
def close(self, cursor, conn):
"""释放连接归还给连接池"""
cursor.close()
conn.close()
# 查询所有
def selectall(self, sql, param=None):
cursor = None
conn = None
count = None
try:
cursor, conn, count = self.execute(sql, param)
res = cursor.fetchall()
return res
except Exception as e:
print(e)
self.close(cursor, conn)
return count
# 查询单条
def selectone(self, sql, param=None):
cursor = None
conn = None
count = None
try:
cursor, conn, count = self.execute(sql, param)
res = cursor.fetchone()
self.close(cursor, conn)
return res
except Exception as e:
print("error_msg:", e.args)
self.close(cursor, conn)
return count
# 增加
def insertone(self, sql, param):
cursor = None
conn = None
count = None
try:
cursor, conn, count = self.execute(sql, param)
# _id = cursor.lastrowid() # 获取当前插入数据的主键id,该id应该为自动生成为好
conn.commit()
self.close(cursor, conn)
return count
except Exception as e:
print(e)
conn.rollback()
self.close(cursor, conn)
return count
# 增加多行
def insertmany(self, sql, param):
"""
:param sql:
:param param: 必须是元组或列表[(),()]或((),())
:return:
"""
cursor, conn, count = self.db.getconn()
try:
cursor.executemany(sql, param)
conn.commit()
return count
except Exception as e:
print(e)
conn.rollback()
self.close(cursor, conn)
return count
# 删除
def delete(self, sql, param=None):
cursor = None
conn = None
count = None
try:
cursor, conn, count = self.execute(sql, param)
self.close(cursor, conn)
return count
except Exception as e:
print(e)
conn.rollback()
self.close(cursor, conn)
return count
# 更新
def update(self, sql, param=None):
cursor = None
conn = None
count = None
try:
cursor, conn, count = self.execute(sql, param)
conn.commit()
self.close(cursor, conn)
return count
except Exception as e:
print(e)
conn.rollback()
self.close(cursor, conn)
return count
# if __name__ == '__main__':
# db = MySqLHelper()
# sql = "SELECT SLEEP(10)"
# db.execute(sql)
# time.sleep(20)
# TODO 查询单条
# sql1 = 'select * from userinfo where name=%s'
# args = 'python'
# ret = db.selectone(sql=sql1, param=args)
# print(ret) # (None, b'python', b'123456', b'0')
# TODO 增加单条
# sql2 = 'insert into hotel_urls(cname,hname,cid,hid,url) values(%s,%s,%s,%s,%s)'
# ret = db.insertone(sql2, ('1', '2', '1', '2', '2'))
# print(ret)
# TODO 增加多条
# sql3 = 'insert into userinfo (name,password) VALUES (%s,%s)'
# li = li = [
# ('分省', '123'),
# ('到达','456')
# ]
# ret = db.insertmany(sql3,li)
# print(ret)
# TODO 删除
# sql4 = 'delete from userinfo WHERE name=%s'
# args = 'xxxx'
# ret = db.delete(sql4, args)
# print(ret)
# TODO 更新
# sql5 = r'update userinfo set password=%s WHERE name LIKE %s'
# args = ('993333993', '%old%')
# ret = db.update(sql5, args)
# print(ret)
二、连接池测试
修改 db_dbutils_init.py 文件,在创建连接池def __getconn(self):方法下,加一个打印随机数,方便将来我们定位是否时单例的线程池。

修改后的db_dbutils_init.py 文件:
from dbutils.pooled_db import PooledDB
import db_config as config
import random
from singleton import singleton
"""
@功能:创建数据库连接池
"""
class MyConnectionPool(object):
# 私有属性
# 能通过对象直接访问,但是可以在本类内部访问;
__pool = None
# def __init__(self):
# self.conn = self.__getConn()
# self.cursor = self.conn.cursor()
# 创建数据库连接conn和游标cursor
def __enter__(self):
self.conn = self.__getconn()
self.cursor = self.conn.cursor()
# 创建数据库连接池
def __getconn(self):
if self.__pool is None:
i = random.randint(1, 100)
print("线程池的随机数"+str(i))
self.__pool = PooledDB(
creator=config.DB_CREATOR,
mincached=config.DB_MIN_CACHED,
maxcached=config.DB_MAX_CACHED,
maxshared=config.DB_MAX_SHARED,
maxconnections=config.DB_MAX_CONNECYIONS,
blocking=config.DB_BLOCKING,
maxusage=config.DB_MAX_USAGE,
setsession=config.DB_SET_SESSION,
host=config.DB_TEST_HOST,
port=config.DB_TEST_PORT,
user=config.DB_TEST_USER,
passwd=config.DB_TEST_PASSWORD,
db=config.DB_TEST_DBNAME,
use_unicode=False,
charset=config.DB_CHARSET
)
return self.__pool.connection()
# 释放连接池资源
def __exit__(self, exc_type, exc_val, exc_tb):
self.cursor.close()
self.conn.close()
# 关闭连接归还给链接池
# def close(self):
# self.cursor.close()
# self.conn.close()
# 从连接池中取出一个连接
def getconn(self):
conn = self.__getconn()
cursor = conn.cursor()
return cursor, conn
# 获取连接池,实例化
@singleton
def get_my_connection():
return MyConnectionPool()
开始测试:
场景一:同一个实例,执行2次sql
from mysqlhelper import MySqLHelper
import time
if __name__ == '__main__':
sql = "SELECT SLEEP(10)"
sql1 = "SELECT SLEEP(15)"
db = MySqLHelper()
db.execute(sql)
db.execute(sql1)
time.sleep(20)
在数据库中,使用 show processlist;
show processlist;
当执行第一个sql时。数据库连接显示。
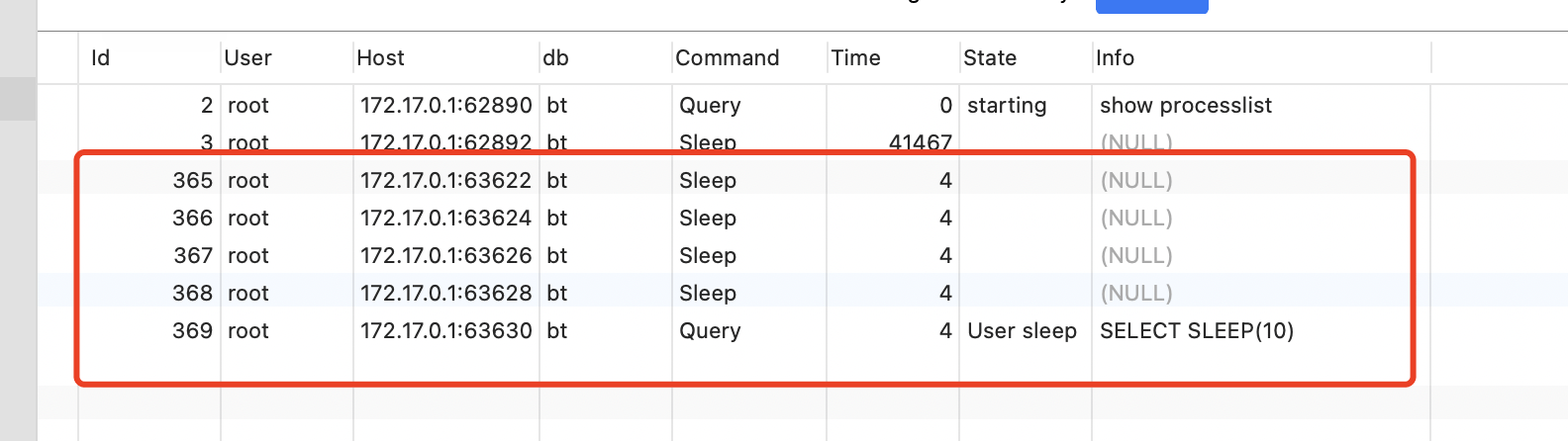
当执行第二个sql时。数据库连接显示:
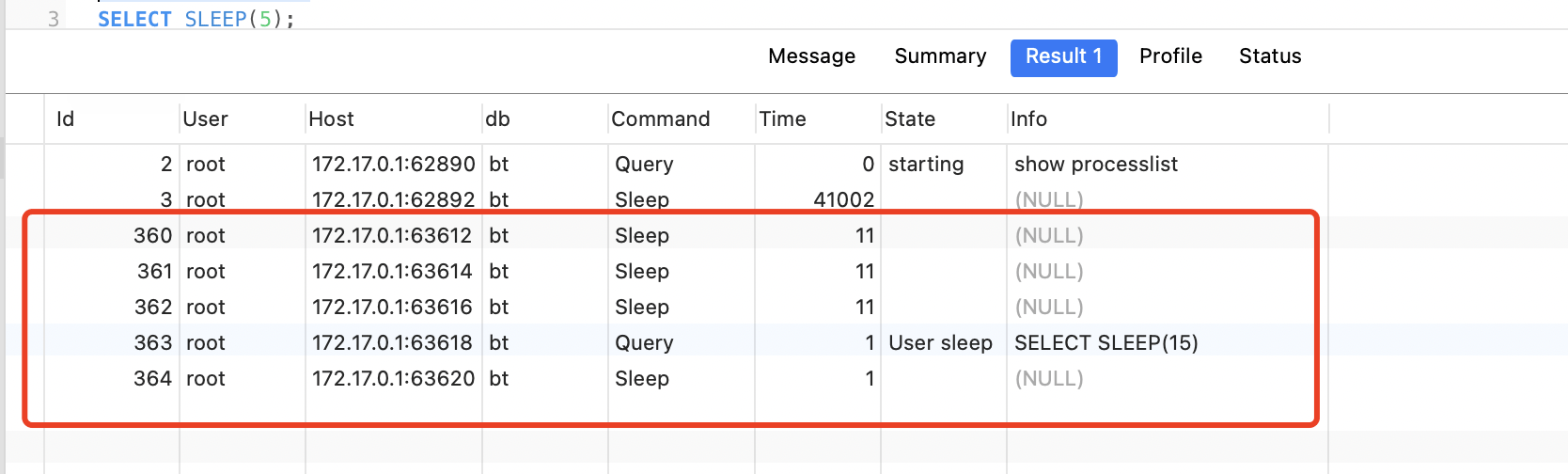
当执行完sql,程序sleep时。数据库连接显示:
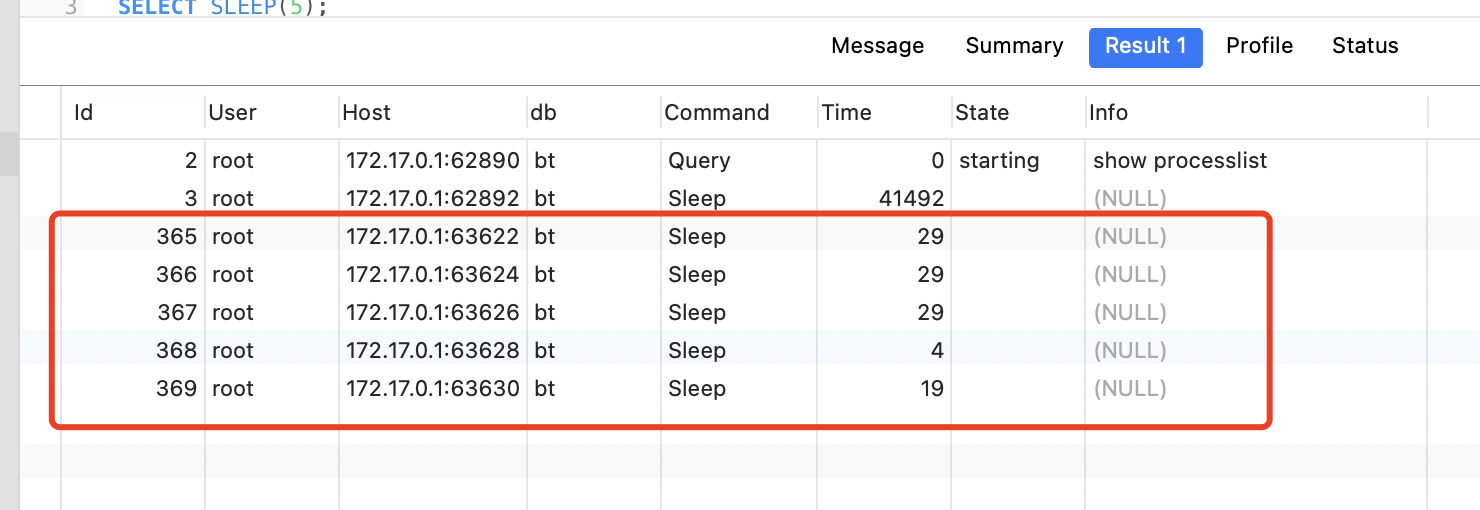
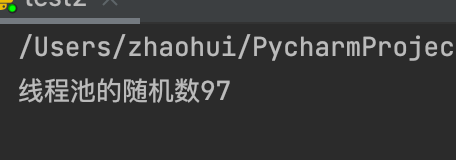
程序打印结果:
线程池的随机数43
由以上可以得出结论:
线程池启动后,生成了5个连接。执行第一个sql时,使用了1个连接。执行完第一个sql后,使用了另外1个连接。 这是一个线性的,线程池中一共5个连接,但是每次执行,只使用了其中一个。
有个疑问,连接池如果不支持并发是不是就毫无意义?
如上,虽然开了线程池5个连接,但是每次执行sql,只用到了一个连接。那为何不设置线程池大小为1呢?设置线程池大小的意义何在呢?(如果在非并发的场景下,是不是设置大小无意义?)
相比于不用线程池的优点:
如果不用线程池,则每次执行一个sql都要创建、断开连接。 像我们这样使用连接池,不用反复创建、断开连接,拿现成的连接直接用就好了。
场景二:依次创建2个实例,各自执行sql
from mysqlhelper import MySqLHelper
import time
if __name__ == '__main__':
db = MySqLHelper()
db1 = MySqLHelper()
sql = "SELECT SLEEP(10)"
sql1 = "SELECT SLEEP(15)"
db.execute(sql)
db1.execute(sql1)
time.sleep(20)
第一个实例db,执行sql。线程池启动了5个连接
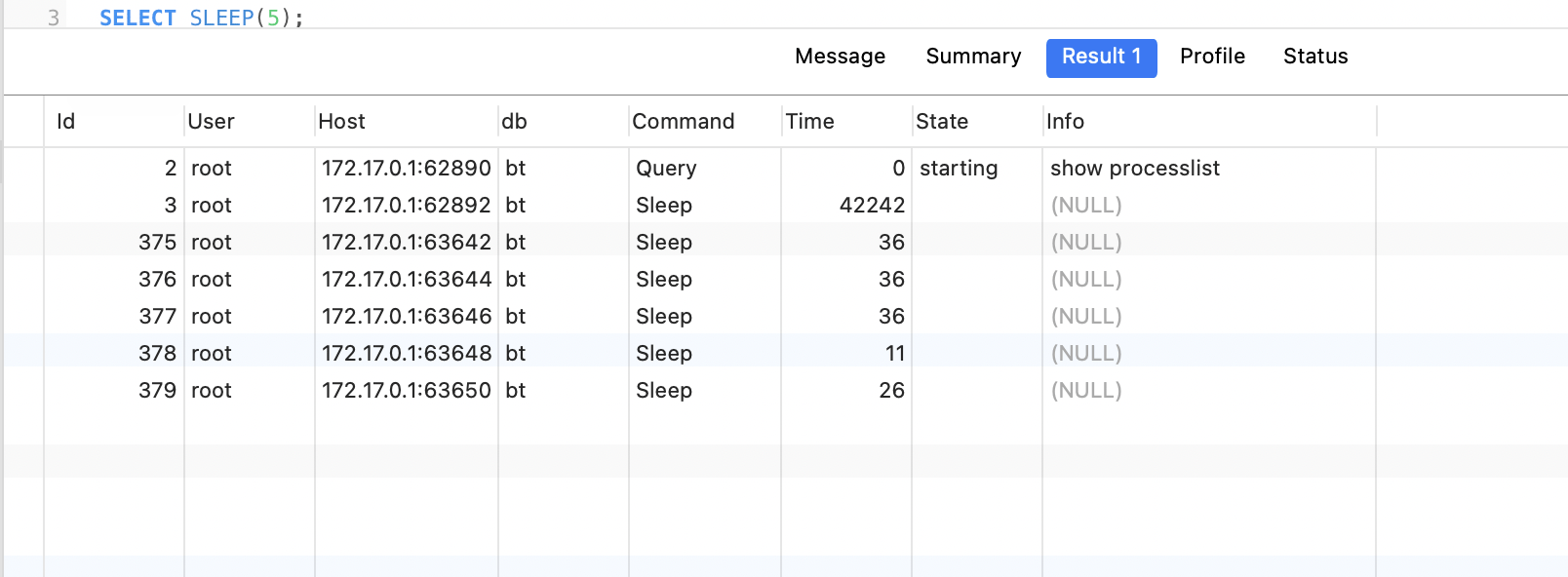
第二个实例db1,执行sql:
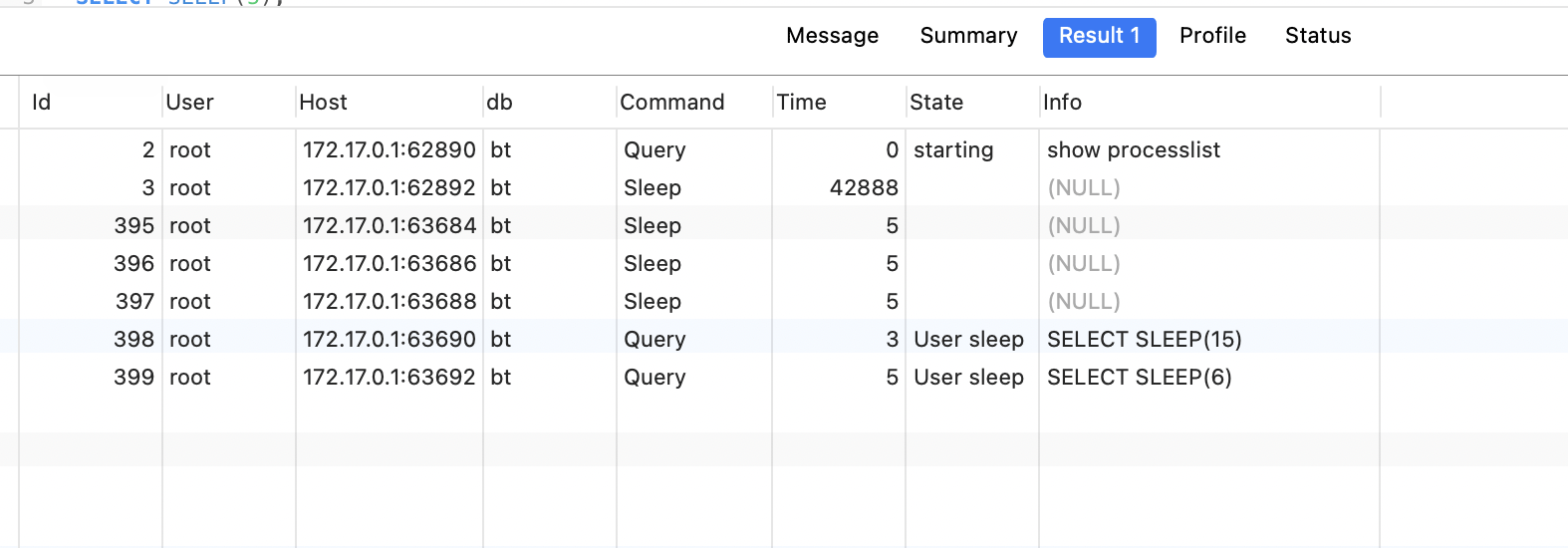
程序睡眠时,一共5个线程池:
打印结果:
结果证明:
虽然我们依次创建了2个实例,但是(1)创建线程池的打印结果,只打印1次,且从始至终,线程池一共只启动了5个连接,且连接的id没有发生改变,说明一直是这5个连接。
证明,我们虽然创建了2个实例,但是这2个实例其实是一个实例。(单例模式是生效的)
场景三:启动2个线程,但是线程在创建连接池实例时,有时间间隔
import threading
from mysqlhelper import MySqLHelper
import time
def sl1():
time.sleep(2)
db = MySqLHelper()
sql = "SELECT SLEEP(6)"
db.execute(sql)
def sl2():
time.sleep(4)
db = MySqLHelper()
sql = "SELECT SLEEP(15)"
db.execute(sql)
if __name__ == '__main__':
threads = []
t1 = threading.Thread(target=sl1)
threads.append(t1)
t2 = threading.Thread(target=sl2)
threads.append(t2)
for t in threads:
t.setDaemon(True)
t.start()
time.sleep(20)
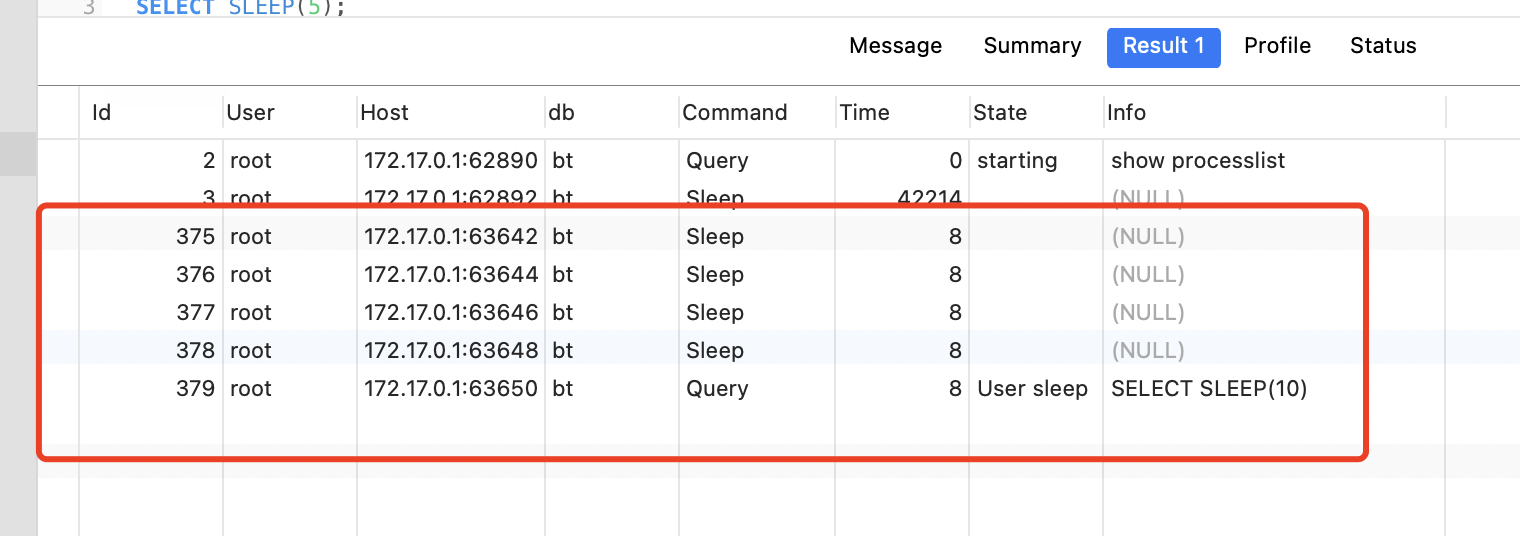
2个线程间隔了2秒。
观察数据库的连接数量:

打印结果:
在并发执行2个sql时,共用了这5个连接,且打印结果只打印了一次,说明虽然并发创建了2次实例,但真正只创建了一个连接池。
场景四:启动2个线程,线程在创建连接池实例时,没有时间间隔
import threading
from mysqlhelper import MySqLHelper
import time
if __name__ == '__main__':
db = MySqLHelper()
sql = "SELECT SLEEP(6)"
sql1 = "SELECT SLEEP(15)"
threads = []
t1 = threading.Thread(target=db.execute, args=(sql,))
threads.append(t1)
t2 = threading.Thread(target=db.execute, args=(sql1,))
threads.append(t2)
for t in threads:
t.setDaemon(True)
t.start()
time.sleep(20)
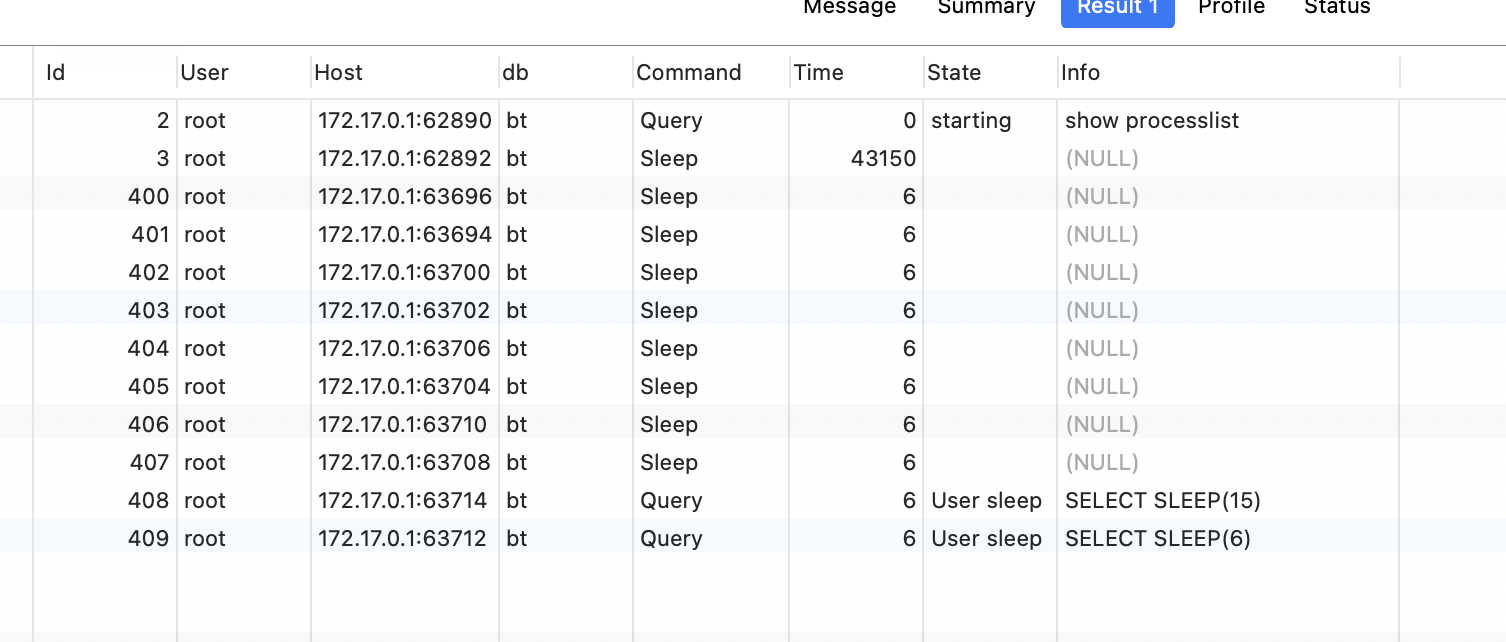
观察数据库连接 :
打印结果:

结果表明:
终端打印了2次,数据库建立了10个连接,说明创建了2个线程池。这样的单例模式,存在线程安全问题。
到此这篇关于Python封装数据库连接池详解的文章就介绍到这了,更多相关Python连接池内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python实现Mysql数据库连接池实例详解
python连接Mysql数据库: Python编程中可以使用MySQLdb进行数据库的连接及诸如查询/插入/更新等操作,但是每次连接MySQL数据库请求时,都是独立的去请求访问,相当浪费资源,而且访问数量达到一定数量时,对mysql的性能会产生较大的影响.因此,实际使用中,通常会使用数据库的连接池技术,来访问数据库达到资源复用的目的. 数据库连接池 python的数据库连接池包 DBUtils: DBUtils是一套Python数据库连接池包,并允许对非线程安全的数据库接口进行线程安全包装.D
-
构建高效的python requests长连接池详解
前文: 最近在搞全网的CDN刷新系统,在性能调优时遇到了requests长连接的一个问题,以前关注过长连接太多造成浪费的问题,但因为系统都是分布式扩展的,针对这种各别问题就懒得改动了. 现在开发的缓存刷新系统,对于性能还是有些敏感的,我后面会给出最优的http长连接池构建方式. 老生常谈: python下的httpclient库哪个最好用? 我想大多数人还是会选择requests库的.原因么?也就是简单,易用! 如何蛋疼的构建reqeusts的短连接请求: python requests库默认就
-
Python MySQL数据库连接池组件pymysqlpool详解
引言 pymysqlpool (本地下载)是数据库工具包中新成员,目的是能提供一个实用的数据库连接池中间件,从而避免在应用中频繁地创建和释放数据库连接资源. 功能 连接池本身是线程安全的,可在多线程环境下使用,不必担心连接资源被多个线程共享的问题: 提供尽可能紧凑的接口用于数据库操作: 连接池的管理位于包内完成,客户端可以通过接口获取池中的连接资源(返回 pymysql.Connection): 将最大程度地与 dataobj 等兼容,便于使用: 连接池本身具备动态增加连接数的功能,即 max_
-
分析解决Python中sqlalchemy数据库连接池QueuePool异常
目录 数据库相关错误的解决办法 错误一:数据库连接池超过限制 错误二:数据库事务未回滚 数据库相关错误的解决办法 错误一:数据库连接池超过限制 SqlAlchemy QueuePool limit overflow 造成连接数超过数据库连接池的限制,有两方面的原因,第一个是由于数据库连接池数比较小,因此当连接数稍微增加的时候就会超过限制,另一个原因就是在使用完数据库连接后未能即使释放,最后造成数据连接数持续增加从而超出数据库连接池的限制,所以我们也可以从这两个方面来解决这个问题,但是根本上还是得
-
Python 中创建 PostgreSQL 数据库连接池
目录 习惯于使用数据库之前都必须创建一个连接池,即使是单线程的应用,只要有多个方法中需用到数据库连接,建立一两个连接的也会考虑先池化他们.连接池的好处多多, 1) 如果反复创建连接相当耗时, 2) 对于单个连接一路用到底的应用,有连接池时避免了数据库连接对象传来传去, 3) 忘记关连接了,连接池幸许还能帮忙在一定时长后关掉,当然密集取连接的应用势将耗尽连接, 4) 一个应用打开连接的数量是可控的 接触到 Python 后,在使用 PostgreSQL 也自然而然的考虑创建连接池,使用时从池中取,
-
python连接池实现示例程序
复制代码 代码如下: import socketimport Queueimport threading def worker(): while True: i = q.get() conn=i[0] addr=i[1] while 1: sms=conn.recv(1024) if sms!="": print "Message from
-
python自制简易mysql连接池的实现示例
目录 连接池是什么? 为什么需要连接池? 连接池的原理是什么? 使用python语言自制简易mysql连接池 开始使用 自定义配置文件名 & 配置标签 命名思路 GitHub地址 今天我们来说一点不一样的, 使用python语言手撸mysql连接池. 连接池是什么? 连接池是创建和管理一个连接的缓冲池的技术,这些连接准备好被任何需要它们的线程使用.在并发量足够时连接池一般比直接连接性能更优, 不仅提高了性能的同时还管理了宝贵的资源. 为什么需要连接池? 讨论这个问题时, 我们需要先了解高并发导致
-
Python3 多线程(连接池)操作MySQL插入数据
多线程(连接池)操作MySQL插入数据 针对于此篇博客的收获心得: 首先是可以构建连接数据库的连接池,这样可以多开启连接,同一时间连接不同的数据表进行查询,插入,为多线程进行操作数据库打基础 多线程根据多连接的方式,需求中要完成多语言的入库操作,我们可以启用多线程对不同语言数据进行并行操作 在插入过程中,一条一插入,比较浪费时间,我们可以把数据进行积累,积累到一定的条数的时候,执行一条sql命令,一次性将多条数据插入到数据库中,节省时间cur.executemany 1.主要模块 DBUtils
-
Python封装数据库连接池详解
目录 一.数据库封装 1.1数据库基本配置 1.2 编写单例模式注解 1.3 构建连接池 1.4 封装Python操作MYSQL的代码 二.连接池测试 场景一:同一个实例,执行2次sql 场景二:依次创建2个实例,各自执行sql 场景三:启动2个线程,但是线程在创建连接池实例时,有时间间隔 场景四:启动2个线程,线程在创建连接池实例时,没有时间间隔 前言: 线程安全问题:当2个线程同时用到线程池时,会同时创建2个线程池.如果多个线程,错开用到线程池,就只会创建一个线程池,会共用一个线程池.我用的
-
Java 数据库连接池详解及简单实例
Java 数据库连接池详解 数据库连接池的原理是: 连接池基本的思想是在系统初始化的时候,将数据库连接作为对象存储在内存中,当用户需要访问数据库时,并非建立一个新的连接,而是从连接池中取出一个已建立的空闲连接对象.使用完毕后,用户也并非将连接关闭,而是将连接放回连接池中,以供下一个请求访问使用.而连接的建立.断开都由连接池自身来管理.同时,还可以通过设置连接池的参数来控制连接池中的初始连接数.连接的上下限数以及每个连接的最大使用次数.最大空闲时间等等.也可以通过其自身的管理机制来监视数据库连接的
-
Tomcat 7-dbcp配置数据库连接池详解
Tomcat 7-dbcp配置数据库连接池详解 原理 关于连接池,大家都晓得用来限定对数据库的连接.基本的原理是预先在缓冲池中放入一定的空闲连接,当程序需要和数据库来交互时,不是直接新建数据库连接而是在连接池中直接取,使用完成后再放回到连接池中.为什么要这样牺牲一个缓冲来存放这些原本就会使用的连接呢?在上面讲了一个好处就是可以限定连接数,这样不会造成N多的数据库连接最后宕机:额外有了这样一个连接池,也可以来监听这些连接和便于管理. 配置 1.拷贝相关的jar 要知道连接池不是用来直接操作数据库的
-
Spring事务管理中关于数据库连接池详解
目录 Spring事务管理 环境搭建 标准配置 声明式事务 总结 SqlSessionFactory XML中构建SqlSessionFactory 获得SqlSession的实例 代码实现 作用域(Scope)和生命周期 SqlSessionFactoryBuilder(构造器) SqlSessionFactory(工厂) SqlSession(会话) Spring事务管理 事务(Transaction),一般是指要做的或所做的事情.在计算机术语中是指访问并可能更新数据库中各种数据项的一个程序
-
对Python中创建进程的两种方式以及进程池详解
在Python中创建进程有两种方式,第一种是: from multiprocessing import Process import time def test(): while True: print('---test---') time.sleep(1) if __name__ == '__main__': p=Process(target=test) p.start() while True: print('---main---') time.sleep(1) 上面这段代码是在window
-
Python底层封装实现方法详解
这篇文章主要介绍了Python底层封装实现方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 事实上,python封装特性的实现纯属"投机取巧",之所以类对象无法直接调用私有方法和属性,是因为底层实现时,python偷偷改变了它们的名称. python在底层实现时,将它们的名称都偷偷改成了"_类名__属性(方法)名"的格式 class Person: def setname(self, name): if le
-
用python构建IP代理池详解
目录 概述 提供免费代理的网站 代码 导包 网站页面的url ip地址 检测 整理 必要参数 总代码 总结 概述 用爬虫时,大部分网站都有一定的反爬措施,有些网站会限制每个 IP 的访问速度或访问次数,超出了它的限制你的 IP 就会被封掉.对于访问速度的处理比较简单,只要间隔一段时间爬取一次就行了,避免频繁访问:而对于访问次数,就需要使用代理 IP 来帮忙了,使用多个代理 IP 轮换着去访问目标网址可以有效地解决问题. 目前网上有很多的代理服务网站提供代理服务,也提供一些免费的代理,但可用性较差
-
SpringBoot HikariCP连接池详解
目录 背景 公用池化包 Commons Pool 2 案例 JMH 测试 数据库连接池 HikariCP 结果缓存池 小结 背景 在我们平常的编码中,通常会将一些对象保存起来,这主要考虑的是对象的创建成本. 比如像线程资源.数据库连接资源或者 TCP 连接等,这类对象的初始化通常要花费比较长的时间,如果频繁地申请和销毁,就会耗费大量的系统资源,造成不必要的性能损失. 并且这些对象都有一个显著的特征,就是通过轻量级的重置工作,可以循环.重复地使用. 这个时候,我们就可以使用一个虚拟的池子,将这些资
-
MySQL数据库设计之利用Python操作Schema方法详解
弓在箭要射出之前,低声对箭说道,"你的自由是我的".Schema如箭,弓似Python,选择Python,是Schema最大的自由.而自由应是一个能使自己变得更好的机会. Schema是什么? 不管我们做什么应用,只要和用户输入打交道,就有一个原则--永远不要相信用户的输入数据.意味着我们要对用户输入进行严格的验证,web开发时一般输入数据都以JSON形式发送到后端API,API要对输入数据做验证.一般我都是加很多判断,各种if,导致代码很丑陋,能不能有一种方式比较优雅的验证用户数据呢