人工智能学习Pytorch进阶操作教程
目录
- 一、合并与分割
- 1.cat拼接
- 2.stack堆叠
- 3.拆分
- ①Split按长度拆分
- ②Chunk按数量拆分
- 二、基本运算
- 1.加减乘除
- 2.矩阵相乘
- 3.次方计算
- 4. clamp
- 三、属性统计
- 1.求范数
- 2.求极值、求和、累乘
- 3. dim和keepdim
- 4.topk和kthvalue
- 5.比较运算
- 6.高阶操作
- ①where
- ②gather
一、合并与分割
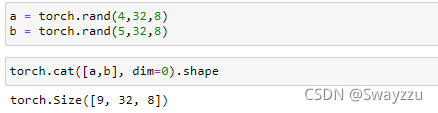
1.cat拼接
直接按照指定的dim维度进行合并,要求除了所需要合并的维度之外,其他的维度需要是一样的
2.stack堆叠
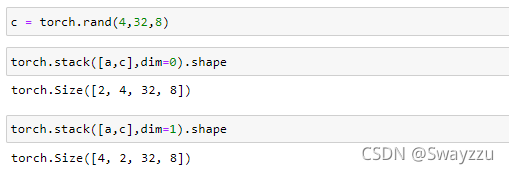
例:此处创建一个和a一样的tensor,按照某一维度进行stack,就会在堆叠的维度前面,生成一个新的维度,用以进行选择,比如新生成了一个2维,就可以通过0,1进行选择。具体是什么意义,取决于实际的问题。
比如两个班成绩单用stack合并,生成的新维度,就可以选择0或1来选择这个新维度,从而达到选择班级的目的。
3.拆分
①Split按长度拆分
第一个参数可以是单独的数字a,意思是每一个拆分出来的部分有a个数据;可以是一个类似list的对象b,意思是把数据按照b里面的方式拆分,拆分成len(b)个tensor。

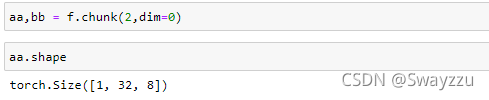
②Chunk按数量拆分
传入的第一个参数就是拆成几个chunk,然后把原来的维度除以这个数量即可。
比如下面的例子,原来维度是[2,32,8],chunk参数传入2,就需要拆成2个,则2/2=1,最终每一个的维度变为[1,32,8]。
二、基本运算
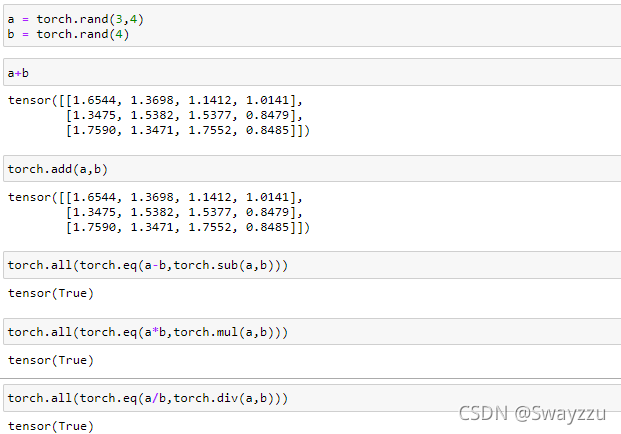
1.加减乘除
和numpy中的一致。也可以使用torch.add等方法。
2.矩阵相乘
注意,*就是元素与元素相乘,而矩阵相乘可以用以下两种:torch.matmul,@
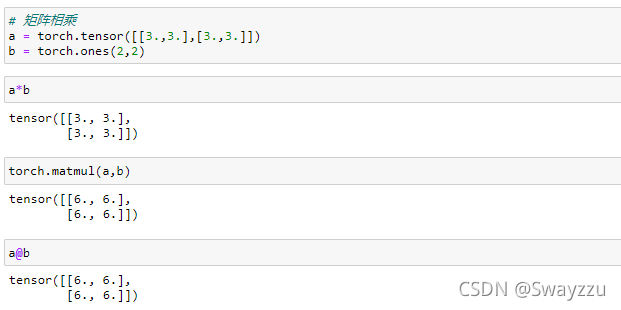
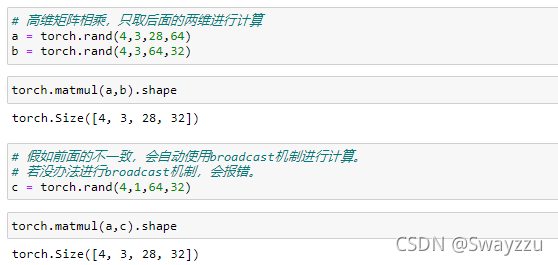
如果是高维矩阵相乘,计算的其实就是最后的两个维度的矩阵乘法。
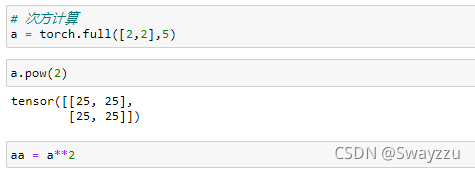
3.次方计算
和numpy中一致,可以使用**来计算任意次方。此外.pow()也可以计算。
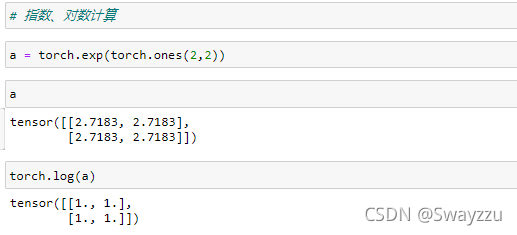
指数和对数计算也基本一致,log默认是以e为底的。
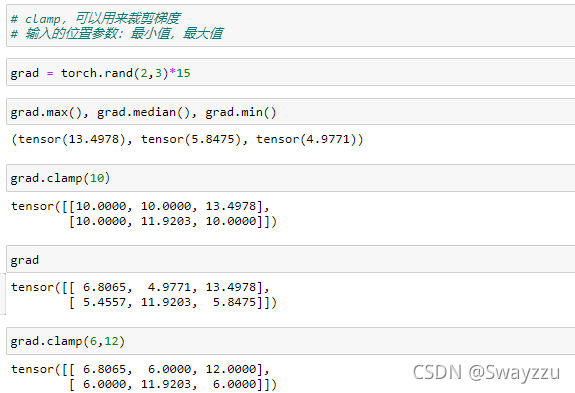
4. clamp
通常用于当出现梯度过大等情况时,对梯度进行裁剪。通过输入最大最小值,目标中超出最大值的按最大值来;低于最小值的按最小值来。
三、属性统计
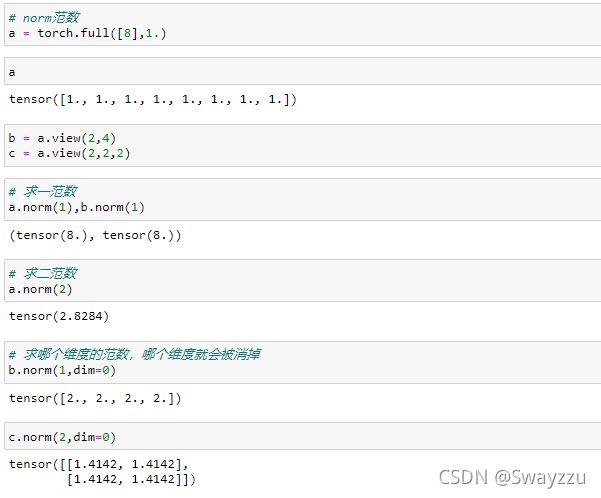
1.求范数
注意一点:求哪个维度的范数,哪个维度就会被消掉。
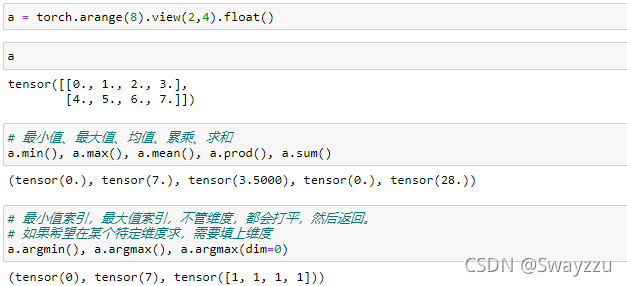
2.求极值、求和、累乘
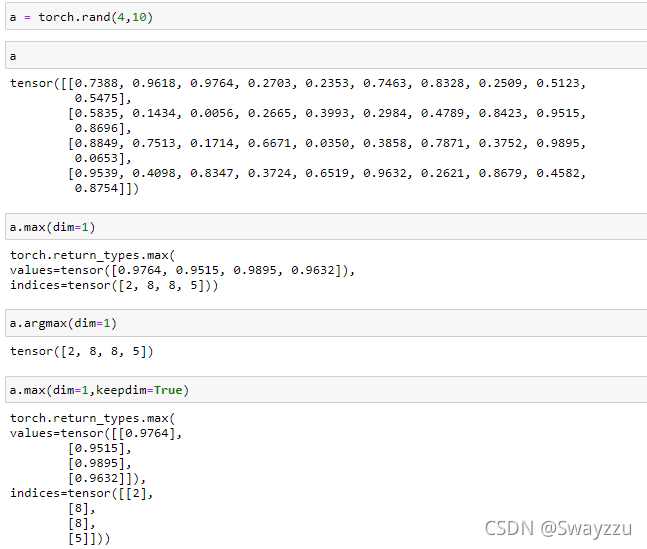
3. dim和keepdim
在很多方法中,都可以对dim进行设置。如果不设置,就是把所有数据展开后,求全局的。
注意这里的dim,a的形状是[4,10],求最大值时,如果设置dim=1,也就是列,个人理解,意思是结果的维度需要是列,那么就是把整行的数值进行计算找最大值,最后返回一个列作为结果。
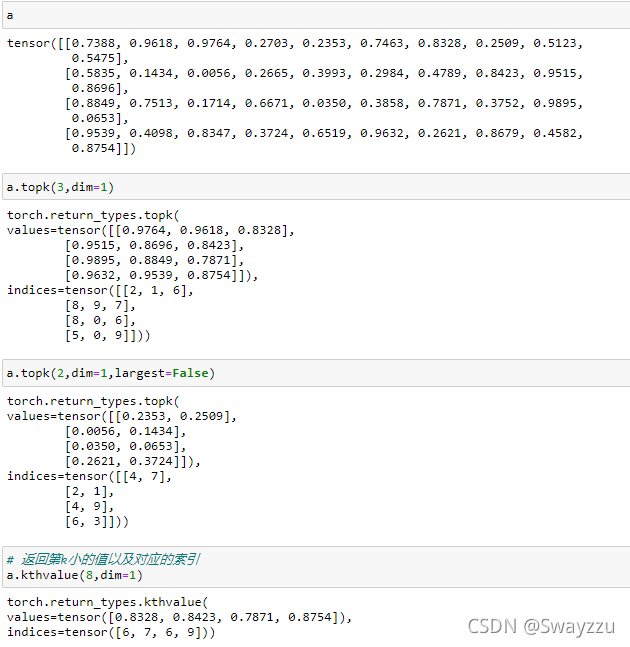
4.topk和kthvalue
topk参数:k(前k个最大值),dim(以dim的维度返回结果)
这个方法默认的是返回的最大值,同时会返回它们的索引。
kthvalue参数:k(第k小的值),dim
5.比较运算
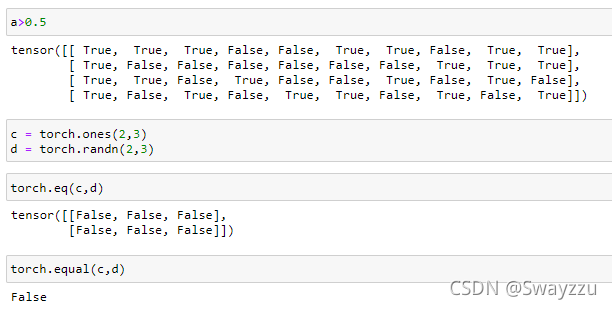
和Numpy中的一致。如果使用torch.eq方法,返回每个对应位置的结果;如果使用torch.equal方法,返回的是整体对比的结果。
6.高阶操作
①where
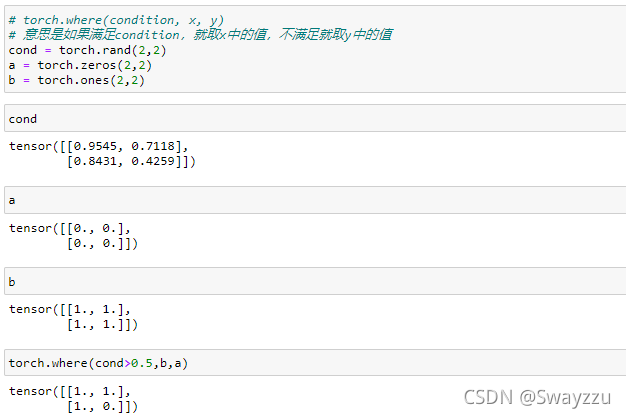
②gather
索引行数小于等于表的行数。也就是说,既然要用索引来去找表中的内容,就不能超过表的索引长度。索引在传入gather方法中的时候,必须要转换成Long的类型。
举例如下:
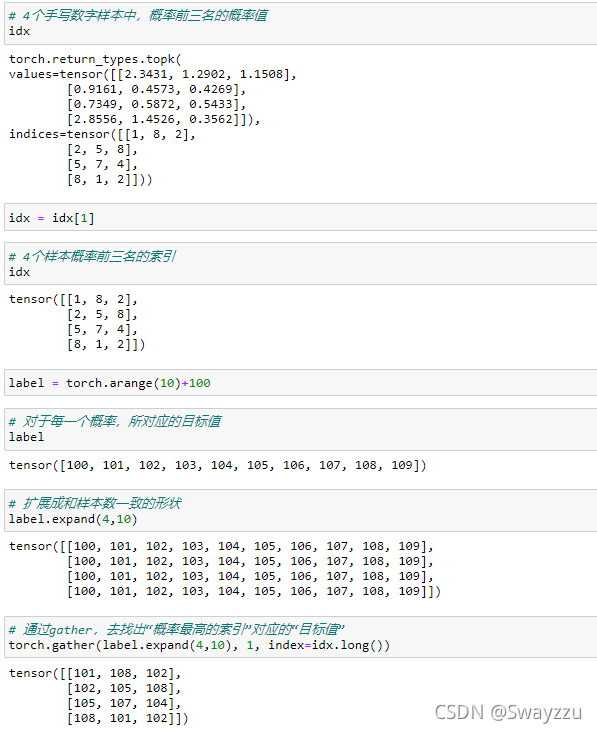
返回值的形状一定是索引的形状,因为就是按照索引去取的值。返回值的内容就来自于输入的input,根据索引获得的对应的值。
以上就是人工智能学习Pytorch进阶操作教程的详细内容,更多关于PyTorch进阶的资料请关注我们其它相关文章!
相关推荐
-

人工智能学习pyTorch的ResNet残差模块示例详解
目录 1.定义ResNet残差模块 ①各层的定义 ②前向传播 2.ResNet18的实现 ①各层的定义 ②前向传播 3.测试ResNet18 1.定义ResNet残差模块 一个block中,有两个卷积层,之后的输出还要和输入进行相加.因此一个block的前向流程如下: 输入x→卷积层→数据标准化→ReLU→卷积层→数据标准化→数据和x相加→ReLU→输出out 中间加上了数据的标准化(通过nn.BatchNorm2d实现),可以使得效果更好一些. ①各层的定义 ②前向传播 在前向传播中输入x,过
-
人工智能学习Pytorch数据集分割及动量示例详解
目录 1.数据集分割 2.正则化 3.动量和学习率衰减 1.数据集分割 通过datasets可以直接分别获取训练集和测试集. 通常我们会将训练集进行分割,通过torch.utils.data.random_split方法. 所有的数据都需要通过torch.util.data.DataLoader进行加载,才可以得到可以使用的数据集. 具体代码如下: 2. 2.正则化 PyTorch中的正则化和机器学习中的一样,不过设置方式不一样. 直接在优化器中,设置weight_decay即可.优化器中,默认
-
人工智能学习Pytorch梯度下降优化示例详解
目录 一.激活函数 1.Sigmoid函数 2.Tanh函数 3.ReLU函数 二.损失函数及求导 1.autograd.grad 2.loss.backward() 3.softmax及其求导 三.链式法则 1.单层感知机梯度 2. 多输出感知机梯度 3. 中间有隐藏层的求导 4.多层感知机的反向传播 四.优化举例 一.激活函数 1.Sigmoid函数 函数图像以及表达式如下: 通过该函数,可以将输入的负无穷到正无穷的输入压缩到0-1之间.在x=0的时候,输出0.5 通过PyTorch实现方式
-
使用 pytorch 创建神经网络拟合sin函数的实现
我们知道深度神经网络的本质是输入端数据和输出端数据的一种高维非线性拟合,如何更好的理解它,下面尝试拟合一个正弦函数,本文可以通过简单设置节点数,实现任意隐藏层数的拟合. 基于pytorch的深度神经网络实战,无论任务多么复杂,都可以将其拆分成必要的几个模块来进行理解. 1)构建数据集,包括输入,对应的标签y 2) 构建神经网络模型,一般基于nn.Module继承一个net类,必须的是__init__函数和forward函数.__init__构造函数包括创建该类是必须的参数,比如输入节点数,隐藏层
-
人工智能学习pyTorch自建数据集及可视化结果实现过程
目录 一.自定义数据集 1.文件夹映射 2.图片对应标签 3.训练及测试数据分割 4.数据处理 二.ResNet处理 三.训练及可视化 1.数据集导入 2.测试函数 3.训练过程及可视化 一.自定义数据集 现有数据如下: 5个文件夹,每个文件夹是神奇宝贝的一种. 每个图片形状.大小.格式不一. 我们训练CNN的时候需要的是tensor类型的数据,因此需要将所有的图片进行下列转换: 1.对文件夹编号,进行映射,比如妙蛙种子文件夹编号0,皮卡丘编号1等. 2.对文件夹中所有图片,进行编号的对应,这个
-
pytorch制作自己的LMDB数据操作示例
本文实例讲述了pytorch制作自己的LMDB数据操作.分享给大家供大家参考,具体如下: 前言 记录下pytorch里如何使用lmdb的code,自用 制作部分的Code code就是ASTER里数据制作部分的代码改了点,aster_train.txt里面就算图片的完整路径每行一个,图片同目录下有同名的txt,里面记着jpg的标签 import os import lmdb # install lmdb by "pip install lmdb" import cv2 import n
-
人工智能学习PyTorch实现CNN卷积层及nn.Module类示例分析
目录 1.CNN卷积层 2. 池化层 3.数据批量标准化 4.nn.Module类 ①各类函数 ②容器功能 ③参数管理 ④调用GPU ⑤存储和加载 ⑥训练.测试状态切换 ⑦ 创建自己的层 5.数据增强 1.CNN卷积层 通过nn.Conv2d可以设置卷积层,当然也有1d和3d. 卷积层设置完毕,将设置好的输入数据,传给layer(),即可完成一次前向运算.也可以传给layer.forward,但不推荐. 2. 池化层 池化层的核大小一般是2*2,有2种方式: maxpooling:选择数据中最大
-
人工智能学习Pytorch进阶操作教程
目录 一.合并与分割 1.cat拼接 2.stack堆叠 3.拆分 ①Split按长度拆分 ②Chunk按数量拆分 二.基本运算 1.加减乘除 2.矩阵相乘 3.次方计算 4. clamp 三.属性统计 1.求范数 2.求极值.求和.累乘 3. dim和keepdim 4.topk和kthvalue 5.比较运算 6.高阶操作 ①where ②gather 一.合并与分割 1.cat拼接 直接按照指定的dim维度进行合并,要求除了所需要合并的维度之外,其他的维度需要是一样的 2.stack堆叠
-
人工智能学习Pytorch教程Tensor基本操作示例详解
目录 一.tensor的创建 1.使用tensor 2.使用Tensor 3.随机初始化 4.其他数据生成 ①torch.full ②torch.arange ③linspace和logspace ④ones, zeros, eye ⑤torch.randperm 二.tensor的索引与切片 1.索引与切片使用方法 ①index_select ②... ③mask 三.tensor维度的变换 1.维度变换 ①torch.view ②squeeze/unsqueeze ③expand,repea
-
人工智能学习PyTorch教程之层和块
对于多层感知机而言,整个模型做的事情就是接收输入生成输出.但是并不是所有的多层神经网络都一样,所以为了实现复杂的神经网络就需要神经网络块,块可以描述单个层.由多个层组成的组件或整个模型本身.使用块进行抽象的一个好处是可以将一些块组合成更大的组件. 从编程的角度来看,块由类(class)表示.它的任何子类都必须定义一个将其输入转换为输出的正向传播函数,并且必须存储任何必需的参数.注意,有些块不需要任何参数.最后,为了计算梯度,块必须具有反向传播函数.幸运的是,在定义我们自己的块时,由于autogr
-
Python人工智能学习PyTorch实现WGAN示例详解
目录 1.GAN简述 2.生成器模块 3.判别器模块 4.数据生成模块 5.判别器训练 6.生成器训练 7.结果可视化 1.GAN简述 在GAN中,有两个模型,一个是生成模型,用于生成样本,一个是判别模型,用于判断样本是真还是假.但由于在GAN中,使用的JS散度去计算损失值,很容易导致梯度弥散的情况,从而无法进行梯度下降更新参数,于是在WGAN中,引入了Wasserstein Distance,使得训练变得稳定.本文中我们以服从高斯分布的数据作为样本. 2.生成器模块 这里从2维数据,最终生成2
-
人工智能学习Pytorch张量数据类型示例详解
目录 1.python 和 pytorch的数据类型区别 2.张量 ①一维张量 ②二维张量 ③3维张量 ④4维张量 1.python 和 pytorch的数据类型区别 在PyTorch中无法展示字符串,因此表达字符串,需要将其转换成编码的类型,比如one_hot,word2vec等. 2.张量 在python中,会有标量,向量,矩阵等的区分.但在PyTorch中,这些统称为张量tensor,只是维度不同而已. 标量就是0维张量,只有一个数字,没有维度. 向量就是1维张量,是有顺序的数字,但没有"