快速解释如何使用pandas的inplace参数的使用
介绍
在操作数据帧时,初学者有时甚至是更高级的数据科学家会对如何在pandas中使用inplace参数感到困惑。
更有趣的是,我看到的解释这个概念的文章或教程并不多。它似乎被假定为知识或自我解释的概念。不幸的是,这对每个人来说都不是那么简单,因此本文试图解释什么是inplace参数以及如何正确使用它。
让我们来看看一些使用inplace的函数的例子:
- fillna()
- dropna()
- sort_values()
- reset_index()
- sort_index()
- rename()
我已经创建了这个列表,可能还有更多的函数使用inplace作为参数。我没有记住所有这些函数,但是作为参数的几乎所有pandas DataFrame函数都将以类似的方式运行。这意味着在处理它们时,您将能够应用本文将介绍的相同逻辑。
创建一个示例DataFrame
为了说明inplace的用法,我们将创建一个示例DataFrame。
import pandas as pd
import numpy as np
client_dictionary = {'name': ['Michael', 'Ana', 'Sean', 'Carl', 'Bob'],
'second name': [None, 'Angel', 'Ben', 'Frank', 'Daniel'],
'birth place': ['New York', 'New York', 'Los Angeles', 'New York', 'New York'],
'age': [10, 35, 56, None, 28],
'number of children': [0, None, 2, 1, 1]}
df = pd.DataFrame(client_dictionary)
df.head()

我们创建了一个数据框架,该数据框架有5行,列如下: name, second name, birthplace,age,number of children。注意,age、second name和children列中有一些缺失值(nan)。
现在我们将演示dropna()函数如何使用inplace参数工作。因为我们想要检查两个不同的变体,所以我们将创建原始数据框架的两个副本。
df_1 = df.copy() df_2 = df.copy()
下面的代码将删除所有缺少值的行。
df_1.dropna(inplace=True)
如果您在Jupyter notebook中运行此操作,您将看到单元格没有输出。这是因为inplace=True函数不返回任何内容。它用所需的操作修改现有的数据帧,并在原始数据帧上“就地”(inplace)执行。
如果在数据帧上运行head()函数,应该会看到有两行被删除。
df_1.dropna(inplace=True)
现在我们用inplace = False运行相同的代码。注意,这次我们将使用df_2版本的df
df_2.dropna(inplace=False)
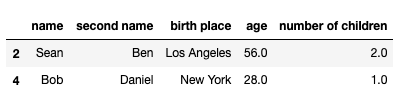
如果您在Jupyter notebook中运行此代码,您将看到有一个输出(上面的屏幕截图)。inplace = False函数将返回包含删除行的数据。
记住,当inplace被设置为True时,不会返回任何东西,但是原始数据被修改了。
那么这一次原始数据会发生什么呢?让我们调用head()函数进行检查。
df_2.head()
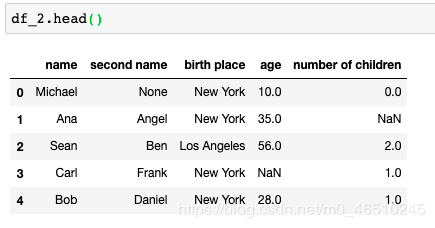
原始数据不变!那么发生了什么?
当您使用inplace=True时,将创建并更改新对象,而不是原始数据。如果您希望更新原始数据以反映已删除的行,则必须将结果重新分配到原始数据中,如下面的代码所示。
df_2 = df_2.dropna(inplace=False)
这正是我们在使用inplace=True时所做的。是的,最后一行代码等价于下面一行:
df_2.dropna(inplace=True)
后者更优雅,并且不创建中间对象,然后将其重新分配给原始变量。它直接改变原始数据框架,因此,如果需要改变原始数据,那么inplace=True是首选。
那么,为什么会有在使用inplace=True产生错误呢?我不太确定,可能是因为有些人还不知道如何正确使用这个参数。让我们看看一些常见的错误。
常见错误
使用inplace = True处理一个片段
如果我们只是想去掉第二个name和age列中的NaN,而保留number of children列不变,我们该怎么办?
我见过有人这样做:
df[['second name', 'age']].dropna(inplace=True)
这会抛出以下警告。

这个警告之所以出现是因为Pandas设计师很好,他们实际上是在警告你不要做你可能不想做的事情。该代码正在更改只有两列的dataframe,而不是原始数据框架。这样做的原因是,您选择了dataframe的一个片段,并将dropna()应用到这个片段,而不是原始dataframe。
为了纠正它,可以这样使用
df.dropna(inplace=True, subset=['second name', 'age']) df.head()

这将导致从dataframe中删除第二个name和age列中值为空的行。
将变量值赋给inplace= True的结果
df = df.dropna(inplace=True)
这又是你永远不应该做的事情!你只需要将None重新赋值给df。记住,当你使用inplace=True时,什么也不会返回。因此,这段代码的结果是将把None分配给df。
总结
我希望本文为您揭开inplace参数的神秘面纱,您将能够在您的代码中正确地使用它。
到此这篇关于快速解释如何使用pandas的inplace参数的使用的文章就介绍到这了,更多相关pandas inplace参数内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
对python pandas中 inplace 参数的理解
pandas 中 inplace 参数在很多函数中都会有,它的作用是:是否在原对象基础上进行修改 inplace = True:不创建新的对象,直接对原始对象进行修改: inplace = False:对数据进行修改,创建并返回新的对象承载其修改结果. 默认是False,即创建新的对象进行修改,原对象不变,和深复制和浅复制有些类似. 例: inplace=True情况: import pandas as pd import numpy as np df=pd.DataFrame(np.rand
-
快速解释如何使用pandas的inplace参数的使用
介绍 在操作数据帧时,初学者有时甚至是更高级的数据科学家会对如何在pandas中使用inplace参数感到困惑. 更有趣的是,我看到的解释这个概念的文章或教程并不多.它似乎被假定为知识或自我解释的概念.不幸的是,这对每个人来说都不是那么简单,因此本文试图解释什么是inplace参数以及如何正确使用它. 让我们来看看一些使用inplace的函数的例子: fillna() dropna() sort_values() reset_index() sort_index() rename() 我已经创建
-
Python drop方法删除列之inplace参数实例
drop方法有一个可选参数inplace,表明可对原数组作出修改并返回一个新数组.不管参数默认为False还是设置为True,原数组的内存值是不会改变的,区别在于原数组的内容是否直接被修改.默认为False,表明原数组内容并不改变,如果我们需要得到改变后的内容,需要将新结果赋给一个新的数组,即data = data.drop(['test','test2'],1). 如果将inplace值设定为True,则原数组内容直接被改变. 测试程序如下 #增加两列空值 import numpy as np
-

python Pandas库read_excel()参数实例详解
目录 1.read_excel函数原型 2.参数使用举例 2.1. io和sheet_name参数 2.2. header参数 2.3. skipfooter参数 2.5. parse_dates参数 2.6. converters参数 2.7. na_values参数 2.8. usecols参数 总结 Pandas read_excel()参数使用详解 1.read_excel函数原型 def read_excel(io, sheet_name=0, header=0, names=None
-
详解Lombok快速上手(安装、使用与注解参数)
Lombok插件安装与使用说明 在实习中发现项目中IDE一直报检查错误,原来是使用了Lombok注解的黑科技,这里整理了一些日常编码中能遇到的所有关于它的使用详解,其实lombok项目的产生就是为了省去我们手动创建getter和setter方法等等一些基本组件代码的麻烦,它能够在我们编译源码的时候自动帮我们生成getter和setter方法.即它最终能够达到的效果是:在源码中没有getter和setter等组件方法,但是在编译生成的字节码文件中有getter和setter等组件方法. 常见参数
-
pandas快速处理Excel,替换Nan,转字典的操作
pandas读取Excel import pandas as pd # 参数1:文件路径,参数2:sheet名 pf = pd.read_excel(path, sheet_name='sheet1') 删除指定列 # 通过列名删除指定列 pf.drop(['序号', '替代', '签名'], axis=1, inplace=True) 替换列名 # 旧列名 新列名对照 columns_map = { '列名1': 'newname_1', '列名2': 'newname_2', '列名3':
-
VSCode下.json文件的编写之(1) linux/g++ (2).json中参数与预定义变量的意义解释
0 引言 转入linux/VSCode编程之后,迫切了解到有必有较为系统地学习一下VSCode中相关配置文件的写法.下面将分为 linux/g++编译指令..json文件关键词/替换变量的意义.编译链接过程原理分析几个部分进行介绍,并以opencv为例,将上述知识综合运用. 1 linux/g++编译指令介绍 参照BattleScars的博客,摘取其中对本文有用的部分进行运用,博客链接如下,质量非常之高,表示感谢!!! https://www.jb51.net/article/183540.ht
-
关于@Scheduled参数及cron表达式解释
目录 @Scheduled参数及cron表达式解释 @Scheduled支持以下8个参数 cron表达式是一个字符串,以空格分开共6个域 通配符说明 常用表达式示例 @Scheduled 定时任务总结 @Scheduled @Scheduled 参数说明 注意事项 @Scheduled参数及cron表达式解释 @Scheduled支持以下8个参数 1.cron:表达式,指定任务在特定时间执行: 2.fixedDelay:表示上一次任务执行完成后多久再次执行,参数类型为long,单位ms: 3.f
-
Python机器学习三大件之二pandas
一.Pandas 2008年WesMcKinney开发出的库 专门用于数据挖掘的开源python库 以Numpy为基础,借力Numpy模块在计算方面性能高的优势 基于matplotlib,能够简便的画图 独特的数据结构 二.数据结构 Pandas中一共有三种数据结构,分别为:Series.DataFrame和MultiIndex. 三.Series Series是一个类似于一维数组的数据结构,它能够保存任何类型的数据,比如整数.字符串.浮点数等,主要由一组数据和与之相关的索引两部分构成. Ser
-
使用Pandas对数据进行筛选和排序的实现
筛选和排序是Excel中使用频率最多的功能,通过这个功能可以很方便的对数据表中的数据使用指定的条件进行筛选和计算,以获得需要的结果.在Pandas中通过.sort和.loc函数也可以实现这两 个功能..sort函数可以实现对数据表的排序操作,.loc函数可以实现对数据表的筛选操作.本篇文章将介绍如果通过Pandas的这两个函数完成Excel中的筛选和排序操作. 首选导入需要使用的Pandas库和numpy库,读取并创建数据表,将数据表命名为lc. import pandas as pd impo