Python爬虫爬取新闻资讯案例详解
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
一个简单的Python资讯采集案例,列表页到详情页,到数据保存,保存为txt文档,网站网页结构算是比较规整,简单清晰明了,资讯新闻内容的采集和保存!
应用到的库
requests,time,re,UserAgent,etree
import requests,time,re
from fake_useragent import UserAgent
from lxml import etree
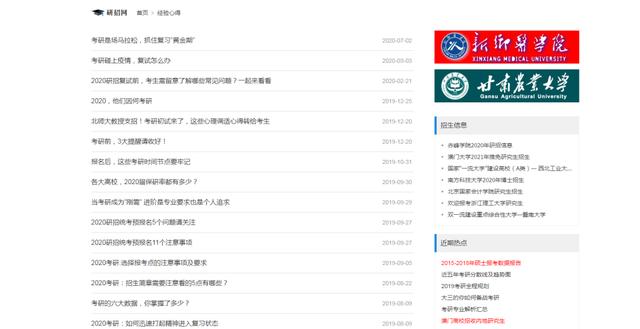
列表页面

列表页,链接xpath解析
href_list=req.xpath('//ul[@class="news-list"]/li/a/@href')
详情页

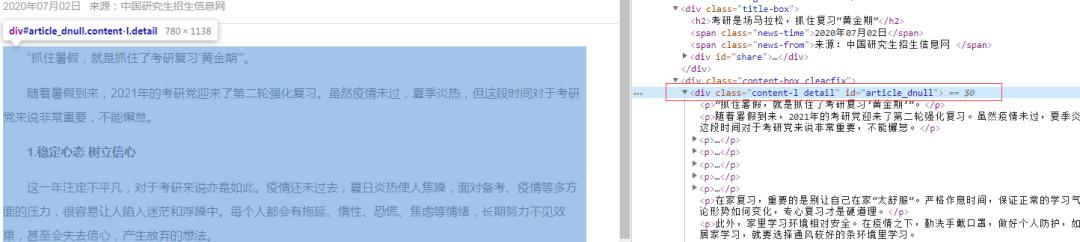
内容xpath解析
h2=req.xpath('//div[@class="title-box"]/h2/text()')[0]
author=req.xpath('//div[@class="title-box"]/span[@class="news-from"]/text()')[0]
details=req.xpath('//div[@class="content-l detail"]/p/text()')
内容格式化处理
detail='\n'.join(details)
标题格式化处理,替换非法字符
pattern = r"[\/\\\:\*\?\"\<\>\|]"
new_title = re.sub(pattern, "_", title) # 替换为下划线
保存数据,保存为txt文本
def save(self,h2, author, detail):
with open(f'{h2}.txt','w',encoding='utf-8') as f:
f.write('%s%s%s%s%s'%(h2,'\n',detail,'\n',author))print(f"保存{h2}.txt文本成功!")
遍历数据采集,yield处理
def get_tasks(self):
data_list = self.parse_home_list(self.url)
for item in data_list:
yield item
程序运行效果

程序采集效果
附源码参考:
# -*- coding: UTF-8 -*-
import requests,time,re
from fake_useragent import UserAgent
from lxml import etree
class RandomHeaders(object):
ua=UserAgent()
@property
def random_headers(self):
return {
'User-Agent': self.ua.random,
}
class Spider(RandomHeaders):
def __init__(self,url):
self.url=url
def parse_home_list(self,url):
response=requests.get(url,headers=self.random_headers).content.decode('utf-8')
req=etree.HTML(response)
href_list=req.xpath('//ul[@class="news-list"]/li/a/@href')
print(href_list)
for href in href_list:
item = self.parse_detail(f'https://yz.chsi.com.cn{href}')
yield item
def parse_detail(self,url):
print(f">>正在爬取{url}")
try:
response = requests.get(url, headers=self.random_headers).content.decode('utf-8')
time.sleep(2)
except Exception as e:
print(e.args)
self.parse_detail(url)
else:
req = etree.HTML(response)
try:
h2=req.xpath('//div[@class="title-box"]/h2/text()')[0]
h2=self.validate_title(h2)
author=req.xpath('//div[@class="title-box"]/span[@class="news-from"]/text()')[0]
details=req.xpath('//div[@class="content-l detail"]/p/text()')
detail='\n'.join(details)
print(h2, author, detail)
self.save(h2, author, detail)
return h2, author, detail
except IndexError:
print(">>>采集出错需延时,5s后重试..")
time.sleep(5)
self.parse_detail(url)
@staticmethod
def validate_title(title):
pattern = r"[\/\\\:\*\?\"\<\>\|]"
new_title = re.sub(pattern, "_", title) # 替换为下划线
return new_title
def save(self,h2, author, detail):
with open(f'{h2}.txt','w',encoding='utf-8') as f:
f.write('%s%s%s%s%s'%(h2,'\n',detail,'\n',author))
print(f"保存{h2}.txt文本成功!")
def get_tasks(self):
data_list = self.parse_home_list(self.url)
for item in data_list:
yield item
if __name__=="__main__":
url="https://yz.chsi.com.cn/kyzx/jyxd/"
spider=Spider(url)
for data in spider.get_tasks():
print(data)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python 通过requests实现腾讯新闻抓取爬虫的方法
最近也是学习了一些爬虫方面的知识.以我自己的理解,通常我们用浏览器查看网页时,是通过浏览器向服务器发送请求,然后服务器响应以后返回一些代码数据,再经过浏览器解析后呈现出来.而爬虫则是通过程序向服务器发送请求,并且将服务器返回的信息,通过一些处理后,就能得到我们想要的数据了. 以下是前段时间我用python写的一个爬取TX新闻标题及其网址的一个简单爬虫: 首先需要用到python中requests(方便全面的http请求库)和 BeautifulSoup(html解析库). 通过pip来安装这两个
-

Python正则抓取网易新闻的方法示例
本文实例讲述了Python正则抓取网易新闻的方法.分享给大家供大家参考,具体如下: 自己写了些关于抓取网易新闻的爬虫,发现其网页源代码与网页的评论根本就对不上,所以,采用了抓包工具得到了其评论的隐藏地址(每个浏览器都有自己的抓包工具,都可以用来分析网站) 如果仔细观察的话就会发现,有一个特殊的,那么这个就是自己想要的了 然后打开链接就可以找到相关的评论内容了.(下图为第一页内容) 接下来就是代码了(也照着大神的改改写写了). #coding=utf-8 import urllib2 import
-
python基础教程项目四之新闻聚合
<python基础教程>书中的第四个练习,新闻聚合.现在很少见的一类应用,至少我从来没有用过,又叫做Usenet.这个程序的主要功能是用来从指定的来源(这里是Usenet新闻组)收集信息,然后讲这些信息保存到指定的目的文件中(这里使用了两种形式:纯文本和html文件).这个程序的用处有些类似于现在的博客订阅工具或者叫RSS订阅器. 先上代码,然后再来逐一分析: from nntplib import NNTP from time import strftime,time,localtime f
-
Python爬取十篇新闻统计TF-IDF
统计十篇新闻TF-IDF 统计TF-IDF词频,每篇文章的 top10 的高频词存储为 json 文件 TF-IDF TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与文本挖掘的常用加权技术.TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度.字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降.TF-IDF加权的各种形式常被搜索引擎应用,作为文
-
python爬虫获取新浪新闻教学
一提到python,大家经常会提到爬虫,爬虫近来兴起的原因我觉得主要还是因为大数据的原因,大数据导致了我们的数据不在只存在于自己的服务器,而python语言的简便也成了爬虫工具的首要语言,我们这篇文章来讲下爬虫,爬取新浪新闻 1. 大家知道,爬虫实际上就是模拟浏览器请求,然后把请求到的数据,经过我们的分析,提取出我们想要的内容,这也就是爬虫的实现 大家知道,爬虫实际上就是模拟浏览器请求,然后把请求到的数据,经过我们的分析,提取出我们想要的内容,这也就是爬虫的实现 2.首先,我们要写爬虫,可以借鉴
-
Python采集腾讯新闻实例
目标是把腾讯新闻主页上所有新闻爬取下来,获得每一篇新闻的名称.时间.来源以及正文. 接下来分解目标,一步一步地做. 步骤1:将主页上所有链接爬取出来,写到文件里. python在获取html方面十分方便,寥寥数行代码就可以实现我们需要的功能. 复制代码 代码如下: def getHtml(url): page = urllib.urlopen(url) html = page.read() page.close() return html 我们都知道htm
-
以911新闻为例演示Python实现数据可视化的教程
本文介绍一个将911袭击及后续影响相关新闻文章的主题可视化的项目.我将介绍我的出发点,实现的技术细节和我对一些结果的思考. 简介 近代美国历史上再没有比911袭击影响更深远的事件了,它的影响在未来还会持续.从事件发生到现在,成千上万主题各异的文章付梓.我们怎样能利用数据科学的工具来探索这些主题,并且追踪它们随着时间的变化呢? 灵感 首先提出这个问题的是一家叫做Local Projects的公司,有人委任它们为纽约的国家911博物馆设置一个展览.他们的展览,Timescape,将事件的主题和文章可
-
python使用nntp读取新闻组内容的方法
本文实例讲述了python使用nntp读取新闻组内容的方法.分享给大家供大家参考.具体实现方法如下: from nntplib import * s = NNTP('web.aioe.org') (resp, count, first, last, name) = s.group('comp.lang.python') (resp, subs) = s.xhdr('subject', (str(first)+'-'+str(last))) for subject in subs[-10:]: p
-
Python爬虫爬取新闻资讯案例详解
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 一个简单的Python资讯采集案例,列表页到详情页,到数据保存,保存为txt文档,网站网页结构算是比较规整,简单清晰明了,资讯新闻内容的采集和保存! 应用到的库 requests,time,re,UserAgent,etree import requests,time,re from fake_useragent import UserAgent from lxml im
-
python爬虫爬取微博评论案例详解
前几天,杨超越编程大赛火了,大家都在报名参加,而我也是其中的一员. 在我们的项目中,我负责的是数据爬取这块,我主要是把对于杨超越 的每一条评论的相关信息. 数据格式:{"name":评论人姓名,"comment_time":评论时间,"comment_info":评论内容,"comment_url":评论人的主页} 以上就是我们需要的信息. 爬虫前的分析: 以上是杨超越的微博主页,这是我们首先需要获取到的内容. 因为我们需要等
-
Python scrapy爬取小说代码案例详解
scrapy是目前python使用的最广泛的爬虫框架 架构图如下 解释: Scrapy Engine(引擎): 负责Spider.ItemPipeline.Downloader.Scheduler中间的通讯,信号.数据传递等. Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎. Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Respon
-
python爬虫爬取监控教务系统的思路详解
这几天考了大大小小几门课,教务系统又没有成绩通知功能,为了急切想知道自己挂了多少门,于是我写下这个脚本. 设计思路: 设计思路很简单,首先对已有的成绩进行处理,变为list集合,然后定时爬取教务系统查成绩的页面,对爬取的成绩也处理成list集合,如果newList的长度增加了,就找出增加的部分,并通过邮件通知我. 脚本运行效果: 服务器: 发送邮件通知: 代码如下: import datetime import time from email.header import Header impor
-
Python爬虫之爬取淘女郎照片示例详解
本篇目标 抓取淘宝MM的姓名,头像,年龄 抓取每一个MM的资料简介以及写真图片 把每一个MM的写真图片按照文件夹保存到本地 熟悉文件保存的过程 1.URL的格式 在这里我们用到的URL是 http://mm.taobao.com/json/request_top_list.htm?page=1,问号前面是基地址,后面的参数page是代表第几页,可以随意更换地址.点击开之后,会发现有一些淘宝MM的简介,并附有超链接链接到个人详情页面. 我们需要抓取本页面的头像地址,MM姓名,MM年龄,MM居住地,
-
详解Python爬虫爬取博客园问题列表所有的问题
一.准备工作 首先,本文使用的技术为 python+requests+bs4,没有了解过可以先去了解一下. 我们的需求是将博客园问题列表中的所有问题的题目爬取下来. 二.分析: 首先博客园问题列表页面右键点击检查 通过Element查找问题所对应的属性或标签 可以发现在div class ="one_entity"中存在页面中分别对应每一个问题 接着div class ="news_item"中h2标签下是我们想要拿到的数据 三.代码实现 首先导入requests和
-
利用Python爬虫爬取金融期货数据的案例分析
目录 任务简介 解决步骤 代码实现 总结 大家好 我是政胤今天教大家爬取金融期货数据 任务简介 首先,客户原需求是获取https://hq.smm.cn/copper网站上的价格数据(注:获取的是网站上的公开数据),如下图所示: 如果以该网站为目标,则需要解决的问题是“登录”用户,再将价格解析为表格进行输出即可.但是,实际上客户核心目标是获取“沪铜CU2206”的历史价格,虽然该网站也有提供数据,但是需要“会员”才可以访问,而会员需要氪金...... 数据的价值!!! 鉴于,客户需求仅仅是“沪铜
-
python爬虫爬取某站上海租房图片
对于一个net开发这爬虫真真的以前没有写过.这段时间开始学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup.python 版本:python3.6 ,IDE :pycharm.其实就几行代码,但希望没有开发基础的人也能一下子看明白,所以大神请绕行. 第三方库首先安装 我是用的pycharm所以另为的脚本安装我这就不介绍了. 如上图打开默认设置选择Project Interprecter,双击pip或者点击加
-
Python爬虫爬取一个网页上的图片地址实例代码
本文实例主要是实现爬取一个网页上的图片地址,具体如下. 读取一个网页的源代码: import urllib.request def getHtml(url): html=urllib.request.urlopen(url).read() return html print(getHtml(http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%E5%A3%81%E7%BA%B8&ct=201326592&am
-
python爬虫爬取快手视频多线程下载功能
环境: python 2.7 + win10 工具:fiddler postman 安卓模拟器 首先,打开fiddler,fiddler作为http/https 抓包神器,这里就不多介绍. 配置允许https 配置允许远程连接 也就是打开http代理 电脑ip: 192.168.1.110 然后 确保手机和电脑是在一个局域网下,可以通信.由于我这边没有安卓手机,就用了安卓模拟器代替,效果一样的. 打开手机浏览器,输入192.168.1.110:8888 也就是设置的代理地址,安装证书之后才能