Python利用PyPDF2库获取PDF文件总页码实例
Python中可以利用PyPDF2库来获取该pdf文件的总页码,可以根据下面的方法一步步进行下去:
1、首先,要安装PyPDF2库,利用以下命令即可:
pip install PyPDF2
2、接着,就是直接编写代码了,其中我新建了一个py文件,名为file_utils.py,代码如下:
from PyPDF2 import PdfFileReader
def get_num_pages(file_path):
"""
获取文件总页码
:param file_path: 文件路径
:return:
"""
reader = PdfFileReader(file_path)
# 不解密可能会报错:PyPDF2.utils.PdfReadError: File has not been decrypted
if reader.isEncrypted:
reader.decrypt('')
page_num = reader.getNumPages()
return page_num
3、这样就可以获得该pdf文件的总页数了,但是需要传递文件路径进去,因为需要读取这个文件。
4、以上内容仅供学习参考,谢谢!
补充知识:使用python合并pdf文件带书签
1、需求:
将几本纸质书进行了扫描,可是扫描的每页生成一个pdf文件。需要怎么才能把这些pdf文件合成一个呢?adoba acrobat工具支持,可是收费。我们平时用的都是adoba reader,只有读pdf的功能没有合并等高级功能。网上的一些免费工具又担心有病毒或绑定程序。
所以考虑看看pyton实现。网上找了下python合并pdf的脚本,发现也没有添加书签的功能的,有添加书签的也不是很灵活。
所有对网上找的一个python程序进行了升级,可以实现合并pdf并每个章节加入书签。
文件准备:
先将扫描的pdf文件,每一章放到一个文件夹中,文件夹名字用章节名命名。这样最终程序就能将章节名作为书签了,而不是默认将每页都生成书签。
2、程序代码
代码运行环境:python3
需要安装PyPDF2包:pip install PyPDF2
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
'''
本脚本用来合并pdf文件,支持带一级子目录的
每章内容分别放在不同的目录下,目录名为章节名
最终生成的pdf,按章节名生成书签
'''
import os, sys, codecs
from PyPDF2 import PdfFileReader, PdfFileWriter, PdfFileMerger
import glob
def getFileName(filepath):
'''
获取当前目录下的所有pdf文件
'''
file_list = glob.glob(filepath+"/*.pdf")
# 默认安装字典序排序,也可以安装自定义的方式排序
# file_list.sort()
return file_list
def get_dirs(filepath='', dirlist_out=[], dirpathlist_out=[]):
# 遍历filepath下的所有目录
for dir in os.listdir(filepath):
dirpathlist_out.append(filepath + '\\' + dir)
return dirpathlist_out
def merge_childdir_files(path):
'''
每个子目录下合并生成一个pdf
'''
dirpathlist = get_dirs(path)
if len(dirpathlist) == 0:
print("当前目录不存在子目录")
sys.exit()
for dir in dirpathlist:
mergefiles(dir, dir)
def mergefiles(path, output_filename, import_bookmarks=False):
# 遍历目录下的所有pdf将其合并输出到一个pdf文件中,输出的pdf文件默认带书签,书签名为之前的文件名
# 默认情况下原始文件的书签不会导入,使用import_bookmarks=True可以将原文件所带的书签也导入到输出的pdf文件中
merger = PdfFileMerger()
filelist = getFileName(path)
if len(filelist) == 0:
print("当前目录及子目录下不存在pdf文件")
sys.exit()
for filename in filelist:
f = codecs.open(filename, 'rb')
file_rd = PdfFileReader(f)
short_filename = os.path.basename(os.path.splitext(filename)[0])
if file_rd.isEncrypted == True:
print('不支持的加密文件:%s'%(filename))
continue
merger.append(file_rd, bookmark=short_filename, import_bookmarks=import_bookmarks)
print('合并文件:%s'%(filename))
f.close()
# out_filename = os.path.join(os.path.abspath(path), output_filename)
merger.write(output_filename + ".pdf")
print('合并后的输出文件:%s'%(output_filename))
merger.close()
if __name__ == "__main__":
# 每个章节一个子目录,先分别合并每个子目录文件为一个pdf,然后再将这些pdf合并为一个大的pdf,这样做目的是想生成每个章节的书签
# 1.指定目录
# 原始pdf所在目录
path = "D:\spdf"
# 输出pdf路径和文件名
output_filename = "D:\spdf\战略规划 公司实现持续成功的方法、工具和实践 罗熙昶 2018-09"
# 2.生成子目录的pdf
# merge_childdir_files(path)
# 3.子目录pdf合并为总的pdf
mergefiles(path, output_filename)
3、程序使用
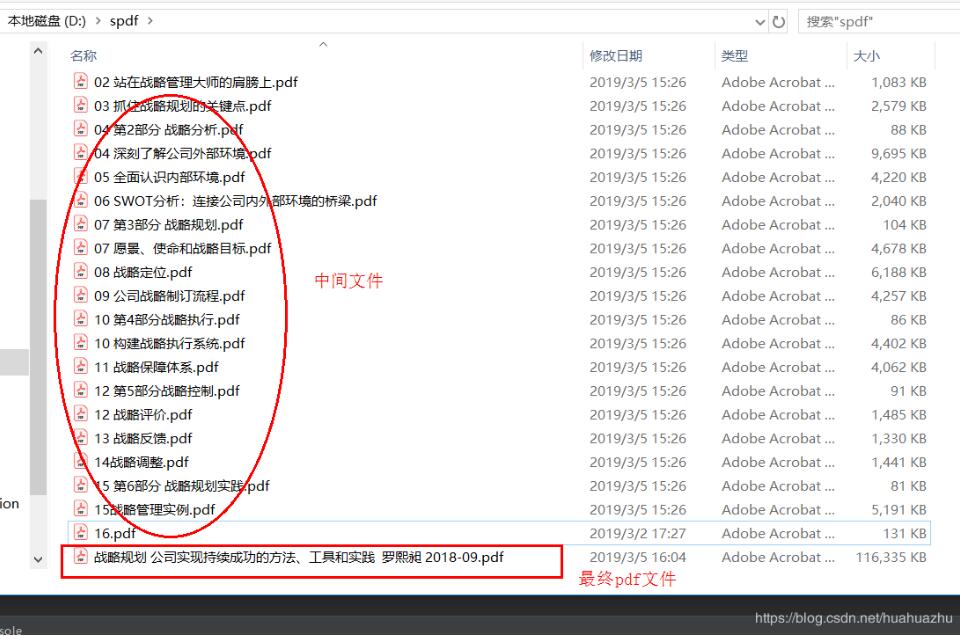
将要生成的pdf文件目录导入到程序指定目录下,例如我程序中的path是“D:\spdf”,然后指定最终输出的文件路径及文件名,我上面的output_filename是"D:\spdf\战略规划 公司实现持续成功的方法、工具和实践 罗熙昶 2018-09"
数据结果如下:
以上这篇Python利用PyPDF2库获取PDF文件总页码实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python统计函数库scipy.stats的用法解析
背景 总结统计工作中几个常用用法在python统计函数库scipy.stats的使用范例. 正态分布 以正态分布的常见需求为例了解scipy.stats的基本使用方法. 1.生成服从指定分布的随机数 norm.rvs通过loc和scale参数可以指定随机变量的偏移和缩放参数,这里对应的是正态分布的期望和标准差.size得到随机数数组的形状参数.(也可以使用np.random.normal(loc=0.0, scale=1.0, size=None)) In [4]: import numpy a
-
Python爬虫 urllib2的使用方法详解
所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地.在Python中有很多库可以用来抓取网页,我们先学习urllib2. urllib2是Python2.x自带的模块(不需要下载,导入即可使用) urllib2官网文档:https://docs.python.org/2/library/urllib2.html urllib2源码 urllib2在python3.x中被改为urllib.request urlopen 我们先来段代码: #-*- coding:utf-8
-

Python PyPDF2模块安装使用解析
这篇文章主要介绍了Python PyPDF2模块安装使用解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 PyPDF2模块主要的功能是分割或合并PDF文件,裁剪或转换PDF文件中的页面. 0.安装PyPDF2的模块 pip install PyPDF2 1.常用的函数 #!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2020/1/15 13:38 # @Author : suk
-
Python利用PyPDF2库获取PDF文件总页码实例
Python中可以利用PyPDF2库来获取该pdf文件的总页码,可以根据下面的方法一步步进行下去: 1.首先,要安装PyPDF2库,利用以下命令即可: pip install PyPDF2 2.接着,就是直接编写代码了,其中我新建了一个py文件,名为file_utils.py,代码如下: from PyPDF2 import PdfFileReader def get_num_pages(file_path): """ 获取文件总页码 :param file_path: 文件
-
Python利用PyPDF2快速拆分PDF文档
目录 安装PyPDF2模块 创建文件,准备PDF文档 万事俱备,准备开拆 文档的拆分思路 python拆分计算公式: 具体怎么拆? 完整拆分程序: 列表拆分法实现拆分PDF 写在最后 "人生苦短,快学Python",因为这句口号,我也加入了学习Python的浩浩大军,但由于Python真的是可以做的事情太多了,一时迷了眼,不知道自己应该去专攻哪个方向. 经过多方向试探,我还是选择了广而不深的web开发,Python的web开发自然离不开大名鼎鼎的Django,有一次突发奇想,下载了Dj
-
Python 利用pydub库操作音频文件的方法
最近使用Python调用百度的REST API实现语音识别,但是百度要求音频文件的压缩方式只能是pcm(不压缩).wav.opus.speex.amr,这里面也就wav还常见一点,但是一般设备录音得到的文件都是mp3,这就要把mp3转换为wav,由于python的效率并不高,很多实现都是使用C++或者Java,不过GitHub上有一个项目pydub(https://github.com/jiaaro/pydub/tree/master/pydub)可以暂时解决问题. 安装pydub 直接执行以下
-
Python如何把多个PDF文件合并代码实例
这篇文章主要介绍了Python如何把多个PDF文件合并,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 代码如下 from PyPDF2 import PdfFileMerger import os files = os.listdir()#列出目录中的所有文件 merger = PdfFileMerger() for file in files: #从所有文件中选出pdf文件合并 if file[-4:] == ".pdf": mer
-
python利用标准库如何获取本地IP示例详解
标准库 Python拥有一个强大的标准库.Python语言的核心只包含数字.字符串.列表.字典.文件等常见类型和函数,而由Python标准库提供了系统管理.网络通信.文本处理.数据库接口.图形系统.XML处理等额外的功能. Python标准库的主要功能有: 1.文本处理,包含文本格式化.正则表达式匹配.文本差异计算与合并.Unicode支持,二进制数据处理等功能 2.文件处理,包含文件操作.创建临时文件.文件压缩与归档.操作配置文件等功能 3.操作系统功能,包含线程与进程支持.IO复用.日期与时
-
Python利用pdfplumber实现读取PDF写入Excel
目录 一.Python操作PDF 13大库对比 二.pdfplumber模块 1.安装 2. 加载PDF 3. pdfplumber.PDF类 4. pdfplumber.Page类 三.实战操作 1. 提取单个PDF全部页数 2. 批量提取多个PDF文件 一.Python操作PDF 13大库对比 PDF(Portable Document Format)是一种便携文档格式,便于跨操作系统传播文档.PDF文档遵循标准格式,因此存在很多可以操作PDF文档的工具,Python自然也不例外. Pyth
-
Python利用reportlab实现制作pdf报告
目录 前言 reportlab是什么 安装和导入库 将画图.画表格.编辑文字抽象为类 pdf插入图片 以文件路径写入pdf 以流文件写入pdf pdf分页 以生成pdf流文件为例 前言 本博客重点内容:reportlab生成流文件格式.reportlab分页和图片流文件写入reportlab等. 我讲一下我这个需求的来源,做的项目是一个地理空间查询和使用的系统,通过在前端调用高德地图api创建了一个查询区域,获取区域内的地理数据(数据库).具体的需求就是,将查询区域和地理数据制作成一个覆盖率分析
-
Python利用pywin32库实现将PPT导出为高清图片
目录 一.安装库 二.代码原理 三.使用效果 四.所有代码 一.安装库 需要安装pywin32库 pip install pywin32 二.代码原理 WPS高清图片导出需要会员,就为了一个这个小需求开一个会员太亏了,因此就使用python对ppt进行高清图片导出. 设置format=19即可: ppt.SaveAs(imgs_path, 19) 三.使用效果 输入一个文件路径 path = 'D:\\自动化\\课件.pptx' 最后的效果: 会在路径下创建一个‘’课件‘’文件夹 里面是所有转换
-
Python利用openpyxl库遍历Sheet的实例
方法一,利用 sheet.iter_rows() 获取 Sheet1 表中的所有行,然后遍历 import openpyxl wb = openpyxl.load_workbook('example.xlsx') sheet = wb.get_sheet_by_name('Sheet1') for row in sheet.iter_rows(): for cell in row: print(cell.coordinate, cell.value) print('--- END OF ROW
-
python利用requests库模拟post请求时json的使用教程
我们都见识过requests库在静态网页的爬取上展现的威力,我们日常见得最多的为get和post请求,他们最大的区别在于安全性上: 1.GET是通过URL方式请求,可以直接看到,明文传输. 2.POST是通过请求header请求,可以开发者工具或者抓包可以看到,同样也是明文的. 3.GET请求会保存在浏览器历史纪录中,还可能会保存在Web的日志中. 两者用法上也有显著差异(援引自知乎): 1.GET用于从服务器端获取数据,包括静态资源(HTML|JS|CSS|Image等等).动态数据展示(列表