浅谈Python中re.match()和re.search()的使用及区别
1.re.match()
re.match()的概念是从头匹配一个符合规则的字符串,从起始位置开始匹配,匹配成功返回一个对象,未匹配成功返回None。
包含的参数如下:
pattern: 正则模型
string : 要匹配的字符串
falgs : 匹配模式
match() 方法一旦匹配成功,就是一个match object对象,而match object对象有以下方法:
group() 返回被 RE 匹配的字符串
start() 返回匹配开始的位置
end() 返回匹配结束的位置
span()返回一个元组包含匹配 (开始,结束) 的位置
案例:
import re
# re.match 返回一个Match Object 对象
# 对象提供了 group() 方法,来获取匹配的结果
result = re.match("hello","hello,world")
if result:
print(result.group())
else:
print("匹配失败!")
输出结果:
hello
2.re.search()
re.search()函数会在字符串内查找模式匹配,只要找到第一个匹配然后返回,如果字符串没有匹配,则返回None。
格式:re.search(pattern, string, flags=0)
要求:匹配出文章阅读的次数
import re ret = re.search(r"\d+", "阅读次数为 9999") print(ret.group())
输出结果:
9999
3.match()和search()的区别:
match()函数只检测RE是不是在string的开始位置匹配,
search()会扫描整个string查找匹配
match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回none
举例说明:
import re
print(re.match('super', 'superstition').span())
(0, 5)
print(re.match('super','insuperable'))
None
print(re.search('super','superstition').span())
(0, 5)
print(re.search('super','insuperable').span())
(2, 7)
补充知识: jupyter notebook_主函数文件如何调用类文件
使用jupyter notebook编写python程序,rw_visual.jpynb是写的主函数,random_walk.jpynb是类(如图)。在主函数中将类实例化后运行会报错,经网络查找解决了问题,缺少Ipynb_importer.py这样一个链接文件。
解决方法:
1、在同一路径下创建名为Ipynb_importer.py的文件:File-->download as-->Python(.py),该文件内容如下:
#!/usr/bin/env python
# coding: utf-8
# In[ ]:
import io, os,sys,types
from IPython import get_ipython
from nbformat import read
from IPython.core.interactiveshell import InteractiveShell
class NotebookFinder(object):
"""Module finder that locates Jupyter Notebooks"""
def __init__(self):
self.loaders = {}
def find_module(self, fullname, path=None):
nb_path = find_notebook(fullname, path)
if not nb_path:
return
key = path
if path:
# lists aren't hashable
key = os.path.sep.join(path)
if key not in self.loaders:
self.loaders[key] = NotebookLoader(path)
return self.loaders[key]
def find_notebook(fullname, path=None):
"""find a notebook, given its fully qualified name and an optional path
This turns "foo.bar" into "foo/bar.ipynb"
and tries turning "Foo_Bar" into "Foo Bar" if Foo_Bar
does not exist.
"""
name = fullname.rsplit('.', 1)[-1]
if not path:
path = ['']
for d in path:
nb_path = os.path.join(d, name + ".ipynb")
if os.path.isfile(nb_path):
return nb_path
# let import Notebook_Name find "Notebook Name.ipynb"
nb_path = nb_path.replace("_", " ")
if os.path.isfile(nb_path):
return nb_path
class NotebookLoader(object):
"""Module Loader for Jupyter Notebooks"""
def __init__(self, path=None):
self.shell = InteractiveShell.instance()
self.path = path
def load_module(self, fullname):
"""import a notebook as a module"""
path = find_notebook(fullname, self.path)
print ("importing Jupyter notebook from %s" % path)
# load the notebook object
with io.open(path, 'r', encoding='utf-8') as f:
nb = read(f, 4)
# create the module and add it to sys.modules
# if name in sys.modules:
# return sys.modules[name]
mod = types.ModuleType(fullname)
mod.__file__ = path
mod.__loader__ = self
mod.__dict__['get_ipython'] = get_ipython
sys.modules[fullname] = mod
# extra work to ensure that magics that would affect the user_ns
# actually affect the notebook module's ns
save_user_ns = self.shell.user_ns
self.shell.user_ns = mod.__dict__
try:
for cell in nb.cells:
if cell.cell_type == 'code':
# transform the input to executable Python
code = self.shell.input_transformer_manager.transform_cell(cell.source)
# run the code in themodule
exec(code, mod.__dict__)
finally:
self.shell.user_ns = save_user_ns
return mod
sys.meta_path.append(NotebookFinder())
2、在主函数中import Ipynb_importer
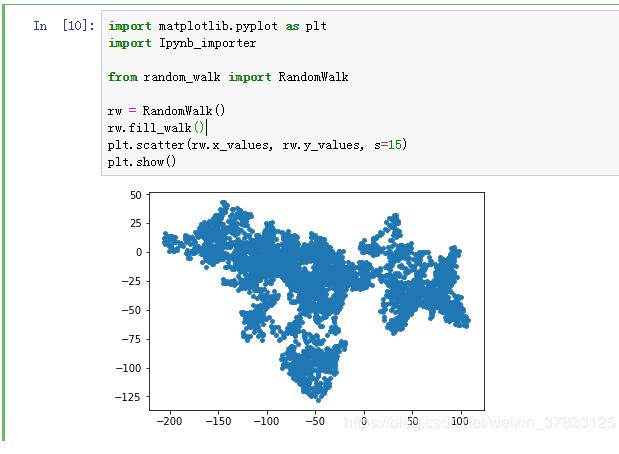
import matplotlib.pyplot as plt import Ipynb_importer from random_walk import RandomWalk rw = RandomWalk() rw.fill_walk() plt.scatter(rw.x_values, rw.y_values, s=15) plt.show()
3、运行主函数,调用成功
ps:random_walk.jpynb文件内容如下:
from random import choice
class RandomWalk():
def __init__(self, num_points=5000):
self.num_points = num_points
self.x_values = [0]
self.y_values = [0]
def fill_walk(self):
while len(self.x_values) < self.num_points:
x_direction = choice([1,-1])
x_distance = choice([0,1,2,3,4])
x_step = x_direction * x_distance
y_direction = choice([1,-1])
y_distance = choice([0,1,2,3,4])
y_step = y_direction * y_distance
if x_step == 0 and y_step == 0:
continue
next_x = self.x_values[-1] + x_step
next_y = self.y_values[-1] + y_step
self.x_values.append(next_x)
self.y_values.append(next_y)
运行结果:
以上这篇浅谈Python中re.match()和re.search()的使用及区别就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
对python 中re.sub,replace(),strip()的区别详解
1.strip(): str.strip([chars]);去除字符串前面和后面的所有设置的字符串,默认为空格 chars -- 移除字符串头尾指定的字符序列. st = " hello " st = st.strip() print(st+"end") 输出: 如果设置了字符序列的话,那么它会删除,字符串前后出现的所有序列中有的字符.但不会清除空格. st = "hello" st = st.strip('h,o,e') print(st) 因
-
python正则-re的用法详解
天在刷题的时候用到了正则,用的过程中就感觉有点不太熟练了,很久没有用正则都有点忘了.所以现在呢,我们就一起来review一下python中正则模块re的用法吧. 今天是review,所以一些基础的概念就不做介绍了,先来看正则中的修饰符以及它的功能: 修饰符 •re.I 使匹配对大小写不敏感 •re.L 做本地化识别匹配 •re.M 多行匹配,影响^和$ •re.S 使.匹配包括换行在内的所有字符 •re.U 根据Unicode字符集解析字符.这个标志影响\w \W \b \B •re.X 该标志
-
Python3中正则模块re.compile、re.match及re.search函数用法详解
本文实例讲述了Python3中正则模块re.compile.re.match及re.search函数用法.分享给大家供大家参考,具体如下: re模块 re.compile.re.match. re.search re 模块官方说明文档 正则匹配的时候,第一个字符是 r,表示 raw string 原生字符,意在声明字符串中间的特殊字符不用转义. 比如表示 '\n',可以写 r'\n',或者不适用原生字符 '\n'. 推荐使用 re.match re.compile() 函数 编译正则表达式模式,
-
浅谈Python中re.match()和re.search()的使用及区别
1.re.match() re.match()的概念是从头匹配一个符合规则的字符串,从起始位置开始匹配,匹配成功返回一个对象,未匹配成功返回None. 包含的参数如下: pattern: 正则模型 string : 要匹配的字符串 falgs : 匹配模式 match() 方法一旦匹配成功,就是一个match object对象,而match object对象有以下方法: group() 返回被 RE 匹配的字符串 start() 返回匹配开始的位置 end() 返回匹配结束的位置 span()返
-
浅谈Python中的正则表达式
Python里的正则表达式 Python里的正则表达式,无需下载外部模块,只需要引入自带模块:re: import re 官方re模块文档: https://docs.python.org/zh-cn/3.9/library/re.html 同时,Python的正则表达式是PCRE标准的,相较于广泛应用在Unix上的POSIX标准,还是有些区别的(主要是简化) 基本方法 观察re源码,其主要的接口方法有: match(-):从字符串的起始位置匹配一个模式,如果无法匹配成功,则match()就返回
-
浅谈python中copy和deepcopy中的区别
在下是个编程爱好者,最近将魔爪伸向了Python编程.....遇到copy和deepcopy感到很困惑,现在针对这两个方法进行区分,一种是浅复制(copy),一种是深度复制(deepcopy). 首先说一下deepcopy,所谓的深度复制,在这里我理解的是完全复制然后变成一个新的对象,复制的对象和被复制的对象没有任何关系,彼此之间无论怎么改变都相互不影响. 然后说一下copy,在这里我分为两类来说,一种是字典数据类型的copy函数,一种是copy包的copy函数. 一.字典数据类型的copy函数
-
浅谈python中列表、字符串、字典的常用操作
列表操作如此下: a = ["haha","xixi","baba"] 增:a.append[gg] a.insert[1,gg] 在下标为1的地方,新增 gg 删:a.remove(haha) 删除列表中从左往右,第一个匹配到的 haha del a.[0] 删除下标为0 对应的值 a.pop(0) 括号里不写内容,默认删除最后一个,写了,就删除对应下标的内容 改:a.[0] = "gg" 查:a[0] a.index(&q
-
浅谈Python中函数的参数传递
1.普通的参数传递 >>> def add(a,b): return a+b >>> print add(1,2) 3 >>> print add('abc','123') abc123 2.参数个数可选,参数有默认值的传递 >>> def myjoin(string,sep='_'): return sep.join(string) >>> myjoin('Test') 'T_e_s_t' >>>
-

浅谈python中的面向对象和类的基本语法
当我发现要写python的面向对象的时候,我是踌躇满面,坐立不安呀.我一直在想:这个坑应该怎么爬?因为python中关于面向对象的内容很多,如果要讲透,最好是用面向对象的思想重新学一遍前面的内容.这个坑是如此之大,犹豫再三,还是只捡一下重要的内容来讲吧,不足的内容只能靠大家自己去补充了. 惯例声明一下,我使用的版本是 python2.7,版本之间可能存在差异. 好,在开讲之前,我们先思考一个问题,看代码: 为什么我只创建是为 a 赋值,就可以使用一些我没写过的方法? 可能会有小伙伴说:因为 a
-
浅谈python中的getattr函数 hasattr函数
hasattr(object, name) 作用:判断对象object是否包含名为name的特性(hasattr是通过调用getattr(ojbect, name)是否抛出异常来实现的). 示例: >>> hasattr(list, 'append') True >>> hasattr(list, 'add') False getattr(object,name,default): 作用:返回object的名称为name的属性的属性值,如果属性name存在,则直接返回其
-
浅谈python中的数字类型与处理工具
python中的数字类型工具 python中为更高级的工作提供很多高级数字编程支持和对象,其中数字类型的完整工具包括: 1.整数与浮点型, 2.复数, 3.固定精度十进制数, 4.有理分数, 5.集合, 6.布尔类型 7.无穷的整数精度 8.各种数字内置函数及模块. 基本数字类型 python中提供了两种基本类型:整数(正整数金额负整数)和浮点数(注:带有小数部分的数字),其中python中我们可以使用多种进制的整数.并且整数可以用有无穷精度. 整数的表现形式以十进制数字字符串写法出现,浮点数带
-
浅谈python中scipy.misc.logsumexp函数的运用场景
scipy.misc.logsumexp函数的输入参数有(a, axis=None, b=None, keepdims=False, return_sign=False),具体配置可参见这里,返回的值是np.log(np.sum(np.exp(a))). 这里需要强调的是使用该函数的场景: 一般来说,该函数主要用于非常小的数值的运算(比如蒙特卡洛取样样本).在这种情况下,将数据保持log处理是必须的.所以这时你如果想将数组中的数据累加求和就需要这样计算log(sum(exp(a))),但这样做就
-
浅谈python中set使用
浅谈python中set使用 In [2]: a = set() # 常用操作1 In [3]: a Out[3]: set() In [4]: type(a) Out[4]: set In [5]: b = set([1, 3]) In [6]: b Out[6]: {1, 3} In [7]: type(b) Out[7]: set In [8]: b.update(2) ------------------------------------------------------------