jupyter notebook参数化运行python方式
Updates
(2019.8.14 19:53)吃饭前用这个方法实战了一下,吃完回来一看好像不太行:跑完一组参数之后,到跑下一组参数时好像没有释放之占用的 GPU,于是 notebook 上的结果,后面好几条都报错说 cuda out of memory。
现在改成:将 notebook 中的代码写在一个 python 文件中,然后用命令行运行这个文件,比如:
# autorun.py
import os
# print(os.getcwd())
over = [ # 之前手工改参数跑完的参数组合
[0, 1, 1], [0, 1, 2], [0, 1, 3],
[0, 2, 1],
[1, 0, 1],
[1, 2, 1]
]
for alpha in range(1, 4, 1):
for beta in range(3):
for gamma in range(3):
if [alpha, beta, gamma] in over:
continue
os.system(f'python main.py --alpha {alpha} --beta {beta} --gamma {gamma}')
这里的 main.py 是训练用的主文件。改在 py 里用 os.system 跑,希望跑一组参数之后完会自动释放资源再跑下一组(?)
Notes
有多组参数组合需要尝试,不想每组参数都人工修改 python 代码,再在 notebook 中 %run 它。
python 参数通过的 argparse 接收,在 notebook 中写个多重循环遍历参数组合传给 python 程序自动运行。
记录一个简例。
Codes
test_dir
|- test.py
|- test.ipynb
in py file
# test.py
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--number', type=int, default=0, help='number')
parser.add_argument('--string', type=str, default='abc', help='string')
args = parser.parse_args()
print('number:', args.number, type(args.number))
print('string:', args.string, type(args.string))
in notebook
注意传参数时 $ 的使用
# test.ipynb
for i in range(3):
for s in ('a', 'b', 'c'):
%run test.py --number $i --string $s
补充知识:Jupyter Notebook出现kernel error FileNotFoundError: [WinError 2] 系统找不到指定的文件
Jupyter Notebook出现kernel error

conda create -n py36 --clone root
当时用Anaconda克隆本地的环境root到自己创建的py36环境,由于克隆完成后我又更改了虚拟环境名称,所以导致启动
jupyter notebook 进入文件是不能找到连接文件。
File”//anaconda/lib/python2.7/site-packages/jupyter_client/manager.py”, line 190, in _launch_kernel
return launch_kernel(kernel_cmd, **kw)
File “//anaconda/lib/python2.7/site-packages/jupyter_client/launcher.py”, line 123, in launch_kernel
proc = Popen(cmd, **kwargs)
File “//anaconda/lib/python2.7/subprocess.py”, line 710, in init
errread, errwrite)
File “//anaconda/lib/python2.7/subprocess.py”, line 1335, in _execute_child
raise child_exception
OSError: [Errno 2] No such file or director
解决办法
首先在cmd 使用jupyter kernelspec list查看安装的内核和位置
进入安装内核目录打开kernel.jason文件,查看Python编译器的路径是否正确
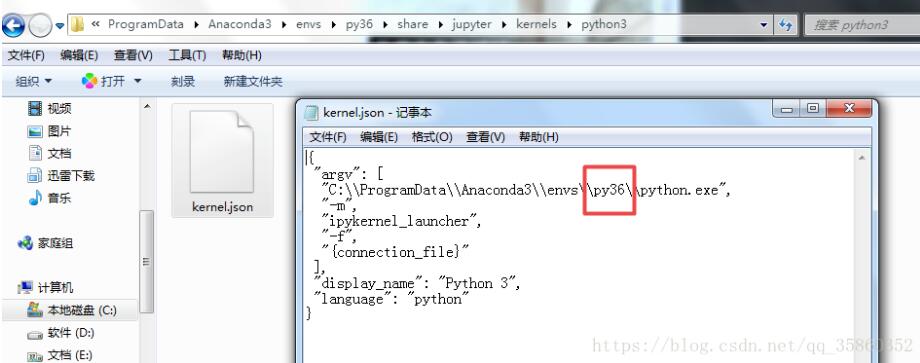
如果不正确python -m ipykernel install --user重新安装内核,如果有多个内核,如果你使用conda create -n python2 python=2,为Python2.7设置conda变量,那么在anacoda下使用activate pyhton2切换python环境,重新使用python -m ipykernel install --user安装内核.(通用情况)
或者直接进入kernel.json里更改py36(这是属于我的情况)
重启jupyter notebook即可。
以上这篇jupyter notebook参数化运行python方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
解决jupyter notebook打不开无反应 浏览器未启动的问题
问题: 这几天要看几个ipython格式的文件,但是jupyter notebook打开之后一直卡在命令行的界面那里(如图),然后就不动了,浏览器也没有预期地自动弹出来. 解决方法: 如果你的命令行显示的结果和我的一样,那你只需要把如图的地址,复制粘贴到浏览器的地址栏,就能打开jupyter notebook. 成功: 补充知识:打开jupyter notebook时浏览器不能自动弹出,网页不显示问题解决 问题: 在windows下打开jupyter notebook时,卡在黑框,浏览器界面加载
-
Jupyter notebook运行Spark+Scala教程
今天在intellij调试spark的时候感觉每次有新的一段代码,都要重新跑一遍,如果用spark-shell,感觉也不是特别方便,如果能像python那样,使用jupyter notebook进行编程就很方便了,同时也适合代码展示,网上查了一下,试了一下,碰到了很多坑,有些是旧的版本,还有些是版本不同导致错误,这里就记录下来安装的过程. 1.运行环境 硬件:Mac 事先装好:Jupyter notebook,spark2.1.0,scala 2.11.8 (这个版本很重要,关系到后面的安装)
-
解决Jupyter因卸载重装导致的问题修复
因为一些原因,卸载了Anaconda2的版本,转向3..发现Jupyter挂了.百思不得其解.后来了解到是因为内核找不到的问题导致的.这里整理了一下处理办法 错误内容: Traceback (most recent call last): File "c:\program files\python36\lib\site-packages\tornado\web.py", line 1543, in _execute result = yield result File "c:
-
jupyter notebook清除输出方式
在 jupyter notebook参数化运行python时,怕输出太多文件太大,想及时清除 notebook 的输出. 在别人代码里看到用 easydl 的 clear_output().调用很简单: from easydl import clear_output print('before') clear_output() # 清除输出 print('after') 查它源码:clear_output def clear_output(): """ clear outpu
-
Window版下在Jupyter中编写TensorFlow的环境搭建
在疫情飘摇的2020年初,TensorFlow发布了2.1.0版本,本Python小白在安装过程中遇坑无数,幸得多年练就的百度功力终于解决,特记录下来以免后人跳坑. 准备工作 Python 3.6或3.7 .TensorFlow2.1.0版本将是最后一个支持Python 2的版本,但Python3.8还不支持,因此请自行从官网下载安装Python 3.6或3.7(我安装的是3.6). 一.搭建虚拟环境(以下顺序不要乱) virtualenv可以搭建虚拟且独立的Python环境,解决不同的工程依赖
-
jupyter notebook参数化运行python方式
Updates (2019.8.14 19:53)吃饭前用这个方法实战了一下,吃完回来一看好像不太行:跑完一组参数之后,到跑下一组参数时好像没有释放之占用的 GPU,于是 notebook 上的结果,后面好几条都报错说 cuda out of memory. 现在改成:将 notebook 中的代码写在一个 python 文件中,然后用命令行运行这个文件,比如: # autorun.py import os # print(os.getcwd()) over = [ # 之前手工改参数跑完的参数
-
使用jupyter notebook运行python和R的步骤
一个图形化的交互式运行环境,对于编程语言的学习和开发,特别是可视化方面,提供了极大的便利.比如在window上使用R语言进行绘图,在R语言自带的交互环境中,可以实时观测到代码的可视化效果,从而方便的进行参数调整. python语言基于命令行的交互式运行环境,可以方便的测试和运行简单代码,但是对于可视化的支持不是很友好,为此,有开发人眼开发出了ipython这一加强版的交互式运行环境,在ipython的基础上,又进一步打造出了jupyter notebook这一强大的交互式运行环境. jupyte
-

详解运行Python的神器Jupyter Notebook
Jupyter Notebook Jupyter项目是从Ipython项目中分出去的,在Ipython3.x之前,他们两个是在一起发布的.在Ipython4.x之后,Jupyter作为一个单独的项目进行开发和管理.因为Jupyter不仅仅可以运行Python程序,它还可以执行其他流程编程语言的运行. Jupyter Notebook包括三个部分,第一个部分是一个web应用程序,提供交互式界面,可以在交互式界面中运行相应的代码. 上图是NoteBook的交互界面,我们可以对文档进行编辑,运行等操作
-
Jupyter Notebook运行JavaScript的方法
后面也加了怎么在 VSC 中使用 Jupyter Notebook-- 安装 Anaconda 安装部分我是直接使用 Anaconda 安装的,这个下载 msi 就可以了,没有什么难的. 遇到报错,以及配置 Anaconda 报错信息如下: D:\>jupyter notebook Traceback (most recent call last): File "C:\ProgramData\Anaconda3\Scripts\jupyter-notebook-script.py"
-
如何实现更换Jupyter Notebook内核Python版本
我使用anaconda安装的python3.6.3,并且自己建立一个虚拟环境,虚拟环境下的python版本也是3.6.3,Jupyter Notebook的内核P丫头好哦哦呢指向的是虚拟环境下的python,最近在使用matplotlib库的遇到了下面的问题: 我的lib目录下是有matplotlib以及相关的库的,重装什么的都试过,无奈实在是找不到解决的办法,于是想更换一下Jupyter Notebook的内核Python版本.接下来具体看一下如何更换内核Python版本. 1.首先在cmd下
-
基于Jupyter notebook搭建Spark集群开发环境的详细过程
一.概念介绍: 1.Sparkmagic:它是一个在Jupyter Notebook中的通过Livy服务器 Spark REST与远程Spark群集交互工作工具.Sparkmagic项目包括一组以多种语言交互运行Spark代码的框架和一些内核,可以使用这些内核将Jupyter Notebook中的代码转换在Spark环境运行. 2.Livy:它是一个基于Spark的开源REST服务,它能够通过REST的方式将代码片段或是序列化的二进制代码提交到Spark集群中去执行.它提供了以下这些基本功能:提
-
Windows下的Jupyter Notebook 安装与自定义启动(图文详解)
我们小编注:如果不是特殊需要建议安装 Anaconda3 即可,自带Jupyter Notebook . 手动安装之前建议查看这篇文章:http://www.jb51.net/article/135171.htm 这是我自定义的Python 的安装目录 (D:\SoftWare\Python\Python36\Scripts) 1.Jupyter Notebook 和 pip 为了更加方便地写 Python 代码,还需要安装 Jupyter notebook. 利用 pip 安装 Jupyter
-
Python3 jupyter notebook 服务器搭建过程
1. jupyter notebook 安装 •创建 jupyter 目录 mkdir jupyter cd jupyter/ •创建独立的 Python3 运行环境,并激活进入该环境 virtualenv --python=python3 --no-site-packages venv source venv/bin/activate •安装 jupyter pip install jupyter 2. jupyter notebook 配置 •创建 notebooks 目录 mkdir no
-
如何实现在jupyter notebook中播放视频(不停地展示图片)
在解决图像处理问题的时候,可以利用opencv打开视频,并一帧一帧地show出来,但是要用到imshow(),需要本地的界面支持. 代码如下 # -*- coding:utf-8*- import cv2 capture = cv2.VideoCapture("D:\\dataset\\chip_gesture.ts") # 图像处理函数 def processImg(img): # 画出一个框 cv2.rectangle(img, (500, 300), (800, 400), (0