Django values()和value_list()的使用
一.values()
1.values()结果是什么?
官方文档说明:https://docs.djangoproject.com/en/2.1/ref/models/querysets/#django.db.models.query.QuerySet.values
示例:
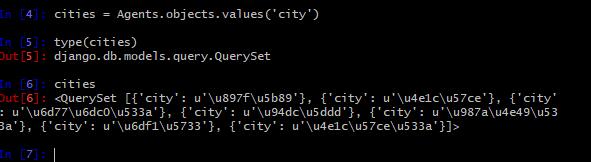
结果:values()得到的是一个字典形式的查询集(QuerySet),查询集是一个可迭代对象。
2.values()结果如何序列化为json?
(1)将QuerySet转为list: city_list = list(cities)
(2)将list序列化为json: city_json = json.dumps(city_list)
补充知识:django queryset values&values_list
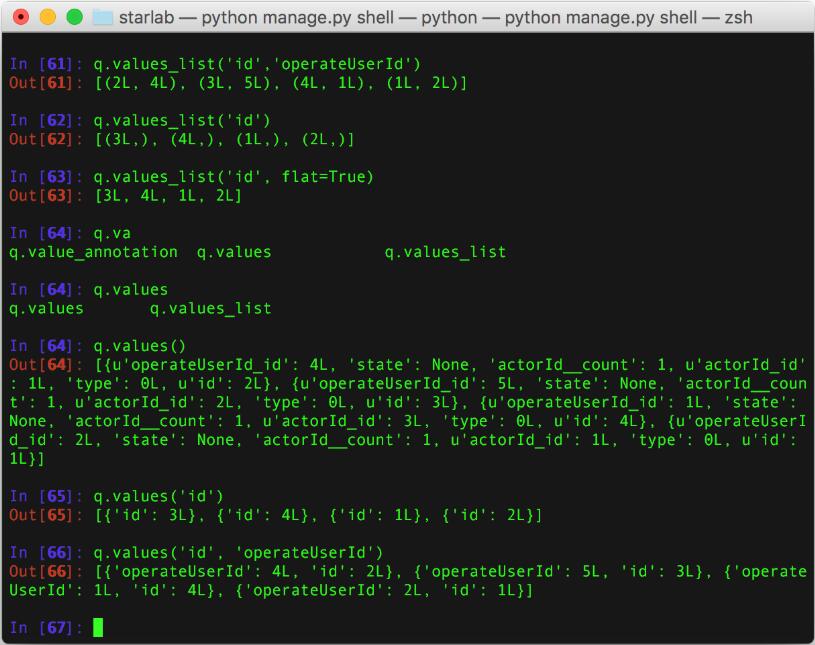
1、values返回是字典列表;
2、values_list返回的是元组列表,
3、values_list加上
flat=True
之后返回值列表
#增
_obj = {'netStates':HostInfo['NetStates'],'ip':HostInfo['ip'],'mem':HostInfo['memoInfo'],'cpu':HostInfo['cpuInfo'],'time':HostInfo['timeInfo']}
obj = models.Monitor.objects.create(**_obj)
#删
models.Charactor.objects.fileter(cid = cID).delete()
#改
obj = object()
abj = models.Charactor.objects.get(cid = cID)
obj.cid = '1'
obj.save()
#查
objLst0 = models.Charactor.objects.filter(cid = cID)
以上这篇Django values()和value_list()的使用就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
基于Django OneToOneField和ForeignKey的区别详解
根据Django官方文档介绍: A one-to-one relationship. Conceptually, this is similar to a ForeignKey with unique=True, but the "reverse" side of the relation will directly return a single object. OneToOneField与ForeignKey加上unique=True效果基本一样,但是用OneToOneField反
-
Django ValuesQuerySet转json方式
在使用ValuesQuerySet存放查询结果时,有时需要转为json,但并不能直接使用json.dumps()直接转,而是需要经过下面一个步骤: result_set = Apple.objects.all().values() print type(result_set) data_list = result_set[:] # queryset转为list print type(data_list) output: <class 'django.db.models.query.ValuesQ
-
Django values()和value_list()的使用
一.values() 1.values()结果是什么? 官方文档说明:https://docs.djangoproject.com/en/2.1/ref/models/querysets/#django.db.models.query.QuerySet.values 示例: 结果:values()得到的是一个字典形式的查询集(QuerySet),查询集是一个可迭代对象. 2.values()结果如何序列化为json? (1)将QuerySet转为list: city_list = list(ci
-
浅谈django orm 优化
orm优化 1.数据库技术进行优化,包括给字段加索引,设置唯一性约束等等: 2.查询过滤工作在数据库语句中做,不要放在代码中完成(看情况): 3.如果要一次查询出集合的数量,使用count函数,而不是len函数,但是如果后面还需要到集合,那就用len,因为count还需要进行一次数据库的操作: 4.避免过多的使用count和exists函数: 5.如果需要查询对象的外键,则使用外键字段而不是使用关联的外键的对象的主键: 例子: a.b_id # 正确 a.b.id # 错误 6.在通过all语句
-
Django程序的优化技巧
友情提示: 过度性能优化是没有必要甚至有害的,因为花大力气带来的毫秒级的响应提升你的用户可能根本感知不到,毕竟开发人员的时间也很宝贵. 性能优化指标 在对一个Web项目进行性能优化时,我们通常需要评价多个指标: 响应时间 最大并发连接数 代码的行数 函数调用次数 内存占用情况 CPU占比 其中响应时间(服务器从接收用户请求,处理该请求并返回结果所需的总的时间)通常是最重要的指标,因为过长的响应时间会让用户厌倦等待,转投其它网站或APP.当你的用户数量变得非常庞大,如何提高最大并发连接数,减少内存
-
MySQL数据库表分区注意事项大全【推荐】
表分区与数据库分区是不一样的那么碰到表分区使用时我们要注意一些什么事情呢,今天我们来看一篇关于MySQL数据库表分区注意事项的细节. 1.分区列索引约束 若表有primary key或unique key,则分区表的分区列必须包含在primary key或unique key列表里,这是为了确保主键的效率,否则同一主键区的东西一个在A分区,一个在B分区,显然会比较麻烦. 2.各分区类型条件 range 每个分区包含那些分区表达式的值位于一个给定的连续区间内的行.这些区间要连续且不能相互重叠 li
-
MySQL的表分区详解
一.什么是表分区通俗地讲表分区是将一大表,根据条件分割成若干个小表.mysql5.1开始支持数据表分区了.如:某用户表的记录超过了600万条,那么就可以根据入库日期将表分区,也可以根据所在地将表分区.当然也可根据其他的条件分区. 二.为什么要对表进行分区为了改善大型表以及具有各种访问模式的表的可伸缩性,可管理性和提高数据库效率.分区的一些优点包括: 1).与单个磁盘或文件系统分区相比,可以存储更多的数据. 2).对于那些已经失去保存意义的数据,通常可以通过删除与那些数据有关的
-

MySQL优化之分区表
当数据库数据量涨到一定数量时,性能就成为我们不能不关注的问题,如何优化呢? 常用的方式不外乎那么几种: 1.分表,即把一个很大的表达数据分到几个表中,这样每个表数据都不多. 优点:提高并发量,减小锁的粒度 缺点:代码维护成本高,相关sql都需要改动 2.分区,所有的数据还在一个表中,但物理存储数据根据一定的规则存放在不同的文件中,文件也可以放到另外磁盘上 优点:代码维护量小,基本不用改动,提高IO吞吐量 缺点:表的并发程度没有增加 3.拆分业务,这个本质还是分表. 优点:长期支持更好 缺点:代码
-
python自动化测试之如何解析excel文件
前言 自动化测试中我们存放数据无非是使用文件或者数据库,那么文件可以是csv,xlsx,xml,甚至是txt文件,通常excel文件往往是我们的首选,无论是编写测试用例还是存放测试数据,excel都是很方便的.那么今天我们就把不同模块处理excel文件的方法做个总结,直接做封装,方便我们以后直接使用,增加工作效率. openpyxl openpyxl是个第三方库,首先我们使用命令 pip install openpyxl 直接安装 注:openpyxl操作excel时,行号和列号都是从1开始计算
-
详解mysql DML语句的使用
前言: 在上篇文章中,主要为大家介绍的是DDL语句的用法,可能细心的同学已经发现了.本篇文章将主要聚焦于DML语句,为大家讲解表数据相关操作. 这里说明下DDL与DML语句的分类,可能有的同学还不太清楚. DDL(Data Definition Language):数据定义语言,用于创建.删除.修改.库或表结构,对数据库或表的结构操作.常见的有create,alter,drop等. DML(Data Manipulation Language):数据操纵语言,主要对表记录进行更新(增.删.改).
-
MySQL使用Partition功能实现水平分区
1 回顾 上一节我们详细讲解了如何对数据库进行分区操作,包括了 垂直拆分(Scale Up 纵向扩展)和水平拆分(Scale Out 横向扩展) ,同时简要整理了水平分区的几种策略,现在来回顾一下. 2 水平分区的5种策略 2.1 Hash(哈希) 这种策略是通过对表的一个或多个列的Hash Key进行计算,最后通过这个Hash码不同数值对应的数据区域进行分区.例如我们可以建立一个对表的日期的年份进行分区的策略,这样每个年份都会被聚集在一个区间. PARTITION BY HASH(YEAR(c
-
Mysql数据库分库分表全面瓦解
目录 1 为什么要分库分表 2 垂直拆分(Scale Up 纵向扩展) 2.1 垂直分库 2.2 垂直分表 3 水平拆分(Scale Out 横向扩展) 3.1 库内分表 3.2 库内分表的实现策略 3.2.1 HASH(哈希) 3.2.2 RANGE(范围) 3.2.3 LIST(预定义列表) 3.2.4 KEY(键值) 3.2.5 Composite(复合模式) 3.3 分库分表 4 分库分表存在的问题 4.1 事务问题 4.2 跨库跨表的join问题 4.3 额外的数据管理负担和数据运算压