Python并发编程多进程,多线程及GIL全局解释器锁
目录
- 1. 并发与并行
- 2. 线程与进程的应用场景
- 2.1. 并行/并发编程相关的技术栈
- 3. Python中的GIL是什么,它影响什么
1. 并发与并行
- 所谓的并行(Parallelism),就是多个彼此独立的任务可以同时一起执行,彼此并不相互干扰,并行强调的是同时且独立的运行,彼此不需要协作。
- 而所谓并发(Concurrency),则是多个任务彼此交替执行,但是同一时间只能有一个处于运行状态,并发执行强调任务之间的彼此协作。
并发通常被误解为并行,并发实际是隐式的调度独立的代码,以协作的方式运行。比如在等待IO线程完成IO操作之前,可以启动IO线程之外的其他独立代码同步执行其他操作。
关于并发、并行的图示,如下:
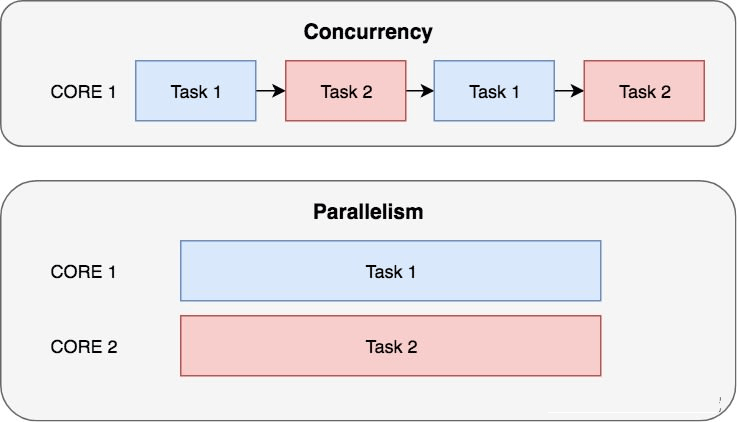
由于CPython解释器中的全局解释器锁(GIL,Global Interpreter Lock)的存在,所以Python中的并行实际上是一种假并行,并不是真正意义上的同时独立运行。
2. 线程与进程的应用场景
进程(Process)是操作系统层面的一个抽象概念,它是运行代码创建出来的、加载到内存中运行的程序。电脑上通常运行着多个进程,这些进程之间是彼此独立运行的。
线程(Thread)是操作系统可以调度的最小运行程序单位,其包含在进程中,一个进程中通常至少包含1个线程,一些进程中会包含多个线程。多个线程运行的都是父进程的相同代码,理想情况下,这些线程是并行执行的,但由于GIL的存在,所以它们实际上是交替执行的,并不是真正意义上的独立、并行的执行的。
下表是进程与线程的对比:

对于IO密集型的操作,更适合使用多线程编程的方式来解决问题;对于CPU密集型的操作,则更适合使用多进程编程的方式来解决问题。
2.1. 并行/并发编程相关的技术栈
Python中提供了一些模块用于实现并行/并发编程,具体如下所示:
threading:Python中进行多线程编程的标准库,是一个对_thread进行再封装的高级模块。multiprocessing:类似于threading模块,提供的API接口也与threading模块类似,不同的是它进行多进程编程。concurrent.futures:标准库中的一个模块,在线程编程模块的基础上抽象出来的更高级实现,且该模块的编程为异步模式。queue:任务队列模块,queue中提供的队列是线程安全的,所以可以使用这个模块进行线程之间进行安全的数据交换操作。不支持分布式。celery:一个高级的分布式任务队列,通过multiprocessing模块或者gevent模块可以实现队列中人物的并发执行。支持多节点之间的分布式计算。 2.2. 通过编码比较多进程与多线程的执行效果
在下面的代码中,定义了两个函数:only_sleep()以及crunch_numbers(),前者用于模拟IO密集型操作(需要频繁中断),后者用于模拟CPU密集型操作。
然后在串行调用、多线程的方式调用、多进程的方式调用,三种不同的执行环境中,比较各个函数的执行效率情况。
具体代码以及执行结果如下所示:
import time
import datetime
import logging
import threading
import multiprocessing
FORMAT = "%(asctime)s [%(processName)s %(process)d] %(threadName)s %(thread)d <=%(message)s=>"
logging.basicConfig(format=FORMAT, level=logging.INFO, datefmt='%H:%M:%S')
def only_sleep():
"""
模拟IO阻塞型操作,此时多线程优势明显
:return:
"""
logging.info('in only_sleep function')
time.sleep(1)
def crunch_numbers():
"""
模拟CPU密集型操作,此时多进程优势明显
:return:
"""
logging.info('in crunch_numbers function')
x = 0
while x < 1000000:
x += 1
if __name__ == '__main__':
work_repeat = 4
print('==>> only_sleep function test')
count = 0
for func in (only_sleep, crunch_numbers):
count += 1
# run tasks serially
start1 = datetime.datetime.now()
for i in range(work_repeat):
func()
stop1 = datetime.datetime.now()
delta1 = (stop1 - start1).total_seconds()
print('Serial Execution takes {} seconds~'.format(delta1))
# run tasks with multi-threads
start2 = datetime.datetime.now()
thread_lst = [threading.Thread(target=func, name='thread-worker' + str(i)) for i in range(work_repeat)]
[thd.start() for thd in thread_lst]
[thd.join() for thd in thread_lst]
stop2 = datetime.datetime.now()
delta2 = (stop2 - start2).total_seconds()
print('Multi-Threads takes {} seconds~'.format(delta2))
# run tasks with multiprocessing
start3 = datetime.datetime.now()
proc_lst = [multiprocessing.Process(target=func, name='process-worker' + str(i)) for i in range(work_repeat)]
[thd.start() for thd in proc_lst]
[thd.join() for thd in proc_lst]
stop3 = datetime.datetime.now()
delta3 = (stop3 - start3).total_seconds()
print('Multi-Processing takes {} seconds~'.format(delta3))
if count == 1:
print('\n', '*.' * 30, end='\n\n')
print('==>> crunch_numbers function test')
上述代码的执行结果如下:
23:55:51 [MainProcess 568124] MainThread 182168 <=in only_sleep function=>
==>> only_sleep function test
23:55:52 [MainProcess 568124] MainThread 182168 <=in only_sleep function=>
23:55:53 [MainProcess 568124] MainThread 182168 <=in only_sleep function=>
23:55:54 [MainProcess 568124] MainThread 182168 <=in only_sleep function=>
23:55:55 [MainProcess 568124] thread-worker0 553012 <=in only_sleep function=>
23:55:55 [MainProcess 568124] thread-worker1 567212 <=in only_sleep function=>
23:55:55 [MainProcess 568124] thread-worker2 547252 <=in only_sleep function=>
23:55:55 [MainProcess 568124] thread-worker3 561892 <=in only_sleep function=>
Serial Execution takes 4.022761 seconds~
Multi-Threads takes 1.01416 seconds~
23:55:56 [process-worker0 563068] MainThread 567480 <=in only_sleep function=>
23:55:56 [process-worker1 567080] MainThread 567628 <=in only_sleep function=>
23:55:56 [process-worker2 567868] MainThread 563656 <=in only_sleep function=>
23:55:56 [process-worker3 567444] MainThread 566436 <=in only_sleep function=>
23:55:57 [MainProcess 568124] MainThread 182168 <=in crunch_numbers function=>
Multi-Processing takes 1.11466 seconds~*.*.*.*.*.*.*.*.*.*.*.*.*.*.*.*.*.*.*.*.*.*.*.*.*.*.*.*.*.*.
==>> crunch_numbers function test
23:55:57 [MainProcess 568124] MainThread 182168 <=in crunch_numbers function=>
23:55:57 [MainProcess 568124] MainThread 182168 <=in crunch_numbers function=>
23:55:57 [MainProcess 568124] MainThread 182168 <=in crunch_numbers function=>
Serial Execution takes 0.1786 seconds~
23:55:57 [MainProcess 568124] thread-worker0 567412 <=in crunch_numbers function=>
23:55:57 [MainProcess 568124] thread-worker1 566468 <=in crunch_numbers function=>
23:55:57 [MainProcess 568124] thread-worker2 565272 <=in crunch_numbers function=>
23:55:57 [MainProcess 568124] thread-worker3 568044 <=in crunch_numbers function=>
Multi-Threads takes 0.195057 seconds~
23:55:58 [process-worker0 567652] MainThread 561892 <=in crunch_numbers function=>
23:55:58 [process-worker1 553012] MainThread 547252 <=in crunch_numbers function=>
23:55:58 [process-worker2 554024] MainThread 556500 <=in crunch_numbers function=>
23:55:58 [process-worker3 565004] MainThread 566108 <=in crunch_numbers function=>
Multi-Processing takes 0.155246 seconds~Process finished with exit code 0
从上述执行结果中可以看出:
上述代码的执行结果也验证了此前的结论:对于IO密集型操作,适合使用多线程编程的方式解决问题;而对于CPU密集型的操作,则适合使用多进程编程的方式解决问题。
3. Python中的GIL是什么,它影响什么
GIL是CPython中实现的全局解释器锁 (Global Interpreter Lock),由于CPython是使用最广泛的Python解释器,所以GIL也是Python世界中最饱受争议的一个主题。
GIL是互斥锁,其目的是为了确保线程安全,正是因为有了GIL,所以可以很方便的与外部非线程安全的模块或者库结合起来。但是这也是有代价的,由于有了GIL,所以导致Python中的并行并不是真正意义上的并行,所以也就无法同时创建两个使用相同代码段的线程,相同代码的线程只能有一个处于执行状态。因为GIL互斥锁,相同代码访问的数据会被加锁,只有当一个线程释放锁之后,相同代码的另一个线程才能访问未被加锁的数据。
所以Python中的多线程是相互交替执行的,并不是真正的并行执行的。但是在CPython之外的一些库,是可以实现真正意义上的并行的,比如numpy这个数据处理常用的库。
到此这篇关于Python并发编程多进程,多线程及GIL全局解释器锁的文章就介绍到这了,更多相关Python GIL解释器锁内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python多进程和多线程介绍
目录 一.什么是进程和线程 二.多进程和多线程 三.python中的多进程和多线程 1.多进程 2.多线程 一.什么是进程和线程 进程是分配资源的最小单位,线程是系统调度的最小单位. 当应用程序运行时最少会开启一个进程,此时计算机会为这个进程开辟独立的内存空间,不同的进程享有不同的空间,而一个CPU在同一时刻只能够运行一个进程,其他进程处于等待状态. 一个进程内部包括一个或者多个线程,这些线程共享此进程的内存空间与资源.相当于把一个任务又细分成若干个子任务,每个线程对应一个子任务. 二.多进程和
-
详解Python中的GIL(全局解释器锁)详解及解决GIL的几种方案
先看一道GIL面试题: 描述Python GIL的概念, 以及它对python多线程的影响?编写一个多线程抓取网页的程序,并阐明多线程抓取程序是否可比单线程性能有提升,并解释原因. GIL:又叫全局解释器锁,每个线程在执行的过程中都需要先获取GIL,保证同一时刻只有一个线程在运行,目的是解决多线程同时竞争程序中的全局变量而出现的线程安全问题.它并不是python语言的特性,仅仅是由于历史的原因在CPython解释器中难以移除,因为python语言运行环境大部分默认在CPython解释器中. 通过
-
Cpython解释器中的GIL全局解释器锁
1.什么是GIL全局解释器锁 GIL:Global Interpreter Lock,意思就是全局解释器锁,这个GIL并不是Python的特性,他是只在Cpython解释器里引入的一个概念,而在其他的语言编写的解释器里就没有GIL,例如:Jython,Pypy等 下面是官方给出的解释: In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from exe
-
对Python中GIL(全局解释器锁)的一点理解浅析
目录 前言 为什么需要 GIL GIL 的实现 几点说明 GIL 优化 用户数据的一致性不能依赖 GIL 总结 参考文档 前言 GIL(Global Interpreter Lock),全局解释器锁,是 CPython 为了避免在多线程环境下造成 Python 解释器内部数据的不一致而引入的一把锁,让 Python 中的多个线程交替运行,避免竞争. 需要说明的是 GIL 不是 Python 语言规范的一部分,只是由于 CPython 实现的需要而引入的,其他的实现如 Jython 和 PyPy
-
Python多进程与多线程的使用场景详解
前言 Python多进程适用的场景:计算密集型(CPU密集型)任务 Python多线程适用的场景:IO密集型任务 计算密集型任务一般指需要做大量的逻辑运算,比如上亿次的加减乘除,使用多核CPU可以并发提高计算性能. IO密集型任务一般指输入输出型,比如文件的读取,或者网络的请求,这类场景一般会遇到IO阻塞,使用多核CPU来执行并不会有太高的性能提升. 下面使用一台64核的虚拟机来执行任务,通过示例代码来区别它们, 示例1:执行计算密集型任务,进行1亿次运算 使用多进程 from multipro
-
Python并发编程多进程,多线程及GIL全局解释器锁
目录 1. 并发与并行 2. 线程与进程的应用场景 2.1. 并行/并发编程相关的技术栈 3. Python中的GIL是什么,它影响什么 1. 并发与并行 所谓的并行(Parallelism),就是多个彼此独立的任务可以同时一起执行,彼此并不相互干扰,并行强调的是同时且独立的运行,彼此不需要协作. 而所谓并发(Concurrency),则是多个任务彼此交替执行,但是同一时间只能有一个处于运行状态,并发执行强调任务之间的彼此协作. 并发通常被误解为并行,并发实际是隐式的调度独立的代码,以协作的方式
-
python并发编程多进程 互斥锁原理解析
运行多进程 每个子进程的内存空间是互相隔离的 进程之间数据不能共享的 互斥锁 但是进程之间都是运行在一个操作系统上,进程之间数据不共享,但是共享同一套文件系统,所以访问同一个文件,或同一个打印终端, 是可以的,而共享带来的是竞争,竞争带来的结果就是错乱 #并发运行,效率高,但竞争同一打印终端,带来了打印错乱 from multiprocessing import Process import time def task(name): print("%s 1" % name) time.
-
python并发编程多进程 模拟抢票实现过程
抢票是并发执行 多个进程可以访问同一个文件 多个进程共享同一文件,我们可以把文件当数据库,用多个进程模拟多个人执行抢票任务 db.txt {"count": 1} 并发运行,效率高,但竞争写同一文件,数据写入错乱,只有一张票,都卖成功给了10个人 #文件db.txt的内容为:{"count":1} #注意一定要用双引号,不然json无法识别 from multiprocessing import Process import time import json cla
-
python并发编程多进程之守护进程原理解析
守护进程 主进程创建子进程目的是:主进程有一个任务需要并发执行,那开启子进程帮我并发执行任务 主进程创建子进程,然后将该进程设置成守护自己的进程 关于守护进程需要强调两点: 其一:守护进程会在主进程代码执行结束后就终止 其二:守护进程内无法再开启子进程,否则抛出异常:AssertionError: daemonic processes are not allowed to have children 如果我们有两个任务需要并发执行,那么开一个主进程和一个子进程分别去执行就ok了,如果子进程的任务
-
Python并发编程队列与多线程最快发送http请求方式
目录 队列+多线程 线程池 协程 + aiohttp grequests 最后的话 Python 并发编程有很多方法,多线程的标准库 threading,concurrency,协程 asyncio,当然还有 grequests 这种异步库,每一个都可以实现上述需求,下面一一用代码实现一下,本文的代码可以直接运行,给你以后的并发编程作为参考: 队列+多线程 定义一个大小为 400 的队列,然后开启 200 个线程,每个线程都是不断的从队列中获取 url 并访问. 主线程读取文件中的 url 放入
-
深入了解Python并发编程
目录 并发方式 线程([Thread]) 进程 (Process) 远程分布式主机 (Distributed Node) 伪线程 (Pseudo-Thread) 实战运用 计算密集型 IO密集型 总结 并发方式 线程([Thread]) 多线程几乎是每一个程序猿在使用每一种语言时都会首先想到用于解决并发的工具(JS程序员请回避),使用多线程可以有效的利用CPU资源(Python例外).然而多线程所带来的程序的复杂度也不可避免,尤其是对竞争资源的同步问题. 然而在python中由于使用了全局解释锁
-
Python并发编程之未来模块Futures
目录 区分并发和并行 并发编程之Futures 到底什么是Futures? 为什么多线程每次只有一个线程执行? 总结 不论是哪一种语言,并发编程都是一项非常重要的技巧.比如我们上一章用的爬虫,就被广泛用在工业的各个领域.我们每天在各个网站.App上获取的新闻信息,很大一部分都是通过并发编程版本的爬虫获得的. 正确并合理的使用并发编程,无疑会给我们的程序带来极大性能上的提升.今天我们就一起学习Python中的并发编程——Futures. 区分并发和并行 我们在学习并发编程时,常常会听到两个词:并发