Python超详细讲解内存管理机制
目录
- 什么是内存管理机制
- 一、引用计数机制
- 二、数据池和缓存
什么是内存管理机制
python中创建的对象的时候,首先会去申请内存地址,然后对对象进行初始化,所有对象都会维护在一
个叫做refchain的双向循环链表中,每个数据都保存如下信息:
1. 链表中数据前后数据的指针
2. 数据的类型
3. 数据值
4. 数据的引用计数
5. 数据的长度(list,dict..)
一、引用计数机制
引用计数增加:
1.1 对象被创建
1.2 对象被别的变量引用(另外起了个名字)
1.3 对象被作为元素,放在容器中(比如被当作元素放在列表中)
1.4 对象被当成参数传递到函数中
import sys a = [11,22] # 对象被创建 b = a # 对象被别的变量引用 c = [111,222,333,a] # 对象被作为元素,放在容器中 # 获取对象的引用计数 print(sys.getrefcount(a)) # 对象被当成参数传递到函数中
最后的执行结果是,a 这个变量被引用了4次

引用计数减少:
- 对象的别名被显式的销毁
- 对象的一个别名被赋值给其他对象 (例:比如原来的a=10,被改成a=100,此时10的引用计数就减少了)
- 对象从容器中被移除,或者容器被销毁(例:对象从列表中被移除,或者列表被销毁)
- 一个引用离开了它的作用域(调用函数的时候传进去的参数,在函数运行结束后,该参数的引用即被销毁)
import sys del b # 对象的别名被显式的销毁 b = 999 # 对象的一个别名被赋值给其他对象 del c # 列表被销毁(容器被销毁) c.pop() # 把列表数据最后一个删除掉(对象从容器中被移除)
二、数据池和缓存
数据池分为两种:小整数池 和 大整数池
小整数池(-5到256之间的数据)
运行机制:Python自动将 -5~256 的整数进行了缓存到一个小整数池中,当你将这些整数赋值给变量时,并不会重新
创建对象,而是使用已经创建好的缓存对象,当删除这些数据的引用时,也不会进行回收
超出-5到256的整数将不会在在缓存,会重新创建对象
例如:
对于超出-5到256的整数将不会在在缓存,Python会重新创建对象,返回id
# 场景1:数据为列表,不在-5~256 的范围 >>> a = [11] >>> b = [11] >>> id(a),id(b) (1693226918600, 1693231858248) ========》 id 不一样 # 场景二: 数据为整数,在-5~256 的范围 >>> aa = 11 >>> bb = 11 >>> id(aa),id(bb) (140720470385616, 140720470385616) id 一样 # 场景三: 数据不在-5~256的范围 >>> bb = -7 >>> aa = -7 >>> id(aa),id(bb) (1843518717904, 1843518717776) id 不一样 # 场景四: 数据不在-5~256的范围 >>> a = 257 >>> b = 257 >>> id(a),id(b) (2092420910928, 2092420911056) id 不一样
大整数池(字符串驻留池 / intern机制)
优点:在创建新的字符串对象时,会先在缓存池里面找是否有已经存在的值相同的对象(标识符,即只包含数字、字母、下划线的字符串),如果有,则直接拿过来用(引用),避免频繁的创建和销毁内存,提升效率
例如:
对于不在标识符内的数据将不会在在缓存,Python会重新创建对象,返回id
# 场景1: >>> a = '123adsf_' >>> b = '123adsf_' >>> id(a),id(b) (61173296, 61173296) ========》 id 一样 # 场景二: >>> b1 = '123adsf_?' >>> b2 = '123adsf_?' >>> id(b1),id(b2) (61173376, 61173416) id 不一样
缓存机制
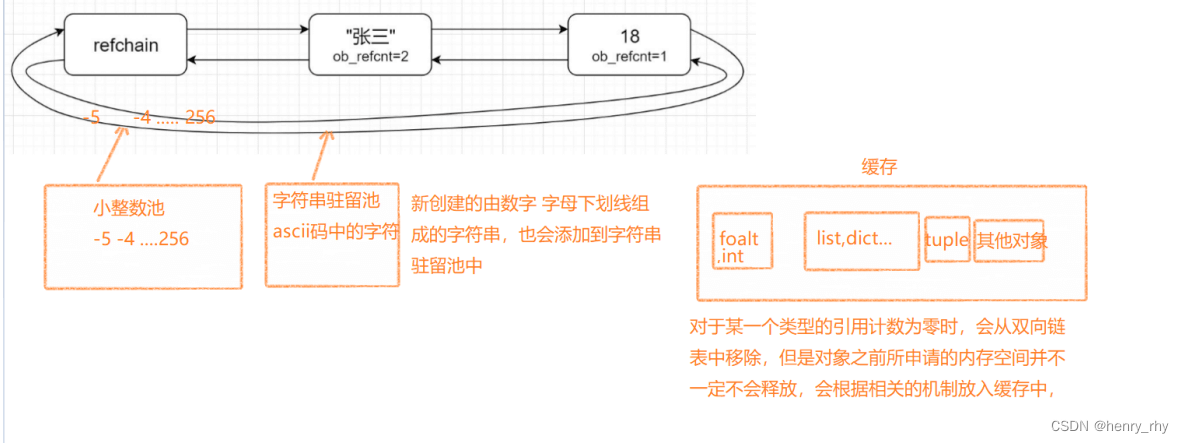
对于python中常用内置数据类型的缓存:
float:缓存100个对象
list: 80个对象
dict: 80个对象
set: 80个对象
元组:会根据元组数据的长度,分别缓存元组长度为0-20的对象
到此这篇关于Python超详细讲解内存管理机制的文章就介绍到这了,更多相关Python内存管理内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python的内存管理和垃圾回收机制详解
简单来说python的内存管理机制有三种 1)引用计数 2)垃圾回收 3)内存池 接下来我们来详细讲解这三种管理机制 1,引用计数: 引用计数是一种非常高效的内存管理手段,当一个pyhton对象被引用时其引用计数增加1,当其不再被引用时引用计数减1,当引用计数等于0的时候,对象就被删除了. 2,垃圾回收(这是一个很重要知识点): ① 引用计数 引用计数也是一种垃圾回收机制,而且是一种最直观,最简单的垃圾回收技术. 在Python中每一个对象的核心就是一个结构体PyObject,它的内部有一个引
-
从Python的源码浅要剖析Python的内存管理
Python 的内存管理架构(Objects/obmalloc.c): 复制代码 代码如下: _____ ______ ______ ________ [ int ] [ dict ] [ list ] ... [ string ] Python core | +3 | <----- Object-specific memory -----> | <-- Non-object memory --> | _________
-
python内存管理机制原理详解
python内存管理机制: 引用计数 垃圾回收 内存池 1. 引用计数 当一个python对象被引用时 其引用计数增加 1 ; 当其不再被变量引用时 引用计数减 1 ; 当对象引用计数等于 0 时, 对象被删除(引用计数是一种非常高效的内存管理机制) 2. 垃圾回收 垃圾回收机制: ① 引用计数 , ②标记清除 , ③分带回收 引用计数 : 引用计数也是一种垃圾收集机制, 而且也是一种最直观, 最简单的垃圾收集技术.当python某个对象的引用计数降为 0 时, 说明没有任何引用指向该对象, 该
-
简单了解python的内存管理机制
Python引入了一个机制:引用计数. 引用计数 python内部使用引用计数,来保持追踪内存中的对象,Python内部记录了对象有多少个引用,即引用计数,当对象被创建时就创建了一个引用计数,当对象不再需要时,这个对象的引用计数为0时,它被垃圾回收. 总结一下对象会在一下情况下引用计数加1: 1.对象被创建:x=4 2.另外的别人被创建:y=x 3.被作为参数传递给函数:foo(x) 4.作为容器对象的一个元素:a=[1,x,'33'] 引用计数减少情况 1.一个本地引用离开了它的作用域.比如上
-
python 怎样进行内存管理
从三个方面来说,主要有方面的措施:对象的引用计数机制.垃圾回收机制.内存池机制. 一.对象的引用计数机制 Python内部使用引用计数,来保持追踪内存中的对象,所有对象都有引用计数. 引用计数增加的情况: 1.一个对象分配一个新名称 2.将其放入一个容器中(如列表.元组或字典) 引用计数减少的情况: 1.使用del语句对对象别名显示的销毁 2.引用超出作用域或被重新赋值 sys.getrefcount( )函数可以获得对象的当前引用计数 多数情况下,引用计数比你猜测得要大得多.对于不可变数据(如
-
Python深入学习之内存管理
语言的内存管理是语言设计的一个重要方面.它是决定语言性能的重要因素.无论是C语言的手工管理,还是Java的垃圾回收,都成为语言最重要的特征.这里以Python语言为例子,说明一门动态类型的.面向对象的语言的内存管理方式. 对象的内存使用 赋值语句是语言最常见的功能了.但即使是最简单的赋值语句,也可以很有内涵.Python的赋值语句就很值得研究. a = 1 整数1为一个对象.而a是一个引用.利用赋值语句,引用a指向对象1.Python是动态类型的语言(参考动态类型),对象与引用分离.Pytho
-
python内存管理分析
本文较为详细的分析了python内存管理机制.分享给大家供大家参考.具体分析如下: 内存管理,对于Python这样的动态语言,是至关重要的一部分,它在很大程度上甚至决定了Python的执行效率,因为在Python的运行中,会创建和销毁大量的对象,这些都涉及到内存的管理. 小块空间的内存池 在Python中,许多时候申请的内存都是小块的内存,这些小块内存在申请后,很快又会被释放,由于这些内存的申请并不是为了创建对象,所以并没有对象一级的内存池机制. Python内存池全景 这就意味着Python在
-
Python内存管理实例分析
本文实例讲述了Python内存管理.分享给大家供大家参考,具体如下: a = 1 a是引用,1是对象.Python缓存整数和短字符串,对象只有一份,但长字符串和其他对象(列表字典)则有很多对象(赋值语句创建新的对象). from sys import getrefcount a=[1,2,3] print(getfrecount(a)) 返回4,当使用某个引用作为参数传给getfrecount时,创建了临时引用,+1. 对象引用对象 class from_obj(object): def __i
-
Python 内存管理机制全面分析
内存管理: 概述 在Python中,内存管理涉及到一个包含所有Python对象和数据结构的私有堆(heap). 这个私有堆的管理由内部的Python内存管理器保证.Python内存管理器有不同的组件来处理各种动态存储管理方面的问题,如共享,分割,预分配或缓存. 在最底层,一个原始内存分配器通过与操作系统的内存管理器交互,确保私有堆有足够的空间来存储所有与Python相关的数据.在原始内存分配器的基础上,几个对象特定的分配器在同一个堆上运行,并根据每种对象类型的特点实现不同的内存管理策略.例如,整
-
Python超详细讲解内存管理机制
目录 什么是内存管理机制 一.引用计数机制 二.数据池和缓存 什么是内存管理机制 python中创建的对象的时候,首先会去申请内存地址,然后对对象进行初始化,所有对象都会维护在一 个叫做refchain的双向循环链表中,每个数据都保存如下信息: 1. 链表中数据前后数据的指针 2. 数据的类型 3. 数据值 4. 数据的引用计数 5. 数据的长度(list,dict..) 一.引用计数机制 引用计数增加: 1.1 对象被创建 1.2 对象被别的变量引用(另外起了个名字) 1.3 对象被作为元素,
-
Spring Boot超详细讲解请求处理流程机制
目录 1. 背景 2. Spring Boot 的请求处理流程设计 3. Servlet服务模式请求流程分析 3.1 ServletWebServerApplicationContext分析 3.2 Servlet服务模式之请求流程具体分析 4. Reactive服务模式请求流程分析 4.1 ReactiveWebServerApplicationContext分析 4.2 webflux服务模式之请求流程具体分析 5. 总结 1. 背景 之前我们对Spring Boot做了研究讲解,我们知道怎
-
SpringBoot超详细讲解事务管理
目录 1. 事务的定义 2. 事务的特性 3. 事务的隔离性 4. 事务管理 5. 示例 1. 事务的定义 事务是由 N 步数据库操作序列组成的逻辑执行单元,这系列操作要么全部执行,要么全部放弃执行. 2. 事务的特性 事务的 ACID 特性: 原子性:事务是应用中不可分割的最小执行体 一致性:事务执行的结果必须使得数据从一个一致性状态转变为另一个一致性状态 隔离性:各个事务的执行互不干扰,任何事务的内部操作对其他事务都是隔离的 持久性:事务一旦提交,对数据所做的任何修改都要记录到永久存储器中
-
C++超详细讲解内存空间分配与this指针
目录 成员属性和函数的存储 空对象 成员属性的存储 成员函数的存储 this指针的概念 解决名称冲突 返回对象指针*this 总结 成员属性和函数的存储 在C++中成员变量和成员函数是分开存储的: 空对象 class Person {}; 这里我直接创建一个空的类,并创建一个空的类对象(Person p),利用sizeof关键字输出p所占内存空间,sizeof(p);结果是p=1: 注意:空对象占用内存空间为: 1.C++编译器会给每个空对象分配一个字节空间,是为了区分空对象占内存的位置 2.每
-
C++详细讲解内存管理工具primitives
目录 primitives new 和 delete placement new 重载 operator new per-class allocator New Handler =default,=delete primitives 分配 释放 属于 是否可重载 malloc() free() C 不可 new delete C++表达式 不可 ::operator new() ::operator delete() C++函数 可 allocator::allocate() allocator
-
Python超详细讲解元类的使用
目录 类的定义 一.什么是元类 二.注意区分元类和继承的基类 三.type 元类的使用 四.自定义元类的使用 类的定义 对象是通过类创建的,如下面的代码: # object 为顶层基类 class Work(object): a = 100 Mywork = Work() # 实例化 print(Mywork ) # Mywork 是 Work 所创建的一个对象 <__main__.Work object at 0x101eb4630> print(type(Mywork)) # <cl
-
Python多进程并发与同步机制超详细讲解
目录 多进程 僵尸进程 Process类 函数方式 继承方式 同步机制 状态管理Managers 在<多线程与同步>中介绍了多线程及存在的问题,而通过使用多进程而非线程可有效地绕过全局解释器锁. 因此,通过multiprocessing模块可充分地利用多核CPU的资源. 多进程 多进程是通过multiprocessing包来实现的,multiprocessing.Process对象(和多线程的threading.Thread类似)用来创建一个进程对象: 在类UNIX平台上,需要对每个Proce
-
C语言可变参数与内存管理超详细讲解
目录 概述 动态分配内存 重新调整内存的大小和释放内存 概述 有时,您可能会碰到这样的情况,您希望函数带有可变数量的参数,而不是预定义数量的参数.C 语言为这种情况提供了一个解决方案,它允许您定义一个函数,能根据具体的需求接受可变数量的参数.下面的实例演示了这种函数的定义. int func(int, ... ) { . . . } int main() { func(2, 2, 3); func(3, 2, 3, 4); } 请注意,函数func()最后一个参数写成省略号,即三个点号(...)
-
Python进程间通讯与进程池超详细讲解
目录 进程间通讯 队列Queue 管道Pipe 进程池Pool 在<多进程并发与同步>中介绍了进程创建与信息共享,除此之外python还提供了更方便的进程间通讯方式. 进程间通讯 multiprocessing中提供了Pipe(一对一)和Queue(多对多)用于进程间通讯. 队列Queue 队列是一个可用于进程间共享的Queue(内部使用pipe与锁),其接口与普通队列类似: put(obj[, block[, timeout]]):插入数据到队列(默认阻塞,且没有超时时间): 若设定了超时且