图文详解Mysql索引的最左前缀原则
目录
- 前言
- 1. 定义
- 2. 全索引顺序
- 3. 部分索引顺序
- 3.1 正序
- 3.2 乱序
- 4. 模糊索引
- 5. 范围索引
- 总结
前言
之所以有这个最左前缀索引
归根结底是mysql的数据库结构 B+树
在实际问题中 比如
索引index (a,b,c)有三个字段,
使用查询语句select * from table where c = '1' ,sql语句不会走index索引的
select * from table where b =‘1’ and c ='2' 这个语句也不会走index索引
1. 定义
最左前缀匹配原则:在MySQL建立联合索引时会遵守最左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配
为了更好辨别这种情况,通过建立表格以及索引的情况进行分析
2. 全索引顺序
建立一张表,建立一个联合索引,如果顺序颠倒,其实还是可以识别的,但是一定要有它的全部部分
建立表
CREATE TABLE staffs(
id INT PRIMARY KEY AUTO_INCREMENT,
`name` VARCHAR(24) NOT NULL DEFAULT'' COMMENT'姓名',
`age` INT NOT NULL DEFAULT 0 COMMENT'年龄',
`pos` VARCHAR(20) NOT NULL DEFAULT'' COMMENT'职位',
`add_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT'入职时间'
)CHARSET utf8 COMMENT'员工记录表';
INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('z3',22,'manager',NOW());
INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('July',23,'dev',NOW());
INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('2000',23,'dev',NOW());
建立索引ALTER TABLE staffs ADD INDEX index_staffs_nameAgePos(name,age,pos);
索引的顺序位name-age-pos
显示其索引有没有show index from staffs;

通过颠倒其左右顺序,其执行都是一样的
主要的语句是这三句
explain select *from staffs where name='z3'and age=22 and pos='manager';explain select *from staffs where pos='manager' and name='z3'and age=22;explain select *from staffs where age=22 and pos='manager' and name='z3';
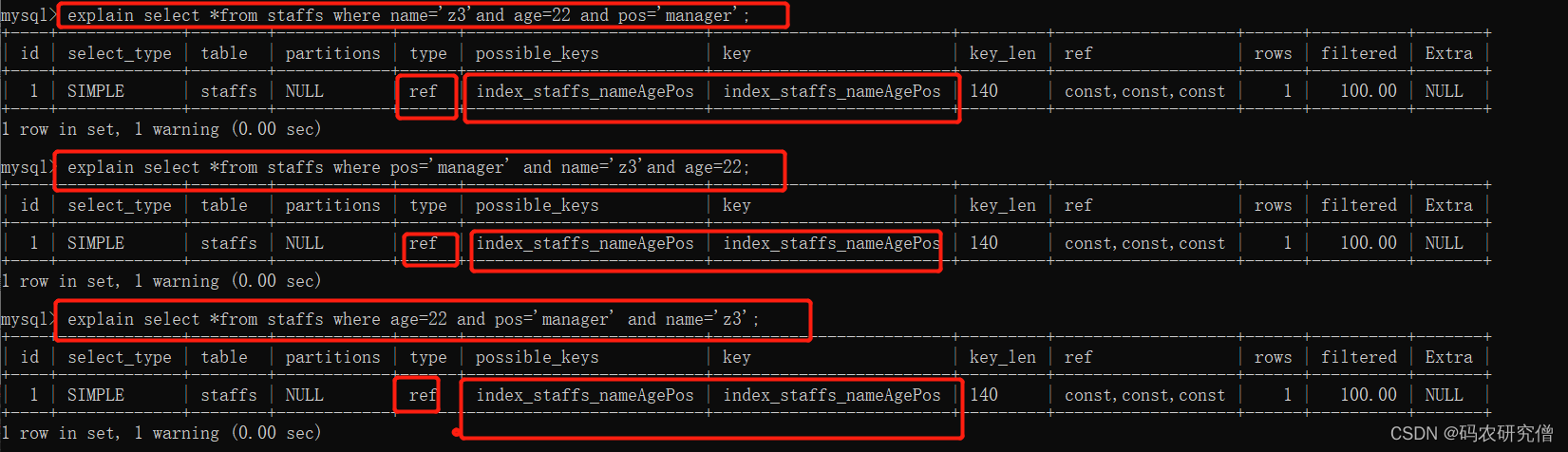
以上三者的顺序颠倒,都使用到了联合索引
最主要是因为MySQL中有查询优化器explain,所以sql语句中字段的顺序不需要和联合索引定义的字段顺序相同,查询优化器会判断纠正这条SQL语句以什么样的顺序执行效率高,最后才能生成真正的执行计划
不论以何种顺序都可使用到联合索引
3. 部分索引顺序
3.1 正序
如果是按照顺序(缺胳膊断腿的),都是一样的
explain select *from staffs where name=‘z3’;explain select *from staffs where name='z3’and age=22;explain select *from staffs where name='z3’and age=22;
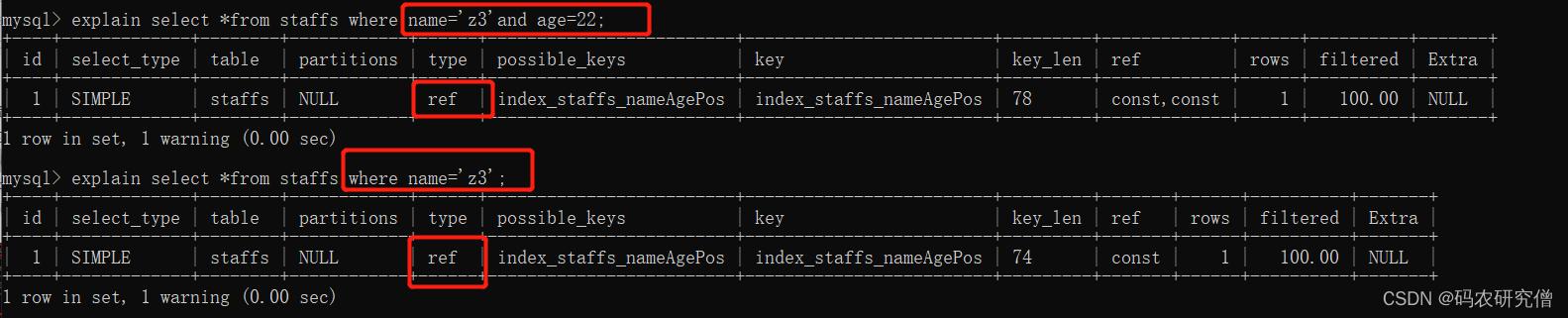
其type都是ref类型,但是其字段长度会有微小变化,也就是它定义的字长长度变化而已
3.2 乱序
如果部分索引的顺序打乱
- 只查第一个索引
explain select *from staffs where name='z3'; - 跳过中间的索引
explain select *from staffs where name='z3' and pos='manager'; - 只查最后的索引
explain select *from staffs where pos='manager';

可以发现正序的时候
如果缺胳膊少腿,也是按照正常的索引
即使跳过了中间的索引,也是可以使用到索引去查询
但是如果只查最后的索引
type就是all类型,直接整个表的查询了(这是因为没有从name一开始匹配,直接匹配pos的话,会显示无序,)
有些时候type就是index类型,这是因为还是可以通过索引进行查询
index是对所有索引树进行扫描,而all是对整个磁盘的数据进行全表扫描
4. 模糊索引
类似模糊索引就会使用到like的语句
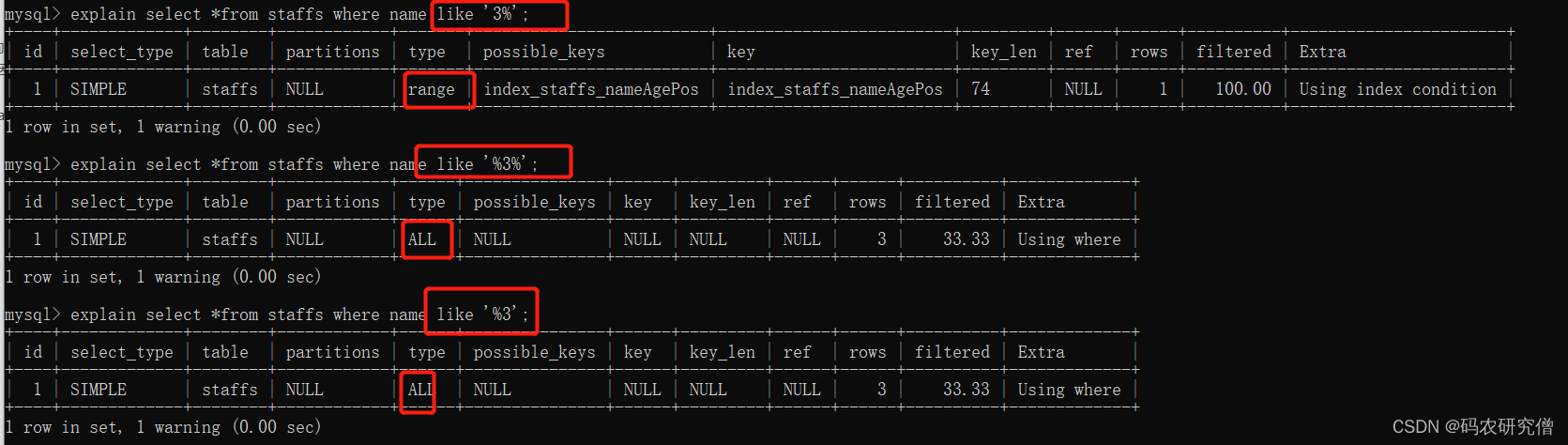
所以下面的三条语句
如果复合最左前缀的话,会使用到range或者是index的类型进行索引
explain select *from staffs where name like '3%';最左前缀索引,类型为index或者rangeexplain select *from staffs where name like '%3%';类型为all,全表查询explain select *from staffs where name like '%3%';,类型为all,全表查询
5. 范围索引
如果查询多个字段的时候,出现了中间是范围的话,建议删除该索引,剔除中间索引即可
具体思路如下
建立一张单表
CREATE TABLE IF NOT EXISTS article( id INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT, author_id INT(10) UNSIGNED NOT NULL, category_id INT(10) UNSIGNED NOT NULL, views INT(10) UNSIGNED NOT NULL, comments INT(10) UNSIGNED NOT NULL, title VARCHAR(255) NOT NULL, content TEXT NOT NULL ); INSERT INTO article(author_id,category_id,views,comments,title,content) VALUES (1,1,1,1,'1','1'), (2,2,2,2,'2','2'), (1,1,3,3,'3','3');
经过如下查询:
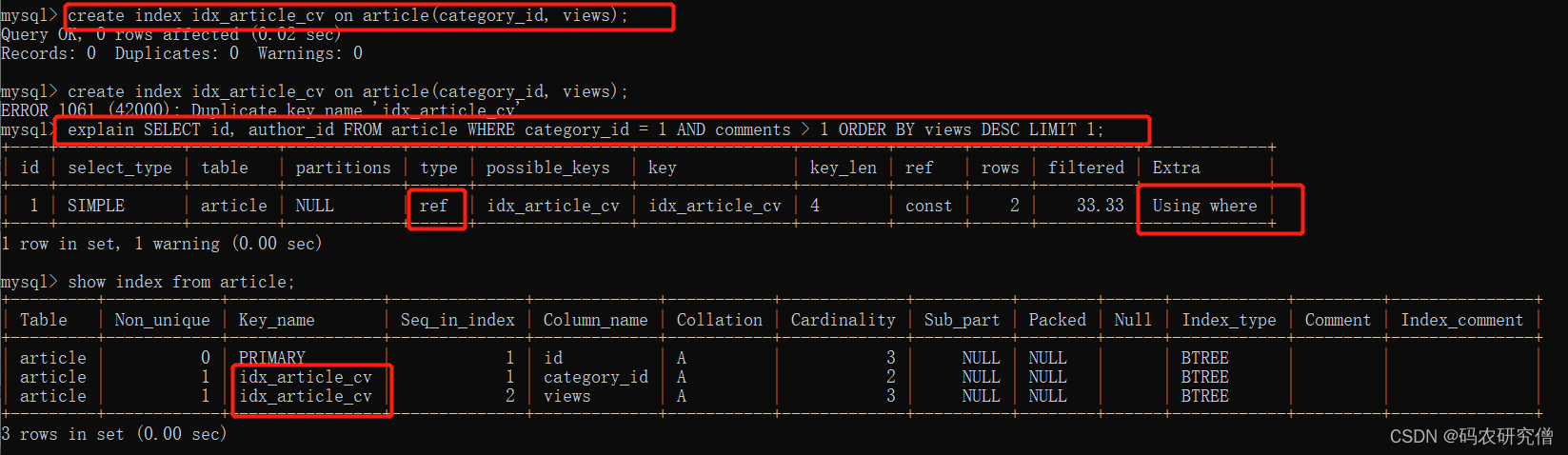
explain SELECT id, author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1;

发现其上面的单表查询,不是索引的话,他是进行了全表查询,而且在extra还出现了Using filesort等问题
所以思路可以有建立其复合索引
具体建立复合索引有两种方式:
create index idx_article_ccv on article(category_id,comments,views);ALTER TABLE 'article' ADD INDEX idx_article_ccv ( 'category_id , 'comments', 'views' );

但这只是去除了它的范围,如果要去除Using filesort问题的话,还要将其中间的条件范围改为等于号才可满足
发现其思路不行,所以删除其索引 DROP INDEX idx_article_ccv ON article;

主要的原因是:
这是因为按照BTree索引的工作原理,先排序category_id,如果遇到相同的category_id则再排序comments,如果遇到相同的comments 则再排序views。
当comments字段在联合索引里处于中间位置时,因comments > 1条件是一个范围值(所谓range),MySQL无法利用索引再对后面的views部分进行检索,即range类型查询字段后面的索引无效。
所以建立复合索引是对的
但是其思路要避开中间那个范围的索引进去
只加入另外两个索引即可create index idx_article_cv on article(category_id, views);
总结
到此这篇关于通过Mysql索引的最左前缀原则的文章就介绍到这了,更多相关Mysql索引最左前缀原则内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySQL前缀索引导致的慢查询分析总结
前端时间跟一个DB相关的项目,alanc反馈有一个查询,使用索引比不使用索引慢很多倍,有点毁三观.所以跟进了一下,用explain,看了看2个查询不同的结果. 不用索引的查询的时候结果如下,实际查询中速度比较块. 复制代码 代码如下: mysql> explain select * from rosterusers limit 10000,3 ; +----+-------------+-------------+------+---------------+------+---------+-
-
通过实例认识MySQL中前缀索引的用法
今天在测试环境中加一个索引时候发现一警告 root@test 07:57:52>alter table article drop index ind_article_url; Query OK, 144384 rows affected (16.29 sec) Records: 144384 Duplicates: 0 Warnings: 0 root@test 07:58:40>alter table article add index ind_article_url(url); Query
-

图文详解Mysql索引的最左前缀原则
目录 前言 1. 定义 2. 全索引顺序 3. 部分索引顺序 3.1 正序 3.2 乱序 4. 模糊索引 5. 范围索引 总结 前言 之所以有这个最左前缀索引 归根结底是mysql的数据库结构 B+树 在实际问题中 比如 索引index (a,b,c)有三个字段, 使用查询语句select * from table where c = '1' ,sql语句不会走index索引的 select * from table where b =‘1’ and c ='2' 这个语句也不会走index索引
-
详解MySQL索引原理以及优化
前言 本文是美团一位大佬写的,还不错拿出来和大家分享下,代码中嵌套在html中sql语句是java框架的写法,理解其sql要执行的语句即可. 背景 MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库.虽然性能出色,但所谓"好马配好鞍",如何能够更好的使用它,已经成为开发工程师的必修课,我们经常会从职位描述上看到诸如"精通MySQL"."SQL语句优化"."了解数据库原理"等要求.我
-
详解mysql索引总结----mysql索引类型以及创建
关于MySQL索引的好处,如果正确合理设计并且使用索引的MySQL是一辆兰博基尼的话,那么没有设计和使用索引的MySQL就是一个人力三轮车.对于没有索引的表,单表查询可能几十万数据就是瓶颈,而通常大型网站单日就可能会产生几十万甚至几百万的数据,没有索引查询会变的非常缓慢.还是以WordPress来说,其多个数据表都会对经常被查询的字段添加索引,比如wp_comments表中针对5个字段设计了BTREE索引. 一个简单的对比测试 以我去年测试的数据作为一个简单示例,20多条数据源随机生成200万条
-
图文详解MySQL中两表关联的连接表如何创建索引
本文介绍了MySQL中两表关联的连接表是如何创建索引的相关内容,分享出来供大家参考学习,下面来看看详细的介绍: 问题介绍 创建数据库的索引,可以选择单列索引,也可以选择创建组合索引. 遇到如下这种情况,用户表(user)与部门表(dept)通过部门用户关联表(deptuser)连接起来,如下图所示: 表间关系 问题就是,在这个关联表中该如何建立索引呢? 针对该表,有如下四种选择: 针对于user_uuid建立单列索引idx_user 针对于user_dept建立单列索引idx_dept 建立组合
-
图文详解MySQL中的主键与事务
一.MySQL 主键和表字段的注释 1.主键及自增 每一张表通常会有一个且只有一个主键,来表示每条数据的唯一性. 特性:值不能重复,不能为空 null 格式:create table test (ID int primary key) 1 主键 + 自增的写法: 格式:create table test (ID int primary key auto_increment) 1 注意:自增只能配合主键来使用(如果单独定义则会报错) 2.表字段的注释 mysql> alter table test
-
图文详解Mysql中如何查看Sql语句的执行时间
目录 一.初始SQL准备 二.Mysql查看Sql语句的执行时间 三.不同查询的执行时间 总结 Mysql中如何查看Sql语句的执行时间 一.初始SQL准备 初始化表 -- 用户表 create table t_users( id int primary key auto_increment, -- 用户名 username varchar(20), -- 密码 password varchar(20), -- 真实姓名 real_name varchar(50), -- 性别 1表示男 0表示
-
图文详解mysql中with...as用法
最近无意中接触到了一篇文章,里面写了一个SQL的用法,是with...as,中午抽空记录一下 用MySQL试了一下,发现并不支持该语法(版本:5.7) 于是换作以下(版本:8.0)不会报错: 总结一下with的用法,类似生成一个临时的表,和如下红框里的操作并无异样 感觉是个鸡肋语法...翻遍了mysql文档也没找到该语法到底是哪个版本开始支持的 更新大佬的原理链接---> MariaDB表表达式(2):CTE - 骏马金龙 总结 到此这篇关于mysql中with...as用法的文章就介绍到这了,
-
详解mysql权限和索引
mysql权限和索引 mysql的最高用户是root, 我们可以在数据库中创建用户,语句为CREATE USER 用户名 IDENTIFIED BY '密码',也可以执行CREATE USER 用户名 语句来创建用户,不过此用户没有密码,可以将用户登录后进行密码设置:删除用户语句为DROP USER 用户:更改用户名的语句为RENAME USER 老用户名 to 新用户名: 修改密码语句为set password=password('密码'): 高级用户修改别的用户密码的语句为SET PASSW
-
详解mysql中的冗余和重复索引
mysql允许在相同列上创建多个索引,无论是有意还是无意,mysql需要单独维护重复的索引,并且优化器在优化查询的时候也需要逐个地进行考虑,这会影响性能. 重复索引是指的在相同的列上按照相同的顺序创建的相同类型的索引,应该避免这样创建重复索引,发现以后也应该立即删除.但,在相同的列上创建不同类型的索引来满足不同的查询需求是可以的. CREATE TABLE test( ID INT NOT NULL PRIMARY KEY, A INT NOT NULL, B INT NOT NULL, UNI
-
MySQL的Query Cache图文详解
目录 一.原理概述 二.Query Cache系统变量 1. have_query_cache 2. query_cache_limit 3. query_cache_min_res_unit 4. query_cache_size 5. query_cache_type 6. query_cache_wlock_invalidate 三.Query Cache状态变量 1. Qcache_free_blocks 2. Qcache_free_memory 3. Qcache_hits 4. Q