基于Pytorch的神经网络之Regression的实现
目录
- 1.引言
- 2.神经网络搭建
- 2.1准备工作
- 2.2搭建网络
- 2.3训练网络
- 3.效果
- 4.完整代码
1.引言
我们之前已经介绍了神经网络的基本知识,神经网络的主要作用就是预测与分类,现在让我们来搭建第一个用于拟合回归的神经网络吧。
2.神经网络搭建
2.1 准备工作
要搭建拟合神经网络并绘图我们需要使用python的几个库。
import torch import torch.nn.functional as F import matplotlib.pyplot as plt x = torch.unsqueeze(torch.linspace(-5, 5, 100), dim=1) y = x.pow(3) + 0.2 * torch.rand(x.size())
既然是拟合,我们当然需要一些数据啦,我选取了在区间 内的100个等间距点,并将它们排列成三次函数的图像。
2.2 搭建网络
我们定义一个类,继承了封装在torch中的一个模块,我们先分别确定输入层、隐藏层、输出层的神经元数目,继承父类后再使用torch中的.nn.Linear()函数进行输入层到隐藏层的线性变换,隐藏层也进行线性变换后传入输出层predict,接下来定义前向传播的函数forward(),使用relu()作为激活函数,最后输出predict()结果即可。
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_feature, n_hidden)
self.predict = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = F.relu(self.hidden(x))
return self.predict(x)
net = Net(1, 20, 1)
print(net)
optimizer = torch.optim.Adam(net.parameters(), lr=0.2)
loss_func = torch.nn.MSELoss()
网络的框架搭建完了,然后我们传入三层对应的神经元数目再定义优化器,这里我选取了Adam而随机梯度下降(SGD),因为它是SGD的优化版本,效果在大部分情况下比SGD好,我们要传入这个神经网络的参数(parameters),并定义学习率(learning rate),学习率通常选取小于1的数,需要凭借经验并不断调试。最后我们选取均方差法(MSE)来计算损失(loss)。
2.3 训练网络
接下来我们要对我们搭建好的神经网络进行训练,我训练了2000轮(epoch),先更新结果prediction再计算损失,接着清零梯度,然后根据loss反向传播(backward),最后进行优化,找出最优的拟合曲线。
for t in range(2000):
prediction = net(x)
loss = loss_func(prediction, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
3.效果
使用如下绘图的代码展示效果。
for t in range(2000):
prediction = net(x)
loss = loss_func(prediction, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if t % 5 == 0:
plt.cla()
plt.scatter(x.data.numpy(), y.data.numpy(), s=10)
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=2)
plt.text(2, -100, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 10, 'color': 'red'})
plt.pause(0.1)
plt.ioff()
plt.show()

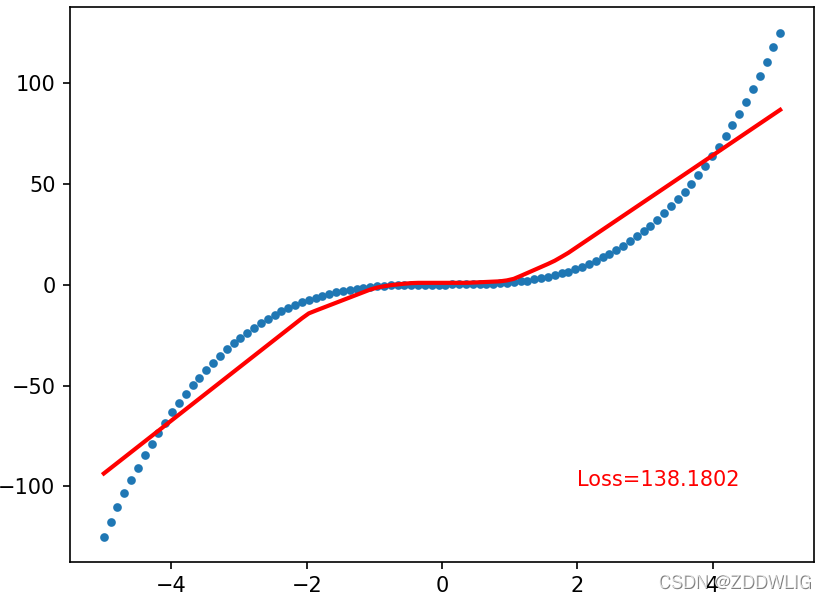
最后的结果:

4. 完整代码
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
x = torch.unsqueeze(torch.linspace(-5, 5, 100), dim=1)
y = x.pow(3) + 0.2 * torch.rand(x.size())
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_feature, n_hidden)
self.predict = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = F.relu(self.hidden(x))
return self.predict(x)
net = Net(1, 20, 1)
print(net)
optimizer = torch.optim.Adam(net.parameters(), lr=0.2)
loss_func = torch.nn.MSELoss()
plt.ion()
for t in range(2000):
prediction = net(x)
loss = loss_func(prediction, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if t % 5 == 0:
plt.cla()
plt.scatter(x.data.numpy(), y.data.numpy(), s=10)
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=2)
plt.text(2, -100, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 10, 'color': 'red'})
plt.pause(0.1)
plt.ioff()
plt.show()
到此这篇关于基于Pytorch的神经网络之Regression的实现的文章就介绍到这了,更多相关 Pytorch Regression内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

pyTorch深入学习梯度和Linear Regression实现
目录 梯度 线性回归(linear regression) 模拟数据集 加载数据集 定义loss_function 梯度 PyTorch的数据结构是tensor,它有个属性叫做requires_grad,设置为True以后,就开始track在其上的所有操作,前向计算完成后,可以通过backward来进行梯度回传. 评估模型的时候我们并不需要梯度回传,使用with torch.no_grad() 将不需要梯度的代码段包裹起来.每个Tensor都有一个.grad_fn属性,该属性即创建该Tensor
-
基于Pytorch的神经网络之Regression的实现
目录 1.引言 2.神经网络搭建 2.1准备工作 2.2搭建网络 2.3训练网络 3.效果 4.完整代码 1.引言 我们之前已经介绍了神经网络的基本知识,神经网络的主要作用就是预测与分类,现在让我们来搭建第一个用于拟合回归的神经网络吧. 2.神经网络搭建 2.1 准备工作 要搭建拟合神经网络并绘图我们需要使用python的几个库. import torch import torch.nn.functional as F import matplotlib.pyplot as plt x = to
-
基于pytorch的保存和加载模型参数的方法
当我们花费大量的精力训练完网络,下次预测数据时不想再(有时也不必再)训练一次时,这时候torch.save(),torch.load()就要登场了. 保存和加载模型参数有两种方式: 方式一: torch.save(net.state_dict(),path): 功能:保存训练完的网络的各层参数(即weights和bias) 其中:net.state_dict()获取各层参数,path是文件存放路径(通常保存文件格式为.pt或.pth) net2.load_state_dict(torch.loa
-
使用 pytorch 创建神经网络拟合sin函数的实现
我们知道深度神经网络的本质是输入端数据和输出端数据的一种高维非线性拟合,如何更好的理解它,下面尝试拟合一个正弦函数,本文可以通过简单设置节点数,实现任意隐藏层数的拟合. 基于pytorch的深度神经网络实战,无论任务多么复杂,都可以将其拆分成必要的几个模块来进行理解. 1)构建数据集,包括输入,对应的标签y 2) 构建神经网络模型,一般基于nn.Module继承一个net类,必须的是__init__函数和forward函数.__init__构造函数包括创建该类是必须的参数,比如输入节点数,隐藏层
-
pytorch动态神经网络(拟合)实现
(1)首先要建立数据集 import torch #引用torch模块 import matplotlib.pyplot as plt #引用画图模块 x=torch.unsqueeze(torch.linspace(-1,1,100),dim=1)#产生(-1,1)的100个点横坐标,dim表示维度,表示在这里增加第二维 y=x.pow(2)+0.2*torch.rand(x,size()) #0.2*torch.rand(x,size())是为了产生噪点使数据更加真实 (2)建立神经网络 i
-
基于PyTorch实现一个简单的CNN图像分类器
pytorch中文网:https://www.pytorchtutorial.com/ pytorch官方文档:https://pytorch.org/docs/stable/index.html 一. 加载数据 Pytorch的数据加载一般是用torch.utils.data.Dataset与torch.utils.data.Dataloader两个类联合进行.我们需要继承Dataset来定义自己的数据集类,然后在训练时用Dataloader加载自定义的数据集类. 1. 继承Dataset类并
-
聊聊基于pytorch实现Resnet对本地数据集的训练问题
目录 1.dataset.py(先看代码的总体流程再看介绍) 2.network.py 3.train.py 4.结果与总结 本文是使用pycharm下的pytorch框架编写一个训练本地数据集的Resnet深度学习模型,其一共有两百行代码左右,分成mian.py.network.py.dataset.py以及train.py文件,功能是对本地的数据集进行分类.本文介绍逻辑是总分形式,即首先对总流程进行一个概括,然后分别介绍每个流程中的实现过程(代码+流程图+文字的介绍). 对于整个项目的流程首
-
Python基于Pytorch的特征图提取实例
目录 简述 单个图片的提取 神经网络的构建 特征图的提取 可视化展示 完整代码 总结 简述 为了方便理解卷积神经网络的运行过程,需要对卷积神经网络的运行结果进行可视化的展示. 大致可分为如下步骤: 单个图片的提取 神经网络的构建 特征图的提取 可视化展示 单个图片的提取 根据目标要求,需要对单个图片进行卷积运算,但是Pytorch中读取数据主要用到torch.utils.data.DataLoader类,因此我们需要编写单个图片的读取程序 def get_picture(picture_dir,
-
基于Pytorch实现的声音分类实例代码
目录 前言 环境准备 安装libsora 安装PyAudio 安装pydub 训练分类模型 生成数据列表 训练 预测 其他 总结 前言 本章我们来介绍如何使用Pytorch训练一个区分不同音频的分类模型,例如你有这样一个需求,需要根据不同的鸟叫声识别是什么种类的鸟,这时你就可以使用这个方法来实现你的需求了. 源码地址:https://github.com/yeyupiaoling/AudioClassification-Pytorch 环境准备 主要介绍libsora,PyAudio,pydub
-
基于Pytorch实现分类器的示例详解
目录 Softmax分类器 定义 训练 测试 感知机分类器 定义 训练 测试 本文实现两个分类器: softmax分类器和感知机分类器 Softmax分类器 Softmax分类是一种常用的多类别分类算法,它可以将输入数据映射到一个概率分布上.Softmax分类首先将输入数据通过线性变换得到一个向量,然后将向量中的每个元素进行指数函数运算,最后将指数运算结果归一化得到一个概率分布.这个概率分布可以被解释为每个类别的概率估计. 定义 定义一个softmax分类器类: class SoftmaxCla
-
基于pytorch 预训练的词向量用法详解
如何在pytorch中使用word2vec训练好的词向量 torch.nn.Embedding() 这个方法是在pytorch中将词向量和词对应起来的一个方法. 一般情况下,如果我们直接使用下面的这种: self.embedding = torch.nn.Embedding(num_embeddings=vocab_size, embedding_dim=embeding_dim) num_embeddings=vocab_size 表示词汇量的大小 embedding_dim=embeding