Docker核心原理之 Cgroup详解
内核中强大的工具cgroup,不仅可以限制被NameSpace隔离起来的资源,还可以为资源设置权重,计算用量等
什么是cgroup
cgroup全称是control groups
control groups:控制组,被整合在了linux内核当中,把进程(tasks)放到组里面,对组设置权限,对进程进行控制。可以理解为用户和组的概念,用户会继承它所在组的权限。
cgroups是linux内核中的机制,这种机制可以根据特定的行为把一系列的任务,子任务整合或者分离,按照资源划分的等级的不同,从而实现资源统一控制的框架,cgroup可以控制、限制、隔离进程所需要的物理资源,包括cpu、内存、IO,为容器虚拟化提供了最基本的保证,是构建docker一系列虚拟化的管理工具
对于开发cgroup的特点
API:实现管理
cgroup管理可以管理到线程界别
所有线程功能都是subsystem(子系统)统一的管理方式
子进程和父进程在一个cgroup里面,只需要控制父进程就可以
cgroup的作用
cgroup的内核通过hook钩子来实现管理进程资源,提供了一个统一的接口,从单个进程的资源控制到操作系统层面的虚拟卡的过渡
cgroup提供了四个功能:
- 资源控制:cgroup通过进程组对资源总额进行限制。如:程序使用内存时,要为程序设定可以使用主机的多少内存,也叫作限额
- 优先级分配:使用硬件的权重值。当两个程序都需要进程读取cpu,哪个先哪个后,通过优先级来进行控制
- 资源统计:可以统计硬件资源的用量,如:cpu、内存…使用了多长时间
- 进程控制:可以对进程组实现挂起/恢复的操作,
术语表
- task:表示系统中的某一个进程—PID
- cgroup:资源控制,以控制组(cgroup)为单位实现,cgroup中有都是task,可以有多个cgroup组,可以限制不同的内容,组名不能相同。
- subsystem:子系统。资源调度控制器。具体控制内容。如:cpu的子系统控制cpu的时间分配,内存的子系统可以控制某个cgroup内的内存使用量,硬盘的子系统,可以控制硬盘的读写等等。
- hierarchy:层级树,一堆cgroup构成,包含多个cgroup的叫层级树,,每个hierarchy通过绑定的子系统对资源进行调度,可以包含0个或多个子节点,子节点继承父节点的属性,整个系统可以有多个hierarchy,是一个逻辑概念
关系:一个cgroup里可以有多个task,subsystem相当于控制cgroup限制的类型, hierarchy里可以有多个cgroup,一个系统可以有多个hierarchy。
层级树的四大规则
传统的进程启动,是以init为根节点,也叫父进程,由它来创建子进程,作为子节点,而每个子节点还可以创建新的子节点,这样构成了树状结构。而cgroup的结构跟他类似的。子节点继承父节点的属性。他们最大的不同在于,系统的cgroup构成的层级树允许有多个存在,如果进程模型是init为根节点形成一个树,那cgroup的模型由多个层级树来构成。
如果只有一个层级树,所有的task都会受到一个subsystem的相同的限制,会给不需要这种限制的task造成麻烦
1.同一个层级树(hierarchy)可以附加一个或多个子系统(subsystem)

可以看到在一个层级树中,有一个cpu_mem_cg的cgroup组下还有两个子节点cg1和cg2,如图所示,也就意味着在cpu_mem_cg的组中,附加了cpu和mem内存两个子系统,同时来控制cg1和cg2的cpu和内存的硬件资源使用
2.一个子系统(subsystem)可以附加到多个层级树(hierarchy)中,但是仅仅是可以附加到多个没有任何子系统的层级树中。
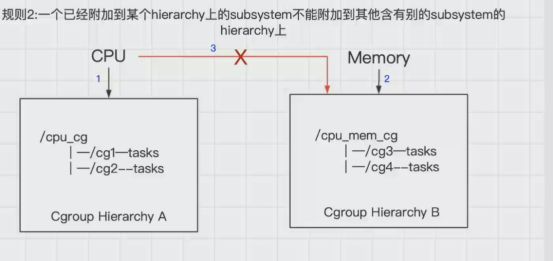
如图所示,cpu子系统先附加到层级树A上,同时就不能附加到层级树B上,因为B上已经有了一个mem子系统,如果B和A同时都是没有任何子系统时,这时,cpu子系统可以同时附加到A和B两个层级树中
言外之意就是,如果多个层级树中都没有子系统,这个时候一个cpu子系统依次可以附加到这些层级树中
3.一个进程(task)不能属于同一个层级树(hierarchy)的不同cgroup

系统每次新建一个层级树(hierarchy)时,默认的构成了新的层级树的初始化的cgroup,这个cgroup被称为root cgroup,对于你自己成功的层级树(hierarchy)来说,task只能存在这个层级树的一个cgroup当中,意思就是一个层级树中不能出现两个相同的task,但是它可以存在不同的层级树中的其他cgroup。
如果要将一个层级树cgroup中的task添加到这个层级树的其他cgroup时,会被从之前task所在的cgroup移除
如以上图中示例:
httpd已经加入到层级树(hierarchy)A中的cg1中,且pid为58950,此时就不能将这个httpd进程放入到cg2中,不然cg1中的httpd进程就会被删除,但是可以放到层级树(hierarchy)B的cg3控制组中
其实是为了防止出现进程矛盾,如:在层级树A中的cg1中存在httpd进程,这时cpu对cg1的限制使用率为30%,cg2的限制使用率为50%,如果再将httpd进程添加到cg2中,这时httpd的cpu使用率限制就有了矛盾。
4.刚fork出的子进程在初始状态与父进程处于同一个cgroup
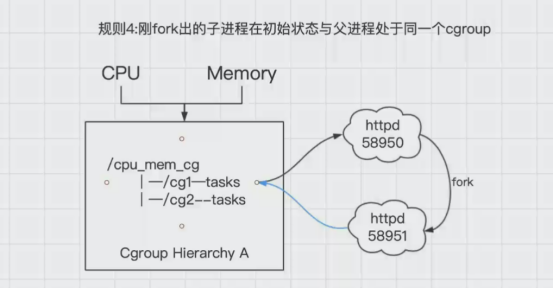
进程task新开的一个子进程(child_task)默认是和原来的task在同一个cgroup中,但是child_task允许被移除到该层级树的其他不同的cgroup中。
当fork刚完成之后,父进程和子进程是完全独立的
如图中所示中,httpd58950进程,当有人访问时,会fork出另外一个子进程httpd58951,这个时候默认httpd58951和httpd58950都在cg1中,他们的关系也是父子进程,httpd58951是可以移动到cg2中,这时候就改变了他们的关系,都变为了独立的进程。
Subsystem子系统
subsystem究竟可以控制什么东西
通过以下的操作来验证
[root@localhost ~]# yum -y install libcgroup-tools 安装这个工具后就看可以通过使用cgroup命令来查看
列出系统中所有的cgroup控制组
[root@localhost ~]# lscgroup net_cls,net_prio:/ freezer:/ hugetlb:/ cpu,cpuacct:/ cpu,cpuacct:/machine.slice cpu,cpuacct:/user.slice cpu,cpuacct:/system.slice cpu,cpuacct:/system.slice/network.service cpu,cpuacct:/system.slice/docker.service ...
查看subsystem可以控制的硬件
[root@localhost ~]# lssubsys -a cpuset cpu,cpuacct memory devices freezer net_cls,net_prio blkio perf_event hugetlb pids
以上查看到的,有存在的对应目录,/sys/fs/cgroup
[root@localhost ~]# ll /sys/fs/cgroup/ total 0 drwxr-xr-x. 5 root root 0 Mar 25 04:50 blkio lrwxrwxrwx. 1 root root 11 Mar 25 04:50 cpu -> cpu,cpuacct lrwxrwxrwx. 1 root root 11 Mar 25 04:50 cpuacct -> cpu,cpuacct drwxr-xr-x. 5 root root 0 Mar 25 04:50 cpu,cpuacct drwxr-xr-x. 2 root root 0 Mar 25 04:50 cpuset drwxr-xr-x. 5 root root 0 Mar 25 04:50 devices drwxr-xr-x. 2 root root 0 Mar 25 04:50 freezer drwxr-xr-x. 2 root root 0 Mar 25 04:50 hugetlb drwxr-xr-x. 5 root root 0 Mar 25 04:50 memory lrwxrwxrwx. 1 root root 16 Mar 25 04:50 net_cls -> net_cls,net_prio drwxr-xr-x. 2 root root 0 Mar 25 04:50 net_cls,net_prio lrwxrwxrwx. 1 root root 16 Mar 25 04:50 net_prio -> net_cls,net_prio drwxr-xr-x. 2 root root 0 Mar 25 04:50 perf_event drwxr-xr-x. 5 root root 0 Mar 25 04:50 pids drwxr-xr-x. 5 root root 0 Mar 25 04:50 systemd
可以看到目录中的内容是比命令查看到的多,是因为有几个软链接文件
# 以下三个都属于cpu,cpuacct cpu -> cpu,cpuacct cpuacct -> cpu,cpuacct cpu,cpuacct # 以下三个都属于net_cls,net_prio net_cls -> net_cls,net_prio net_prio -> net_cls,net_prio net_cls,net_prio
Subsystem可以控制的内容分别代表什么
| 编号 | 限制内容 | 代表意思 |
|---|---|---|
| 1 | blkio(对块设备提供输入输出的限制) | 光盘、固态磁盘、USB…。 |
| 2 | cpu | 可以调控task对cpu的使用。 |
| 3 | cpuacct | 自动生成task对cpu资源使用情况的报告。 |
| 4 | cpuset(针对多处理器的物理机使用) | 对task单独分配某个cpu使用的。 |
| 5 | device(设备是指键盘、鼠标…) | 关闭和开启task对设备的访问。 |
| 6 | freezer | 控制task的挂起和恢复,如不允许某个task使用cpu被称之为挂起。 |
| 7 | memory | 控制task对内存使用量的限定,自动生成对内存资源使用的报告 |
| 8 | perf_event | 对task可以进行统一的性能测试,如探测linxu的cpu性能以及硬盘的读写效率等等。 |
| 9 | net_cls | 在docker中没有直接被使用,它通过使用等级识别符(classid)标记网络数据包,从而允许 Linux 流量控制程序识别从具体cgroup中生成的数据包。 |
注意:到现在为止,还没有可以对容器硬盘大小进行限制的工具,只能限制硬盘的读写频率
cgroup的工作原理
查看cgroup中的CPU控制中的tasks文件,存放了对文件中的进程的cpu的控制,如果要添加某个进程对cpu的控制,将进程的pid加入tasks文件即可,包括其他的硬件资源控制也是如此
[root@localhost ~]# cat /sys/fs/cgroup/cpu/tasks 1 2 4 5 6 7 8 9 ... 68469 68508 68526 68567
在生产环境中,由于在内核中,所以它是自动增加的
cgroup真正的工作原理就是hook钩子,cgroup的实现本质上是给系统进程挂上钩子实现的,当task进程运行的过程中,设计到某个资源是,就会触发钩子上附带的subsystem子系统进行资源检测,最终根据资源类别的不同使用对应的技术进行资源限制和优先级分配。
钩子是怎么实现的
简单来说,linux中管理task进程的数据结构,在cgroup的每个task设置一个关键词,将关键词都指向钩子,叫做指针。
一个task只对应一个指针结构时,一个指针结构可以被多个task进行使用
当一个指针一旦读取到唯一指针数据的内容,task就会被触发,就可以进行资源控制
在实际的使用过程中,用户需要使用mount来挂载cgroup控制组
在目录中可以看到,比如httpd程序,pid号为69060
[root@localhost ~]# yum -y install httpd^C [root@localhost ~]# systemctl start httpd^C [root@localhost ~]# netstat -anput | grep 80 tcp6 0 0 :::80 :::* LISTEN 69060/httpd
查看它pid号目录中的mounts文件,存放了大量的关于cgroup的挂载
可以看到每一个cgoup后面的目录,如/sys/fs/cgroup/cpu,cpuacct,说明httpd进程受到了cpu使用的限制,该文件中还有很多类似的挂载项,可以看到的有blkio/perf_event/memory等的硬件资源控制。
[root@localhost ~]# cat /proc/69060/mounts rootfs / rootfs rw 0 0 /dev/mapper/centos-root / xfs rw,seclabel,relatime,attr2,inode64,noquota 0 0 devtmpfs /dev devtmpfs rw,seclabel,nosuid,size=914476k,nr_inodes=228619,mode=755 0 0 tmpfs /dev/shm tmpfs rw,seclabel,nosuid,nodev 0 0 devpts /dev/pts devpts rw,seclabel,nosuid,noexec,relatime,gid=5,mode=620,ptmxmode=000 0 0 mqueue /dev/mqueue mqueue rw,seclabel,relatime 0 0 hugetlbfs /dev/hugepages hugetlbfs rw,seclabel,relatime 0 0 ... cgroup /sys/fs/cgroup/systemd cgroup rw,seclabel,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd 0 0 cgroup /sys/fs/cgroup/net_cls,net_prio cgroup rw,seclabel,nosuid,nodev,noexec,relatime,net_prio,net_cls 0 0 cgroup /sys/fs/cgroup/freezer cgroup rw,seclabel,nosuid,nodev,noexec,relatime,freezer 0 0 cgroup /sys/fs/cgroup/hugetlb cgroup rw,seclabel,nosuid,nodev,noexec,relatime,hugetlb 0 0 cgroup /sys/fs/cgroup/cpu,cpuacct cgroup rw,seclabel,nosuid,nodev,noexec,relatime,cpuacct,cpu 0 0 cgroup /sys/fs/cgroup/cpuset cgroup rw,seclabel,nosuid,nodev,noexec,relatime,cpuset 0 0 cgroup /sys/fs/cgroup/devices cgroup rw,seclabel,nosuid,nodev,noexec,relatime,devices 0 0 cgroup /sys/fs/cgroup/memory cgroup rw,seclabel,nosuid,nodev,noexec,relatime,memory 0 0 cgroup /sys/fs/cgroup/blkio cgroup rw,seclabel,nosuid,nodev,noexec,relatime,blkio 0 0 cgroup /sys/fs/cgroup/pids cgroup rw,seclabel,nosuid,nodev,noexec,relatime,pids 0 0 cgroup /sys/fs/cgroup/perf_event cgroup rw,seclabel,nosuid,nodev,noexec,relatime,perf_event 0 0 ...
这就是通过mount控制cgroup的,所有的程序都是这样的,子系统上所有的系统都把文件mount上以后,就可以像操作系统一样操作cgroup和层级树进行管理,包括权限管理、子文件系统,除了cgroup文件系统以外,内核中没有为cgroup的访问提供添加其他任何的操作,想要去操作cgroup,就必须使用mount挂到某一个cgroup控制组内才行。
资源控制操作
我们需要知道每一个硬件资源的具体怎么去控制的操作
如:
cgroup组中的cpu目录里具体的每一项的具体的含义,都是对cpu具体的控制的细节
[root@localhost ~]# cd /sys/fs/cgroup/cpu [root@localhost cpu]# ls cgroup.clone_children cpuacct.stat cpu.cfs_quota_us cpu.stat system.slice cgroup.event_control cpuacct.usage cpu.rt_period_us machine.slice tasks cgroup.procs cpuacct.usage_percpu cpu.rt_runtime_us notify_on_release user.slice cgroup.sane_behavior cpu.cfs_period_us cpu.shares release_agent
这些具体的使用方法会在下一篇文章中来逐个去解释用法
Docker命令行限制内容
-c/--cpu-shares:限制cpu优先级 -m/--memory:限制内存的使用容量 --memory-swap:限制内存+swap的大小 --blkil-weight bps/iops --device-read-bps --device-write-bps --device-read-iops --device-write-iops
cgroup目录结构如下
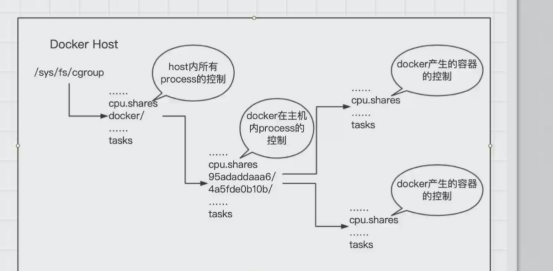
/sys/fs/cgroup中存放了所有进程的硬件资源控制
/sys/fs/cgroup/{cpu,memory,blkio...}/目录下存放了特定硬件资源的默认的非docker进程的控制,docker的进程号不会在这些目录下
/sys/fs/cgroup/cpu/docker/目录下存放了docker在主机内的进程控制
/sys/fs/cgroup/cpu/docker/容器id/目录下存放了对docker产生的容器的控制
到此这篇关于Docker核心原理之 Cgroup详解的文章就介绍到这了,更多相关Docker核心原理内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Docker底层技术Namespace Cgroup应用详解
Docker底层技术: docker底层的2个核心技术分别是Namespaces和Control groups Namespace:是容器虚拟化的核心技术,用来隔离各个容器,可解决容器之间的冲突. 主要通过以下六项隔离技术来实现: 有两个伪文件系统:/proc和/sys/ UTS:允许每个container拥有独立的hostname(主机名)和domainname(域名),使其在网络上可以被视作一个独立的节点而非Host上的一个进程. IPC:contaner中进程交互还是采用linux常见的进
-
docker cgroup 资源监控的详解
docker cgroup 资源监控的详解 1.cgroup术语解析: blkio: 这个subsystem可以为块设备设定输入/输出限制,比如物理驱动设备(包括磁盘.固态硬盘.USB等). cpu: 这个subsystem使用调度程序控制task对CPU的使用. cpuacct: 这个subsystem自动生成cgroup中task对CPU资源使用情况的报告. cpuset: 这个subsystem可以为cgroup中的task分配独立的CPU(此处针对多处理器系统)和内存. devices
-
详解Docker 容器使用 cgroups 限制资源使用
上一篇文章将到 Docker 容器使用 linux namespace 来隔离其运行环境,使得容器中的进程看起来就像爱一个独立环境中运行一样.但是,光有运行环境隔离还不够,因为这些进程还是可以不受限制地使用系统资源,比如网络.磁盘.CPU以及内存 等.为了让容器中的进程更加可控,Docker 使用 Linux cgroups 来限制容器中的进程允许使用的系统资源. 1. 基础知识:Linux control groups 1.1 概念 Linux Cgroup 可让您为系
-

Docker核心原理之 Cgroup详解
内核中强大的工具cgroup,不仅可以限制被NameSpace隔离起来的资源,还可以为资源设置权重,计算用量等 什么是cgroup cgroup全称是control groups control groups:控制组,被整合在了linux内核当中,把进程(tasks)放到组里面,对组设置权限,对进程进行控制.可以理解为用户和组的概念,用户会继承它所在组的权限. cgroups是linux内核中的机制,这种机制可以根据特定的行为把一系列的任务,子任务整合或者分离,按照资源划分的等级的不同,从而实现
-
Docker的理解和基本命令详解
如何通俗解释D ocker是什么? Docker思想来自于集装箱,集装箱解决了什么问题呢?比如,在一艘大船上,要把各种各样的货物要整理起来,集装箱(Docker)就可以做到,并且相互间不会影响.就不需要指定运输的船了(这个船运吃的那个船运穿的).只要把货物装在集装箱里封装好,就可以用一艘大船把他们都运走. 1.Docker就是类似的理念.云计算是运输船,Docker就是集装箱. 1.不同的应用程序可能会有不同的应用环境,比如.net开发的网站和php开发的网站依赖的软件就不一样,如果把他们依赖的
-
Python 异步协程函数原理及实例详解
这篇文章主要介绍了Python 异步协程函数原理及实例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一. asyncio 1.python3.4开始引入标准库之中,内置对异步io的支持 2.asyncio本身是一个消息循环 3.步骤: (1)创建消息循环 (2)把协程导入 (3)关闭 4.举例: import threading # 引入异步io包 import asyncio # 使用协程 @ asyncio.coroutine def
-
SpringBoot实战之高效使用枚举参数(原理篇)案例详解
找入口 对 Spring 有一定基础的同学一定知道,请求入口是DispatcherServlet,所有的请求最终都会落到doDispatch方法中的ha.handle(processedRequest, response, mappedHandler.getHandler())逻辑.我们从这里出发,一层一层向里扒. 跟着代码深入,我们会找到org.springframework.web.method.support.InvocableHandlerMethod#invokeForRequest的
-
Docker核心组件之联合文件系统详解
目录 1. 联合文件系统的定义 2. 配置 Docker 的 AUFS 模式 3. AUFS 工作原理 3.1 AUFS 如何存储文件 3.2 AUFS 如何工作 4. AUFS 演示 4.1 准备演示目录和文件 4.2 创建 AUFS 联合文件系统 4.3 验证 AUFS 的写时复制 1. 联合文件系统的定义 联合文件系统(Union File System,Unionfs)是一种分层的轻量级文件系统,它可以把多个目录内容联合挂载到同一目录下,从而形成一个单一的文件系统,这种特性可以让使用者像
-
epoll封装reactor原理剖析示例详解
目录 reactor是什么? reactor模型三个重要组件与流程分析 组件 流程 将epoll封装成reactor事件驱动 封装每一个连接sockfd变成ntyevent 封装epfd和ntyevent变成ntyreactor 封装读.写.接收连接等事件对应的操作变成callback 给每个客户端的ntyevent设置属性 将ntyevent加入到epoll中由内核监听 将ntyevent从epoll中去除 读事件回调函数 写事件回调函数 接受新连接事件回调函数 reactor运行 react
-
Java基础之Stream流原理与用法详解
目录 一.接口设计 二.创建操作 三.中间操作 四.最终操作 五.Collect收集 Stream简化元素计算 一.接口设计 从Java1.8开始提出了Stream流的概念,侧重对于源数据计算能力的封装,并且支持序列与并行两种操作方式:依旧先看核心接口的设计: BaseStream:基础接口,声明了流管理的核心方法: Stream:核心接口,声明了流操作的核心方法,其他接口为指定类型的适配: 基础案例:通过指定元素的值,返回一个序列流,元素的内容是字符串,并转换为Long类型,最终计算求和结果并
-
SpringBoot Starter依赖原理与实例详解
目录 1 Starter 2 了解 spring.factories机制 2.1 不同包路径下的依赖注入 2.2 spring.factories 机制 3 spring.factories 机制的实现源码分析 4 程序运行入口run() 1 Starter 在开发 SpringBoot 项目的时候,我们常常通过 Maven 导入自动各种依赖,其中很多依赖都是以 xxx-starter 命名的. 像这种 starter 依赖是怎么工作的呢? 2 了解 spring.factories机制 导入一
-
Java中读写锁ReadWriteLock的原理与应用详解
目录 什么是读写锁? 为什么需要读写锁? 读写锁的特点 读写锁的使用场景 读写锁的主要成员和结构图 读写锁的实现原理 读写锁总结 Java并发编程提供了读写锁,主要用于读多写少的场景,今天我就重点来讲解读写锁的底层实现原理 什么是读写锁? 读写锁并不是JAVA所特有的读写锁(Readers-Writer Lock)顾名思义是一把锁分为两部分:读锁和写锁,其中读锁允许多个线程同时获得,因为读操作本身是线程安全的,而写锁则是互斥锁,不允许多个线程同时获得写锁,并且写操作和读操作也是互斥的. 所谓的读
-
无UI 组件Headless框架逻辑原理用法示例详解
目录 概述 精读 总结 概述 Headless 组件即无 UI 组件,框架仅提供逻辑,UI 交给业务实现.这样带来的好处是业务有极大的 UI 自定义空间,而对框架来说,只考虑逻辑可以让自己更轻松的覆盖更多场景,满足更多开发者不同的诉求. 我们以 headlessui-tabs 为例看看它的用法,并读一读 源码. headless tabs 最简单的用法如下: import { Tab } from "@headlessui/react"; function MyTabs() { ret