Python爬虫Scrapy框架IP代理的配置与调试
目录
- 代理ip的逻辑在哪里
- 如何配置动态的代理ip
在调试爬虫的时候,新手都会遇到关于ip的错误,好好的程序突然报错了,怎么解决,关于ip访问的错误其实很好解决,但是怎么知道解决好了呢?怎么确定是代理ip的问题呢?由于笔者主修语言是Java,所以有些解释可能和Python大佬们的解释不一样,因为我是从Java 的角度看Python。这样也便于Java开发人员阅读理解。
代理ip的逻辑在哪里
一个scrapy 的项目结构是这样的
scrapydownloadertest # 项目文件夹
│ items.py # 定义爬取结果存储的数据结构
│ middlewares.py # 中间件(可以理解java的过滤器拦截器)
│ pipelines.py # 数据管道,对获取到的数据做操作
│ settings.py # 项目的配置文件
│ __init__.py # 初始化逻辑
│
├─spiders # 放置 Spiders 的文件夹
│ │ httpProxyIp.py # 爬取到结果后的处理类
│ │ __init__.py # spider初始化逻辑
scrapy.py
从上可以发现,代理ip的设置肯定是在发送请求之前就要设置好,那么唯一符合条件的地方就是 middlewares.py ,所以关于代理的相关逻辑都写在这个里面。直接在其中添加如下代码:
# Scrapy 内置的 Downloader Middleware 为 Scrapy 供了基础的功能,
# 定义一个类,其中(object)可以不写,效果一样
class SimpleProxyMiddleware(object):
# 声明一个数组
proxyList = ['http://218.75.158.153:3128','http://188.226.141.61:8080']
# Downloader Middleware的核心方法,只有实现了其中一个或多个方法才算自定义了一个Downloader Middleware
def process_request(self, request, spider):
# 随机从其中选择一个,并去除左右两边空格
proxy = random.choice(self.proxyList).strip()
# 打印结果出来观察
print("this is request ip:" + proxy)
# 设置request的proxy属性的内容为代理ip
request.meta['proxy'] = proxy
# Downloader Middleware的核心方法,只有实现了其中一个或多个方法才算自定义了一个Downloader Middleware
def process_response(self, request, response, spider):
# 请求失败不等于200
if response.status != 200:
# 重新选择一个代理ip
proxy = random.choice(self.proxyList).strip()
print("this is response ip:" + proxy)
# 设置新的代理ip内容
request.mete['proxy'] = proxy
return request
return response
每个 Downloader Middleware 定义了一个或多个方法的类,核心的方法有如下三个:
- process_request(request, spider)
- process_response(request,response, spider)
- process_exception(request, exception, spider)
然后找到 setting.py 文件中的这块区域

修改如下,也就是取消注释,加上刚刚写的Middleware 类的路径

以上就已经配置好了一个简单的代理ip,此时来到 httpProxyIp.py 这个文件, 这个文件是我通过命令 scrapy genspider httpProxyIp icanhazip.com 生成的,创建成功内容如下:
# -*- coding: utf-8 -*-
import scrapy
class HttpproxyipSpider(scrapy.Spider):
name = 'httpProxyIp'
allowed_domains = ['icanhazip.com']
start_urls = ['http://icanhazip.com/']
def parse(self, response):
pass
我们修改一下,最终代码如下所示:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.cmdline import execute
class HttpproxyipSpider(scrapy.Spider):
# spider 任务名
name = 'httpProxyIp'
# 允许访问的域名
allowed_domains = ['icanhazip.com']
# 起始爬取的url
start_urls = ['http://icanhazip.com/']
# spider 爬虫解析的方法,关于内容的解析都在这里完成; self表示实例的引用, response爬虫的结果
def parse(self, response):
print('代理后的ip: ', response.text)
# 这个是main函数也是整个程序入口的惯用写法
if __name__ == '__main__':
execute(['scrapy', 'crawl', 'httpbin'])
此时运行程序 scrapy crawl httpProxyIp 可以看到结果输出
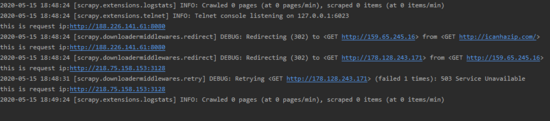
很明显,这里没有打印出我们想要的结果,说明之前 proxyList = ['http://218.75.158.153:3128','http://188.226.141.61:8080'] 没有用,我们找找有没有可以用的,这里用免费的,所以找起来费点时间 免费代理ip
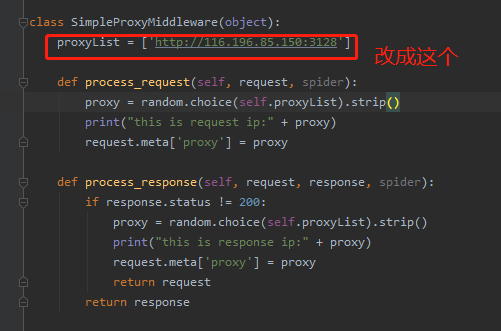
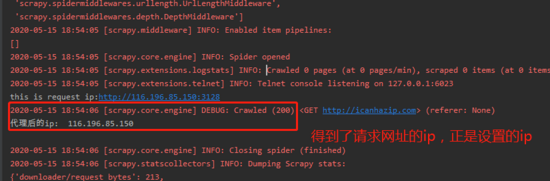
这样就完成了scrapy的代理设置和验证调试。
如何配置动态的代理ip
这里使用的是收费的代理ip了,你可以使用快代理或者阿布云等云服务商提供的服务,当你注册并缴费之后,会给你一个访问url和用户名密码,这里直接看代码吧! 同样在 middlewares.py新建一个类
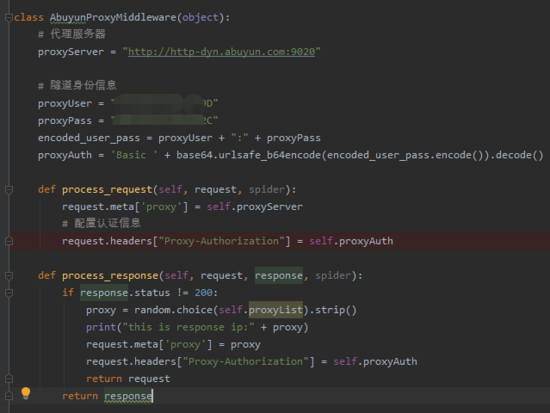
修改 setting.py 的 DOWNLOADER_MIDDLEWARES 内容
DOWNLOADER_MIDDLEWARES = {
# 注释掉之前的例子改用AbuyunProxyMiddleware
# 'scrapydownloadertest.middlewares.SimpleProxyMiddleware': 100,
'scrapydownloadertest.middlewares.AbuyunProxyMiddleware': 100,
}
其他地方不动,我们在启动看看,这里换种启动方式,因为使用的是PyCharm开发工具,所以可以直接
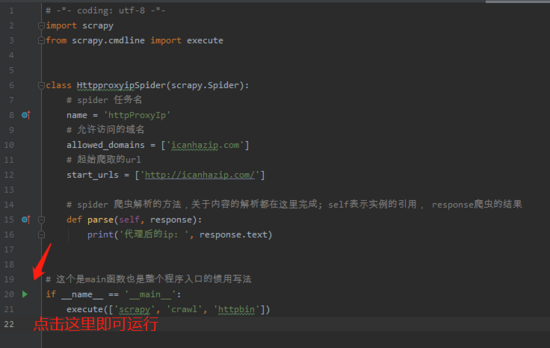
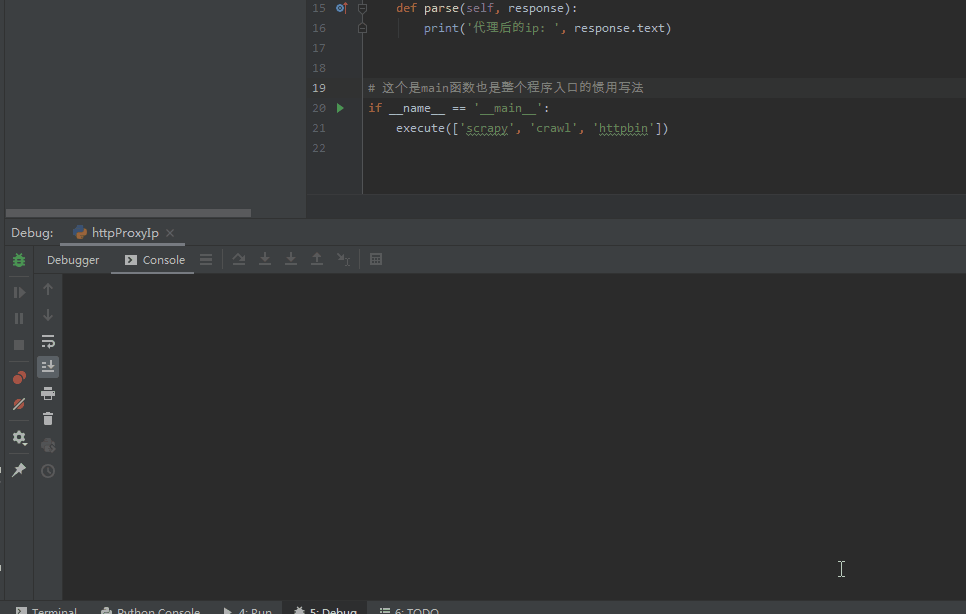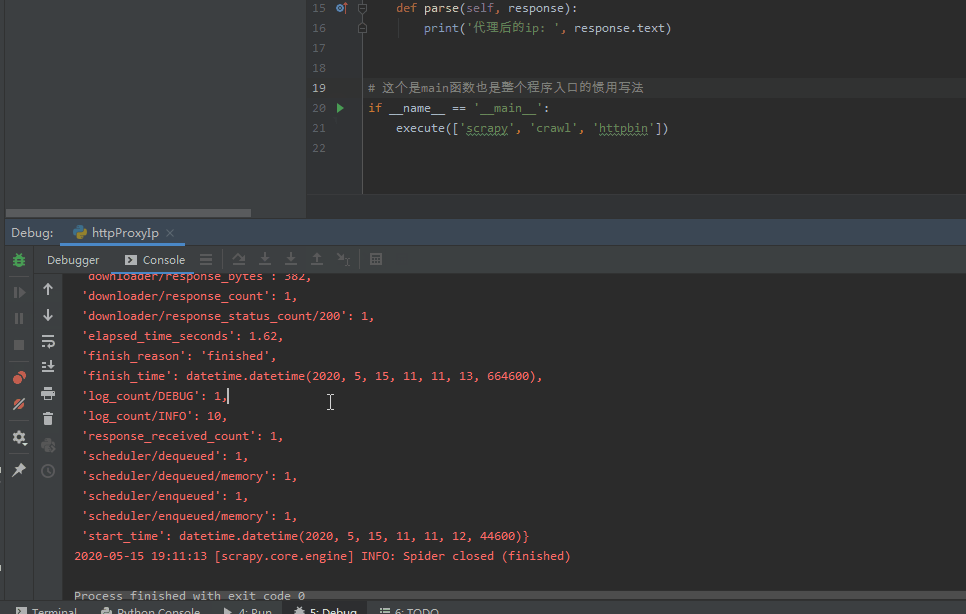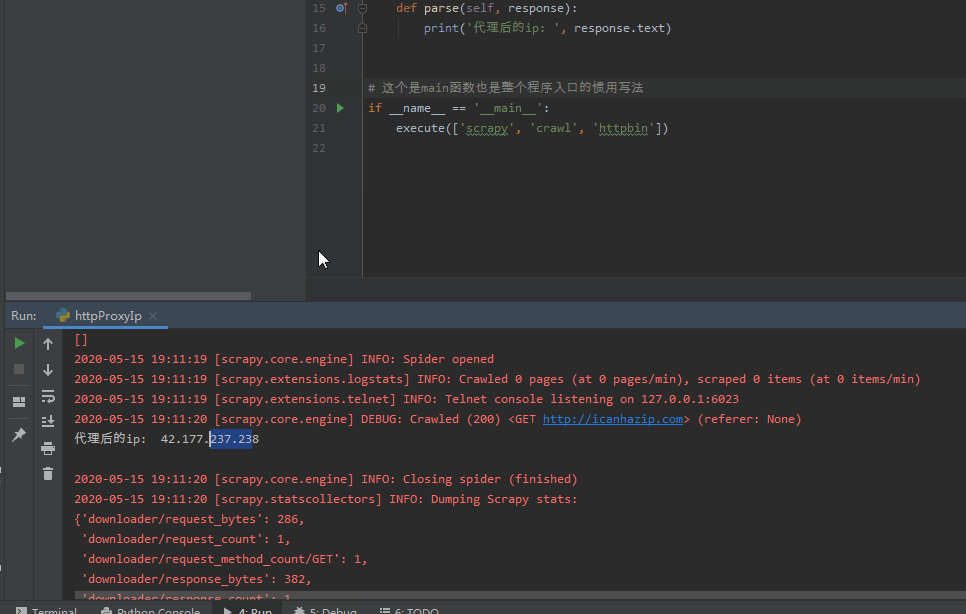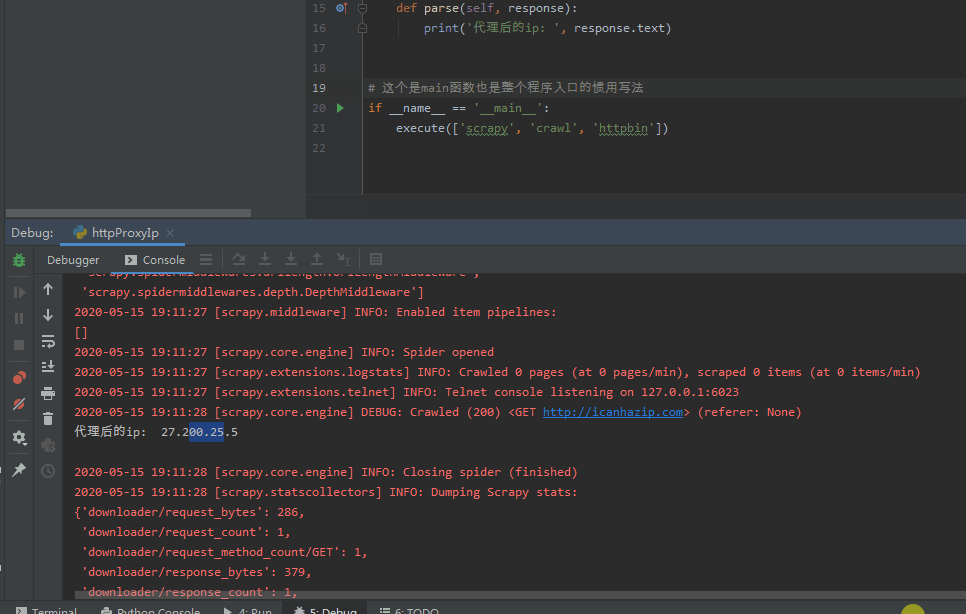
http://icanhazip.com/是一个显示当前访问者ip的网站,可以很方便的用来验证scrapy的代理ip 设置是否成功。
到此这篇关于Python爬虫Scrapy框架IP代理的配置与调试的文章就介绍到这了,更多相关Scrapy框架IP代理配置调试内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python3 Scrapy爬虫框架ip代理配置的方法
什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性的项目模板.对于框架的学习,重点是要学习其框架的特性.各个功能的用法即可. 一.背景 在做爬虫项目的过程中遇到ip代理的问题,网上搜了一些,要么是用阿里云的ip代理,要么是搜一些网上现有的ip资源,然后配置在setting文件中.这两个方法都存在一些问题. 1.阿里云ip代理方法,网上大
-
详解基于Scrapy的IP代理池搭建
一.为什么要搭建爬虫代理池 在众多的网站防爬措施中,有一种是根据ip的访问频率进行限制,即在某一时间段内,当某个ip的访问次数达到一定的阀值时,该ip就会被拉黑.在一段时间内禁止访问. 应对的方法有两种: 1. 降低爬虫的爬取频率,避免IP被限制访问,缺点显而易见:会大大降低爬取的效率. 2. 搭建一个IP代理池,使用不同的IP轮流进行爬取. 二.搭建思路 1.从代理网站(如:西刺代理.快代理.云代理.无忧代理)爬取代理IP: 2.验证代理IP的可用性(使用代理IP去请求指定URL,根据响应验证
-
Python爬虫Scrapy框架IP代理的配置与调试
目录 代理ip的逻辑在哪里 如何配置动态的代理ip 在调试爬虫的时候,新手都会遇到关于ip的错误,好好的程序突然报错了,怎么解决,关于ip访问的错误其实很好解决,但是怎么知道解决好了呢?怎么确定是代理ip的问题呢?由于笔者主修语言是Java,所以有些解释可能和Python大佬们的解释不一样,因为我是从Java 的角度看Python.这样也便于Java开发人员阅读理解. 代理ip的逻辑在哪里 一个scrapy 的项目结构是这样的 scrapydownloadertest # 项目文件夹 │ ite
-
Python爬虫scrapy框架Cookie池(微博Cookie池)的使用
下载代码Cookie池(这里主要是微博登录,也可以自己配置置其他的站点网址) 下载代码GitHub:https://github.com/Python3WebSpider/CookiesPool 下载安装过后注意看网页下面的相关基础配置和操作!!!!!!!!!!!!! 自己的设置主要有下面几步: 1.配置其他设置 2.设置使用的浏览器 3.设置模拟登陆 源码cookies.py的修改(以下两处不修改可能会产生bug): 4.获取cookie 随机获取Cookies: http://localho
-
python爬虫Scrapy框架:媒体管道原理学习分析
目录 一.媒体管道 1.1.媒体管道的特性 媒体管道实现了以下特性: 图像管道具有一些额外的图像处理功能: 1.2.媒体管道的设置 二.ImagesPipeline类简介 三.小案例:使用图片管道爬取百度图片 3.1.spider文件 3.2.items文件 3.3.settings文件 3.4.pipelines文件 一.媒体管道 1.1.媒体管道的特性 媒体管道实现了以下特性: 避免重新下载最近下载的媒体 指定存储位置(文件系统目录,Amazon S3 bucket,谷歌云存储bucket)
-
python爬虫scrapy框架的梨视频案例解析
之前我们使用lxml对梨视频网站中的视频进行了下载,感兴趣的朋友点击查看吧. 下面我用scrapy框架对梨视频网站中的视频标题和视频页中对视频的描述进行爬取 分析:我们要爬取的内容并不在同一个页面,视频描述内容需要我们点开视频,跳转到新的url中才能获取,我们就不能在一个方法中去解析我们需要的不同内容 1.爬虫文件 这里我们可以仿照爬虫文件中的parse方法,写一个新的parse方法,可以将新的url的响应对象传给这个新的parse方法 如果需要在不同的parse方法中使用同一个item对象,可
-
Python爬虫Scrapy框架CrawlSpider原理及使用案例
提问:如果想要通过爬虫程序去爬取"糗百"全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬去进行实现的(Request模块回调) 方法二:基于CrawlSpider的自动爬去进行实现(更加简洁和高效) 一.简单介绍CrawlSpider CrawlSpider其实是Spider的一个子类,除了继承到Spider的特性和功能外,还派生除了其自己独有的更加强大的特性和功能.其中最显著的功能就是"LinkExtractors链接提取器&qu
-
python爬虫scrapy框架之增量式爬虫的示例代码
scrapy框架之增量式爬虫 一 .增量式爬虫 什么时候使用增量式爬虫: 增量式爬虫:需求 当我们浏览一些网站会发现,某些网站定时的会在原有的基础上更新一些新的数据.如一些电影网站会实时更新最近热门的电影.那么,当我们在爬虫的过程中遇到这些情况时,我们是不是应该定期的更新程序以爬取到更新的新数据?那么,增量式爬虫就可以帮助我们来实现 二 .增量式爬虫 概念: 通过爬虫程序检测某网站数据更新的情况,这样就能爬取到该网站更新出来的数据 如何进行增量式爬取工作: 在发送请求之前判断这个URL之前是不是
-
Python爬虫 scrapy框架爬取某招聘网存入mongodb解析
创建项目 scrapy startproject zhaoping 创建爬虫 cd zhaoping scrapy genspider hr zhaopingwang.com 目录结构 items.py title = scrapy.Field() position = scrapy.Field() publish_date = scrapy.Field() pipelines.py from pymongo import MongoClient mongoclient = MongoClien
-
Python利用Scrapy框架爬取豆瓣电影示例
本文实例讲述了Python利用Scrapy框架爬取豆瓣电影.分享给大家供大家参考,具体如下: 1.概念 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 通过Python包管理工具可以很便捷地对scrapy进行安装,如果在安装中报错提示缺少依赖的包,那就通过pip安装所缺的包 pip install scrapy scrapy的组成结构如下图所示 引擎Scrapy Engine,用于中转调度其他部分的信号和数据