c++实现一个简易的网络缓冲区的实践
目录
- 1. 前言
- 2. 数据结构
- 3. 外部接口设计与实现
- 4. 完整代码与测试
1. 前言
请思考以下几个问题:
1).为什么需要设计网络缓冲区,内核中不是有读写缓冲区吗?
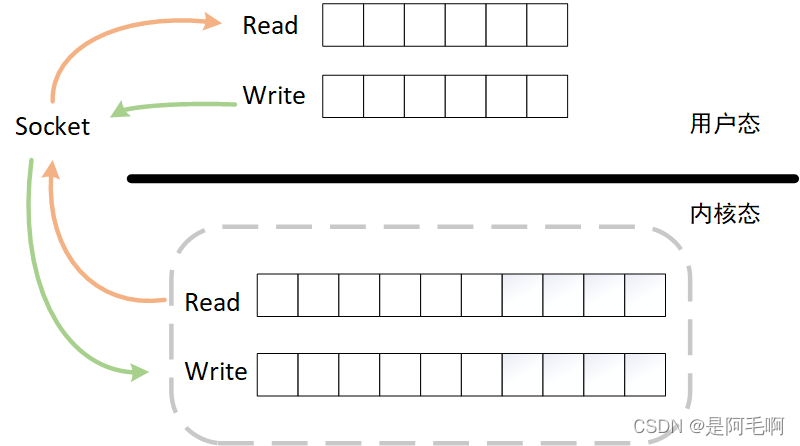
需要设计的网络缓冲区和内核中TCP缓冲区的关系如下图所示,通过socket进行进行绑定。具体来说网络缓冲区包括读(接收)缓冲区和写(发送)缓冲区。设计读缓冲区的目的是:当从TCP中读数据时,不能确定读到的是一个完整的数据包,如果是不完整的数据包,需要先放入缓冲区中进行缓存,直到数据包完整才进行业务处理。设计写缓冲区的目的是:向TCP写数据不能保证所有数据写成功,如果TCP写缓冲区已满,则会丢弃数据包,所以需要一个写缓冲区暂时存储需要写的数据。
2).缓冲区应该设置为堆内存还是栈内存?
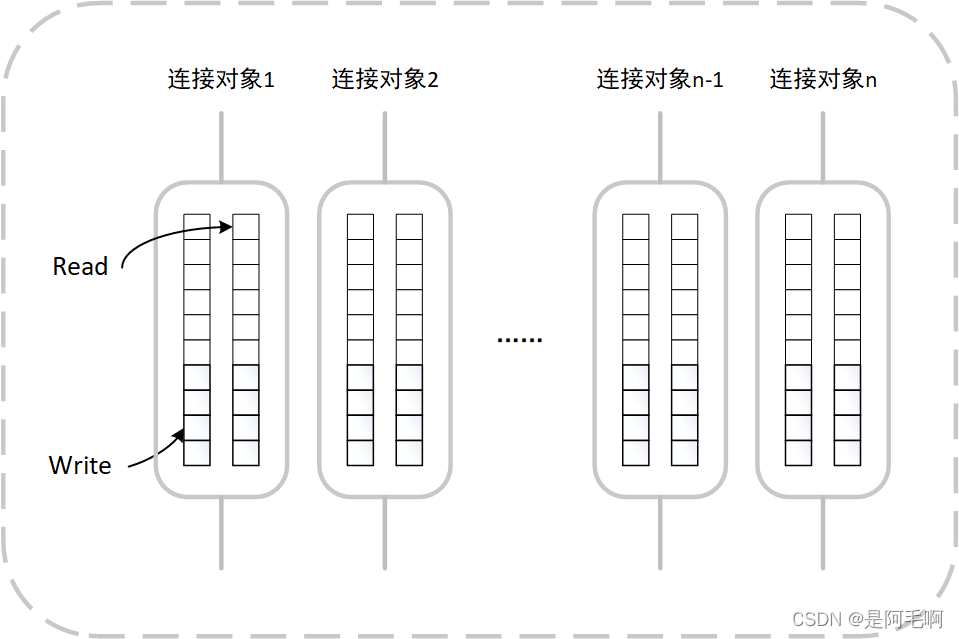
假设有一个服务端程序,需要同时连接多个客户端,每一个socket就是一个连接对象,所以不同的socket都需要自己对应的读写缓冲区。如果将缓冲区设置为栈内存,很容易爆掉,故将将其设置为堆内存更加合理。此外,缓冲区容量上限一般是有限制的,一开始不需要分配过大,仅仅在缓冲区不足时进行扩展。
3).读写缓冲区的基本要求是什么?
通过以上分析,不难得出读写缓冲区虽然是两个独立的缓冲区,但是其核心功能相同,可以复用其代码。
读写缓冲区至少提供两类接口:存储数据和读取数据
读写缓冲区要求:先进先出,保证存储的数据是有序的
4).如何界定数据包?
第一种使用特殊字符界定数据包:例如\n,\r\n,第二种通过长度界定数据包,数据包中首先存储的是整个数据包的长度,再根据长度进行读取。
5).几种常见的缓冲区设计
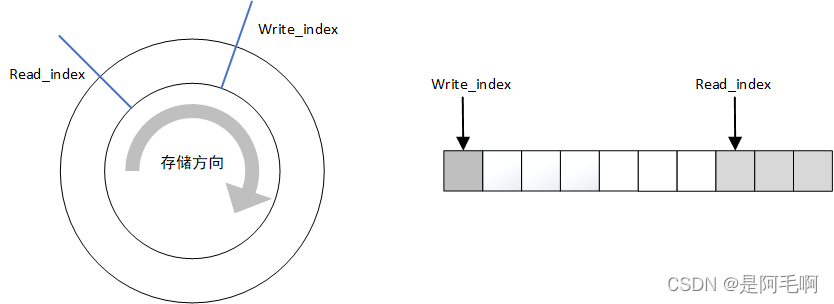
①ringbuffer+读写指针
ringbuffer是一段连续的内存,当末端已经写入数据后,会从头部继续写数据,所以感觉上像一个环,实际是一个循环数组。ringbuffer的缺点也很明显:不能够扩展、对于首尾部分的数据需要增加一次IO调用。
②可扩展的读写缓冲区+读写指针
下图设计了一种可扩展的读写缓冲区,在创建时会分配一块固定大小的内存,整个结构分为预留空间数据空间。预留空间用于存储必要的信息,真正存储数据的空间由连续内存组成。此种缓冲区设计相对于ringbuffer能够扩展,但是也有一定的缺点:由于需要最大化利用空间,会将数据移动至开头,移动操作会降低读写速度。
本文实现可扩展的读写缓冲区+读写指针
2. 数据结构
①Buffer类的设计与初始化
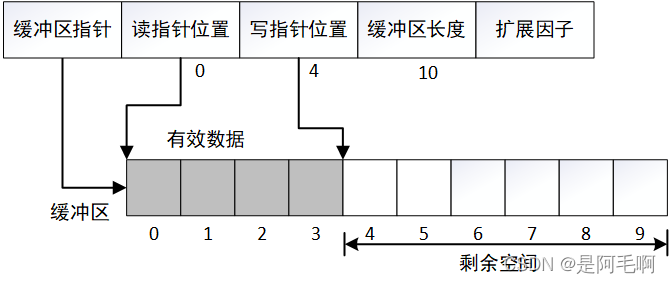
Buffer类的数据结构如下所示,m_s是指向缓冲区的指针,m_max_size是缓冲区的长度,初始设置为10,并根据扩展因子m_expand_par进行倍增。扩展因子m_expand_par设置为2,表示每次扩增长度翻倍,也就是说缓冲区的长度随扩展依次为10、20、40、80。
class Buffer{
public:
Buffer(); //构造
~Buffer();
int init(); //分配缓冲区
private:
char* m_s; //缓冲区指针
size_t m_read_index; //读指针位置
size_t m_write_index; //写指针位置
size_t m_max_size; //缓冲区长度
size_t m_expand_par; //扩展因子
};
构造函数的初始化列表中初始化成员变量。实际初始化缓冲区在init函数中分配内存,大小为m_max_size。不在构造函数中初始化缓冲区的原因是:如果构造函数中分配失败,无法处理,也可使用RAII手段进行处理
Buffer::Buffer()
:m_read_index(0),m_write_index(0),m_max_size(10), m_expand_par(2),m_s(nullptr)
{}
Buffer::~Buffer()
{
delete[] m_s;
}
int Buffer::init()
{
m_s = new char[m_max_size]();
if (m_s == nullptr) {
cout << "分配m_s失败\n";
return -1;
}
return 0;
}
②读写指针的位置变化
当缓冲区为空时,读写指针位置相同都为0。
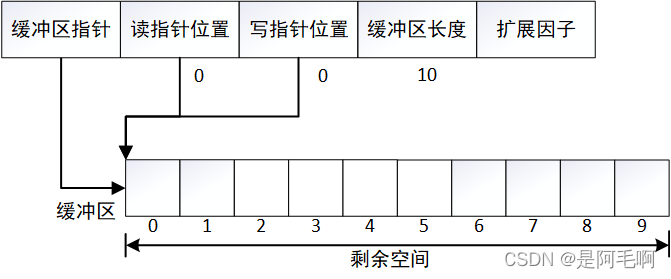
在写入长度为6的数据后,读写指针位置如图
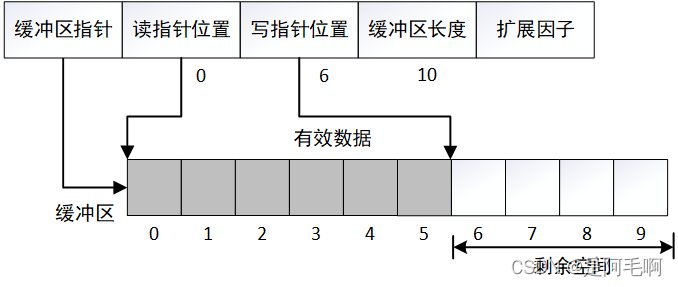
接着读取两个字节后,读写指针如图
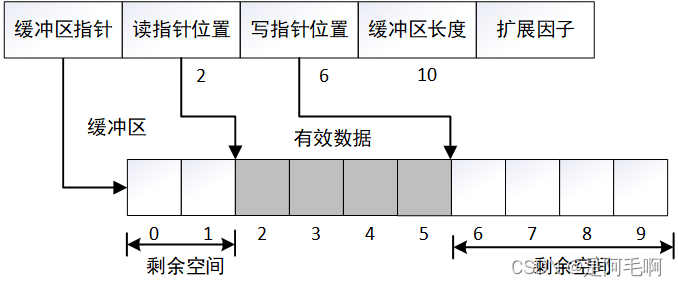
③扩展缓冲区实现
扩展缓冲区实际分为两步,将有效数据前移至缓冲区头(最大化利用数据),再进行扩展。根据成员变量扩展因子m_expand_par的值,将缓冲区按倍数扩大。
假设当前存储数据4个字节,读写指针如下图。需要新增9个字节

将数据前移至缓冲区头
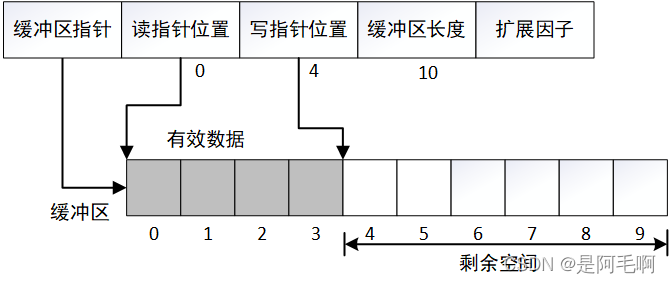
扩展缓冲区为2倍
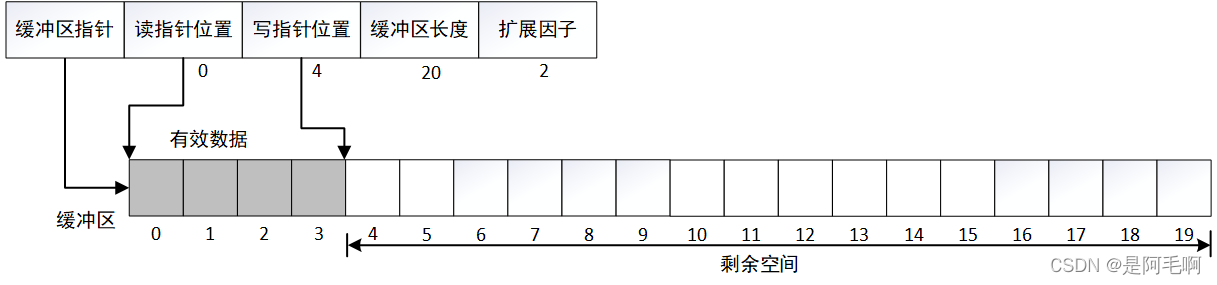
写入9个字节
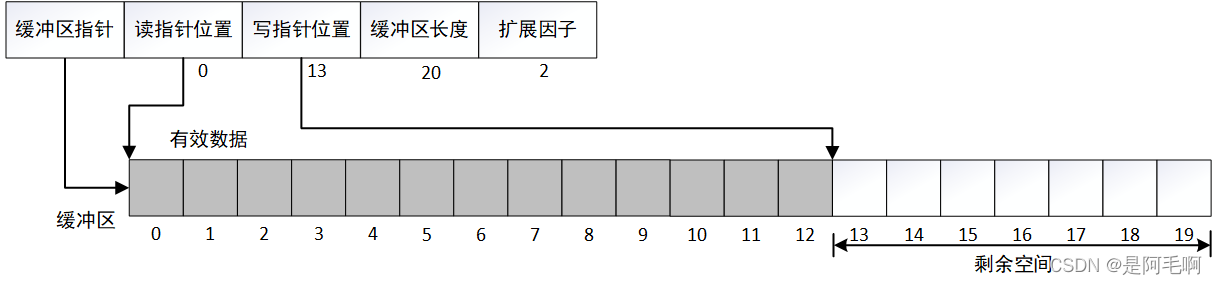
实际需要实现的两个私有成员函数:调整数据位置至缓冲区头adjust_buffer()和扩展expand_buffer(),设置为私有属性则是因为不希望用户调用,仅仅在写入缓冲区前判断不够就进行扩展,用户不应该知道与主动调用。
class Buffer {
public:
...
private:
void adjust_buffer(); //调整数据位置至缓冲区头部头
void expand_buffer(size_t need_size); //扩展缓冲区长度
...
}
adjust_buffer()实现如下,注释写的较为清楚,不再赘述
void Buffer::adjust_buffer()
{
if (m_read_index == 0) //数据已经在头部,直接返回
return;
int used_size = m_write_index - m_read_index;
if (used_size == 0) { //缓冲区为空,重置读写指针
m_write_index = 0;
m_read_index = 0;
}
else {
cout << "调整前read_index write_index" << m_read_index << " " << m_write_index << endl;
memcpy(m_s, &m_s[m_read_index], used_size); //将数据拷贝至头部
m_write_index -= m_read_index; //写指针也前移
cout << "调整了" << used_size << "个字节" << endl;
m_read_index = 0; //读指针置0
}
cout << "调整后read_index write_index" << m_read_index << " " << m_write_index << endl;
}
扩展缓冲区实现如下:
- 首先根据需要写入的字节数判断缓冲区长度多大才能够容下
- 申请新的存储区,并将数据拷贝到新存储区
- 释放旧缓冲区,将新存储区作为缓冲区
void Buffer::expand_buffer(size_t need_size) //need_size需要写入的字节数
{
size_t used_size = m_write_index - m_read_index; //used_size表示已经存储的字节数
size_t remain_size = m_max_size - used_size; //remain_size表示剩余空间
size_t expand_size = m_max_size;
while (remain_size < need_size) { //剩余空间不够时扩展,用while表示直到扩展至够用
expand_size *= m_expand_par;
remain_size = expand_size - used_size;
//cout << "扩展长度中... 总剩余 总长度 " << remain_size << " " << expand_size << endl;
}
char* s1 = new char[expand_size](); //申请新的空间
memcpy(s1, m_s, m_max_size);
free(m_s);
m_s = s1; //将新空间挂载到缓冲区
m_max_size = expand_size; //更新缓冲区总长度
//cout << "扩展结束,总长度为" << m_max_size << endl;
}
3. 外部接口设计与实现
以读缓冲区为例需要提供的接口有:向缓冲区写入数据write_to_buffer(),向缓冲区读取数据read_from_buffer(),得到能够读取的最大字节数readable_bytes()。
class Buffer {
public:
void write_to_buffer(char* src); //从src中写数据
size_t readable_bytes(); //存储数据的字节数
size_t read_from_buffer(char *dst,int bytes); //读数据
size_t pop_bytes(size_t bytes); //丢弃数据
}
① 写入缓冲区write_to_buffer()
write_to_buffer()实现的思路如流程图所示:
判断剩余空间:
剩余空间不够:调整数据至头部、扩展缓冲区
剩余空间足够:向下继续
判断当前空间:
当前空间不够:调整数据至头部
剩余空间足够:向下继续
存储数据
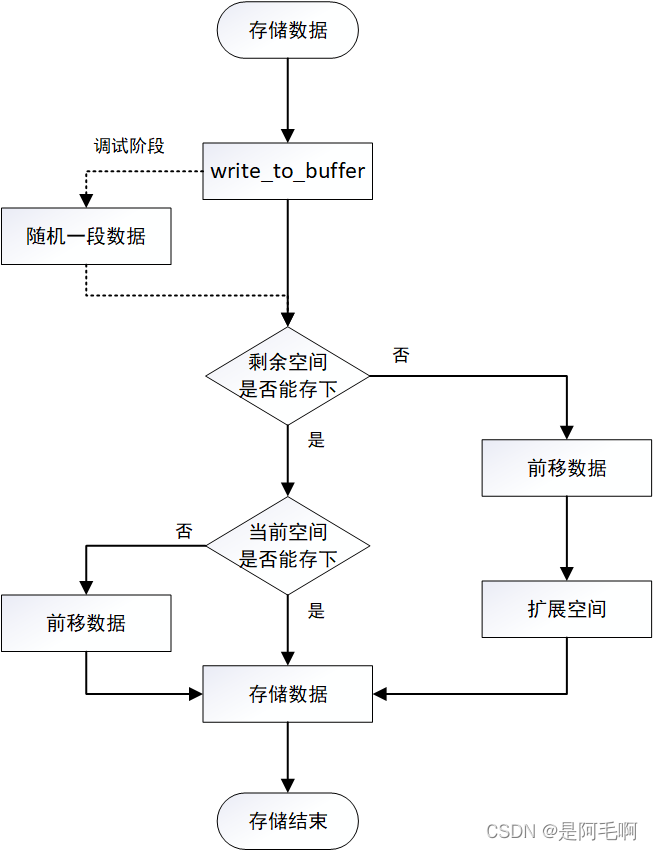
根据流程图实现起来逻辑非常清晰,src表示原始数据
void Buffer::write_to_buffer(char* src)
{
size_t used_size = m_write_index - m_read_index; //used_size表示已经存储的字节数
size_t remain_size = m_max_size - used_size; //remain_size表示剩余空间
size_t cur_size = m_max_size - m_write_index; //cur_size表示当前能够存储的空间
size_t size = init_random_write(&src);
//printf("已经使用%d,剩余总长度%d,剩余当前长度%d\n", used_size, remain_size, cur_size);
if (size > remain_size) { //剩余空间不够
adjust_buffer();
expand_buffer(size);
}
else if (size > cur_size) { //剩余空间够,当前存不下
adjust_buffer();
}
memcpy(&m_s[m_write_index], src, size); //存储数据
m_write_index += size;
delete[] src;
//更新并打印log
//used_size = m_write_index - m_read_index;
//remain_size = m_max_size - used_size;
//cur_size = m_max_size - m_write_index;
//printf("已经使用%d,剩余总长度%d,剩余当前长度%d\n", used_size, remain_size, cur_size);
}
流程图中还出现随机一段数据,这是用来调试的。随机初始化一段长度为0~ 40,字符a~ z的数据,并写缓存区
static int get_random_len() {
return rand() % 40;
}
static int get_random_ala() {
return rand() % 26;
}
size_t Buffer::init_random_write(char** src)
{
int size = get_random_len();
char ala = get_random_ala();
*src = new char[size];
cout << "准备写入的长度为" << size << " 值全是 " << (unsigned char)('a' + ala) << endl;
for (int i = 0; i < size; i++) {
(*src)[i] = 'a' + ala;
}
return size;
}
② 读取缓冲区read_from_buffer()
read_from_buffer(char*dst,int read_size)传入需要拷贝到目的地址和需要读取的字节数,需要注意的是需要读取的字节数为-1表示全部读取,函数返回实际读取的字节数。实现如流程图所示:
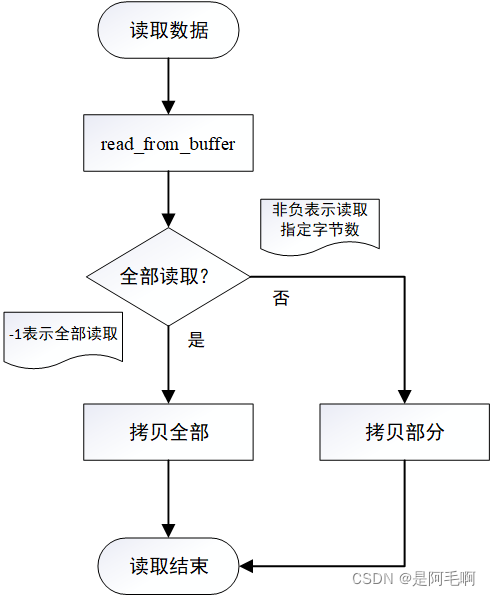
代码如下
size_t Buffer::read_from_buffer(char*dst,int read_size)
{
size_t read_max = m_write_index - m_read_index; //read_max存储的字节数
if (read_size == 0 || read_max == 0) //读取0字节和空缓存区时直接返回
return 0;
if (read_size == -1) { //全读走
memcpy(dst, &m_s[m_read_index], read_max);
m_read_index += read_max;
cout << "读取了" << read_max << "个字节" << endl;
}
else if (read_size > 0) { //读取指定字节
if ((size_t)read_size > read_max)
read_size = read_max;
memcpy(dst, &m_s[m_read_index], read_size);
m_read_index += read_size;
cout << "读取了" << read_size << "个字节" << endl;
}
return read_size; //返回读取的字节数
}
③ 丢弃数据pop_bytes
size_t pop_bytes(size_t size)传入需要丢弃的字节数,需要注意的是需要丢弃的字节数为-1表示全部丢弃;-2表示随机丢弃0~ 40字节,函数返回实际丢弃的字节数。实现如流程图所示:
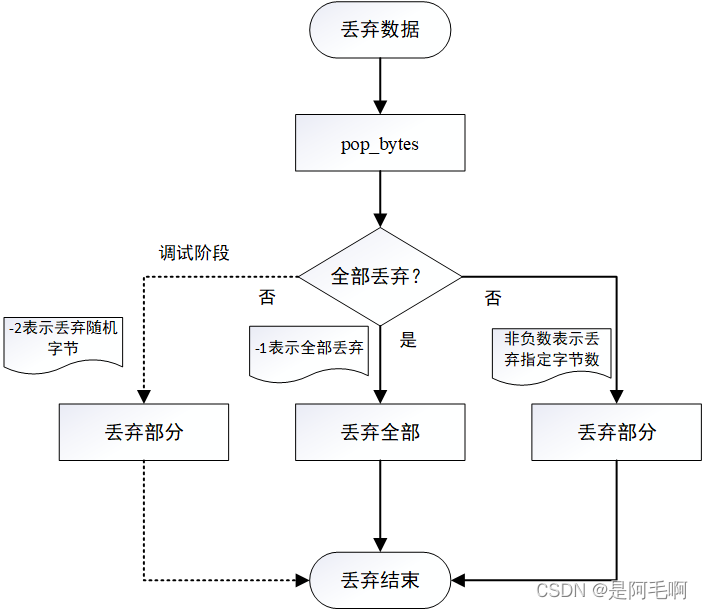
size_t Buffer::pop_bytes(size_t size)
{
size_t read_max = m_write_index - m_read_index; //存储数据长度
//test random
if (size == -2)
size = get_random_len();
if (size == 0 || read_max == 0) //缓冲区为空或丢弃0字节返回
return 0;
if (size == -1) { //全丢
m_read_index += read_max;
cout << "丢弃了" << read_max << "个字节" << endl;
return read_max;
}
if (size > 0) { //丢弃指定字节
if (size > read_max)
size = read_max;
m_read_index += size;
cout << "丢弃了" << size << "个字节" << endl;
}
return size;
}
④ 其他接口
peek_read()和peek_write()返回读写指针的位置
size_t peek_read(); //指向准备读的位置(调试用)
size_t peek_write(); //指向准备写的位置(调试用)
size_t Buffer::peek_write()
{
return m_write_index;
}
size_t Buffer::peek_read()
{
return m_read_index;
}
4. 完整代码与测试
① 完整代码
Buffer.h
#pragma once
class Buffer {
public:
Buffer(); //构造
~Buffer(); //析构
int init(); //分配缓冲区
void write_to_buffer(char* src); //写数据
size_t pop_bytes(size_t bytes); //丢弃数据
size_t read_from_buffer(char *dst,int bytes);//读数据
size_t readable_bytes(); //得到存储数据的字节数
size_t peek_read(); //指向准备读的位置(调试用)
size_t peek_write(); //指向准备写的位置(调试用)
private:
void adjust_buffer(); //调整数据位置至缓冲区头
void expand_buffer(size_t need_size); //扩展缓冲区长度
size_t init_random_write(char** src); //随机初始化一段数据(调试用)
private:
char* m_s; //缓冲区指针
size_t m_read_index; //读指针位置
size_t m_write_index; //写指针位置
size_t m_max_size; //缓冲区长度
size_t m_expand_par; //扩展因子
};
Buffer.cpp:
#include "Buffer.h"
#include<iostream>
#include<time.h>
using namespace std;
int total_write = 0; //记录总写入
int total_read = 0; //记录总读取
static int get_random_len() {
return rand() % 40;
}
static int get_random_ala() {
return rand() % 26;
}
Buffer::Buffer()
:m_read_index(0),m_write_index(0),m_max_size(10), m_expand_par(2),m_s(nullptr)
{}
Buffer::~Buffer()
{
delete[] m_s;
}
int Buffer::init()
{
m_s = new char[m_max_size]();
if (m_s == nullptr) {
cout << "分配m_s失败\n";
return -1;
}
return 0;
}
size_t Buffer::read_from_buffer(char*dst,int read_size)
{
size_t read_max = m_write_index - m_read_index; //read_max存储的字节数
if (read_size == 0 || read_max == 0) //读取0字节和空缓存区时直接返回
return 0;
if (read_size == -1) { //全读走
memcpy(dst, &m_s[m_read_index], read_max);
m_read_index += read_max;
printf("读取完成:\t读取%d个字节\n", read_max);
total_read += read_max;
}
else if (read_size > 0) { //读取指定字节
if ((size_t)read_size > read_max)
read_size = read_max;
memcpy(dst, &m_s[m_read_index], read_size);
m_read_index += read_size;
printf("读取完成:\t读取%d个字节\n", read_size);
total_read += read_size;
}
return read_size; //返回读取的字节数
}
size_t Buffer::readable_bytes()
{
return m_write_index - m_read_index;
}
size_t Buffer::peek_write()
{
return m_write_index;
}
size_t Buffer::peek_read()
{
return m_read_index;
}
void Buffer::write_to_buffer(char* src)
{
size_t used_size = m_write_index - m_read_index; //used_size表示已经存储的字节数
size_t remain_size = m_max_size - used_size; //remain_size表示剩余空间
size_t cur_size = m_max_size - m_write_index; //cur_size表示当前能够存储的空间
size_t size = init_random_write(&src);
//printf("已经使用%d,剩余总长度%d,剩余当前长度%d\n", used_size, remain_size, cur_size);
if (size > remain_size) { //剩余空间不够
adjust_buffer();
expand_buffer(size);
}
else if (size > cur_size) { //剩余空间够,当前存不下
adjust_buffer();
}
memcpy(&m_s[m_write_index], src, size); //存储数据
m_write_index += size;
delete[] src;
//更新并打印log
used_size = m_write_index - m_read_index;
remain_size = m_max_size - used_size;
cur_size = m_max_size - m_write_index;
printf("写入完成:\t总存储%d,剩余空间%d,剩余当前空间%d\n", used_size, remain_size, cur_size);
}
size_t Buffer::pop_bytes(size_t size)
{
size_t read_max = m_write_index - m_read_index; //存储数据长度
//test random
if (size == -2)
size = get_random_len();
if (size == 0 || read_max == 0) //缓冲区为空或丢弃0字节返回
return 0;
if (size == -1) { //全丢
m_read_index += read_max;
cout << "丢弃了" << read_max << "个字节" << endl;
total_read += read_max;
return read_max;
}
if (size > 0) { //丢弃指定字节
if (size > read_max)
size = read_max;
m_read_index += size;
cout << "丢弃了" << size << "个字节" << endl;
total_read += size;
}
return size;
}
size_t Buffer::init_random_write(char** src)
{
int size = get_random_len();
total_write += size;
*src = new char[size];
char ala = get_random_ala();
cout << "随机写入:\t长度为" << size << " 值全是 " << (unsigned char)('a' + ala) << endl;
for (int i = 0; i < size; i++) {
(*src)[i] = 'a' + ala;
}
return size;
}
void Buffer::adjust_buffer()
{
if (m_read_index == 0) //数据已经在头部,直接返回
return;
int used_size = m_write_index - m_read_index;
if (used_size == 0) { //缓冲区为空,重置读写指针
m_write_index = 0;
m_read_index = 0;
}
else {
cout << "调整前read_index write_index" << m_read_index << " " << m_write_index << endl;
memcpy(m_s, &m_s[m_read_index], used_size); //将数据拷贝至头部
m_write_index -= m_read_index; //写指针也前移
cout << "调整了" << used_size << "个字节" << endl;
m_read_index = 0; //读指针置0
}
cout << "调整后read_index write_index" << m_read_index << " " << m_write_index << endl;
}
void Buffer::expand_buffer(size_t need_size) //need_size需要写入的字节数
{
size_t used_size = m_write_index - m_read_index; //used_size表示已经存储的字节数
size_t remain_size = m_max_size - used_size; //remain_size表示剩余空间
size_t expand_size = m_max_size;
while (remain_size < need_size) { //剩余空间不够时扩展,用while表示直到扩展至够用
expand_size *= m_expand_par;
remain_size = expand_size - used_size;
cout << "扩展长度中... 总剩余 总长度 " << remain_size << " " << expand_size << endl;
}
char* s1 = new char[expand_size](); //申请新的空间
memcpy(s1, m_s, m_max_size);
free(m_s);
m_s = s1; //将新空间挂载到缓冲区
m_max_size = expand_size; //更新缓冲区总长度
cout << "扩展结束,总长度为" << m_max_size << endl;
}
② 测试
int main() {
srand((unsigned)time(NULL)); //调试需要初始化随机种子
Buffer* pbuffer = new Buffer(); //创建Buffer对象
if (pbuffer->init() != 0) //init函数分配缓冲区
return 0;
{
char* s = nullptr; //s是指向随机数据的指针
char* read = new char[1000]; //读取时将数据存储到的指针read
size_t read_size = 0; //本次读取到的字节数
pbuffer->write_to_buffer(s);
read_size = pbuffer-> read_from_buffer(read, -1);
pbuffer->write_to_buffer(s);
pbuffer->pop_bytes(-2);
read_size = read_size = pbuffer-> read_from_buffer(read, 0);
pbuffer->write_to_buffer(s);
cout << "总写入\t" << total_write << endl;;
cout << "总读取\t" << total_read << endl;
cout << "目前写入" << total_write - total_read << endl;
cout << "可读取\t" << pbuffer->readable_bytes()<< endl;
printf(" write %d read %d \n", pbuffer->peek_write(),pbuffer->peek_read());
if (total_write - total_read != pbuffer->readable_bytes()) { //根据总写入-总读取和一共存储的字节数判断是否存储正确
cout << "error!!!" << endl;
}
else
cout << "test is ok\n\n\n";
}
delete s;
delete[] read;
delete pbuffer;
return 0;
}
随机1000000次测试
int main() {
srand((unsigned)time(NULL)); //调试需要初始化随机种子
Buffer* pbuffer = new Buffer(); //创建Buffer对象
if (pbuffer->init() != 0) //init函数分配缓冲区
return 0;
char* s = nullptr; //s是指向随机数据的指针
char* read = new char[1000]; //读取时将数据存储到的指针read
size_t read_size = 0; //本次读取到的字节数
unsigned long long time = 0; //调试的循环次数
while (1) {
pbuffer->write_to_buffer(s);
read_size = pbuffer-> read_from_buffer(read, -1);
pbuffer->write_to_buffer(s);
pbuffer->write_to_buffer(s);
pbuffer->pop_bytes(-2);
read_size = read_size = pbuffer-> read_from_buffer(read, 0);
pbuffer->write_to_buffer(s);
pbuffer->pop_bytes(-2);
pbuffer->write_to_buffer(s);
read_size = pbuffer-> read_from_buffer(read, -1);
pbuffer->write_to_buffer(s);
pbuffer->write_to_buffer(s);
read_size = pbuffer-> read_from_buffer(read, 22);
pbuffer->write_to_buffer(s);
pbuffer->write_to_buffer(s);
read_size = pbuffer-> read_from_buffer(read, -1);
pbuffer->pop_bytes(-2);
pbuffer->pop_bytes(-2);
pbuffer->write_to_buffer(s);
pbuffer->write_to_buffer(s);
read_size = pbuffer-> read_from_buffer(read, 2);
pbuffer->write_to_buffer(s);
read_size = pbuffer-> read_from_buffer(read, 17);
pbuffer->write_to_buffer(s);
pbuffer->pop_bytes(-2);
pbuffer->write_to_buffer(s);
pbuffer->write_to_buffer(s);
pbuffer->read_from_buffer(read, 18);
cout << "总写入\t" << total_write << endl;;
cout << "总读取\t" << total_read << endl;
cout << "目前写入" << total_write - total_read << endl;
cout << "可读取\t" << pbuffer->readable_bytes()<< endl;
printf(" write %d read %d \n", pbuffer->peek_write(),pbuffer->peek_read());
if (total_write - total_read != pbuffer->readable_bytes()) { //根据总写入-总读取和一共存储的字节数判断是否存储正确
cout << "error!!!" << endl;
break;
}
if (time == 1000000) //循环1000000次
{
cout << "1000000 ok!!!" << endl;
break;
}
cout << time++ << " is ok\n\n\n";
}
delete s;
delete[] read;
delete pbuffer;
return 0;
}
到此这篇关于c++实现一个简易的网络缓冲区的实践的文章就介绍到这了,更多相关c++ 网络缓冲区内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

浅谈C++ 缓冲区(buffer)的使用
缓冲区 缓冲区 (buffer) 是内存空间的一部分. 在内存中会为每一个数据流开辟一个内存缓冲区. 缓冲区是用来存放流中的数据, 缓冲区中的数据就是流. 在 C++ 中, 输入输出流被定义为类, C++ 的 I/O 库中的类称为流类 (stream class). cout 和 cin 是 iostream 流类中的流对象. 为什么要引入缓冲区 我们为什么要引入缓冲区呢? 比如我们从磁盘里取信息,我们先把读出的数据放在缓冲区,计算机再直接从缓冲区中取数据,等缓冲区的数据取完后再去磁盘中读取,这
-
C++字符串输入缓冲区机制详解
目录 一.缓冲定义 1.缓冲定义 2.为什么引入缓冲区 二.scanf,cin输入缓冲区 1.scanf和cin的缓冲类型 2.scanf和cin的缓冲机制 3.cin.getline和cin.get 4.scanf和cin输入 5.可能遇到的问题 总结 一.缓冲定义 1.缓冲定义 缓冲是在两种不同速度设备之间传输信息时平滑传输过程的常用手段. 2.为什么引入缓冲区 操作系统这门课有明确的说明缓冲的作用,是为了解决高速设备和低速设备之间速度不匹配的问题,直接举个书上的CPU和打印机的例子: 首先
-
c++实现一个简易的网络缓冲区的实践
目录 1. 前言 2. 数据结构 3. 外部接口设计与实现 4. 完整代码与测试 1. 前言 请思考以下几个问题: 1).为什么需要设计网络缓冲区,内核中不是有读写缓冲区吗? 需要设计的网络缓冲区和内核中TCP缓冲区的关系如下图所示,通过socket进行进行绑定.具体来说网络缓冲区包括读(接收)缓冲区和写(发送)缓冲区.设计读缓冲区的目的是:当从TCP中读数据时,不能确定读到的是一个完整的数据包,如果是不完整的数据包,需要先放入缓冲区中进行缓存,直到数据包完整才进行业务处理.设计写缓冲区的目的是
-
webpack5搭建一个简易的react脚手架项目实践
目录 项目初始化 安装webpack 搭建脚手架目录结构 开启本地服务 配置css&sass 安装react的相关依赖 项目添加热更新 生产环境打包 总结 项目初始化 首先我们创建一个目录,初始化 npm,得到一个package.json文件. mkdir react-cli cd react-cli npm init -y 安装webpack 安装webpack和相关依赖.webpack-dev-server是开启开发环境的服务,webpack-merge是合并公共配置文件. npm inst
-
C++实现简易UDP网络聊天室
本文实例为大家分享了C++实现简易UDP网络聊天室的具体代码,供大家参考,具体内容如下 工程名:NetSrv NetSrv.cpp //服务器端 #include<Winsock2.h> #include<stdio.h> void main() { //加载套接字库 WORD wVersionRequested; WSADATA wsaData; int err; wVersionRequested = MAKEWORD(1,1); err = WSAStartup(wVersi
-
Java实现一个简易聊天室流程
目录 文件传输 Tcp方式 Udp 方式 简易聊天室的实现 接收端 发送端 启动 说到网络,相信大家都对TCP.UDP和HTTP协议这些都不是很陌生,学习这部分应该先对端口.Ip地址这些基础知识有一定了解,后面我们都是直接上demo来解释代码 文件传输 Tcp方式 这里我们指的是C/S架构的文件传输,需要涉及一个客户端Client和服务器端(Server),这里采用的是TCP协议进行传输的,TCP需要经过三次握手和四次挥手,需要注意的是Client上传文件我们需要告诉服务器,我已经传输完成了so
-
教你使用Python实现一个简易版Web服务器
目录 一.简介 二.Web服务器基础概念 三.Python网络编程库 四.实现简易Web服务器 1.使用socket库创建服务器套接字. 2.绑定服务器IP地址和端口. 3.监听客户端连接. 4.接受客户端连接并处理请求. 五.处理HTTP请求 六.返回静态文件 1.根据请求URL读取文件内容. 2.根据文件内容构建HTTP响应. 七.测试与优化 八.总结及拓展 九.补充:多线程处理客户端请求 一.修改处理客户端请求的函数 二.使用多线程处理客户端请求 三.完整的多线程Web服务器代码 一.简介
-
JavaScript编写一个简易购物车功能
网上关于购物车实现的代码非常多,今天看了一些知识点,决定自己动手写写,于是写了一个简易购物车,接下来讲解一下具体的实现. 1.用html实现内容: 2.用css修饰外观: 3.用js(jq)设计动效. 第一步:首先是进行html页面的设计,我用一个大的div将所有商品包含,然后用不同的div将不同的商品进行封装,商品列表中我用了ul li实现,具体实现代码如下(代码中涉及到的商品都是网上随便copy的,不具有参考价值): <div id="goods"> <div c
-
vue + socket.io实现一个简易聊天室示例代码
vue + vuex + elementUi + socket.io实现一个简易的在线聊天室,提高自己在对vue系列在项目中应用的深度.因为学会一个库或者框架容易,但要结合项目使用一个库或框架就不是那么容易了.功能虽然不多,但还是有收获.设计和实现思路较为拙劣,恳请各位道友指正. 可以达到的需求 能查看在线用户列表 能发送和接受消息 使用到的框架和库 socket.io做为实时通讯基础 vuex/vue:客户端Ui层使用 Element-ui:客户端Ui组件 类文件关系图 服务端: 客户端: 服
-
AngularJs篇:使用AngularJs打造一个简易权限系统的实现代码
一.引言 上一篇博文已经向大家介绍了AngularJS核心的一些知识点,在这篇博文将介绍如何把AngularJs应用到实际项目中.本篇博文将使用AngularJS来打造一个简易的权限管理系统.下面不多说,直接进入主题. 二.整体架构设计介绍 首先看下整个项目的架构设计图: 从上图可以看出整个项目的一个整体结构,接下来,我来详细介绍了项目的整体架构: 采用Asp.net Web API来实现REST 服务.这样的实现方式,已达到后端服务的公用.分别部署和更好地扩展.Web层依赖应用服务接口,并且使
-
基于python的Tkinter实现一个简易计算器
本文实例介绍了基于python的Tkinter实现简易计算器的详细代码,分享给大家供大家参考,具体内容如下 第一种:使用python 的 Tkinter实现一个简易计算器 #coding:utf-8 from Tkinter import * import time root = Tk() def cacl(input_str): if "x" in input_str: ret = input_str.split("x") return int(ret[0]) *
-
从零学习node.js之简易的网络爬虫(四)
前言 之前已经介绍了node.js的一些基本知识,下面这篇文章我们的目标是学习完本节课程后,能进行网页简单的分析与抓取,对抓取到的信息进行输出和文本保存. 爬虫的思路很简单: 确定要抓取的URL: 对URL进行抓取,获取网页内容: 对内容进行分析并存储: 重复第1步 在这节里做爬虫,我们使用到了两个重要的模块: request : 对http进行封装,提供更多.更方便的接口供我们使用,request进行的是异步请求.更多信息可以去这篇文章上进行查看 cheerio : 类似于jQuery,可以使