Python抓取今日头条街拍图片数据
目录
- (1)抓取今日头条街拍图片
- (2)分析今日头条街拍图片结构
- (3)按功能不同编写不同方法组织代码
- (4)抓取20page今日头条街拍图片数据
(1)抓取今日头条街拍图片
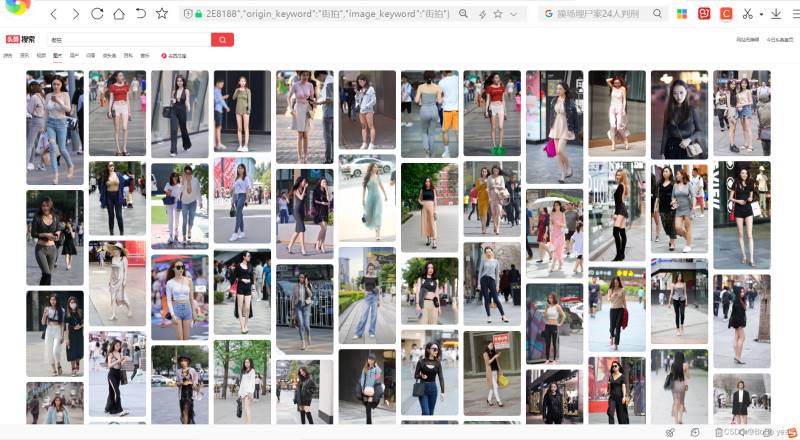
(2)分析今日头条街拍图片结构
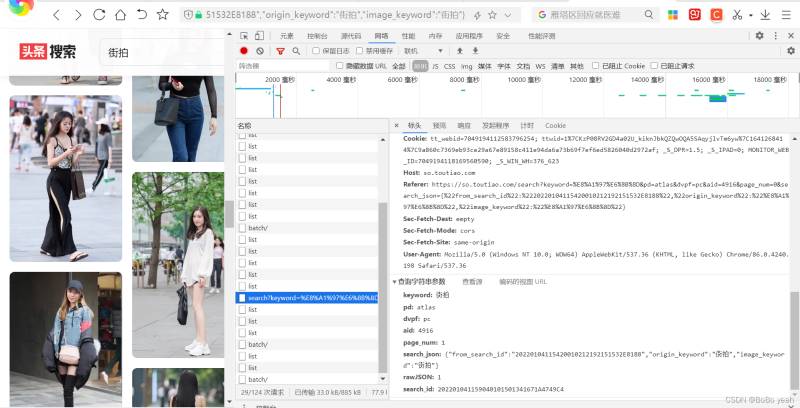
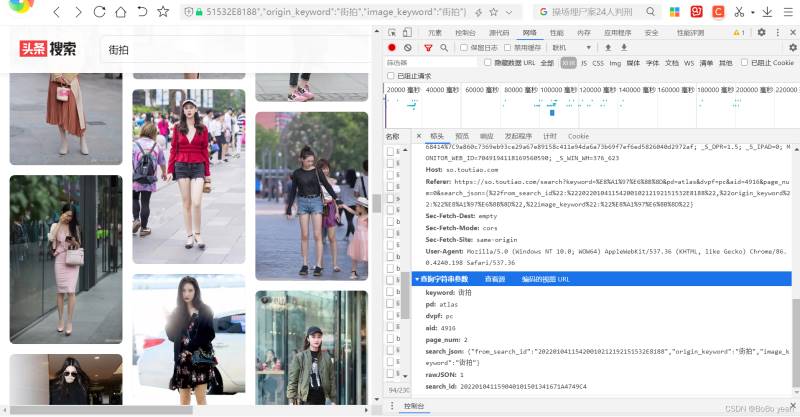
keyword: 街拍
pd: atlas
dvpf: pc
aid: 4916
page_num: 1
search_json: {"from_search_id":"20220104115420010212192151532E8188","origin_keyword":"街拍","image_keyword":"街拍"}
rawJSON: 1
search_id: 202201041159040101501341671A4749C4
可以找到规律,page_num从1开始累加,其他参数不变
(3)按功能不同编写不同方法组织代码
获取网页json格式数据
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search?keyword=%E8%A1%97%E6%8B%8D&pd=atlas&dvpf=pc&aid=4916&page_num=0&search_json={%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
从json格式数据提取街拍图片
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
将街拍图片以其md5码命名并保存图片
实现一个保存图片的方法 save_image(),其中 item 就是前面 get_images() 方法返回的一个字典。在该方法中,首先根据 item 的 title 来创建文件夹,然后请求这个图片链接,获取图片的二进制数据,以二进制的形式写入文件。图片的名称可以使用其内容的 MD5 值,这样可以去除重复。相关代码如下:
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
main()调用其他函数
def main(page_num):
json = get_page(page_num)
for link in get_images(json):
#print(link)
save_image(link)
(4)抓取20page今日头条街拍图片数据
这里定义了分页的起始页数和终止页数,分别为 GROUP_START 和 GROUP_END,还利用了多线程的线程池,调用其 map() 方法实现多线程下载。
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()
import requests
from urllib.parse import urlencode
from hashlib import md5
from multiprocessing.pool import Pool
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search?keyword=%E8%A1%97%E6%8B%8D&pd=atlas&dvpf=pc&aid=4916&page_num=0&search_json={%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
def main(page_num):
json = get_page(page_num)
for link in get_images(json):
#print(link)
save_image(link)
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()

到此这篇关于Python抓取今日头条街拍图片数据的文章就介绍到这了,更多相关Python抓取今日头条图片内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python基于分析Ajax请求实现抓取今日头条街拍图集功能示例
本文实例讲述了Python基于分析Ajax请求实现抓取今日头条街拍图集功能.分享给大家供大家参考,具体如下: 代码: import os import re import json import time from hashlib import md5 from multiprocessing import Pool import requests from requests.exceptions import RequestException from pymongo import Mongo
-
Python抓取今日头条街拍图片数据
目录 (1)抓取今日头条街拍图片 (2)分析今日头条街拍图片结构 (3)按功能不同编写不同方法组织代码 (4)抓取20page今日头条街拍图片数据 (1)抓取今日头条街拍图片 (2)分析今日头条街拍图片结构 keyword: 街拍 pd: atlas dvpf: pc aid: 4916 page_num: 1 search_json: {"from_search_id":"20220104115420010212192151532E8188","orig
-
python抓取网页中图片并保存到本地
在上篇文章给大家分享PHP源码批量抓取远程网页图片并保存到本地的实现方法,感兴趣的朋友可以点击了解详情. #-*-coding:utf-8-*- import os import uuid import urllib2 import cookielib '''获取文件后缀名''' def get_file_extension(file): return os.path.splitext(file)[1] '''創建文件目录,并返回该目录''' def mkdir(path): # 去除左右两边的
-
Python学习笔记之抓取某只基金历史净值数据实战案例
本文实例讲述了Python抓取某只基金历史净值数据.分享给大家供大家参考,具体如下: http://fund.eastmoney.com/f10/jjjz_519961.html 1.接下来,我们需要动手把这些html抓取下来(这部分知识我们之前已经学过,现在不妨重温) # coding: utf-8 from selenium.webdriver.support.ui import WebDriverWait from selenium import webdriver from bs4 im
-
python抓取网页图片并放到指定文件夹
python抓取网站图片并放到指定文件夹 复制代码 代码如下: # -*- coding=utf-8 -*-import urllib2import urllibimport socketimport osimport redef Docment(): print u'把文件存在E:\Python\图(请输入数字或字母)' h=raw_input() path=u'E:\Python\图'+str(h) if not os.path.exists(path):
-
python抓取网页中链接的静态图片
本文实例为大家分享了python抓取网页中链接的静态图片的具体代码,供大家参考,具体内容如下 # -*- coding:utf-8 -*- #http://tieba.baidu.com/p/2460150866 #抓取图片地址 from bs4 import BeautifulSoup import urllib.request from time import sleep html_doc = "http://tieba.baidu.com/p/2460150866" def ge
-
python抓取网站的图片并下载到本地的方法
实例如下所示: #!/usr/bin/python # -*- coding: UTF-8 -*- import re import urllib,urllib2; #通过url获取网页 def getHtml(url): # 要设置请求头,让服务器知道不是机器人 user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' headers = {'User-Agent': user_agent} request=urllib2.Re
-
python抓取并保存html页面时乱码问题的解决方法
本文实例讲述了python抓取并保存html页面时乱码问题的解决方法.分享给大家供大家参考,具体如下: 在用Python抓取html页面并保存的时候,经常出现抓取下来的网页内容是乱码的问题.出现该问题的原因一方面是自己的代码中编码设置有问题,另一方面是在编码设置正确的情况下,网页的实际编码和标示的编码不符合造成的.html页面标示的编码在这里: 复制代码 代码如下: <meta http-equiv="Content-Type" content="text/html;
-
Python抓取框架Scrapy爬虫入门:页面提取
前言 Scrapy是一个非常好的抓取框架,它不仅提供了一些开箱可用的基础组建,还能够根据自己的需求,进行强大的自定义.本文主要给大家介绍了关于Python抓取框架Scrapy之页面提取的相关内容,分享出来供大家参考学习,下面随着小编来一起学习学习吧. 在开始之前,关于scrapy框架的入门大家可以参考这篇文章:http://www.jb51.net/article/87820.htm 下面创建一个爬虫项目,以图虫网为例抓取图片. 一.内容分析 打开 图虫网,顶部菜单"发现" "
-
Python抓取聚划算商品分析页面获取商品信息并以XML格式保存到本地
本文实例为大家分享了Android九宫格图片展示的具体代码,供大家参考,具体内容如下 #!/user/bin/python # -*- coding: gbk -*- #Spider.py import urllib2 import httplib import StringIO import gzip import re import chardet import sys import os import datetime from xml.dom.minidom import Documen