python爬虫实战之制作属于自己的一个IP代理模块
一、使用PyChram的正则
首先,小编讲的不是爬取ip,而是讲了解PyCharm的正则,这里讲的正则不是Python的re模块哈!
而是PyCharm的正则功能,我们在PyChram的界面上按上Ctrl+R,可以发现,这里出现两行输入框

现在如果小编想把如下数据转换成一个字典存储
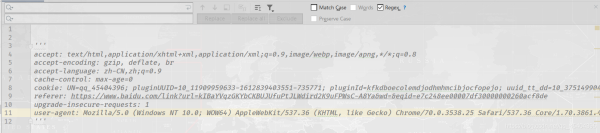
读者也许会一个一去改,但是小编只需在上述的那两个输入框内,输入一串字符串即可。

只需在第一个输入框中,输入(.*) : (.*)
在第二个输入框中,输入"$1":"$2",,看看效果如何

之后再给两端分别一个花括号和取一个字典名称即可。
二、制作一个随机User-Agent模块
反爬措施中,有这样一条,就是服务器会检查请求的user-agent参数值,如果检查的结果为python,那么服务器就知道这是爬虫,为了避免被服务器发现这是爬虫,通常user-agent参数值会设置浏览器的值,但是爬取一个网址时,每次都需要查看网址network下面的内容,显得比较繁琐,为什么不自定义一个随机获取user-agent的值模块呢?这样既可以减少查看network带来的繁琐,同时还可以避免服务器发现这是同一个user-agent发起多次请求。
说了这么多,那么具体怎样实现呢?

只需调用随机模块random的方法choice()即可,这个方法里面的参数类型时列表类型,具体参考代码如下:
import random
class useragent(object):
def getUserAgent(self):
useragents=[
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 2.0.50727; SLCC2; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; Tablet PC 2.0; .NET4.0E)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)',
]
return random.choice(useragents)
这样我们就可以随机得到一个user-agent的值了。
三、最终实践
3.1 爬取快代理上的ip
接下来,就是最终实践了,制作属于自己的IP代理模块。
那么,从哪里获取IP呢?小编用的是快代理这个网址,网址链接为:https://www.kuaidaili.com/free/inha/1/。
怎样提取IP呢?小编用的是xpath语法
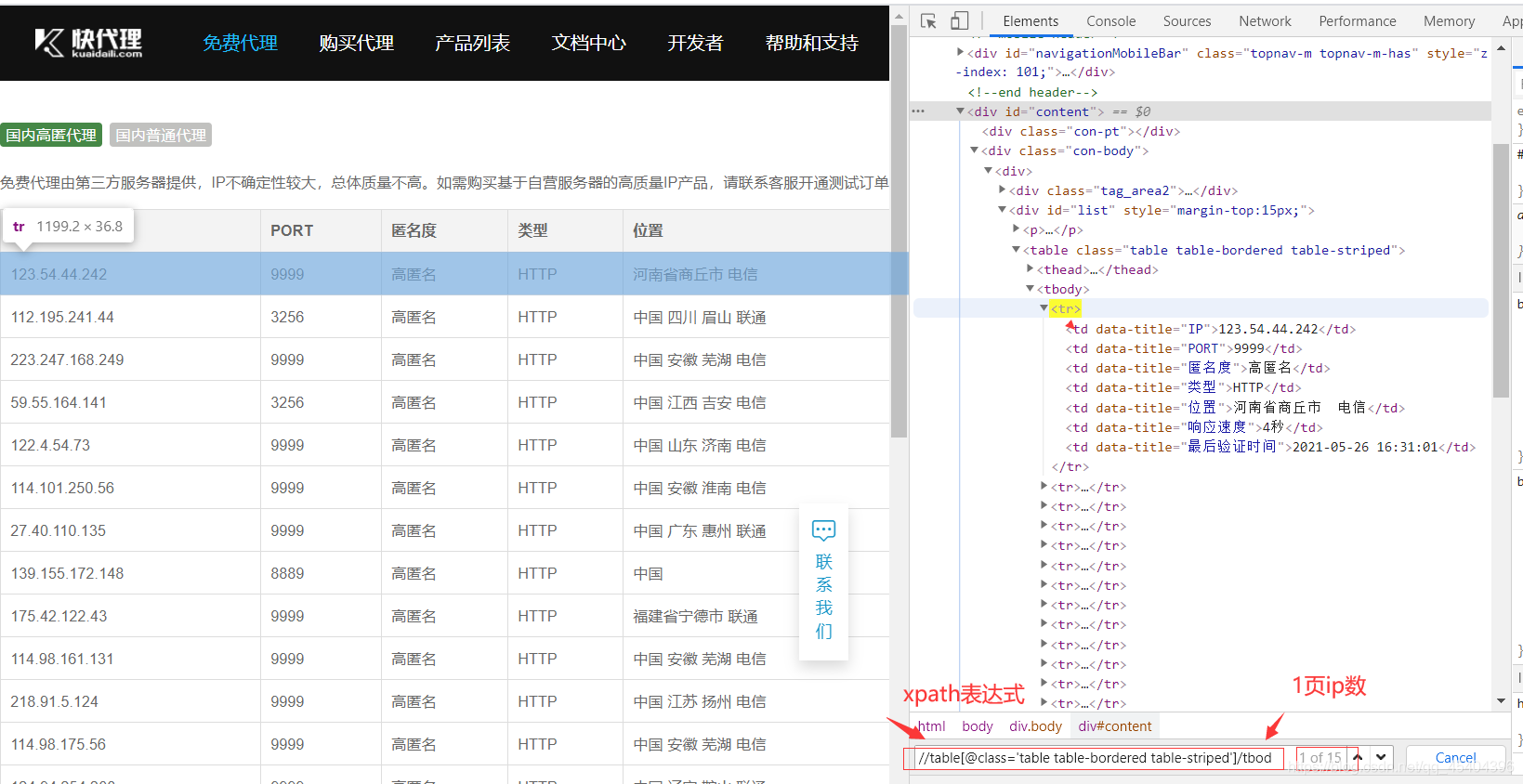
参考代码如下:
import requests
from crawlers.userAgent import useragent # 导入自己自定义的类,主要作用为随机取user-agent的值
from lxml import etree
url='https://www.kuaidaili.com/free/inha/1/'
headers={'user-agent':useragent().getUserAgent()}
rsp=requests.get(url=url,headers=headers)
HTML=etree.HTML(rsp.text)
infos=HTML.xpath("//table[@class='table table-bordered table-striped']/tbody/tr")
for info in infos:
print(info.xpath('./td[1]/text()')) # ip
print(info.xpath('./td[2]/text()')) # ip对应的端口 列表类型
怎样爬取多页呢?分析快代理那个网址,可以发现https://www.kuaidaili.com/free/inha/{页数}/ ,花括号里面就是页数,这个网址总页数为4038,这里小编只爬取5页,并且开始页数取(1,3000)之间的随机数,但是如果for循环这个过程,运行结果如下:

原来是请求过快的原因,只需在爬取1页之后,休眠几秒钟即可解决。
3.2 验证爬取到的ip是否可用
这里直接用百度这个网址作为测试网址,主要代码为:
url='https://www.baidu.com'
headers={'user-agent':useragent().getUserAgent()}
proxies={} # ip ,这里只是讲一下关键代码,没有给出具体IP
rsp=requests.get(url=url,headers=headers,proxies=proxies,time=0.2) # timeout为超时时间
只需判断rsp的状态码为200,如果是,把它添加到一个指定的列表中。
具体参考代码小编已经上传到Gitee上,链接为:ip代理模块
当然读者可用把这个文件保存到python\Lib文件夹下面,这样就可用随时随地导入了。
3.3 实战:利用爬取到的ip访问CSDN博客网址1000次
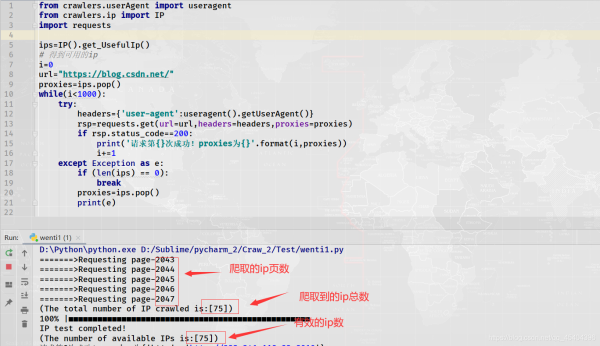


上述出现那个错误,小编上网搜索了一下原因,如下:

我想应该是第1种原因,ip被封,我这里没有设置超时时间,应该不会出现程序请求速度过快。
四、总结
上述那个ip代理模块还有很多的不足点,比如用它去访问一些网址时,不管运行多少次,输出的结果状态码不会时200,这也正常,毕竟免费的ip并不是每个都能用的。如果要说改进的话,就是多爬取几个不同ip代理网址,去重,这样的结果肯定会比上述的那个ip代理模块要好
到此这篇关于python爬虫实战之制作属于自己的一个IP代理模块的文章就介绍到这了,更多相关Python IP代理模块内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python3 Scrapy爬虫框架ip代理配置的方法
什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性的项目模板.对于框架的学习,重点是要学习其框架的特性.各个功能的用法即可. 一.背景 在做爬虫项目的过程中遇到ip代理的问题,网上搜了一些,要么是用阿里云的ip代理,要么是搜一些网上现有的ip资源,然后配置在setting文件中.这两个方法都存在一些问题. 1.阿里云ip代理方法,网上大
-
python如何基于redis实现ip代理池
这篇文章主要介绍了python如何基于redis实现ip代理池,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 使用apscheduler库定时爬取ip,定时检测ip删除ip,做了2层检测,第一层爬取后放入redis--db0进行检测,成功的放入redis--db1再次进行检测,确保获取的代理ip的可用性 import requests, redis import pandas import random from apscheduler.sch
-
Python爬虫动态ip代理防止被封的方法
在爬取的过程中难免发生ip被封和403错误等等,这都是网站检测出你是爬虫而进行反爬措施,在这里为大家总结一下怎么用IP代理防止被封 首先,设置等待时间: 常见的设置等待时间有两种,一种是显性等待时间(强制停几秒),一种是隐性等待时间(看具体情况,比如根据元素加载完成需要时间而等待)图1是显性等待时间设置,图2是隐性 第二步,修改请求头: 识别你是机器人还是人类浏览器浏览的重要依据就是User-Agent,比如人类用浏览器浏览就会使这个样子的User-Agent:'Mozilla/5.0 (Win
-
python单例模式获取IP代理的方法详解
引言 最近在学习python,先说一下我学Python得原因,一个是因为它足够好用,完成同样的功能,代码量会比其他语言少很多,有大量的丰富的库可以使用,基本上前期根本不需要自己造什么轮子.第二个是因为目前他很火,网上各种资料都比较丰富,且质量尚可.接下来不如正题 在学习Python爬虫的时候,经常会遇见所要爬取的网站采取了反爬取技术导致爬取失败.高强度.高效率地爬取网页信息常常会给网站服务器带来巨大压力,所以同一个IP反复爬取同一个网页,就很可能被封,这里讲述一个爬虫技巧,设置代理IP 为什么需
-
python3 requests中使用ip代理池随机生成ip的实例
啥也不说了,直接上代码吧! # encoding:utf-8 import requests # 导入requests模块用于访问测试自己的ip import random pro = ['1.119.129.2:8080', '115.174.66.148', '113.200.214.164'] # 在(http://www.xicidaili.com/wt/)上面收集的ip用于测试 # 没有使用字典的原因是 因为字典中的键是唯一的 http 和https 只能存在一个 所以不建议使用字典
-
Python爬虫设置ip代理过程解析
1.get方式:如何为爬虫添加ip代理,设置Request header(请求头) import urllib import urllib.request import urllib.parse import random import time from fake_useragent import UserAgent ua = UserAgent() url = "http://www.baidu.com" ######################################
-
python利用proxybroker构建爬虫免费IP代理池的实现
前言 写爬虫的小伙伴可能遇到过这种情况: 正当悠闲地喝着咖啡,满意地看着屏幕上的那一行行如流水般被爬下来的数据时,突然一个Error弹出,提示抓不到数据了... 然后你反复检查,确信自己代码莫得问题之后,发现居然连浏览器也无法正常访问网页了... 难道是网站被我爬瘫痪了? 然后你用手机浏览所爬网站,惊奇地发现居然能访问! 才原来我的IP被网站给封了,拒绝了我的访问 这时只能用IP代理来应对禁IP反爬策略了,但是网上高速稳定的代理IP大多都收费,看了看皱皱的钱包后,一个大胆的想法冒出 我要白嫖!
-
python实现ip代理池功能示例
本文实例讲述了python实现ip代理池功能.分享给大家供大家参考,具体如下: 爬取的代理源为西刺代理. 用xpath解析页面 用telnet来验证ip是否可用 把有效的ip写入到本地txt中.当然也可以写入到redis.mongodb中,也可以设置检测程序当代理池中的ip数不够(如:小于20个)时,启动该脚本来重新获取ip,本脚本的代码也要做相应的改变. # !/usr/bin/env python # -*- coding: utf-8 -*- # @Version : 1.0 # @Tim
-
python爬虫实战之制作属于自己的一个IP代理模块
一.使用PyChram的正则 首先,小编讲的不是爬取ip,而是讲了解PyCharm的正则,这里讲的正则不是Python的re模块哈! 而是PyCharm的正则功能,我们在PyChram的界面上按上Ctrl+R,可以发现,这里出现两行输入框 现在如果小编想把如下数据转换成一个字典存储 读者也许会一个一去改,但是小编只需在上述的那两个输入框内,输入一串字符串即可. 只需在第一个输入框中,输入(.*) : (.*) 在第二个输入框中,输入"$1":"$2",,看看效果如何
-
Python爬虫实战:分析《战狼2》豆瓣影评
刚接触python不久,做一个小项目来练练手.前几天看了<战狼2>,发现它在最新上映的电影里面是排行第一的,如下图所示.准备把豆瓣上对它的影评做一个分析. 目标总览 主要做了三件事: 抓取网页数据 清理数据 用词云进行展示 使用的python版本是3.5. 一.抓取网页数据 第一步要对网页进行访问,python中使用的是urllib库.代码如下: from urllib import request resp = request.urlopen('https://movie.douban.co
-
Python爬虫实战案例之爬取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一起期待吧!! 这个案例的视频地址在这里 https://v.douyu.com/show/a2JEMJj3e3mMNxml 项目目标 爬取喜马拉雅音频数据 受害者地址 https://www.ximalaya.com/ 本文知识点: 1.系统分析网页性质 2.多层数据解析 3.海量音频数据保存 环境
-
Python爬虫实战之爬取携程评论
一.分析数据源 这里的数据源是指html网页?还是Aajx异步.对于爬虫初学者来说,可能不知道怎么判断,这里辰哥也手把手过一遍. 提示:以下操作均不需要登录(当然登录也可以) 咱们先在浏览器里面搜索携程,然后在携程里面任意搜索一个景点:长隆野生动物世界,这里就以长隆野生动物世界为例,讲解如何去爬取携程评论数据. 页面下方则是评论数据 从上面两张图可以看出,点击评论下一页,浏览器的链接没有变化,说明数据是Ajax异步请求.因此我们就找到了数据是异步加载过来的,这时候需要去network里面是查
-
Python爬虫实战之使用Scrapy爬取豆瓣图片
使用Scrapy爬取豆瓣某影星的所有个人图片 以莫妮卡·贝鲁奇为例 1.首先我们在命令行进入到我们要创建的目录,输入 scrapy startproject banciyuan 创建scrapy项目 创建的项目结构如下 2.为了方便使用pycharm执行scrapy项目,新建main.py from scrapy import cmdline cmdline.execute("scrapy crawl banciyuan".split()) 再edit configuration 然后
-
Python爬虫实战之用selenium爬取某旅游网站
一.selenium实战 这里我们只会用到很少的selenium语法,我这里就不补充别的用法了,以实战为目的 二.打开艺龙网 可以直接点击这里进入:艺龙网 这里是主页 三.精确目标 我们的目标是,鹤壁市,所以我们应该先点击搜索框,然后把北京删掉,替换成鹤壁市,那么怎么通过selenium实现呢? 打开pycharm,新建一个叫做艺龙网的py文件,先导包: from selenium import webdriver import time # 导包 driver = webdriver.Chro
-
Python爬虫实战之爬取京东商品数据并实实现数据可视化
一.开发工具 Python版本:3.6.4 相关模块: DecryptLogin模块: argparse模块: 以及一些python自带的模块. 二.环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 三.原理简介 原理其实挺简单的,首先,我们利用之前开源的DecryptLogin库来实现一下微博的模拟登录操作: '''模拟登录京东''' @staticmethod def login(): lg = login.Login() infos_return, session
-
Python爬虫实战项目掌握酷狗音乐的加密过程
1.前言 小编在这里讲一下,下面的内容仅供学习参考,切莫用于商业活动,一经被相关人员发现,本小编概不负责!读者切记切记. 2.获取音乐播放列表 其实,这就是小编要讲的重点,因为就是这部分用到了加密. 我们在搜索栏上输入我们想听的音乐,小编输入:刺客 是不是看到了一系列音乐,怎样得到这些音乐的一些信息呢?(这里指的音乐信息是指音乐的hash值和音乐的album_id值[这两个参数在获取音乐的下载链接那里会用到],当然还包括音乐的名称[不然怎么区别呢?]). 由于这一系列音乐是动态加载出来的,也就是
-
Python爬虫实战JS逆向AES逆向加密爬取
目录 爬取目标 工具使用 项目思路解析 简易源码分享 爬取目标 网址:监管平台 工具使用 开发工具:pycharm 开发环境:python3.7, Windows10 使用工具包:requests,AES,json 涉及AES对称加密问题 需要 安装node.js环境 使用npm install 安装 crypto-js 项目思路解析 确定数据 在这个网页可以看到数据是动态返回的 但是 都是加密的 如何确定是我们需要的? 突然想到 如果我分页 是不是会直接加载第二个页面 然后查看相似度 找到第
-
python爬虫实战steam加密逆向RSA登录解析
目录 采集目标 工具准备 项目思路解析 采集目标 网址:steam 工具准备 开发工具:pycharm 开发环境:python3.7, Windows10 使用工具包:requests 项目思路解析 访问登录页面重登录页面获取登录接口, 先输入错误的账户密码去测试登录接口. 获取到登录的接口地址,请求方法是post请求,找到需要传递的参数,可以看到密码数据是加密的第一个数据是时间戳密码加密字段应该用的base64,rsatimestamp字段目前还不清楚是什么,其他的都是固定数据. 找到pass