详解commons-pool2池化技术
目录
- 一、前言
- 二、commons-pool2池化技术剖析
- 2.1、核心三元素
- 2.1.1、ObjectPool
- 2.1.2、PooledObjectFactory
- 2.1.3、PooledObject
- 2.2、对象池逻辑分析
- 2.2.1、对象池接口说明
- 2.2.2、对象创建解耦
- 2.2.3、对象池源码分析
- 2.3、核心业务流程
- 2.3.1、池化对象状态变更
- 2.3.2、对象池browObject过程
- 2.3.3、对象池returnObject的过程执行逻辑
- 2.4、拓展和思考
- 2.4.1、关于LinkedBlockingDeque的另种实现
- 2.4.2、对象池的自我保护机制
- 三、写在最后
一、前言
我们经常会接触各种池化的技术或者概念,包括对象池、连接池、线程池等,池化技术最大的好处就是实现对象的重复利用,尤其是创建和使用大对象或者宝贵资源(HTTP连接对象,MySQL连接对象)等方面的时候能够大大节省系统开销,对提升系统整体性能也至关重要。
在并发请求下,如果需要同时为几百个query操作创建/关闭MySQL的连接或者是为每一个HTTP请求创建一个处理线程或者是为每一个图片或者XML解析创建一个解析对象而不使用池化技术,将会给系统带来极大的负载挑战。
二、commons-pool2池化技术剖析
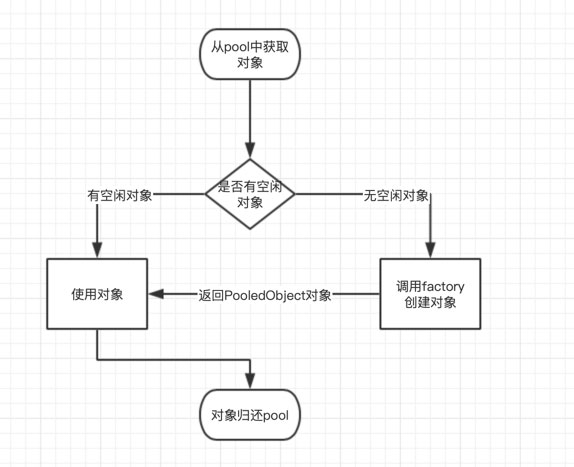
越来越多的框架在选择使用apache commons-pool2进行池化的管理,如jedis-cluster,commons-pool2工作的逻辑如下图所示:
2.1、核心三元素
2.1.1、ObjectPool
对象池,负责对对象进行生命周期的管理,并提供了对对象池中活跃对象和空闲对象统计的功能。
2.1.2、PooledObjectFactory
对象工厂类,负责具体对象的创建、初始化,对象状态的销毁和验证。commons-pool2框架本身提供了默认的抽象实现BasePooledObjectFactory ,业务方在使用的时候只需要继承该类,然后实现warp和create方法即可。
2.1.3、PooledObject
池化对象,是需要放到ObjectPool对象的一个包装类。添加了一些附加的信息,比如说状态信息,创建时间,激活时间等。commons-pool2提供了DefaultPooledObject和 PoolSoftedObject 2种实现。其中PoolSoftedObject继承自DefaultPooledObject,不同点是使用SoftReference实现了对象的软引用。获取对象的时候使用也是通过SoftReference进行获取。
2.2、对象池逻辑分析
2.2.1、对象池接口说明
1)我们在使用commons-pool2的时候,应用程序获取或释放对象的操作都是基于对象池进行的,对象池核心接口主要包括如下:
/**
*向对象池中增加对象实例
*/
void addObject() throws Exception, IllegalStateException,
UnsupportedOperationException;
/**
* 从对象池中获取对象
*/
T borrowObject() throws Exception, NoSuchElementException,
IllegalStateException;
/**
* 失效非法的对象
*/
void invalidateObject(T obj) throws Exception;
/**
* 释放对象至对象池
*/
void returnObject(T obj) throws Exception;
除了接口本身之外,对象池还支持对对象的最大数量,保留时间等等进行设置。对象池的核心参数项包括maxTotal,maxIdle,minIdle,maxWaitMillis,testOnBorrow 等。
2.2.2、对象创建解耦
对象工厂是commons-pool2框架中用于生成对象的核心环节,业务方在使用过程中需要自己去实现对应的对象工厂实现类,通过工厂模式,实现了对象池与对象的生成与实现过程细节的解耦,每一个对象池应该都有对象工厂的成员变量,如此实现对象池本身和对象的生成逻辑解耦。
可以通过代码进一步验证我们的思路:
public GenericObjectPool(final PooledObjectFactory<T> factory) {
this(factory, new GenericObjectPoolConfig<T>());
}
public GenericObjectPool(final PooledObjectFactory<T> factory,
final GenericObjectPoolConfig<T> config) {
super(config, ONAME_BASE, config.getJmxNamePrefix());
if (factory == null) {
jmxUnregister(); // tidy up
throw new IllegalArgumentException("factory may not be null");
}
this.factory = factory;
idleObjects = new LinkedBlockingDeque<>(config.getFairness());
setConfig(config);
}
public GenericObjectPool(final PooledObjectFactory<T> factory,
final GenericObjectPoolConfig<T> config, final AbandonedConfig abandonedConfig) {
this(factory, config);
setAbandonedConfig(abandonedConfig);
}
可以看到对象池的构造方法,都依赖于对象构造工厂PooledObjectFactory,在生成对象的时候,基于对象池中定义的参数和对象构造工厂来生成。
/**
* 向对象池中增加对象,一般在预加载的时候会使用该功能
*/
@Override
public void addObject() throws Exception {
assertOpen();
if (factory == null) {
throw new IllegalStateException(
"Cannot add objects without a factory.");
}
final PooledObject<T> p = create();
addIdleObject(p);
}
create() 方法基于对象工厂来生成的对象,继续往下跟进代码来确认逻辑;
final PooledObject<T> p;
try {
p = factory.makeObject();
if (getTestOnCreate() && !factory.validateObject(p)) {
createCount.decrementAndGet();
return null;
}
} catch (final Throwable e) {
createCount.decrementAndGet();
throw e;
} finally {
synchronized (makeObjectCountLock) {
makeObjectCount--;
makeObjectCountLock.notifyAll();
}
}
此处确认了factory.makeObject()的操作,也印证了上述的推测,基于对象工厂来生成对应的对象。
为了更好的能够实现对象池中对象的使用以及跟踪对象的状态,commons-pool2框架中使用了池化对象PooledObject的概念,PooledObject本身是泛型类,并提供了getObject()获取实际对象的方法。
2.2.3、对象池源码分析
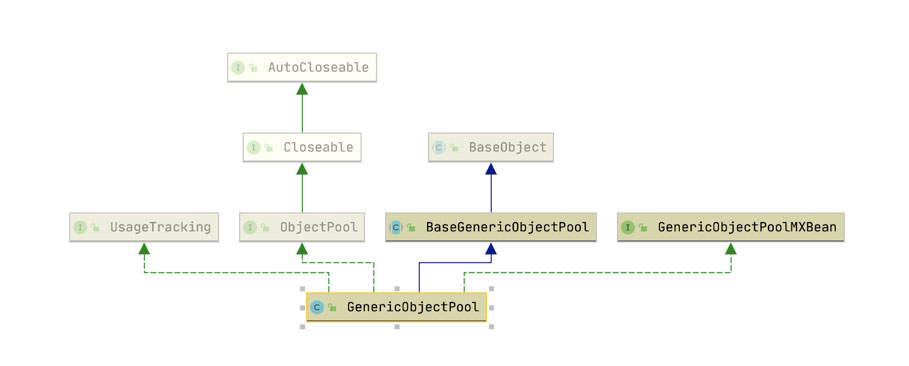
经过上述分析我们知道了对象池承载了对象的生命周期的管理,包括整个对象池中对象数量的控制等逻辑,接下来我们通过GenericObjectPool的源码来分析究竟是如何实现的。
对象池中使用了双端队列LinkedBlockingDeque来存储对象,LinkedBlockingDeque对列支持FIFO和FILO两种策略,基于AQS来实现队列的操作的协同。
LinkedBlockingDeque提供了队尾和队头的插入和移除元素的操作,相关操作都进行了加入重入锁的加锁操作队列中设置notFull 和 notEmpty两个状态变量,当对队列进行元素的操作的时候会触发对应的执行await和notify等操作。
/**
* 第一个节点
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
private transient Node<E> first; // @GuardedBy("lock")
/**
* 最后一个节点
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
private transient Node<E> last; // @GuardedBy("lock")
/** 当前队列长度 */
private transient int count; // @GuardedBy("lock")
/** 队列最大容量 */
private final int capacity;
/** 主锁 */
private final InterruptibleReentrantLock lock;
/** 队列是否为空状态锁 */
private final Condition notEmpty;
/** 队列是否满状态锁 */
private final Condition notFull;
队列核心点为:
1.队列中所有的移入元素、移出、初始化构造元素都是基于主锁进行加锁操作。
2.队列的offer和pull支持设置超时时间参数,主要是通过两个状态Condition来进行协调操作。如在进行offer操作的时候,如果操作不成功,则基于notFull状态对象进行等待。
public boolean offerFirst(final E e, final long timeout, final TimeUnit unit)
throws InterruptedException {
Objects.requireNonNull(e, "e");
long nanos = unit.toNanos(timeout);
lock.lockInterruptibly();
try {
while (!linkFirst(e)) {
if (nanos <= 0) {
return false;
}
nanos = notFull.awaitNanos(nanos);
}
return true;
} finally {
lock.unlock();
}
}
如进行pull操作的时候,如果操作不成功,则对notEmpty进行等待操作。
public E takeFirst() throws InterruptedException {
lock.lock();
try {
E x;
while ( (x = unlinkFirst()) == null) {
notEmpty.await();
}
return x;
} finally {
lock.unlock();
}
}
反之当操作成功的时候,则进行唤醒操作,如下所示:
private boolean linkLast(final E e) {
// assert lock.isHeldByCurrentThread();
if (count >= capacity) {
return false;
}
final Node<E> l = last;
final Node<E> x = new Node<>(e, l, null);
last = x;
if (first == null) {
first = x;
} else {
l.next = x;
}
++count;
notEmpty.signal();
return true;
}
2.3、核心业务流程
2.3.1、池化对象状态变更
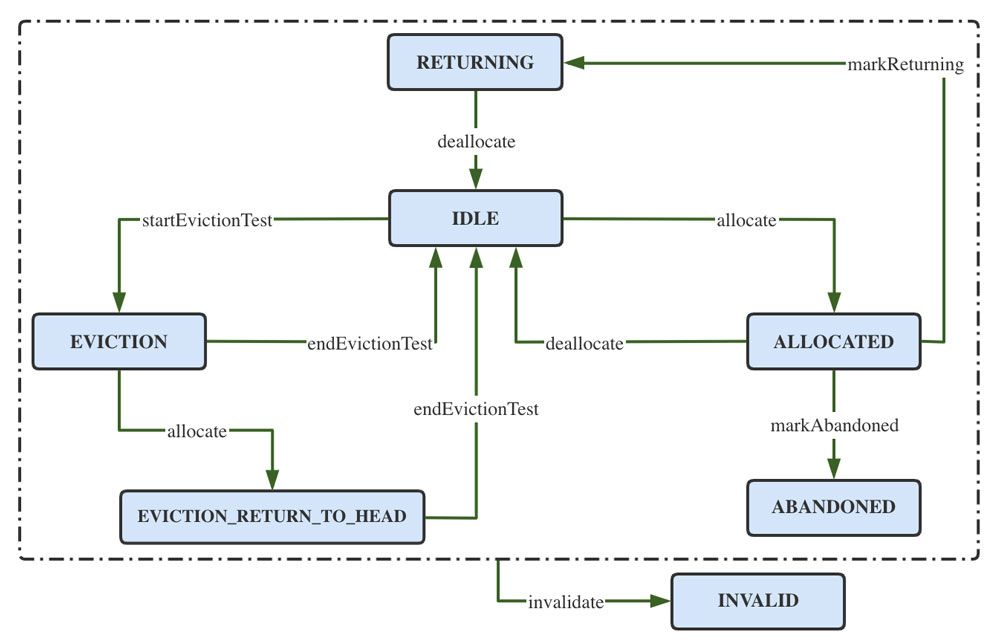
上图是PooledObject的状态机图,蓝色表示状态,红色表示与ObjectPool相关的方法.PooledObject的状态为:IDLE、ALLOCATED、RETURNING、ABANDONED、INVALID、EVICTION、EVICTION_RETURN_TO_HEAD
所有状态是在PooledObjectState类中定义的,其中一些是暂时未使用的,此处不再赘述。
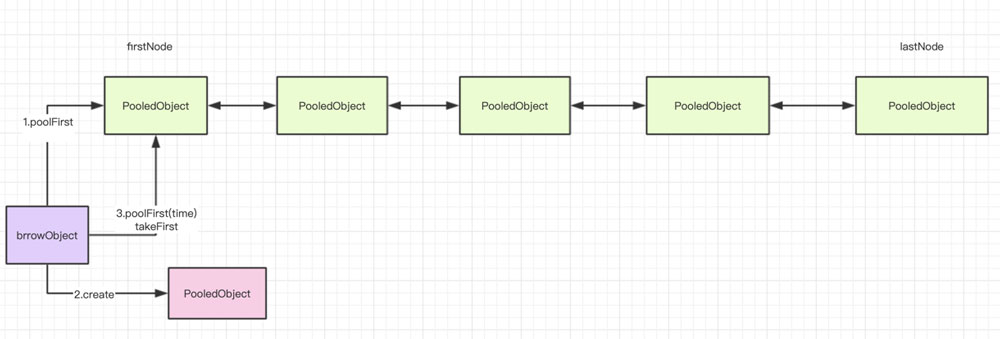
2.3.2、对象池browObject过程
第一步、根据配置确定是否要为标签删除调用removeAbandoned方法。
第二步、尝试获取或创建一个对象,源码过程如下:
//1、尝试从双端队列中获取对象,pollFirst方法是非阻塞方法
p = idleObjects.pollFirst();
if (p == null) {
p = create();
if (p != null) {
create = true;
}
}
if (blockWhenExhausted) {
if (p == null) {
if (borrowMaxWaitMillis < 0) {
//2、没有设置最大阻塞等待时间,则无限等待
p = idleObjects.takeFirst();
} else {
//3、设置最大等待时间了,则阻塞等待指定的时间
p = idleObjects.pollFirst(borrowMaxWaitMillis,
TimeUnit.MILLISECONDS);
}
}
}
示意图如下所示:
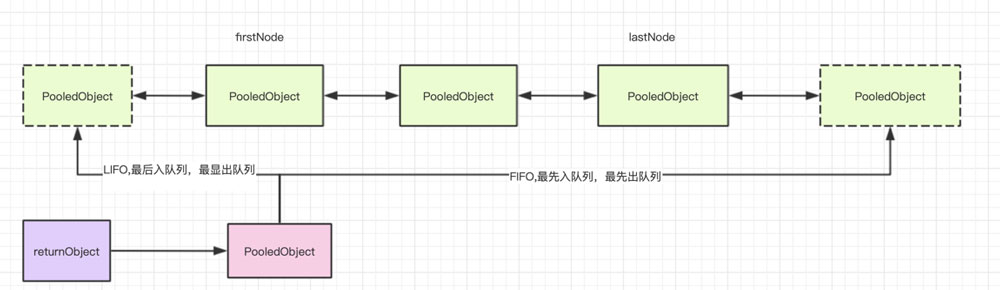
第三步、调用allocate使状态更改为ALLOCATED状态。
第四步、调用工厂的activateObject来初始化对象,如果发生错误,请调用destroy方法来销毁对象,例如源代码中的六个步骤。
第五步、调用TestFactory的validateObject进行基于TestOnBorrow配置的对象可用性分析,如果不可用,则调用destroy方法销毁对象。3-7步骤的源码过程如下所示:
//修改对象状态
if (!p.allocate()) {
p = null;
}
if (p != null) {
try {
//初始化对象
factory.activateObject(p);
} catch (final Exception e) {
try {
destroy(p, DestroyMode.NORMAL);
} catch (final Exception e1) {
}
}
if (p != null && getTestOnBorrow()) {
boolean validate = false;
Throwable validationThrowable = null;
try {
//验证对象的可用性状态
validate = factory.validateObject(p);
} catch (final Throwable t) {
PoolUtils.checkRethrow(t);
validationThrowable = t;
}
//对象不可用,验证失败,则进行destroy
if (!validate) {
try {
destroy(p, DestroyMode.NORMAL);
destroyedByBorrowValidationCount.incrementAndGet();
} catch (final Exception e) {
// Ignore - validation failure is more important
}
}
}
}
2.3.3、对象池returnObject的过程执行逻辑
第一步、调用markReturningState方法将状态更改为RETURNING。
第二步、基于testOnReturn配置调用PooledObjectFactory的validateObject方法以进行可用性检查。如果检查失败,则调用destroy消耗该对象,然后确保调用idle以确保池中有IDLE状态对象可用,如果没有,则调用create方法创建一个新对象。
第三步、调用PooledObjectFactory的passivateObject方法进行反初始化操作。
第四步、调用deallocate将状态更改为IDLE。
第五步、检测是否已超过最大空闲对象数,如果超过,则销毁当前对象。
第六步、根据LIFO(后进先出)配置将对象放置在队列的开头或结尾。
2.4、拓展和思考
2.4.1、关于LinkedBlockingDeque的另种实现
上文中分析到commons-pool2中使用了双端队列以及java中的condition来实现队列中对象的管理和不同线程对对象获取和释放对象操作之间的协调,那是否有其他方案可以实现类似效果呢?答案是肯定的。
使用双端队列进行操作,其实是想将空闲对象和活跃对象进行隔离,本质上将我们用两个队列来分别存储空闲队列和当前活跃对象,然后再统一使用一个对象锁,也是可以达成相同的目标的,大概的思路如下:
1、双端队列改为两个单向队列分别用于存储空闲的和活跃的对象,队列之间的同步和协调可以通过对象锁的wait和notify完成。
public class PoolState {
protected final List<PooledObject> idleObjects = new ArrayList<>();
protected final List<PooledObject> activeObjects = new ArrayList<>();
//...
}
2、在获取对象时候,原本对双端队列的LIFO或者FIFO变成了从空闲队列idleObjects中获取对象,然后在获取成功并对象状态合法后,将对象添加到活跃对象集合activeObjects 中,如果获取对象需要等待,则PoolState对象锁应该通过wait操作,进入等待状态。
3、在释放对象的时候,则首先从活跃对象集合activeObjects 删除元素,删除完成后,将对象增加到空闲对象集合idleObjects中,需要注意的是,在释放对象过程中也需要去校验对象的状态。当对象状态不合法的时候,对象应该进行销毁,不应该添加到idleObjects中。释放成功后则PoolState通过notify或者notifyAll唤醒等待中的获取操作。
4、为保障对活跃队列和空闲队列的操作线程安全性,获取对象和释放对象需要进行加锁操作,和commons2-pool中的一致。
2.4.2、对象池的自我保护机制
我们在使用commons-pool2中获取对象的时候,会从双端队列中阻塞等待获取元素(或者是创建新对象),但是如果是应用程序的异常,一直未调用returnObject或者invalidObject的时候,那可能就会出现对象池中的对象一直上升,到达设置的上线之后再去调用borrowObject的时候就会出现一直等待或者是等待超时而无法获取对象的情况。
commons-pool2为了避免上述分析的问题的出现,提供了两种自我保护机制:
基于阈值的检测:
从对象池中获取对象的时候会校验当前对象池的活跃对象和空闲对象的数量占比,当空闲独享非常少,活跃对象非常多的时候,会触发空闲对象的回收,具体校验规则为:如果当前对象池中少于2个idle状态的对象或者 active数量>最大对象数-3 的时候,在borrow对象的时候启动泄漏清理。通过AbandonedConfig.setRemoveAbandonedOnBorrow 为 true 进行开启。
//根据配置确定是否要为标签删除调用removeAbandoned方法
final AbandonedConfig ac = this.abandonedConfig;
if (ac != null && ac.getRemoveAbandonedOnBorrow() && (getNumIdle() < 2) && (getNumActive() > getMaxTotal() - 3) ) {
removeAbandoned(ac);
}
异步调度线程检测:
AbandonedConfig.setRemoveAbandonedOnMaintenance 设置为 true 以后,在维护任务运行的时候会进行泄漏对象的清理,通过设置setTimeBetweenEvictionRunsMillis 来设置维护任务执行的时间间隔。
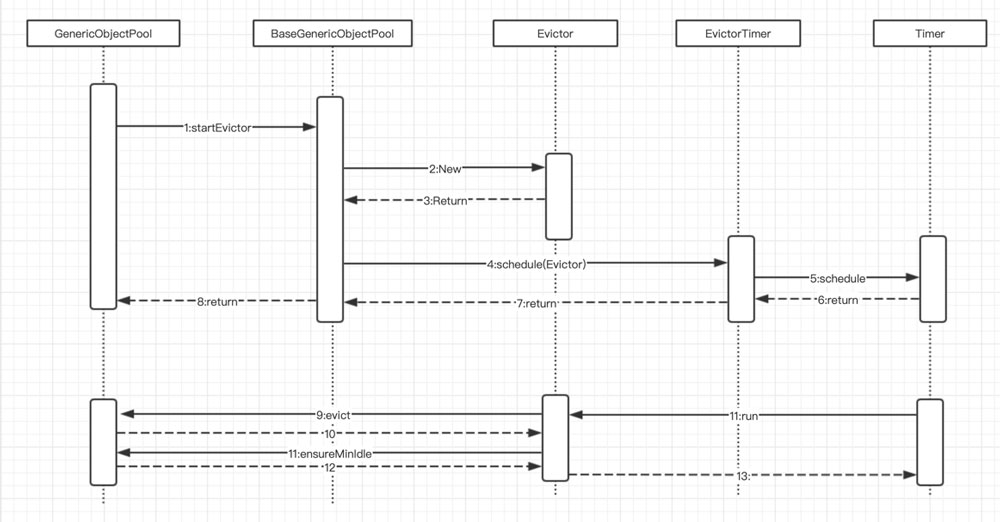
检测和回收实现逻辑分析:
在构造方法内部逻辑的最后调用了startEvictor方法。这个方法的作用是在构造完对象池后,启动回收器来监控回收空闲对象。startEvictor定义在GenericObjectPool的父类BaseGenericObjectPool(抽象)类中,我们先看一下这个方法的源码。
在构造器中会执行如下的设置参数;
public final void setTimeBetweenEvictionRunsMillis(
final long timeBetweenEvictionRunsMillis) {
this.timeBetweenEvictionRunsMillis = timeBetweenEvictionRunsMillis;
startEvictor(timeBetweenEvictionRunsMillis);
}
当且仅当设置了timeBetweenEvictionRunsMillis参数后才会开启定时清理任务。
final void startEvictor(final long delay) {
synchronized (evictionLock) {
EvictionTimer.cancel(evictor, evictorShutdownTimeoutMillis, TimeUnit.MILLISECONDS);
evictor = null;
evictionIterator = null;
//如果delay<=0则不会开启定时清理任务
if (delay > 0) {
evictor = new Evictor();
EvictionTimer.schedule(evictor, delay, delay);
}
}
}
继续跟进代码可以发现,调度器中设置的清理方法的实现逻辑实际在对象池中定义的,也就是由GenericObjectPool或者GenericKeyedObjectPool来实现,接下来我们继续探究对象池是如何进行对象回收的。
a)、核心参数:
minEvictableIdleTimeMillis:指定空闲对象最大保留时间,超过此时间的会被回收。不配置则不过期回收。
softMinEvictableIdleTimeMillis:一个毫秒数值,用来指定在空闲对象数量超过minIdle设置,且某个空闲对象超过这个空闲时间的才可以会被回收。
minIdle:对象池里要保留的最小空间对象数量。
b)、回收逻辑
以及一个对象回收策略接口EvictionPolicy,可以预料到对象池的回收会和上述的参数项及接口EvictionPolicy发生关联,继续跟进代码会发现如下的内容,可以看到在判断对象池可以进行回收的时候,直接调用了destroy进行回收。
boolean evict;
try {
evict = evictionPolicy.evict(evictionConfig, underTest,
idleObjects.size());
} catch (final Throwable t) {
// Slightly convoluted as SwallowedExceptionListener
// uses Exception rather than Throwable
PoolUtils.checkRethrow(t);
swallowException(new Exception(t));
// Don't evict on error conditions
evict = false;
}
if (evict) {
// 如果可以被回收则直接调用destroy进行回收
destroy(underTest);
destroyedByEvictorCount.incrementAndGet();
}
为提升回收的效率,在回收策略判断对象的状态不是evict的时候,也会进行进一步的状态判断和处理,具体逻辑如下:
1.尝试激活对象,如果激活失败则认为对象已经不再存活,直接调用destroy进行销毁。
2.在激活对象成功的情况下,会通过validateObject方法取校验对象状态,如果校验失败,则说明对象不可用,需要进行销毁。
boolean active = false;
try {
// 调用activateObject激活该空闲对象,本质上不是为了激活,
// 而是通过这个方法可以判定是否还存活,这一步里面可能会有一些资源的开辟行为。
factory.activateObject(underTest);
active = true;
} catch (final Exception e) {
// 如果激活的时候,发生了异常,就说明该空闲对象已经失联了。
// 调用destroy方法销毁underTest
destroy(underTest);
destroyedByEvictorCount.incrementAndGet();
}
if (active) {
// 再通过进行validateObject校验有效性
if (!factory.validateObject(underTest)) {
// 如果校验失败,说明对象已经不可用了
destroy(underTest);
destroyedByEvictorCount.incrementAndGet();
} else {
try {
/*
*因为校验还激活了空闲对象,分配了额外的资源,那么就通过passivateObject把在activateObject中开辟的资源释放掉。
*/
factory.passivateObject(underTest);
} catch (final Exception e) {
// 如果passivateObject失败,也可以说明underTest这个空闲对象不可用了
destroy(underTest);
destroyedByEvictorCount.incrementAndGet();
}
}
}
三、写在最后
连接池能够给程序开发者带来一些便利性,前言中我们分析了使用池化技术的好处和必要性,但是我们也可以看到commons-pool2框架在对象的创建和获取上都进行了加锁的操作,这会在并发场景下一定程度的影响应用程序的性能,其次池化对象的对象池中对象的数量也是需要进行合理的设置,否则也很难起到真正的使用对象池的目的,这给我们也带来了一定的挑战。
以上就是详解commons-pool2池化技术的详细内容,更多关于commons-pool2池化技术的资料请关注我们其它相关文章!
相关推荐
-
对Pytorch中Tensor的各种池化操作解析
AdaptiveAvgPool1d(N) 对一个C*H*W的三维输入Tensor, 池化输出为C*H*N, 即按照H轴逐行对W轴平均池化 >>> a = torch.ones(2,3,4) >>> a[0,1,2] = 0 >>>> a tensor([[[1., 1., 1., 1.], [1., 1., 0., 1.], [1., 1., 1., 1.]], [[1., 1., 1., 1.], [1., 1., 1., 1.], [1.,
-
TensorFlow tf.nn.max_pool实现池化操作方式
max pooling是CNN当中的最大值池化操作,其实用法和卷积很类似 有些地方可以从卷积去参考[TensorFlow] tf.nn.conv2d实现卷积的方式 tf.nn.max_pool(value, ksize, strides, padding, name=None) 参数是四个,和卷积很类似: 第一个参数value:需要池化的输入,一般池化层接在卷积层后面,所以输入通常是feature map,依然是[batch, height, width, channels]这样的shape 第
-
keras中的卷积层&池化层的用法
卷积层 创建卷积层 首先导入keras中的模块 from keras.layers import Conv2D 卷积层的格式及参数: Conv2D(filters, kernel_size, strides, padding, activation='relu', input_shape) filters: 过滤器数量 kernel_size:指定卷积窗口的高和宽的数字 strides: 卷积stride,如果不指定任何值,则strides设为1 padding: 选项包括'valid'和'sa
-
pytorch torch.nn.AdaptiveAvgPool2d()自适应平均池化函数详解
如题:只需要给定输出特征图的大小就好,其中通道数前后不发生变化.具体如下: AdaptiveAvgPool2d CLASStorch.nn.AdaptiveAvgPool2d(output_size)[SOURCE] Applies a 2D adaptive average pooling over an input signal composed of several input planes. The output is of size H x W, for any input size.
-
浅谈pytorch池化maxpool2D注意事项
注意: 在搭建网络的时候用carpool2D的时候,让高度和宽度方向不同池化时, 用如下: nn.MaxPool2d(kernel_size=2, stride=(2, 1), padding=(0, 1)) 千万不要用: nn.MaxPool2d(kernel_size=2, stride=(2, 1), padding=(0, 0)), 这样在用交叉熵做损失函数的时候,有时候会出现loss为nan的情况,检查的时候发现,某些样本的提取出来的feature全为nan. 以上这篇浅谈pytorc
-
浅谈tensorflow1.0 池化层(pooling)和全连接层(dense)
池化层定义在tensorflow/python/layers/pooling.py. 有最大值池化和均值池化. 1.tf.layers.max_pooling2d max_pooling2d( inputs, pool_size, strides, padding='valid', data_format='channels_last', name=None ) inputs: 进行池化的数据. pool_size: 池化的核大小(pool_height, pool_width),如[3,3].
-
PyTorch的自适应池化Adaptive Pooling实例
简介 自适应池化Adaptive Pooling是PyTorch含有的一种池化层,在PyTorch的中有六种形式: 自适应最大池化Adaptive Max Pooling: torch.nn.AdaptiveMaxPool1d(output_size) torch.nn.AdaptiveMaxPool2d(output_size) torch.nn.AdaptiveMaxPool3d(output_size) 自适应平均池化Adaptive Average Pooling: torch.nn.A
-
pytorch中的卷积和池化计算方式详解
TensorFlow里面的padding只有两个选项也就是valid和same pytorch里面的padding么有这两个选项,它是数字0,1,2,3等等,默认是0 所以输出的h和w的计算方式也是稍微有一点点不同的:tf中的输出大小是和原来的大小成倍数关系,不能任意的输出大小:而nn输出大小可以通过padding进行改变 nn里面的卷积操作或者是池化操作的H和W部分都是一样的计算公式:H和W的计算 class torch.nn.MaxPool2d(kernel_size, stride=Non
-
Python 字符串池化的前提
前言 在 Python 中经常通过内存池化技术来提高其性能,那么问题来了,在什么情况下会池化呢? 让我们通过几个例子进行一下理解一下. 预备知识 在查看例子之前,首先要提 python 中的一个函数 id(),让我们看一下函数说明: id(obj, /) Return the identity of an object. This is guaranteed to be unique among simultaneously existing objects. (CPython uses the
-

详解commons-pool2池化技术
目录 一.前言 二.commons-pool2池化技术剖析 2.1.核心三元素 2.1.1.ObjectPool 2.1.2.PooledObjectFactory 2.1.3.PooledObject 2.2.对象池逻辑分析 2.2.1.对象池接口说明 2.2.2.对象创建解耦 2.2.3.对象池源码分析 2.3.核心业务流程 2.3.1.池化对象状态变更 2.3.2.对象池browObject过程 2.3.3.对象池returnObject的过程执行逻辑 2.4.拓展和思考 2.4.1.关于
-
详解Java数据库连接池
一.什么是数据库连接池 就是一个容器持有多个数据库连接,当程序需要操作数据库的时候直接从池中取出连接,使用完之后再还回去,和线程池一个道理. 二.为什么需要连接池,好处是什么? 1.节省资源,如果每次访问数据库都创建新的连接,创建和销毁都浪费系统资源 2.响应性更好,省去了创建的时间,响应性更好. 3.统一管理数据库连接,避免因为业务的膨胀导致数据库连接的无限增多. 4.便于监控. 三.都有哪些连接池方案 数据库连接池的方案有不少,我接触过的连接池方案有: 1.C3p0 这个连接池我很久之前看到
-
详解Java线程池是如何重复利用空闲线程的
在Java开发中,经常需要创建线程去执行一些任务,实现起来也非常方便,但如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了,这样频繁创建线程就会大大降低系统的效率,因为频繁创建线程和销毁线程需要时间.此时,我们很自然会想到使用线程池来解决这个问题. 使用线程池的好处: 降低资源消耗.java中所有的池化技术都有一个好处,就是通过复用池中的对象,降低系统资源消耗.设想一下如果我们有n多个子任务需要执行,如果我们为每个子任务都创建一个执行线程,而创建线程的过程是需要一定的系统消耗
-
详解.NET数据库连接池
目录 前置知识背景 1. .NET数据库连接池的背景 2. .NET 数据库连接池的表现 3. .NET是如何形成数据库连接池的? 4. 连接池中的连接什么时候被移除? .NET 如何清空连接池? 一般我们的项目中会使用1到2个数据库连接配置,同程艺龙的数据库连接配置被收拢到统一的配置中心,由DBA统一配置和维护,业务方通过某个字符串配置拿到的是Connection对象. DBA能在对业务方无侵入的情况下,给业务方切换备份数据库,之后DBA要求旧连接池必须立即被清空, 那么问题来了: dotne
-
详解Java线程池的使用及工作原理
一.什么是线程池? 线程池是一种用于实现计算机程序并发执行的软件设计模式.线程池维护多个线程,等待由调度程序分配任务以并发执行,该模型提高了性能,并避免了由于为短期任务频繁创建和销毁线程而导致的执行延迟. 二.线程池要解决什么问题? 说到线程池就一定要从线程的生命周期讲起. 从图中可以了解无论任务执行多久,每个线程都要经历从生到死的状态.而使用线程池就是为了避免线程的重复创建,从而节省了线程的New至Runnable, Running至Terminated的时间:同时也会复用线程,最小化的节省系
-
Java详解使用线程池处理任务方法
什么是线程池? 线程池就是一个可以复用线程的技术. 不使用线程池的问题: 如果用户每发起一个请求,后台就创建一个新线程来处理,下次新任务来了又要创建新线程,而创建新线程的开销是很大的,这样会严重影响系统的性能. 线程池常见面试题: 1.临时线程什么时候创建? 新任务提交时发现核心线程都在忙,任务队列也满了,并且还可以创建临时线程,此时才会创建临时线程. 2.什么时候会开始拒绝任务? 核心线程和临时线程都在忙,任务队列也满了,新的任务过来的时候才会开始任务拒绝. 1.线程池处理Runnable任务
-
Python内存管理器如何实现池化技术
目录 前言 内存层次结构 内存管理逻辑 内存布局及对应的数据结构 内存分配 内存释放 总结 前言 Python 中一切皆对象,这些对象的内存都是在运行时动态地在堆中进行分配的,就连 Python 虚拟机使用的栈也是在堆上模拟的.既然一切皆对象,那么在 Python 程序运行过程中对象的创建和释放就很频繁了,而每次都用 malloc() 和 free() 去向操作系统申请内存或释放内存就会对性能造成影响,毕竟这些函数最终都要发生系统调用引起上下文的切换.下面我们就来看看 Python 中的内存管理
-
详解Java线程池队列中的延迟队列DelayQueue
目录 DelayQueue延迟队列 DelayQueue使用场景 DelayQueue属性 DelayQueue构造方法 实现Delayed接口使用示例 DelayQueue总结 在阻塞队里中,除了对元素进行增加和删除外,我们可以把元素的删除做一个延迟的处理,即使用DelayQueue的方法.本文就来和大家聊聊Java线程池队列中的DelayQueue—延迟队列 public enum QueueTypeEnum { ARRAY_BLOCKING_QUEUE(1, "ArrayBlockingQ
-
详解Java线程池和Executor原理的分析
详解Java线程池和Executor原理的分析 线程池作用与基本知识 在开始之前,我们先来讨论下"线程池"这个概念."线程池",顾名思义就是一个线程缓存.它是一个或者多个线程的集合,用户可以把需要执行的任务简单地扔给线程池,而不用过多的纠结与执行的细节.那么线程池有哪些作用?或者说与直接用Thread相比,有什么优势?我简单总结了以下几点: 减小线程创建和销毁带来的消耗 对于Java Thread的实现,我在前面的一篇blog中进行了分析.Java Thread与内
-
详解JAVA 常量池
前言 对常量池的理解之前,需要熟悉的是一些术语: 字面量 在计算机科学中,字面量(literal)是用于表达源代码中一个固定值的表示法(notation). 几乎所有计算机编程语言都具有对基本值的字面量表示,诸如:整数.浮点数以及字符串:而有很多也对布尔类型和字符类型的值也支持字面量表示: 还有一些甚至对枚举类型的元素以及像数组.记录和对象等复合类型的值也支持字面量表示法.C语言关于复合字面量的介绍可参考: [1] . 百度也给了一个例子: 这个object-c 的例子,容易理解. #incl