Pandas剔除混合数据中非数字的数据操作
我们日常拿到的数据,指标字段有时会混入非数字的数据,这时候会影响我们的操作
| name | height |
| Hang | 180 |
| Ben | 145 |
| Cho | notknow |
| XIn | 189 |
比如read_csv读入时,该列会以object形式读入,也不能直接进行计算,不然会出现如unsupported operand type(s) for +: 'float' and 'str'的错误
这时候就需要进行数据预处理,清除掉指标值中非数字的数据,这里我以2012_FederalElectionCommission_Database数据为例。
首先读入数据,可以发现提示:Columns (6) have mixed types,这里Columns (6)是指标值混有字符串格式数据
fec = pd.read_csv('P00000001-ALL.csv')
D:\SOFTWARE\Anaconda\lib\site-packages\IPython\core\interactiveshell.py:2717: DtypeWarning: Columns (6) have mixed types. Specify dtype option on import or set low_memory=False.
interactivity=interactivity, compiler=compiler, result=result)
#先使用str打开数据
fec = pd.read_csv('P00000001-ALL.csv',dtype={'contbr_zip':str})
#然后使用str函数isdigit()判断单元格是否全为数字
fec_isnum=fec.iloc[:,6].str.isdigit()
#得到使用bool索引把全为数字的表格cleaned
cleaned = fec[fec_isnum].copy()
补充:pandas如何去掉、过滤数据集中的某些值或者某些行?
在进行数据分析与清理中,我们可能常常需要在数据集中去掉某些异常值。具体来说,看看下面的例子。
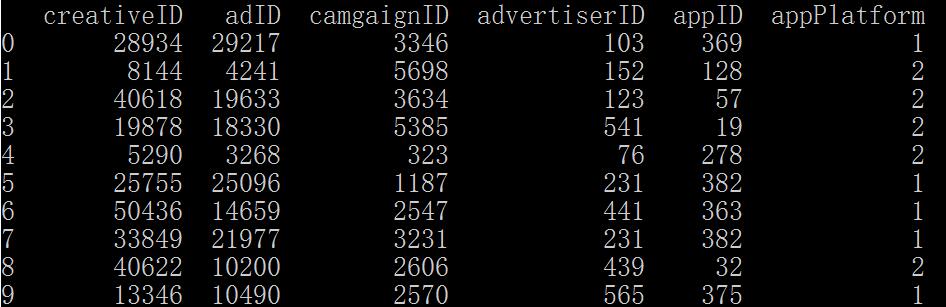
0.导入我们需要使用的包
import pandas as pd
pandas是很常用的数据分析,数据处理的包。anaconda已经有这个包了,纯净版python的可以自行pip安装。
1.去掉某些具体值
数据集df中,对于属性appPlatform(最后一列),我们想删除掉取值为2的那些样本。
如何做?非常简单。
import pandas as pd df[(True-df['appPlatform'].isin([2]))]

当然,有时候我们需要去掉不止一个值,这个时候只需要在isin([])的列表中添加。更具体来说,例如,对于appID这个属性,我们想去掉appID=278和appID=382的样本。
df[(True-df['appID'].isin([278,382]))]
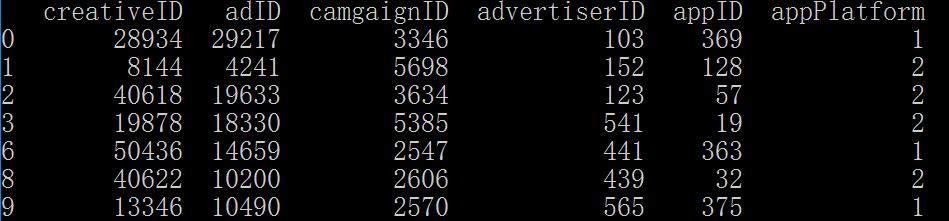
另外,我们有时候并不只是考虑某一列,还需要考虑另外若干列的情况。例如,我们需要过滤掉appPlatform=2而且appID=278和appID=382的样本呢?非常简单。
df[(True-df['appID'].isin([278,382]))&(True-df['appPlatform'].isin([2]))]
其实,在这里我们看到,就是由两部分组成的,第一部分就是appID中等于278和382的,另外一部分就是appPlatform中等于2的。两者取逻辑关系 与(&)

2.过滤掉某个范围的值
上面我们是了解了如何取掉某个具体值,下面,我们要看看如何过滤掉某个范围的值。
对于数据集df,我们想过滤掉creativeID(第一列)中ID值大于10000的样本。
df[df['creativeID']<=10000]

另外,如果要考虑多列的话,其实和上面一样,将两种情况做逻辑与(&)就可以,不过值得注意的是,每个条件要用括号()括起来。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
详解pandas删除缺失数据(pd.dropna()方法)
1.创建带有缺失值的数据库: import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(5, 3), index = list('abcde'), columns = ['one', 'two', 'three']) # 随机产生5行3列的数据 df.ix[1, :-1] = np.nan # 将指定数据定义为缺失 df.ix[1:-1, 2] = np.nan print('\ndf1') # 输出df1,
-
python pandas消除空值和空格以及 Nan数据替换方法
在人工采集数据时,经常有可能把空值和空格混在一起,一般也注意不到在本来为空的单元格里加入了空格.这就给做数据处理的人带来了麻烦,因为空值和空格都是代表的无数据,而pandas中Series的方法notnull()会把有空格的数据也纳入进来,这样就不能完整地得到我们想要的数据了,这里给出一个简单的方法处理该问题. 方法1: 既然我们认为空值和空格都代表无数据,那么可以先得到这两种情况下的布尔数组. 这里,我们的DataFrame类型的数据集为df,其中有一个变量VIN,那么取得空值和空格的布尔数组
-
利用Pandas来清除重复数据的实现方法
一.前言 最近刚好在练手一个数据挖掘的项目,众所周知,数据挖掘中比较重要的一步为数据清洗,而对重复数据的处理也是数据清洗中经常碰到的一项.本文将仅介绍如何利用Pandas来清除重复数据(主要指重复行),话不多说请看下文. 二.具体介绍 2.1. 导入Pandas库 pandas是python的核心数据分析库,你可以把它理解为python版的excel,倘若你还没有安装相应的库,请查询相关教程进行安装,导入pandas的代码为: import pandas as pd 2.2. DataFrame
-

Pandas剔除混合数据中非数字的数据操作
我们日常拿到的数据,指标字段有时会混入非数字的数据,这时候会影响我们的操作 name height Hang 180 Ben 145 Cho notknow XIn 189 比如read_csv读入时,该列会以object形式读入,也不能直接进行计算,不然会出现如unsupported operand type(s) for +: 'float' and 'str'的错误 这时候就需要进行数据预处理,清除掉指标值中非数字的数据,这里我以2012_FederalElectionCommission
-
使用pandas读取表格数据并进行单行数据拼接的详细教程
业务需求 一个几十万条数据的Excel表格,现在需要拼接其中某一列的全部数据为一个字符串,例如下面简短的几行表格数据: id code price num 11 22 33 44 22 33 44 55 33 44 55 66 44 55 66 77 55 66 77 88 66 77 88 99 现在需要将code的这一列用逗号,拼接为字符串,并且每个单元格数据都用单引号包含,需要拼接成字符串'22','33','44','55','66','77',这样的情况,我们需要怎么处理呢?当然方式有
-
python:pandas合并csv文件的方法(图书数据集成)
数据集成:将不同表的数据通过主键进行连接起来,方便对数据进行整体的分析. 两张表:ReaderInformation.csv,ReaderRentRecode.csv ReaderInformation.csv: ReaderRentRecode.csv: pandas读取csv文件,并进行csv文件合并处理: # -*- coding:utf-8 -*- import csv as csv import numpy as np # ------------- # csv读取表格数据 # ---
-
pandas 使用apply同时处理两列数据的方法
多的不说,看了代码就懂了! df = pd.DataFrame ({'a' : np.random.randn(6), 'b' : ['foo', 'bar'] * 3, 'c' : np.random.randn(6)}) def my_test(a, b): return a + b df['Value'] = df.apply(lambda row: my_test(row['a'], row['c']), axis=1) print df 以上这篇pandas 使用apply同时处理两列
-
pandas pivot_table() 按日期分多列数据的方法
如下所示: date 20170307 20170308 iphone4 2 0 iphone5 2 1 iphone6 0 1 先生成DF数据. >>> df = pd.DataFrame.from_dict([['ip4','20170307',1],['ip4','20170307',1],['ip5','20170307',1],['ip5','20170307',1],['ip6','20170308',1],['ip5','20170308',1]]) >>>
-
利用pandas向一个csv文件追加写入数据的实现示例
我们越来越多的使用pandas进行数据处理,有时需要向一个已经存在的csv文件写入数据,传统的方法之前我也有些过,向txt,excel文件写入数据,传送门:Python将二维列表(list)的数据输出(TXT,Excel) pandas to_csv()只能在新文件写数据?当然不是! pandas to_csv() 是可以向已经存在的具有相同结构的csv文件增加dataframe数据. df.to_csv('my_csv.csv', mode='a', header=False) to_csv(
-
Pandas将列表(List)转换为数据框(Dataframe)
Python中将列表转换成为数据框有两种情况:第一种是两个不同列表转换成一个数据框,第二种是一个包含不同子列表的列表转换成为数据框. 第一种:两个不同列表转换成为数据框 from pandas.core.frame import DataFrame a=[1,2,3,4]#列表a b=[5,6,7,8]#列表b c={"a" : a, "b" : b}#将列表a,b转换成字典 data=DataFrame(c)#将字典转换成为数据框 print(data) 输出的结
-
pandas删除某行或某列数据的实现示例
目录 1.drop()函数 2.del函数 首先,创建一个DataFrame格式数据作为举例数据. # 创建一个DataFrame格式数据 data = {'a': ['a0', 'a1', 'a2'], 'b': ['b0', 'b1', 'b2'], 'c': [i for i in range(3)], 'd': 4} df = pd.DataFrame(data) print('举例数据情况:\n', df) 注:DataFrame是最常用的pandas对象,使用pandas读取数据文件
-
使用Python制作一个数据预处理小工具(多种操作一键完成)
在我们平常使用Python进行数据处理与分析时,在import完一大堆库之后,就是对数据进行预览,查看数据是否出现了缺失值.重复值等异常情况,并进行处理. 本文将结合GUI工具PySimpleGUI,来讲解如何制作一款属于自己的数据预处理小工具,让这个过程也能够自动化!最终效果如下 本文将分为三部分讲解: 制作GUI界面 数据处理讲解 打包与测试 主要涉及将涉及以下模块: PySimpleGUI pandas matplotlib 一.GUI界面制作 思路 老规矩,先讲思路再上代码,首先还是说一