Jupyter Notebook读入csv文件时出错的解决方案
问题
jupyter notebook读入csv数据时出现错误
“SyntaxError: (unicode error) ‘unicodeescape' codec can't decode bytes in position 2-3: truncated \UX”

解决方法
将文件路径中'C:\Users\huangyanli\Desktop\churn.csv'的“\”改为“\\”就可以了。

完美解决问题。
补充:Jupyter notebook 导出的csv 文件是乱码的解决方案
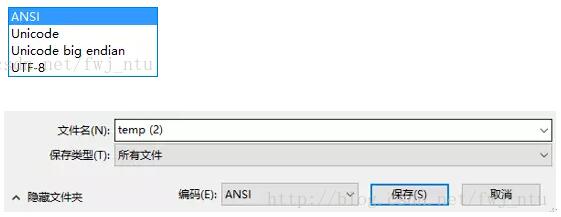
本人使用的是Jupyter notebook 编辑器做数据分析的,API 是pyspark,有时候需要把 pyspark DataFrame 转成 pandas Dataframe,然后转成CSV 文件去汇报工作,发现有中文导出的时候是乱码,问了运维的同事的他们已经设置成了UTF-8 的模式,我在代码里也设置了UTF-8 .后来发现是CSV的问题,先将CSV用txt记事本打开,然后选择ANSI编码方式。
另存为,点编码这里,这里的编码有这么几种选择,最后用excel去打开就可以了。
pyspark 导出代码:
aa1 = aa.toPandas()
aa1.to_csv('output_file.csv')
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
jupyter notebook指定启动目录的方法
问题来源 jupyter notebook在命令行中启动之后,默认根目录为命令行的当前目录,这样便利性较差. 下面给出了三种指定启动目录的方法,分别适用于不同场景. 解决方法 方法一:先在命令行中切换到指定目录,再运行jupyter notebook 这种方法是比较常规的方法,也是最简单的解决方法. 每次运行jupyter notebook之前,先在命令行中利用cd命令切换目录,然后再运行jupyter notebook. 方法二:修改默认打开位置,适合每次在固定目录运行jupyter note
-

详解如何修改jupyter notebook的默认目录和默认浏览器
1 修改默认目录 最近刚刚开始学习Python,比较好的一个IDE就是jupyter Notebook.可以一个cell一个cell的显示结果,对于新手学习Python非常的实用. 但是有个蛋疼的地方就是,每次打开Notebook看到的都是c盘上"我的文档"上的文件.查了一些资料终于把默认路径改了. 方法如下: 1 .找到一个用于存放config文件的文件夹,用cmd来查找路径: 在cmd中 输入命令 jupyter notebook --generate-config(前面是两个-
-
Jupyter Notebook 远程访问配置详解
问题 Jupyter Notebook可以说是非常好用的小工具,但是不经过配置只能够在本机访问 笔者参阅了文档对jupyter notebook进行配置,实现了跨主机浏览器访问 安装jupyter notebook 笔者使用conda包管理 conda install jupyter notebook 生成默认配置文件 jupyter notebook --generate-config 将会在用户主目录下生成.jupyter文件夹,其中jupyter_notebook_config.py就是刚
-
docker容器下配置jupyter notebook的操作
docker容器下配置jupyter notebook,主要是为了编写python代码,更具体点是做深度学习的开发. jupyter web形式最高效的使用方式就是部署在云上,不管是cpu云服务器还是gpu的云服务器,都能快速启动使用. 而docker的出现又方便了很多在部署使用上. - 安装 docker docker分为docker CE和docker EE,一般使用docker CE(社区版本). docker可以在Linux(ubuntu.centos).MacOS.Windows或者树
-
jupyter notebook中图片显示不出来的解决
报错: D:\Program Files\Anaconda3\lib\site-packages\matplotlib\figure.py:445: UserWarning: Matplotlib is currently using module://ipykernel.pylab.backend_inline, which is a non-GUI backend, so...... 解决方法: import matplotlib matplotlib.use('TkAgg') import
-
jupyter 导入csv文件方式
先将准备的文件上传到自己的jupyter工作空间 import numpy as np import pandas as pd housing = pd.read_csv('housing.csv') 补充知识:在jupyter中读取CSV文件时出现'utf-8' codec can't decode byte 0xd5 in position 0: invalid continuation byte解决方法 导入 import pandas as pd 使用pd.read_csv()读csv文
-
详解修改Anaconda中的Jupyter Notebook默认工作路径的三种方式
方式1. 打开Windows的cmd,在cmd中输入jupyter notebook --generate-config如下图: 可以看到路径为D:\Users--找到此路径修改jupyter_notebook_config.py文件 打开此文件找到 ## The directory to use for notebooks and kernels. #c.NotebookApp.notebook_dir = '' 将其改为 ## The directory to use for noteboo
-
jupyter notebook远程访问不了的问题解决方法
jupyter notebook非常方便,想在服务器上面搭建一个,但是访问不了. (一)首先是安装jupyter notebook, pip install jupyter 如果pip安装报错,缺少sqlite的库,那么请安装 sudo apt-get install libsqlite3-dev 然后需要"重新编译python",再通过pip安装(python3.x则不需要安装pysqlite) pip install pysqlite (二)启动jupyter jupyter no
-
Jupyter Notebook读入csv文件时出错的解决方案
问题 jupyter notebook读入csv数据时出现错误 "SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated \UX" 解决方法 将文件路径中'C:\Users\huangyanli\Desktop\churn.csv'的"\"改为"\\"就可以了. 完美解决问题. 补充:Jupyter noteb
-
Jupyter Notebook读取csv文件出现的问题及解决
目录 Jupyter Notebook读取csv文件失败 Excel跨表使用注意事项(包含jupyter读取csv) (1)问题 (2)问题 (3)问题 总结 Jupyter Notebook读取csv文件失败 1.IndentationError: expected an indented block 缩进错误,在报错代码块前加一个空格. 在data前加一个空格. 2.No such file or directory: ‘weatherdata.csv’ 找不到文件,我的weatherdat
-
Python如何读取csv文件时添加表头/列名
目录 读取csv文件时添加表头/列名 解决方法 更改csv文件表头 读取csv文件时添加表头/列名 有时,我们读取的csv文件数据时发现没有表头/列名,是因为Python读取csv文件数据本来就没有表头,用pandas.read读取时,则第一行自动会被识别为columns,从而给后面的分析造成不便,这时候需要我们在读取文件数据的同时添加列名. 解决方法 1.在读取文件数据之后再定义列名 df = pd.read_csv('评论.csv',header=None) df.columns = ["昵
-
处理 SSI 文件时出错的解决方法
IIS6.0对于SSI进行了一些改进,以前IIS5.0的一些程序迁移过后可能无法运用. 一个经常的出现问题是出现如下错误: 处理 SSI 文件时出错 - Error processing SSI file 经过测试,以下做法会导致这个错误: 1.服务器物理路径使用中文名. 2.包含文件中使用中文名. 3.包含文件不存在. 4.被包含的文件再次包含使用中文名的文件. 该错误在Unicode编码时依旧,属于IIS设计问题. 解决方法: 对于使用SSI的站点物理和URL地址都全部使用英文.
-
python的pandas工具包,保存.csv文件时不要表头的实例
用pandas处理.csv文件时,有时我们希望保存的.csv文件没有表头,于是我去看了DataFrame.to_csv的document. 发现只需要再添加header=None这个参数就行了(默认是True), 下面贴上document: DataFrame.to_csv(path_or_buf=None, sep=', ', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=Non
-
pandas读取CSV文件时查看修改各列的数据类型格式
下面给大家介绍下pandas读取CSV文件时查看修改各列的数据类型格式,具体内容如下所述: 我们在调bug的时候会经常查看.修改pandas列数据的数据类型,今天就总结一下: 1.查看: Numpy和Pandas的查看方式略有不同,一个是dtype,一个是dtypes print(Array.dtype) #输出int64 print(df.dtypes) #输出Df下所有列的数据格式 a:int64,b:int64 2.修改 import pandas as pd import numpy a
-
Jupyter Notebook打开任意文件夹操作
废话不多说 1.win+R 启动"运行" 输入cmd 点确定 2.输入 cd /d xxxxxxx 回车 jupyter notebook 回车 在这里我想打开H:\机器学习入门 3.等待一会,在浏览器中自动跳出 也可以复制图2中红框的内容,在浏览器中打开 完成! 补充知识:关于在JupyterNotebook下导入自己的模块的问题 在jupyternotebook下导入自己写的模块,有两点需要注意: 1.要将自己写的模块编程xxx.py的形式,而不是.ipynb文件 2.当更改自己的
-
python中pandas读取csv文件时如何省去csv.reader()操作指定列步骤
优点: 方便,有专门支持读取csv文件的pd.read_csv()函数. 将csv转换成二维列表形式 支持通过列名查找特定列. 相比csv库,事半功倍 1.读取csv文件 import pandas as pd file="c:\data\test.csv" csvPD=pd.read_csv(file) df = pd.read_csv('data.csv', encoding='gbk') #指定编码 read_csv()方法参数介绍 filepath_or_buf
-
微信昵称带符号导致插入MySQL数据库时出错的解决方案
Mysql的utf8编码最多3个字节,而Emoji表情或者某些特殊字符是4个字节. 因此会导致带有表情的昵称插入数据库时出错. 只要修改MySQL的编码即可,解决方案如下: 1.在mysql的安装目录下找到my.ini,作如下修改: [mysqld] character-set-server=utf8mb4 [mysql] default-character-set=utf8mb4 2 重启mysql服务 3 修改表 ALTER TABLE 表名 CONVERT TO CHARACTER SET
-
python读csv文件时指定行为表头或无表头的方法
pd.read_csv()方法中header参数,默认为0,标签为0(即第1行)的行为表头.若设置为-1,则无表头.示例如下: (1)不设置header参数(默认)时: df1 = pd.read_csv('target.csv',encoding='utf-8') df1 (2)header=1时: import pandas as pd df2 = pd.read_csv('target.csv',encoding='utf-8',header=1) df2 (3)header=-1时(可用