Python进阶多线程爬取网页项目实战
目录
- 一、网页分析
- 二、代码实现
一、网页分析
这次我们选择爬取的网站是水木社区的Python页面
网页:https://www.mysmth.net/nForum/#!board/Python?p=1

根据惯例,我们第一步还是分析一下页面结构和翻页时的请求。



通过前三页的链接分析后得知,每一页链接中最后的参数是页数,我们修改它即可得到其他页面的数据。
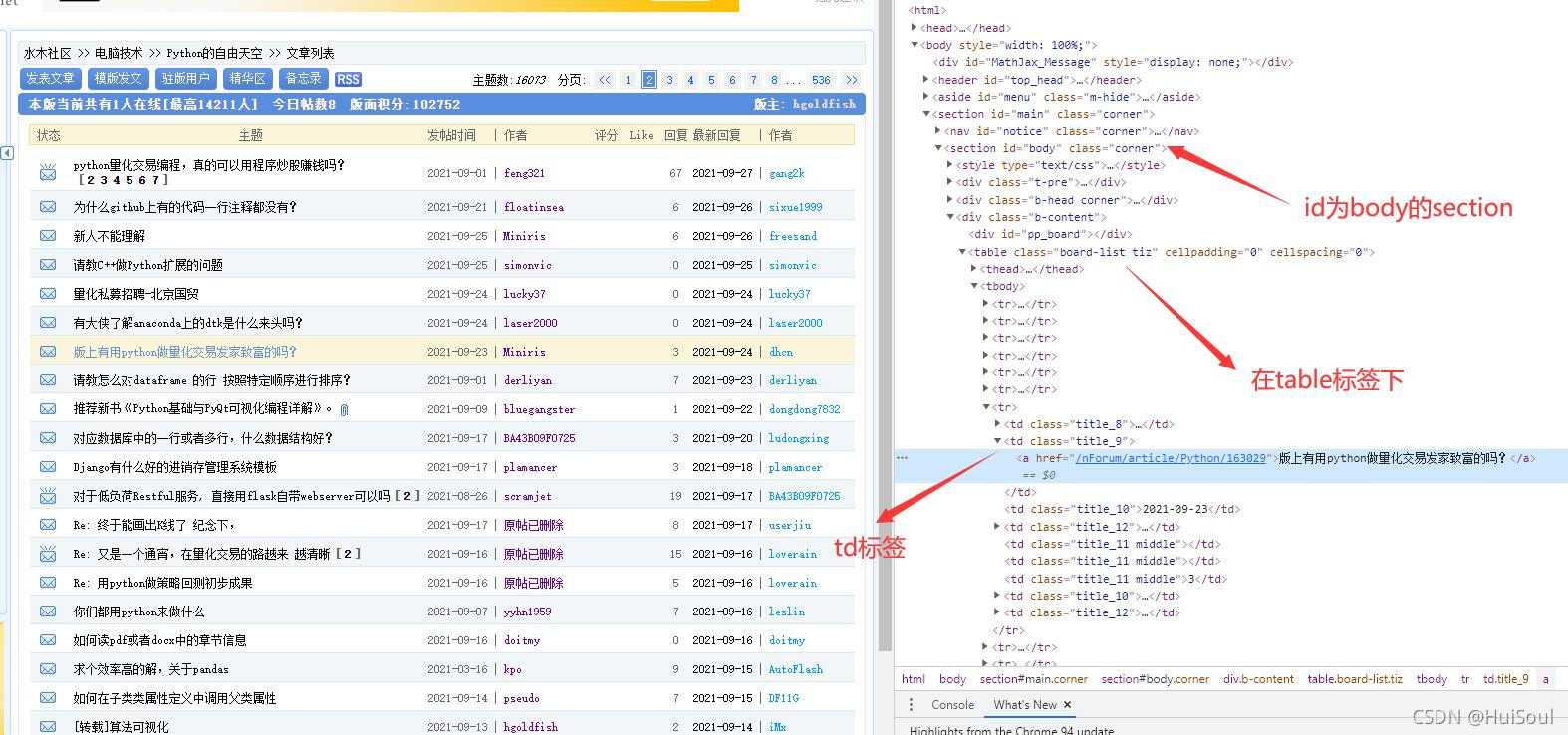
再来分析一下,我们需要获取帖子的链接就在id 为 body 的 section下,然后一层一层找到里面的 table,我们就能遍历这些链接的标题。
我们点开一篇帖子:https://www.mysmth.net/nForum/#!article/Python/162717
和前面一样,我们先分析标题和内容在网页中的结构
不难发现,主题部分只要找到 id 为 main 的 section 下面的 class 为 b-head corner 的下面第二个 span即可
主题部分

而内容部分只要找到class 为 a-wrap corner 的 div,找到下面的 a-content即可。
内容部分

分析网页结构后,我们就可以开始写代码了!
二、代码实现
首先要确定要保存什么内容:这次我们保存水木社区 Python 版面前 10 页的所有帖子标题和帖子第一页的所有回复。
解析列表页,得到所有的帖子链接
from bs4 import BeautifulSoup
# 解析列表页内容,得到这一页的内容链接
def parse_list_page(text):
soup = BeautifulSoup(text, 'html.parser')
# 下面相当于 soup.find('table', class_='board-list tiz').find('tbody')
tbody = soup.find('table', class_='board-list tiz').tbody
urls = []
for tr in tbody:
td = tr.find('td', class_='title_9')
urls.append(td.a.attrs['href'])
return urls
解析内容页,得到标题和这一页的所有帖子内容
# 解析内容页,得到标题和所有帖子内容
def parse_content_page(text):
soup = BeautifulSoup(text, 'html.parser')
title = soup.find('span', class_='n-left').text.strip('文章主题:').strip()
content_div = soup.find('div', class_='b-content corner')
contents = []
for awrap in content_div.find_all('div', class_='a-wrap corner'):
content = awrap.p.text
contents.append(content)
return title, contents
把列表页的链接转换成我们要抓取的链接
def convert_content_url(path): URL_PREFIX = 'http://www.mysmth.net' path += '?ajax' return URL_PREFIX + path
生成前 10 页的列表页链接
list_urls = [] for i in range(1, 11): url = 'http://www.mysmth.net/nForum/board/Python?ajax&p=' url += str(i) list_urls.append(url)
下面是得到前 10 页列表页里所有正文的链接。这个时候我们使用线程池的方式来运行
import requests
from concurrent import futures
session = requests.Session()
executor = futures.ThreadPoolExecutor(max_workers=5)
# 这个函数获取列表页数据,解析出链接,并转换成真实链接
def get_content_urls(list_url):
res = session.get(list_url)
content_urls = parse_list_page(res.text)
real_content_urls = []
for url in content_urls:
url = convert_content_url(url)
real_content_urls.append(url)
return real_content_urls
# 根据刚刚生成的十个列表页链接,开始提交任务
fs = []
for list_url in list_urls:
fs.append(executor.submit(get_content_urls, list_url))
futures.wait(fs)
content_urls = set()
for f in fs:
for url in f.result():
content_urls.add(url)
在这里要注意一下,第 23 行中我们使用了 set() 函数,作用是去除重复值。它的原理是创建一个 Set(集合),集合 是 Python 中的一种特殊数据类型,其中可以包含多个元素,但是不能重复。我们来看看 set() 的用法
numbers = [1, 1, 2, 2, 2, 3, 4]
unique = set(numbers)
print(type(unique))
# 输出:<class 'set'>
print(unique)
# 输出:{1, 2, 3, 4}
我们看到,set() 将列表 numbers 转换成了没有重复元素的集合 {1, 2, 3, 4}。
我们利用这个特性,首先在 23 行通过 content_urls = set() 创建了一个空集合,之后在其中添加链接时,就会自动去除多次出现的链接。
得到了所有正文链接之后,我们解析正文页内容,放到一个字典里
# 获取正文页内容,解析出标题和帖子
def get_content(url):
r = session.get(url)
title, contents = parse_content_page(r.text)
return title, contents
# 提交解析正文的任务
fs = []
for url in content_urls:
fs.append(executor.submit(get_content, url))
futures.wait(fs)
results = {}
for f in fs:
title, contents = f.result()
results[title] = contents
print(results.keys())
就这样,我们完成了多线程的水木社区爬虫。打印 results.keys() 可以看到所有帖子的标题。
这次爬取了前十页的所有主题,以及他们的第一页回复。一共 10 个列表页、300 个主题页,解析出 1533 条回复。在一台网络良好、性能普通的机器上测试执行只花费了 13 秒左右。
完整代码如下
import requests
from concurrent import futures
from bs4 import BeautifulSoup
# 解析列表页内容,得到这一页的内容链接
def parse_list_page(text):
soup = BeautifulSoup(text, 'html.parser')
tbody = soup.find('table', class_='board-list tiz').tbody
urls = []
for tr in tbody:
td = tr.find('td', class_='title_9')
urls.append(td.a.attrs['href'])
return urls
# 解析内容页,得到标题和所有帖子内容
def parse_content_page(text):
soup = BeautifulSoup(text, 'html.parser')
title = soup.find('span', class_='n-left').text.strip('文章主题:').strip()
content_div = soup.find('div', class_='b-content corner')
contents = []
for awrap in content_div.find_all('div', class_='a-wrap corner'):
content = awrap.p.text
contents.append(content)
return title, contents
# 把列表页得到的链接转换成我们要抓取的链接
def convert_content_url(path):
URL_PREFIX = 'http://www.mysmth.net'
path += '?ajax'
return URL_PREFIX + path
# 生成前十页的链接
list_urls = []
for i in range(1, 11):
url = 'http://www.mysmth.net/nForum/board/Python?ajax&p='
url += str(i)
list_urls.append(url)
session = requests.Session()
executor = futures.ThreadPoolExecutor(max_workers=5)
# 这个函数获取列表页数据,解析出链接,并转换成真实链接
def get_content_urls(list_url):
res = session.get(list_url)
content_urls = parse_list_page(res.text)
real_content_urls = []
for url in content_urls:
url = convert_content_url(url)
real_content_urls.append(url)
return real_content_urls
# 根据刚刚生成的十个列表页链接,开始提交任务
fs = []
for list_url in list_urls:
fs.append(executor.submit(get_content_urls, list_url))
futures.wait(fs)
content_urls = set()
for f in fs:
for url in f.result():
content_urls.add(url)
# 获取正文页内容,解析出标题和帖子
def get_content(url):
r = session.get(url)
title, contents = parse_content_page(r.text)
return title, contents
# 提交解析正文的任务
fs = []
for url in content_urls:
fs.append(executor.submit(get_content, url))
futures.wait(fs)
results = {}
for f in fs:
title, contents = f.result()
results[title] = contents
print(results.keys())
本次分享到此结束,谢谢大家阅读!!
有问题欢迎评论区留言!!
更多关于Python多线程爬取网页实战的资料请关注我们其它相关文章!
相关推荐
-
python面向对象多线程爬虫爬取搜狐页面的实例代码
首先我们需要几个包:requests, lxml, bs4, pymongo, redis 1. 创建爬虫对象,具有的几个行为:抓取页面,解析页面,抽取页面,储存页面 class Spider(object): def __init__(self): # 状态(是否工作) self.status = SpiderStatus.IDLE # 抓取页面 def fetch(self, current_url): pass # 解析页面 def parse(self, html_page): pass
-
python爬虫开发之使用Python爬虫库requests多线程抓取猫眼电影TOP100实例
使用Python爬虫库requests多线程抓取猫眼电影TOP100思路: 查看网页源代码 抓取单页内容 正则表达式提取信息 猫眼TOP100所有信息写入文件 多线程抓取 运行平台:windows Python版本:Python 3.7. IDE:Sublime Text 浏览器:Chrome浏览器 1.查看猫眼电影TOP100网页原代码 按F12查看网页源代码发现每一个电影的信息都在"<dd></dd>"标签之中. 点开之后,信息如下: 2.抓取单页内容 在浏
-
python爬虫爬取快手视频多线程下载功能
环境: python 2.7 + win10 工具:fiddler postman 安卓模拟器 首先,打开fiddler,fiddler作为http/https 抓包神器,这里就不多介绍. 配置允许https 配置允许远程连接 也就是打开http代理 电脑ip: 192.168.1.110 然后 确保手机和电脑是在一个局域网下,可以通信.由于我这边没有安卓手机,就用了安卓模拟器代替,效果一样的. 打开手机浏览器,输入192.168.1.110:8888 也就是设置的代理地址,安装证书之后才能
-

Python之多线程爬虫抓取网页图片的示例代码
目标 嗯,我们知道搜索或浏览网站时会有很多精美.漂亮的图片. 我们下载的时候,得鼠标一个个下载,而且还翻页. 那么,有没有一种方法,可以使用非人工方式自动识别并下载图片.美美哒. 那么请使用python语言,构建一个抓取和下载网页图片的爬虫. 当然为了提高效率,我们同时采用多线程并行方式. 思路分析 Python有很多的第三方库,可以帮助我们实现各种各样的功能.问题在于,我们弄清楚我们需要什么: 1)http请求库,根据网站地址可以获取网页源代码.甚至可以下载图片写入磁盘. 2)解析网页源代码,
-
Python进阶多线程爬取网页项目实战
目录 一.网页分析 二.代码实现 一.网页分析 这次我们选择爬取的网站是水木社区的Python页面 网页:https://www.mysmth.net/nForum/#!board/Python?p=1 根据惯例,我们第一步还是分析一下页面结构和翻页时的请求. 通过前三页的链接分析后得知,每一页链接中最后的参数是页数,我们修改它即可得到其他页面的数据. 再来分析一下,我们需要获取帖子的链接就在id 为 body 的 section下,然后一层一层找到里面的 table,我们就能遍历这些链接的标题
-
Python进阶篇之多线程爬取网页
目录 一.前情提要 二.并发的概念 三.并发与多线程 四.线程池 一.前情提要 相信来看这篇深造爬虫文章的同学,大部分已经对爬虫有不错的了解了,也在之前已经写过不少爬虫了,但我猜爬取的数据量都较小,因此没有过多的关注爬虫的爬取效率.这里我想问问当我们要爬取的数据量为几十万甚至上百万时,我们会不会需要要等几天才能将数据全都爬取完毕呢? 唯一的办法就是让爬虫可以 7×24 小时不间断工作.因此我们能做的就是多叫几个爬虫一起来爬数据,这样便可大大提升爬虫的效率. 但在介绍Python 如何让多个爬虫一
-
Python实现多线程抓取网页功能实例详解
本文实例讲述了Python实现多线程抓取网页功能.分享给大家供大家参考,具体如下: 最近,一直在做网络爬虫相关的东西. 看了一下开源C++写的larbin爬虫,仔细阅读了里面的设计思想和一些关键技术的实现. 1.larbin的URL去重用的很高效的bloom filter算法: 2.DNS处理,使用的adns异步的开源组件: 3.对于url队列的处理,则是用部分缓存到内存,部分写入文件的策略. 4.larbin对文件的相关操作做了很多工作 5.在larbin里有连接池,通过创建套接字,向目标站点
-
详解python定时简单爬取网页新闻存入数据库并发送邮件
本人小白一枚,简单记录下学校作业项目,代码十分简单,主要是对各个库的理解,希望能给别的初学者一点启发. 一.项目要求 1.程序可以从北京工业大学首页上爬取新闻内容:http://www.bjut.edu.cn 2.程序可以将爬取下来的数据写入本地MySQL数据库中. 3.程序可以将爬取下来的数据发送到邮箱. 4.程序可以定时执行. 二.项目分析 1.爬虫部分利用requests库爬取html文本,再利用bs4中的BeaultifulSoup库来解析html文本,提取需要的内容. 2.使用pymy
-
Python用requests-html爬取网页的实现
目录 1. 开始 2. 原理 3. 元素定位 css 选择器 4. CSS 简单规则 5. Xpath简单规则 6. 人性化操作 7. 加载 js 8. 总结 1. 开始 Python 中可以进行网页解析的库有很多,常见的有 BeautifulSoup 和 lxml 等.在网上玩爬虫的文章通常都是介绍 BeautifulSoup 这个库,我平常也是常用这个库,最近用 Xpath 用得比较多,使用 BeautifulSoup 就不大习惯,很久之前就知道 Reitz 大神出了一个叫 Requests
-
Python 爬虫批量爬取网页图片保存到本地的实现代码
其实和爬取普通数据本质一样,不过我们直接爬取数据会直接返回,爬取图片需要处理成二进制数据保存成图片格式(.jpg,.png等)的数据文本. 现在贴一个url=https://img.ivsky.com/img/tupian/t/201008/05/bianxingjingang-001.jpg 请复制上面的url直接在某个浏览器打开,你会看到如下内容: 这就是通过网页访问到的该网站的该图片,于是我们可以直接利用requests模块,进行这个图片的请求,于是这个网站便会返回给我们该图片的数据,我们
-
python结合多线程爬取英雄联盟皮肤(原理分析)
1.什么是多线程? 多线程是为了同步完成多项任务,不是为了提高运行效率,而是为了提高资源使用效率来提高系统的效率.线程是在同一时间需要完成多项任务的时候实现的. 为什么要使用多线程 线程在程序中是独立的.并发的执行流.与分隔的进程相比,进程中线程之间的隔离程度要小,它们共享内存.文件句柄和其他进程应有的状态. 因为线程的划分尺度小于进程,使得多线程程序的并发性高.进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率. 线程比进程具有更高的性能,这是由于同一个进程
-
Python基于pandas爬取网页表格数据
以网页表格为例:https://www.kuaidaili.com/free/ 该网站数据存在table标签,直接用requests,需要结合bs4解析正则/xpath/lxml等,没有几行代码是搞不定的. 今天介绍的黑科技是pandas自带爬虫功能,pd.read_html(),只需传人url,一行代码搞定. 原网页结构如下: python代码如下: import pandas as pd url='http://www.kuaidaili.com/free/' df=pd.read_html
-
Python如何利用正则表达式爬取网页信息及图片
一.正则表达式是什么? 概念: 正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符.及这些特定字符的组合,组成一个"规则字符串",这个"规则字符串"用来表达对字符串的一种过滤逻辑. 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配. 个人理解: 简单来说就是使用正则表达式来写一个过滤器来过滤了掉杂乱的无用的信息(eg:网页源代码-)从中来获取自己想要的内容 二.实战项目 1.爬取内容 获取上海所有三甲医院的名称并保
-
python爬虫爬取网页表格数据
用python爬取网页表格数据,供大家参考,具体内容如下 from bs4 import BeautifulSoup import requests import csv import bs4 #检查url地址 def check_link(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('无法链接服务器!!!')