python实现精准搜索并提取网页核心内容
目录
- 各种尝试
- 生成PDF
- 提取文章内容
- 选择最优
- 总结

文 | 李晓飞
来源:Python 技术「ID: pythonall」
爬虫程序想必大家都很熟悉了,随便写一个就可以获取网页上的信息,甚至可以通过请求自动生成 Python 脚本[1]。
最近我遇到一个爬虫项目,需要爬取网上的文章。感觉没有什么特别的,但问题是没有限定爬取范围,意味着没有明确的页面的结构。
对于一个页面来说,除了核心文章内容外,还有头部,尾部,左右列表栏等等。有的页面框架用 div 布局,有的用 table,即使都用 div,不太的网站风格和布局也不同。
但问题必须解决,我想,既然搜索引擎抓取到各种网页的核心内容,我们也应该可以搞定,拎起 Python, 说干就干!
各种尝试
如何解决呢?
生成PDF
开始想了一个取巧的方法,就是利用工具(wkhtmltopdf[2])将目标网页生成 PDF 文件。
好处是不必关心页面的具体形式,就像给页面拍了一张照片,文章结构是完整的。
虽然 PDF 是可以源码级检索,但是,生成 PDF 有诸多缺点:
耗费计算资源多、效率低、出错率高,体积太大。
几万条数据已经两百多G,如果数据量上来光存储就是很大的问题。
提取文章内容
不生成PDF,有简单办法就是通过 xpath[3] 提取页面上的所有文字。
但是内容将失去结构,可读性差。更要命的是,网页上有很多无关内容,比如侧边栏,广告,相关链接等,也会被提取下来,影响内容的精确性。
为了保证有一定的结构,还要识别到核心内容,就只能识别并提取文章部分的结构了。像搜索引擎学习,就是想办法识别页面的核心内容。
我们知道,通常情况下,页面上的核心内容(如文章部分)文字比较集中,可以从这个地方着手分析。
于是编写了一段代码,我是用 Scrapy[4] 作为爬虫框架的,这里只截取了其中提取文章部分的代码 :
divs = response.xpath("body//div")
sel = None
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
value = ps - ds
if value > maxvalue:
sel = {
"node": d,
"value": value
}
maxvalue = value
print("".join(sel['node'].getall()))
response是页面的一个响应,其中包含了页面的所有内容,可以通过xpath提取想要的部分"body//div"的意思是提取所以body标签下的div子标签,注意://操作是递归的- 遍历所有提取到的标签,计算其中包含的
div数量,和p数量 p数量 和div数量的差值作为这个元素的权值,意思是如果这个元素里包含了大量的p时,就认为这里是文章主体- 通过比较权值,选择出权值最大的元素,这便是文章主体
- 得到文章主体之后,提取这个元素的内容,相当于 jQuery[5] 的
outerHtml
简单明了,测试了几个页面确实挺好。
不过大量提取时发现,很多页面提取不到数据。仔细查看发现,有两种情况。
- 有的文章内容被放在了
<article>标签里了,所以没有获取到 - 有的文章每个
<p>外面都包裹了一个<div>,所以p的数量 和div的抵消了
再调整了一下策略,不再区分 div,查看所有的元素。
另外优先选择更多的 p,在其基础上再看更少的 div。调整后的代码如下:
divs = response.xpath("body//*")
sels = []
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
if ps >= maxvalue:
sel = {
"node": d,
"ps": ps,
"ds": ds
}
maxvalue = ps
sels.append(sel)
sels.sort(lambda x: x.ds)
sel = sels[0]
print("".join(sel['node'].getall()))
- 方法主体里,先挑选出
p数量比较大的节点,注意if判断条件中 换成了>=号,作用时筛选出同样具有p数量的结点 - 经过筛选之后,按照
div数量排序,然后选取div数量最少的
经过这样修改之后,确实在一定程度上弥补了前面的问题,但是引入了一个更麻烦的问题。
就是找到的文章主体不稳定,特别容易受到其他部分有些 p 的影响。
选择最优
既然直接计算不太合适,需要重新设计一个算法。
我发现,文字集中的地方是往往是文章主体,而前面的方法中,没有考虑到这一点,只是机械地找出了最大的 p。
还有一点,网页结构是个颗 DOM 树[6]
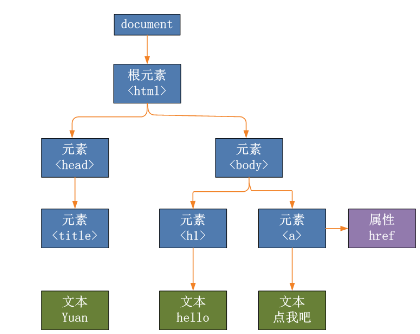
那么越靠近 p 标签的地方应该越可能是文章主体,也就是说,计算是越靠近 p 的节点权值应该越大,而远离 p 的结点及时拥有很多 p 但是权值也应该小一点。
经过试错,最终代码如下:
def find(node, sel):
value = 0
for n in node.xpath("*"):
if n.xpath("local-name()").get() == "p":
t = "".join([s.strip() for s in (n.xpath('text()').getall() + n.xpath("*/text()").getall())])
value += len(t)
else:
value += find(n, a)*0.5
if value > sel["value"]:
sel["node"] = node
sel["value"] = value
return value
sel = {
'value': 0,
'node': None
}
find(response.xpath("body"), sel)
- 定义了一个
find函数,这是为了方便做递归,第一次调用的参数是body标签,和前面一样 - 进入方法里,只找出该节点的直接孩子们,然后遍历这些孩子
- 判断如果孩子是
p节点,提取出其中的所有文字,包括子节点的,然后将文字的长度作为权值 - 提取文字的地方比较绕,先取出直接的文本,和间接文本,合成
list,对每部分文本做了去除前后空字符,最后合并为一个字符串,得到了所包含的文本 - 如果孩子节点不是
p,就递归调用find方法,而find方法返回的是 指定节点所包含的文本长度 - 在获取子节点的长度时,做了缩减处理,用以体现距离越远,权值越低的规则
- 最终通过 引用传递的
sel参数,记录权值最高的节点
通过这样改造之后,效果特别好。
为什么呢?其实利用了密度原理,就是说越靠近中心的地方,密度越高,远离中心的地方密度成倍的降低,这样就能筛选出密度中心了。
50% 的坡度比率是如何得到的呢?
其实是通过实验确定的,刚开始时我设置为 90%,但结果时 body 节点总是最优的,因为 body 里包含了所有的文字内容。
反复实验后,确定 50% 是比较好的值,如果在你的应用中不合适,可以做调整。
总结
描述了我如何选取文章主体的方法后,后没有发现其实很是很简单的方法。而这次解决问题的经历,让我感受到了数学的魅力。
一直以来我认为只要了解常规处理问题的方式就足以应对日常编程了,可以当遇到不确定性问题,没有办法抽取出简单模型的问题时,常规思维显然不行。
所以平时我们应该多看一些数学性强的,解决不确定性问题的方法,以便提高我们的编程适应能力,扩展我们的技能范围。
期望这篇短文能对你有所启发,欢迎在留言区交流讨论,比心!
参考资料
[1]
Curl 转 Python: https://curlconverter.com/
[2]
wkhtmltopdf: https://wkhtmltopdf.org/
[3]
xpath: https://www.w3school.com.cn/xpath/xpath_syntax.asp
[4]
Scrapy: https://scrapy.org/
[5]
jQuery: jquery.com
[6]
DOM 树: https://baike.baidu.com/item/DOM%20Tree/6067246
以上就是python实现精准搜索并提取网页核心内容的详细过程,更多关于python搜索并提取网页内容的资料请关注我们其它相关文章!
相关推荐
-
python基于BeautifulSoup实现抓取网页指定内容的方法
本文实例讲述了python基于BeautifulSoup实现抓取网页指定内容的方法.分享给大家供大家参考.具体实现方法如下: # _*_ coding:utf-8 _*_ #xiaohei.python.seo.call.me:) #win+python2.7.x import urllib2 from bs4 import BeautifulSoup def jd(url): page = urllib2.urlopen(url) html_doc = page.read() soup = B
-
用python3教你任意Html主内容提取功能
本文将和大家分享一些从互联网上爬取语料的经验. 0x1 工具准备 工欲善其事必先利其器,爬取语料的根基便是基于python. 我们基于python3进行开发,主要使用以下几个模块:requests.lxml.json. 简单介绍一个各模块的功能 01|requests requests是一个Python第三方库,处理URL资源特别方便.它的官方文档上写着大大口号:HTTP for Humans(为人类使用HTTP而生).相比python自带的urllib使用体验,笔者认为requests的使用体
-
Python简单实现网页内容抓取功能示例
本文实例讲述了Python简单实现网页内容抓取功能.分享给大家供大家参考,具体如下: 使用模块: import urllib2 import urllib 普通抓取实例: #!/usr/bin/python # -*- coding: UTF-8 -*- import urllib2 url = 'http://www.baidu.com' #创建request对象 request = urllib2.Request(url) #发送请求,获取结果 try: response = urllib2
-
Python爬虫解析网页的4种方式实例及原理解析
这篇文章主要介绍了Python爬虫解析网页的4种方式实例及原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 用Python写爬虫工具在现在是一种司空见惯的事情,每个人都希望能够写一段程序去互联网上扒一点资料下来,用于数据分析或者干点别的事情. 我们知道,爬虫的原理无非是把目标网址的内容下载下来存储到内存中,这个时候它的内容其实是一堆HTML,然后再对这些HTML内容进行解析,按照自己的想法提取出想要的数据,所以今天我们主要来讲四种在Py
-

Python 抓取动态网页内容方案详解
用Python实现常规的静态网页抓取时,往往是用urllib2来获取整个HTML页面,然后从HTML文件中逐字查找对应的关键字.如下所示: 复制代码 代码如下: import urllib2 url="http://mm.taobao.com/json/request_top_list.htm?type=0&page=1" up=urllib2.urlopen(url)#打开目标页面,存入变量up cont=up.read()#从up中读入该HTML文件 key1='<a
-
python实现精准搜索并提取网页核心内容
目录 各种尝试 生成PDF 提取文章内容 选择最优 总结 文 | 李晓飞 来源:Python 技术「ID: pythonall」 爬虫程序想必大家都很熟悉了,随便写一个就可以获取网页上的信息,甚至可以通过请求自动生成 Python 脚本[1]. 最近我遇到一个爬虫项目,需要爬取网上的文章.感觉没有什么特别的,但问题是没有限定爬取范围,意味着没有明确的页面的结构. 对于一个页面来说,除了核心文章内容外,还有头部,尾部,左右列表栏等等.有的页面框架用 div 布局,有的用 table,即使都用 di
-
PHP xpath提取网页数据内容代码解析
想要使用xpath来解析html内容, PHP自带两个对象 DOMDocument,DOMXpath,其中初始化 loadHtml一般都会报很多警告,但是并不影响使用,用@屏蔽错误. /** * 初始化DOMXpath对象 * * @param [type] $content 网页内容 * @param [array] $pathinfo 匹配信息 * * @return void */ private function _createXpathObj($content, $patinfo) {
-
Python+Opencv身份证号码区域提取及识别实现
前端时间智能信息处理实训,我选择的课题为身份证号码识别,对中华人民共和国公民身份证进行识别,提取并识别其中的身份证号码,将身份证号码识别为字符串的形式输出.现在实训结束了将代码发布出来供大家参考,识别的方式并不复杂,并加了一些注释,如果有什么问题可共同讨论.最后重要的事情说三遍:请勿直接抄袭,请勿直接抄袭,请勿直接抄袭!尤其是我的学弟学妹们,还是要自己做的,小心直接拿我的用被老师发现了挨批^_^. 实训环境:CentOS-7.5.1804 + Python-3.6.6 + Opencv-3.4.
-
python使用xslt提取网页数据的方法
1.引言 在Python网络爬虫内容提取器一文我们详细讲解了核心部件:可插拔的内容提取器类gsExtractor.本文记录了确定gsExtractor的技术路线过程中所做的编程实验.这是第一部分,实验了用xslt方式一次性提取静态网页内容并转换成xml格式. 2.用lxml库实现网页内容提取 lxml是python的一个库,可以迅速.灵活地处理 XML.它支持 XML Path Language (XPath) 和 Extensible Stylesheet Language Transform
-
python使用正则表达式提取网页URL的方法
本文实例讲述了python使用正则表达式提取网页URL的方法.分享给大家供大家参考.具体实现方法如下: import re import urllib url="http://www.jb51.net" s=urllib.urlopen(url).read() ss=s.replace(" ","") urls=re.findall(r"<a.*?href=.*?<\/a>",ss,re.I) for i i
-
Python如何利用正则表达式爬取网页信息及图片
一.正则表达式是什么? 概念: 正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符.及这些特定字符的组合,组成一个"规则字符串",这个"规则字符串"用来表达对字符串的一种过滤逻辑. 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配. 个人理解: 简单来说就是使用正则表达式来写一个过滤器来过滤了掉杂乱的无用的信息(eg:网页源代码-)从中来获取自己想要的内容 二.实战项目 1.爬取内容 获取上海所有三甲医院的名称并保
-
Python 数据分析之Beautiful Soup 提取页面信息
概述 数据分析 (Data Analyze) 可以在工作中的各个方面帮助我们. 本专栏为量化交易专栏下的子专栏, 主要讲解一些数据分析的基础知识. Beautiful Soup Beautiful 是一个可以从 HTML 或 XML 文件中提取数据的 Pyhton 库. 简单来说, 它能将 HTML 的标签文件解析成树形结构, 然后方便的获取到指定标签的对应属性. 安装: pip install beautifulsoup4 例子: from bs4 import BeautifulSoup #
-
python爬虫爬取bilibili网页基本内容
用爬虫爬取bilibili网站排行榜游戏类的所有名称及链接: 导入requests.BeautifulSoup import requests from bs4 import BeautifulSoup 然后我们需要插入网站链接并且要解析网站并打印出来: e = requests.get('https://www.bilibili.com/v/popular/rank/game') #当前网站链接 html = e.content soup = BeautifulSoup(html,'htm
-
Python用requests模块实现动态网页爬虫
目录 前言 开发工具 环境搭建 总结 前言 Python爬虫实战,requests模块,Python实现动态网页爬虫 让我们愉快地开始吧~ 开发工具 Python版本: 3.6.4 相关模块: urllib模块: random模块: requests模块: traceback模块: 以及一些Python自带的模块. 环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 那我们就开启爬虫的正确姿势吧,先用解析接口的方法来写爬虫. 首先,找到真实请求.右键检查,点击Networ