Python编程实现简单的微博自动点赞
目录
- 一、实现登陆微博功能
- 二、实现发送微博
- 三、实现微博自动点赞
觉得微博手动点赞太过麻烦?
其实自动点赞的实现并不困难!
本篇会有Cookie、session和token方面的知识,不太了解的可以先看下
web前端cookie session及token会话机制详解
我们先通过前两个小节大概了解一下我们Python登录微博的原理,然后第三小节就会跟大家介绍微博自动点赞的代码。
一、实现登陆微博功能
首先进入微博页面后按F12打开开发者工具,将如图的按钮点击后,在浏览器中手动登陆一次,在Network 标签的XHR类型中找到Login请求标签,在Form data下我们可以看到username(用户名)和password(密码),并知道了请求方式是POST,请求的参数有很多我们直接照搬就是。
网页截图
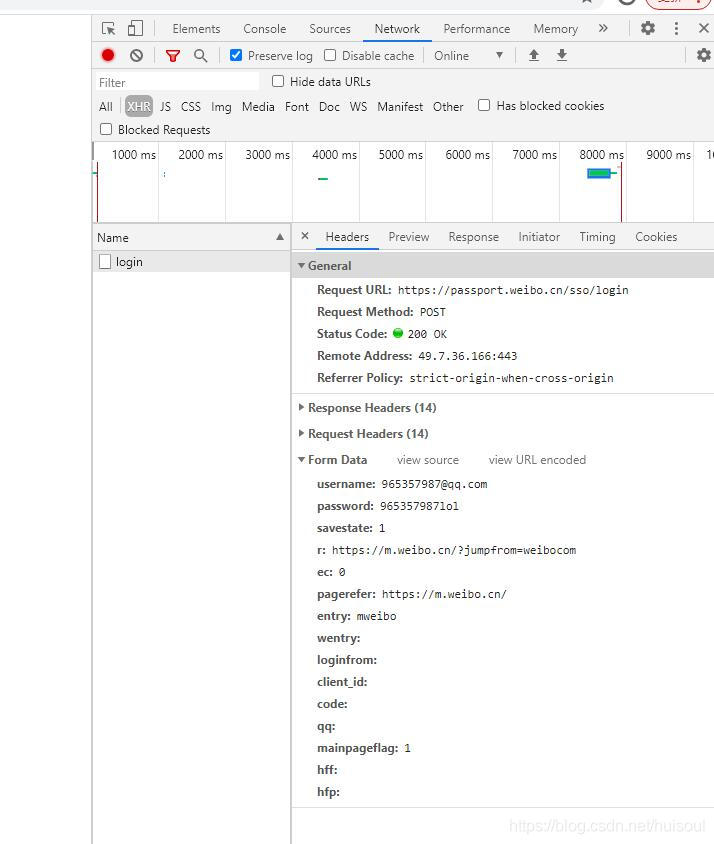
这时,可能学过一些爬虫的同学便会直接上手写出如上雷同的代码,但发现出不来结果
会报错的代码
import requests
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
}
login_data = {
'username': '你的用户名',
'password': '你的密码',
'savestate': '1',
'r': 'https://m.weibo.cn/?jumpfrom=weibocom',
'ec': '0',
'pagerefer': 'https://m.weibo.cn/login?backURL=https%253A%252F%252Fm.weibo.cn%252F%253Fjumpfrom%253Dweibocom',
'entry': 'mweibo',
'wentry': '',
'loginfrom': '',
'client_id': '',
'code': '',
'qq': '',
'mainpageflag': '1',
'hff': '',
'hfp': '',
}
login_req = requests.post('https://passport.weibo.cn/sso/login', data=login_data, headers=headers)
print(login_req.status_code)
这是因为有些网站并不只是按照'user-agent'判断用户的正常访问的。那我们还需点开Request Headers(请求头)检查可能还有什么字段会用来判断用户正常访问
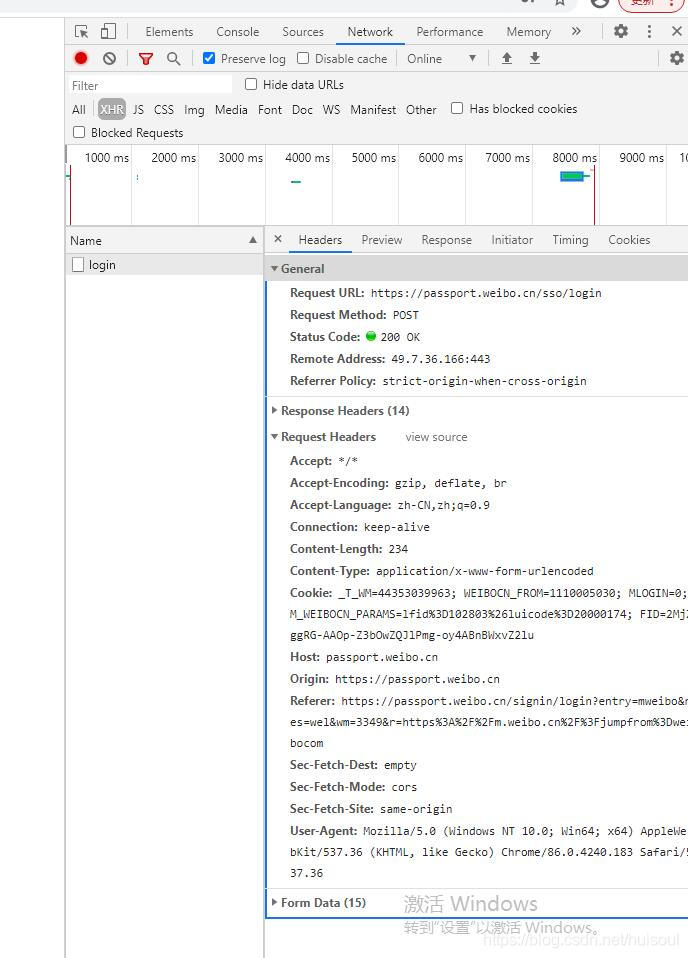
一般 referer(请求来源页面)、origin(谁发起的请求)、host(主机名及端口号) 字段也常被用于反爬虫,当我们的爬虫无法正常获取数据时,我们可以将请求头里的这些字段照搬进去试试。经过验证,微博网页是以referer 来判断是否是用户正常访问。最后我们还可以把Cookie放进代码里,这样就不用在代码里输入账号密码了。
要注意Cookie并不是永久有效的,若发现自动登录失败,可以重新上网页把新的Cookie复制下来更换
完整的代码如下
import requests
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36',
'referer': 'https://passport.weibo.cn/signin/login? entry=mweibo&res=wel&wm=3349&r=https%3A%2F%2Fm.weibo.cn%2F%3Fjumpfrom%3Dweibocom',
'cookie': '你的cookie'
}
login_data = {
'savestate': '1',
'r': 'https://m.weibo.cn/?jumpfrom=weibocom',
'ec': '0',
'pagerefer': 'https://m.weibo.cn/login?backURL=https%253A%252F%252Fm.weibo.cn%252F%253Fjumpfrom%253Dweibocom',
'entry': 'mweibo',
'wentry': '',
'loginfrom': '',
'client_id': '',
'code': '',
'qq': '',
'mainpageflag': '1',
'hff': '',
'hfp': '',
}
login_req = requests.post('https://passport.weibo.cn/sso/login', data=login_data, headers=headers)
print(login_req.status_code) #输出200则代表登录成功
二、实现发送微博
既然都登陆微博了,我们先试试能不能顺便发微博吧
同样的,在微博编辑页面点击F12进入开发者工具,我们先试试发送一个微博,Network标签会出现什么新的内容吧
网页截图

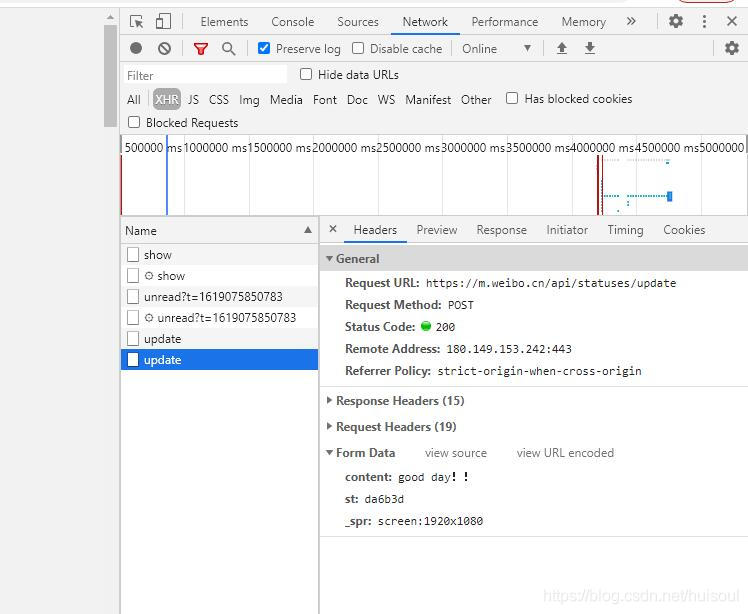
当微博界面点击发送之后,Network标签就会出现update的请求,点进去可以看到,请求地址是https://m.weibo.cn/api/statuses/update,请求方法是 POST。参数有两个一个是content 也就是发送的微博内容,另一个是st,这里的st通过几次的检验,猜测应该是网站的反爬虫措施。这里获得st的方法是通过同为Network标签下的config请求,里面存放了st值,我们将 JSON 格式的字符串转换为字典,然后取到 st 的值
方法
config_req = session.get('https://m.weibo.cn/api/config')
config = config_req.json()
st = config['data']['st']
print(st) #每隔一段时间st值会改变
登录和发送微博的完整代码如
import requests
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36',
'referer': 'https://passport.weibo.cn/signin/login?entry=mweibo&res=wel&wm=3349&r=https%3A%2F%2Fm.weibo.cn%2F%3Fjumpfrom%3Dweibocom',
'cookie': '你的cookie'
}
login_data = {
'savestate': '1',
'r': 'https://m.weibo.cn/?jumpfrom=weibocom',
'ec': '0',
'pagerefer': 'https://m.weibo.cn/login?backURL=https%253A%252F%252Fm.weibo.cn%252F%253Fjumpfrom%253Dweibocom',
'entry': 'mweibo',
'wentry': '',
'loginfrom': '',
'client_id': '',
'code': '',
'qq': '',
'mainpageflag': '1',
'hff': '',
'hfp': '',
}
# 使用 session来保留登录状态
session = requests.Session()
session.headers.update(headers)
login_req = session.post('https://passport.weibo.cn/sso/login', data=login_data)
# 获取 st 请求
config_req = session.get('https://m.weibo.cn/api/config')
config = config_req.json()
st = config['data']['st']
compose_data = {
'content': input("请输入发送的内容:"),,
'st': st
}
compose_req = session.post('https://m.weibo.cn/api/statuses/update', data=compose_data)
print(compose_req.json()) # 输出:{'ok': 1, 'data': 省略部分内容...}
调整结构后的代码(功能一样)如
import requests
class WeiboSpider:
def __init__(self):
self.session = requests.Session()
self.headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36',
'referer': 'https://passport.weibo.cn/signin/login?entry=mweibo&res=wel&wm=3349&r=https%3A%2F%2Fm.weibo.cn%2F%3Fjumpfrom%3Dweibocom',
'cookie': '你的Cookie'
}
self.session.headers.update(self.headers)
def login(self):
login_data = {
'savestate': '1',
'r': 'https://m.weibo.cn/?jumpfrom=weibocom',
'ec': '0',
'pagerefer': 'https://m.weibo.cn/login?backURL=https%253A%252F%252Fm.weibo.cn%252F%253Fjumpfrom%253Dweibocom',
'entry': 'mweibo',
'wentry': '',
'loginfrom': '',
'client_id': '',
'code': '',
'qq': '',
'mainpageflag': '1',
'hff': '',
'hfp': '',
}
self.session.post('https://passport.weibo.cn/sso/login', data=login_data)
def get_st(self):
config_req = self.session.get('https://m.weibo.cn/api/config')
config = config_req.json()
st = config['data']['st']
return st
def compose(self, content):
compose_data = {
'content': content,
'st': self.get_st()
}
compose_req = self.session.post('https://m.weibo.cn/api/statuses/update', data=compose_data)
print(compose_req.json())
def send(self, content):
self.login()
self.compose(content)
weibo = WeiboSpider()
weibo.send(input("请输入发送的内容:"))
三、实现微博自动点赞
完整的代码
import requests
class WeiboSpider:
def __init__(self):
self.session = requests.Session()
self.headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36',
'referer': 'https://passport.weibo.cn/signin/login?entry=mweibo&res=wel&wm=3349&r=https%3A%2F%2Fm.weibo.cn%2F%3Fjumpfrom%3Dweibocom',
'cookie': '你的cookie'
}
self.session.headers.update(self.headers)
def login(self):
login_data = {
'savestate': '1',
'r': 'https://m.weibo.cn/?jumpfrom=weibocom',
'ec': '0',
'pagerefer': 'https://m.weibo.cn/login?backURL=https%253A%252F%252Fm.weibo.cn%252F%253Fjumpfrom%253Dweibocom',
'entry': 'mweibo',
'wentry': '',
'loginfrom': '',
'client_id': '',
'code': '',
'qq': '',
'mainpageflag': '1',
'hff': '',
'hfp': '',
}
self.session.post('https://passport.weibo.cn/sso/login', data=login_data)
def get_st(self):
config_req = self.session.get('https://m.weibo.cn/api/config')
config = config_req.json()
st = config['data']['st']
return st
def compose(self, content):
compose_data = {
'content': content,
'st': self.get_st()
}
compose_req = self.session.post('https://m.weibo.cn/api/statuses/update', data=compose_data)
print(compose_req.json())
def send(self, content):
self.login()
self.compose(content)
# 获取微博列表
def get_weibo_list(self):
params = {
'type': 'uid',
'value': '2139359753',
'containerid': '1076032139359753'
}
weibo_list_req = self.session.get('https://m.weibo.cn/api/container/getIndex', params=params)
weibo_list_data = weibo_list_req.json()
weibo_list = weibo_list_data['data']['cards']
return weibo_list
# 点赞微博
def vote_up(self, id):
vote_up_data = {
'id': id, # 要点赞的微博 id
'attitude': 'heart',
'st': self.get_st()
}
vote_up_req = self.session.post('https://m.weibo.cn/api/attitudes/create', data=vote_up_data)
json = vote_up_req.json()
print(json['msg'])
# 批量点赞微博
def vote_up_all(self):
self.login()
weibo_list = self.get_weibo_list()
for i in weibo_list:
# card_type 为 9 是正常微博
if i['card_type'] == 9:
self.vote_up(i['mblog']['id'])
weibo = WeiboSpider()
weibo.vote_up_all()
谢谢大家,Python的分享就到此为止,以后如果有好玩的Python程序,我还会继续向大家分享的,希望大家以后多多支持我们!
相关推荐
-
python自动点赞功能的实现思路
1.思路 通过pyautogui可以实现鼠标点击.滚动鼠标.截屏等操作.由此功能实现打开页面,进行点赞. aircv可以从大图像获得小图像的位置,利用pyautogui截屏得到的图片,可以在页面获取到每一个
-
Selenium实现微博自动化运营之关注、点赞、评论功能
Selenium 是什么? Selenium是一个用于Web应用程序测试的工具,可以模拟真正的用户操作,支持多种浏览器,如Firefox,Safari,Google Chrome,Opera等. Selenium 模拟的就是一个真实的用户的操作行为,我们完全不用担心 cookie 追踪和隐藏字段的干扰. 除了Selenium 外,还有Puppeteer 工具可以模拟用户操作,Python + Selenium + 第三方浏览器可以让我们处理多种复杂场景,包括网页动态加载.JS 响应.Post 表
-

Python使用新浪微博API发送微博的例子
1.注册一个新浪应用,得到appkey和secret,以及token,将这些信息写入配置文件sina_weibo_config.ini,内容如下,仅举例: 复制代码 代码如下: [userinfo]CONSUMER_KEY=8888888888CONSUMER_SECRET=777777f3feab026050df37d711200000TOKEN=2a21b19910af7a4b1962ad6ef9999999TOKEN_SECRET=47e2fdb0b0ac983241b0caaf45555
-
python实现抖音点赞功能
本文实例为大家分享了python实现抖音点赞功能的具体代码,供大家参考,具体内容如下 #coding=utf-8 from time import sleep, ctime import threading import os import sys import time import subprocess import re #M 2018-08-11 #针对于单条控制命令的终端操作 system(func_swipe,func_trap) #若要进行多条命令操作则可以直接move掉当前执行的
-
python实现QQ空间自动点赞功能
本文实例为大家分享了python实现QQ空间自动点赞的具体代码,供大家参考,具体内容如下 项目github地址 使用python实现qq空间自动点赞功能. 需自行安装库并配置环境. 我想实现的是每6个小时就自动更新一次cookie.这也是和网上其他版本相比具有的优点.不用手动输入cookie.更加自动.(不负责任的说,这个功能没有测试过.) 程序运行方法:将代码存为.py文件,运行即可. 输入QQ密码的时候采用了linux登录的方式--没有回显. from selenium import web
-
Python编程实现简单的微博自动点赞
目录 一.实现登陆微博功能 二.实现发送微博 三.实现微博自动点赞 觉得微博手动点赞太过麻烦? 其实自动点赞的实现并不困难! 本篇会有Cookie.session和token方面的知识,不太了解的可以先看下 web前端cookie session及token会话机制详解 我们先通过前两个小节大概了解一下我们Python登录微博的原理,然后第三小节就会跟大家介绍微博自动点赞的代码. 一.实现登陆微博功能 首先进入微博页面后按F12打开开发者工具,将如图的按钮点击后,在浏览器中手动登陆一次,在Net
-
python编程scrapy简单代码实现搜狗图片下载器
学习任何编程技术,都要有紧有送,今天这篇博客就到了放松的时候了,我们学习一下如何用 scrapy 下载图片吧. 目标站点说明 这次要采集的站点为搜狗图片频道,该频道数据由接口直接返回,接口如下: https://pic.sogou.com/napi/pc/recommend?key=homeFeedData&category=feed&start=10&len=10 https://pic.sogou.com/napi/pc/recommend?key=homeFeedData&a
-
Python实现简单自动评论自动点赞自动关注脚本
目录 前言 开发环境 原理: 1. 请求伪装 2. 获取搜索内容的方法 3. 获取作品评论 4. 自动评论 5. 点赞操作 6. 关注操作 7. 获取创作者信息 8. 获取创作者视频 9. 调用函数 前言 今天的这个脚本,是一个别人发的外包,交互界面的代码就不在这里说了,但是可以分享下自动评论.自动点赞.自动关注.采集评论和视频的数据是如何实现的 开发环境 python 3.8 运行代码pycharm 2021.2 辅助敲代码requests 第三方模块 原理: 模拟客户端,向服务器发送请求 代
-
简单实用的Android UI微博动态点赞效果
说起空间动态.微博的点赞效果,网上也是很泛滥,各种实现与效果一大堆.而详细实现的部分,讲述的也是参差不齐,另一方面估计也有很多大侠也不屑一顾,觉得完全没必要单独开篇来写和讲解吧.毕竟,也就是两个view和一些简单的动画效果罢了. 单若是只讲这些,我自然也是不愿花这番功夫的.虽然自己很菜,可也不甘于太菜.所以偶尔看到些好东西,可以延伸学写下,我还是很情愿拿出来用用,顺带秀一秀逼格什么的. 不扯太多,先说说今天实现点赞效果用到的自以为不错的两个点: Checkable 用来扩展View实现选中状态切
-
Python编程实现下载器自动爬取采集B站弹幕示例
目录 实现效果 UI界面 数据采集 小结 大家好,我是小张! 在<Python编程实现小姐姐跳舞并生成词云视频示例>文章中简单介绍了B站弹幕的爬取方法,只需找到视频中的参数 cid,就能采集到该视频下的所有弹幕:思路虽然很简单,但个人感觉还是比较麻烦,例如之后的某一天,我想采集B站上的某个视频弹幕,还需要从头开始:找cid参数.写代码,重复单调: 因此我在想有没有可能一步到位,以后采集某个视频弹幕时只需一步操作,比如输入想爬取的视频链接,程序能自动识别下载 实现效果 基于此,借助 PyQt5
-
Python利用PyAutoGUI实现自动点赞
目录 前言 思路 实现 总结 前言 在上篇文章<Python自动操作 GUI 神器——PyAutoGUI>中,我跟大家讲解了一下 pyautogui 的一些基础知识和操作,大家反馈很好,给了我好多赞,在此先跟大家说声三克油! 在得到大家正反馈的同时,我受到了很大鼓舞,感觉如果只是介绍一下基础操作,有点不过瘾,所以今天晚上加班回来,虽然很不想打开电脑,但是还是忍着疲惫给大家奉献一个小实例. 为此,我跑去洗手间用凉水洗了一把脸,顿时清醒多了,下面进入正题. 作为一个 GUI 操作的神器,我们看到了
-
Python编程实现的简单Web服务器示例
本文实例讲述了Python编程实现的简单Web服务器.分享给大家供大家参考,具体如下: 最近有个需求,就是要创建一个简到要多简单就有多简单的web服务器,目的就是需要一个后台进程用来接收请求然后处理并返回结果,因此就想到了使用Python来实现. 首先创建一个myapp.py文件,其中定义了一个方法,所有的请求都会经过此方法,可以在此方法里处理传递的url和参数,并返回结果. def myapp(environ, start_response): status = '200 OK' header
-
用Python编写简单的微博爬虫
先说点题外话,我一开始想使用Sina Weibo API来获取微博内容,但后来发现新浪微博的API限制实在太多,大家感受一下: 只能获取当前授权的用户(就是自己),而且只能返回最新的5条,WTF! 所以果断放弃掉这条路,改为『生爬』,因为PC端的微博是Ajax的动态加载,爬取起来有些困难,我果断知难而退,改为对移动端的微博进行爬取,因为移动端的微博可以通过分页爬取的方式来一次性爬取所有微博内容,这样工作就简化了不少. 最后实现的功能: 1.输入要爬取的微博用户的user_id,获得该用户的所有微
-
Python编程实现的简单神经网络算法示例
本文实例讲述了Python编程实现的简单神经网络算法.分享给大家供大家参考,具体如下: python实现二层神经网络 包括输入层和输出层 # -*- coding:utf-8 -*- #! python2 import numpy as np #sigmoid function def nonlin(x, deriv = False): if(deriv == True): return x*(1-x) return 1/(1+np.exp(-x)) #input dataset x = np.