python 如何通过KNN来填充缺失值
看代码吧~
# 加载库
import numpy as np
from fancyimpute import KNN
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import make_blobs
# 创建模拟特征矩阵
features, _ = make_blobs(n_samples = 1000,
n_features = 2,
random_state = 1)
# 标准化特征
scaler = StandardScaler()
standardized_features = scaler.fit_transform(features)
standardized_features
# 制造缺失值
true_value = standardized_features[0,0]
standardized_features[0,0] = np.nan
standardized_features
# 预测
features_knn_imputed = KNN(k=5, verbose=0).fit_transform(standardized_features)
# features_knn_imputed = KNN(k=5, verbose=0).complete(standardized_features)
features_knn_imputed
# #对比真实值和预测值
print("真实值:", true_value)
print("预测值:", features_knn_imputed[0,0])
# 加载库
import numpy as np
from fancyimpute import KNN
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import make_blobs
# 创建模拟特征矩阵
features, _ = make_blobs(n_samples = 1000,
n_features = 2,
random_state = 1)
# 标准化特征
scaler = StandardScaler()
standardized_features = scaler.fit_transform(features)
standardized_features
# 制造缺失值
true_value = standardized_features[0,0]
standardized_features[0,0] = np.nan
standardized_features
# 预测
features_knn_imputed = KNN(k=5, verbose=0).fit_transform(standardized_features)
# features_knn_imputed = KNN(k=5, verbose=0).complete(standardized_features)
features_knn_imputed
# #对比真实值和预测值
print("真实值:", true_value)
print("预测值:", features_knn_imputed[0,0])
真实值: 0.8730186113995938
预测值: 1.0955332713113226
补充:scikit-learn中一种便捷可靠的缺失值填充方法:KNNImputer
在数据挖掘工作中,处理样本中的缺失值是必不可少的一步。其中对于缺失值插补方法的选择至关重要,因为它会对最后模型拟合的效果产生重要影响。
在2019年底,scikit-learn发布了0.22版本,此次版本除了修复之前的一些bug外,还更新了很多新功能,对于数据挖掘人员来说更加好用了。其中我发现了一个新增的非常好用的缺失值插补方法:KNNImputer。这个基于KNN算法的新方法使得我们现在可以更便捷地处理缺失值,并且与直接用均值、中位数相比更为可靠。利用“近朱者赤”的KNN算法原理,这种插补方法借助其他特征的分布来对目标特征进行缺失值填充。
下面,就让我们用实际例子来看看KNNImputer是如何使用的吧
使用KNNImputer需要从scikit-learn中导入:
from sklearn.impute import KNNImputer
先来一个小例子开开胃,data中第二个样本存在缺失值。
data = [[2, 4, 8], [3, np.nan, 7], [5, 8, 3], [4, 3, 8]]
KNNImputer中的超参数与KNN算法一样,n_neighbors为选择“邻居”样本的个数,先试试n_neighbors=1。
imputer = KNNImputer(n_neighbors=1) imputer.fit_transform(data)

可以看到,因为第二个样本的第一列特征3和第三列特征7,与第一行样本的第一列特征2和第三列特征8的欧氏距离最近,所以缺失值按照第一个样本来填充,填充值为4。那么n_neighbors=2呢?
imputer = KNNImputer(n_neighbors=2) imputer.fit_transform(data)

此时根据欧氏距离算出最近相邻的是第一行样本与第四行样本,此时的填充值就是这两个样本第二列特征4和3的均值:3.5。
接下来让我们看一个实际案例,该数据集来自Kaggle皮马人糖尿病预测的分类赛题,其中有不少缺失值,我们试试用KNNImputer进行插补。
import numpy as np
import pandas as pd
import pandas_profiling as pp
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(context="notebook", style="darkgrid")
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
from sklearn.impute import KNNImputer
#Loading the dataset
diabetes_data = pd.read_csv('pima-indians-diabetes.csv')
diabetes_data.columns = ['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness',
'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age', 'Outcome']
diabetes_data.head()

在这个数据集中,0值代表的就是缺失值,所以我们需要先将0转化为nan值然后进行缺失值处理。
diabetes_data_copy = diabetes_data.copy(deep=True) diabetes_data_copy[['Glucose','BloodPressure','SkinThickness','Insulin','BMI']] = diabetes_data_copy[['Glucose','BloodPressure','SkinThickness','Insulin','BMI']].replace(0, np.NaN) print(diabetes_data_copy.isnull().sum())

在本文中,我们尝试用DiabetesPedigreeFunction与Age,对BloodPressure中的35个缺失值进行KNNImputer插补。
先来看一下缺失值都在哪几个样本:
null_index = diabetes_data_copy.loc[diabetes_data_copy['BloodPressure'].isnull(), :].index null_index

imputer = KNNImputer(n_neighbors=10) diabetes_data_copy[['BloodPressure', 'DiabetesPedigreeFunction', 'Age']] = imputer.fit_transform(diabetes_data_copy[['BloodPressure', 'DiabetesPedigreeFunction', 'Age']]) print(diabetes_data_copy.isnull().sum())

可以看到现在BloodPressure中的35个缺失值消失了。我们看看具体填充后的数据(只截图了部分):
diabetes_data_copy.iloc[null_index]
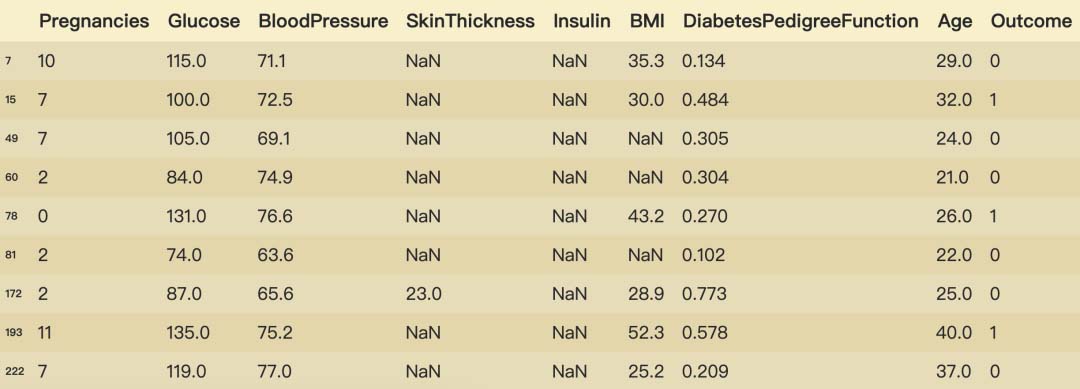
到此,BloodPressure中的缺失值已经根据DiabetesPedigreeFunction与Age运用KNNImputer填充完成了。注意的是,对于非数值型特征需要先转换为数值型特征再进行KNNImputer填充操作,因为目前KNNImputer方法只支持数值型特征(ʘ̆ωʘ̥̆‖)՞。
相关推荐
-

K近邻法(KNN)相关知识总结以及如何用python实现
1.基本概念 K近邻法(K-nearest neighbors,KNN)既可以分类,也可以回归. KNN做回归和分类的区别在于最后预测时的决策方式. KNN做分类时,一般用多数表决法 KNN做回归时,一般用平均法. 基本概念如下:对待测实例,在训练数据集中找到与该实例最邻近的K个实例(也就是上面所说的K个邻居), 这K个实例的多数属于某个类,就把该输入实例分类到这个类中 2. KNN算法三要素 KNN算法主要考虑:k值的选取,距离度量方式,分类决策规则. 1) k值的选取.在应用中,k值一般选
-
Python图像识别+KNN求解数独的实现
Python-opencv+KNN求解数独 最近一直在玩数独,突发奇想实现图像识别求解数独,输入到输出平均需要0.5s. 整体思路大概就是识别出图中数字生成list,然后求解. 输入输出demo 数独采用的是微软自带的Microsoft sudoku软件随便截取的图像,如下图所示: 经过程序求解后,得到的结果如下图所示: 程序具体流程 程序整体流程如下图所示: 读入图像后,根据求解轮廓信息找到数字所在位置,以及不包含数字的空白位置,提取数字信息通过KNN识别,识别出数字:无数字信息的在list中
-
python KNN算法实现鸢尾花数据集分类
一.knn算法描述 1.基本概述 knn算法,又叫k-近邻算法.属于一个分类算法,主要思想如下: 一个样本在特征空间中的k个最近邻的样本中的大多数都属于某一个类别,则该样本也属于这个类别.其中k表示最近邻居的个数. 用二维的图例,说明knn算法,如下: 二维空间下数据之间的距离计算: 在n维空间两个数据之间: 2.具体步骤: (1)计算待测试数据与各训练数据的距离 (2)将计算的距离进行由小到大排序 (3)找出距离最小的k个值 (4)计算找出的值中每个类别的频次 (5)返回频次最高的类别 二.鸢
-
K最近邻算法(KNN)---sklearn+python实现方式
k-近邻算法概述 简单地说,k近邻算法采用测量不同特征值之间的距离方法进行分类. k-近邻算法 优点:精度高.对异常值不敏感.无数据输入假定. 缺点:计算复杂度高.空间复杂度高. 适用数据范围:数值型和标称型. k-近邻算法(kNN),它的工作原理是:存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系.输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标
-
原生python实现knn分类算法
一.题目要求 用原生Python实现knn分类算法. 二.题目分析 数据来源:鸢尾花数据集(见附录Iris.txt) 数据集包含150个数据集,分为3类,分别是:Iris Setosa(山鸢尾).Iris Versicolour(杂色鸢尾)和Iris Virginica(维吉尼亚鸢尾).每类有50个数据,每个数据包含四个属性,分别是:Sepal.Length(花萼长度).Sepal.Width(花萼宽度).Petal.Length(花瓣长度)和Petal.Width(花瓣宽度). 将得到的数据集
-
python实现KNN近邻算法
示例:<电影类型分类> 获取数据来源 电影名称 打斗次数 接吻次数 电影类型 California Man 3 104 Romance He's Not Really into Dudes 8 95 Romance Beautiful Woman 1 81 Romance Kevin Longblade 111 15 Action Roob Slayer 3000 99 2 Action Amped II 88 10 Action Unknown 18 90 unknown 数据显示:肉眼判断
-
Python机器学习之KNN近邻算法
一.KNN概述 简单来说,K-近邻算法采用测量不同特征值之间的距离方法进行分类 优点:精度高.对异常值不敏感.无数据输入假定 缺点:计算复杂度高.空间复杂度高 适用数据范围:数值型和标称2型 工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一个数据与所属分类的对应关系(训练集).输入没有标签的新数据之后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签(测试集).一般来说,我们只选择样
-
python 如何通过KNN来填充缺失值
看代码吧~ # 加载库 import numpy as np from fancyimpute import KNN from sklearn.preprocessing import StandardScaler from sklearn.datasets import make_blobs # 创建模拟特征矩阵 features, _ = make_blobs(n_samples = 1000, n_features = 2, random_state = 1) # 标准化特征 scaler
-
python实现数据预处理之填充缺失值的示例
1.给定一个数据集noise-data-1.txt,该数据集中保护大量的缺失值(空格.不完整值等).利用"全局常量"."均值或者中位数"来填充缺失值. noise-data-1.txt: 5.1 3.5 1.4 0.2 4.9 3 1.4 0.2 4.7 3.2 1.3 0.2 4.6 3.1 1.5 0.2 5 3.6 1.4 0.2 5.4 3.9 1.7 0.4 4.6 3.4 1.4 0.3 5 3.4 1.5 0.2 4.4 2.9 1.4 0.2 4.9
-
python笔记之使用fillna()填充缺失值
目录 使用fillna()填充缺失值 关于fillna()函数详解 一.不指定任何参数 二.指定inplace参数 三.指定method参数 四.指定limit参数 五.指定axis参数 使用fillna()填充缺失值 df = pd.read_csv('ccf_offline_stage1_train.csv') print(df['Distance']) df['distance'] = df['Distance'].fillna(-1).astype(int) print(df['dist
-
Python数据分析的八种处理缺失值方法详解
目录 1. 删除有缺失值的行或列 2. 删除只有缺失值的行或列 3. 根据阈值删除行或列 4. 基于特定的列子集删除 5. 填充一个常数值 6. 填充聚合值 7. 替换为上一个或下一个值 8. 使用另一个数据框填充 总结 技术交流 在本文中,我们将介绍 8 种不同的方法来解决缺失值问题,哪种方法最适合特定情况取决于数据和任务.欢迎收藏学习,喜欢点赞支持,技术交流可以文末加群,尽情畅聊. 让我们首先创建一个示例数据框并向其中添加一些缺失值. 我们有一个 10 行 6 列的数据框. 下一步是添加缺失
-
Python语言描述KNN算法与Kd树
最近邻法和k-近邻法 下面图片中只有三种豆,有三个豆是未知的种类,如何判定他们的种类? 提供一种思路,即:未知的豆离哪种豆最近就认为未知豆和该豆是同一种类.由此,我们引出最近邻算法的定义:为了判定未知样本的类别,以全部训练样本作为代表点,计算未知样本与所有训练样本的距离,并以最近邻者的类别作为决策未知样本类别的唯一依据.但是,最近邻算法明显是存在缺陷的,比如下面的例子:有一个未知形状(图中绿色的圆点),如何判断它是什么形状? 显然,最近邻算法的缺陷--对噪声数据过于敏感,为了解决这个问题,我们可
-
Python实现螺旋矩阵的填充算法示例
本文实例讲述了Python实现螺旋矩阵的填充算法.分享给大家供大家参考,具体如下: afanty的分析: 关于矩阵(二维数组)填充问题自己动手推推,分析下两个下表的移动规律就很容易咯. 对于螺旋矩阵,不管它是什么鬼,反正就是依次向右.向下.向右.向上移动. 向右移动:横坐标不变,纵坐标加1 向下移动:纵坐标不变,横坐标加1 向右移动:横坐标不变,纵坐标减1 向上移动:纵坐标不变,横坐标减1 代码实现: #coding=utf-8 import numpy ''''' Author: afanty
-
pandas 使用均值填充缺失值列的小技巧分享
pd.DataFrame中通常含有许多特征,有时候需要对每个含有缺失值的列,都用均值进行填充,代码实现可以这样: for column in list(df.columns[df.isnull().sum() > 0]): mean_val = df[column].mean() df[column].fillna(mean_val, inplace=True) # -------代码分解------- # 判断哪些列有缺失值,得到series对象 df.isnull().sum() > 0
-
Python实现的knn算法示例
本文实例讲述了Python实现的knn算法.分享给大家供大家参考,具体如下: 代码参考机器学习实战那本书: 机器学习实战 (Peter Harrington著) 中文版 机器学习实战 (Peter Harrington著) 英文原版[附源代码] 有兴趣你们可以去了解下 具体代码: # -*- coding:utf-8 -*- #! python2 ''''' @author:zhoumeixu createdate:2015年8月27日 ''' #np.zeros((4,2)) #np.zero
-
python dataframe向下向上填充,fillna和ffill的方法
首先新建一个dataframe: In[8]: df = pd.DataFrame({'name':list('ABCDA'),'house':[1,1,2,3,3],'date':['2010-01-01','2010-06-09','2011-12-03','2011-04-05','2012-03-23']}) In[9]: df Out[9]: date house name 0 2010-01-01 1 A 1 2010-06-09 1 B 2 2011-12-03 2 C 3 201
-
Python实现基于KNN算法的笔迹识别功能详解
本文实例讲述了Python实现基于KNN算法的笔迹识别功能.分享给大家供大家参考,具体如下: 需要用到: Numpy库 Pandas库 手写识别数据 点击此处本站下载. 数据说明: 数据共有785列,第一列为label,剩下的784列数据存储的是灰度图像(0~255)的像素值 28*28=784 KNN(K近邻算法): 从训练集中找到和新数据最接近的K条记录,根据他们的主要分类来决定新数据的类型. 这里的主要分类,可以有不同的判别依据,比如"最多","最近邻",或者