python实现图像识别的示例代码
一、安装库
首先我们需要安装PIL和pytesseract库。
PIL:(Python Imaging Library)是Python平台上的图像处理标准库,功能非常强大。
pytesseract:图像识别库。
我这里使用的是python3.6,PIL不支持python3所以使用如下命令
pip install pytesseract pip install pillow
如果是python2,则在命令行执行如下命令:
pip install pytesseract pip install PIL
这时候我们去运行上面的代码会发现如下错误:

错误提示的很明显:
No such file or directory :"tesseract"
这是因为我们没有安装tesseract-ocr引擎
二、tesseract-ocr引擎
光学字符识别(OCR,Optical Character Recognition)是指对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程。OCR技术非常专业,一般多是印刷、打印行业的从业人员使用,可以快速的将纸质资料转换为电子资料。关于中文OCR,目前国内水平较高的有清华文通、汉王、尚书,其产品各有千秋,价格不菲。国外OCR发展较早,像一些大公司,如IBM、微软、HP等,即使没有推出单独的OCR产品,但是他们的研发团队早已掌握核心技术,将OCR功能植入了自身的软件系统。对于我们程序员来说,一般用不到那么高级的,主要在开发中能够集成基本的OCR功能就可以了。这两天我查找了很多免费OCR软件、类库,特地整理一下,今天首先来谈谈Tesseract,下一次将讨论下Onenote 2010中的OCR API实现。可以在这里查看OCR技术的发展简史。
Tesseract的OCR引擎最先由HP实验室于1985年开始研发,至1995年时已经成为OCR业内最准确的三款识别引擎之一。然而,HP不久便决定放弃OCR业务,Tesseract也从此尘封。
数年以后,HP意识到,与其将Tesseract束之高阁,不如贡献给开源软件业,让其重焕新生--2005年,Tesseract由美国内华达州信息技术研究所获得,并求诸于Google对Tesseract进行改进、消除Bug、优化工作。
###安装tesseract-ocr引擎
brew install tesseract
然后我们通过tesseract -v看一下是否安装成成功
tesseract 3.05.01 leptonica-1.75.0 libjpeg 9b : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11
这时候我们运行上面代码会出现乱码

这是因为tesseract默认只有语言包中没有中文包,如下图:
###安装tesseract-ocr语言包
我们去GitHub下载我们需要的语言包,这里我只下载了chi_tra.traineddata和chi_sim.traineddata
github:tesseract-ocr/tessdata
然后放到/usr/local/Cellar/tesseract/3.05.01/share/tessdata路径下面。
可以通过tesseract --list-langs查看本地语言包:

可以通过tesseract --help-psm 查看psm
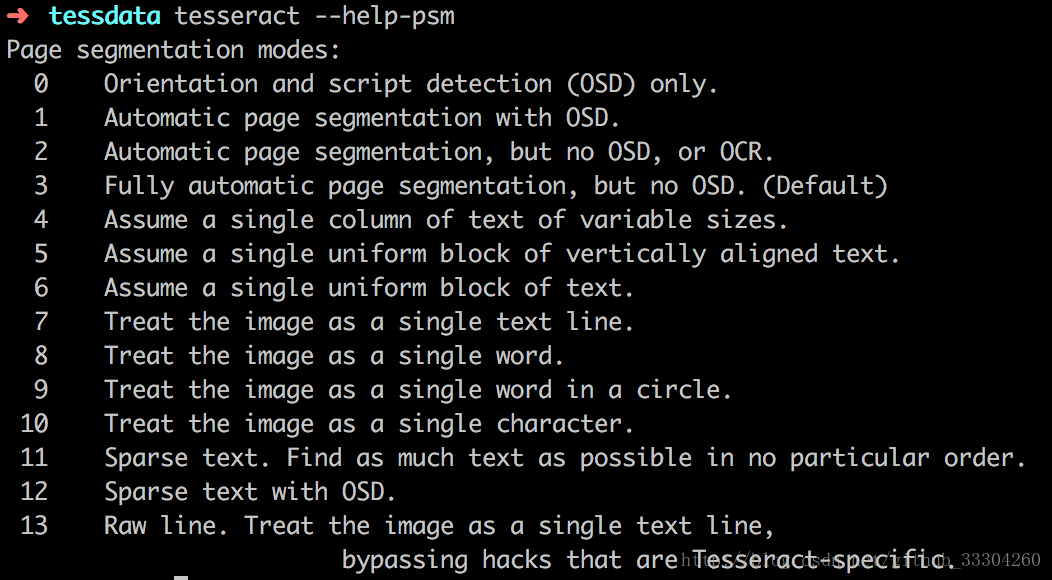
0:定向脚本监测(OSD)
1: 使用OSD自动分页
2 :自动分页,但是不使用OSD或OCR(Optical Character Recognition,光学字符识别)
3 :全自动分页,但是没有使用OSD(默认)
4 :假设可变大小的一个文本列。
5 :假设垂直对齐文本的单个统一块。
6 :假设一个统一的文本块。
7 :将图像视为单个文本行。
8 :将图像视为单个词。
9 :将图像视为圆中的单个词。
10 :将图像视为单个字符。
为什么这里要强调语言包和psm,因为我们在使用中会用到,
比如多个语言包组合并且视为统一的文本块将使用如下参数:
pytesseract.image_to_string(image,lang="chi_sim+eng",config="-psm 6")
这里我们通过+来合并使用多个语言包。
接下来我们看一下配置好一切的正确结果。
import pytesseract
from PIL import Image
image = Image.open("../pic/c.png")
code = pytesseract.image_to_string(image,lang="chi_sim",config="-psm 6")
print(code)


此时大公告成。
到此这篇关于python实现图像识别的示例代码的文章就介绍到这了,更多相关python 图像识别内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python实现连连看辅助(图像识别)
个人兴趣,用python实现连连看的辅助程序,总结实现过程及知识点. 总体思路 1.获取连连看程序的窗口并前置 2.游戏界面截图,将每个一小图标切图,并形成由小图标组成的二维列表 3.对图片的二维列表遍历,将二维列表转换成由数字组成的二维数组,图片相同的数值相同. 4.遍历二维数组,找到可消除的对象,实现算法: 两个图标相邻.(一条线连接) 两个图标同行,同列,且中间的图标全部为空(数值为0)(一条线连接) 两条线连接,转弯一次,路径上所有图标为空.(二条线连接) 三条线连接,转弯二次,路径上所
-
python自动截取需要区域,进行图像识别的方法
实例如下所示: import os os.chdir("G:\Python1\Lib\site-packages\pytesser") from pytesser import * from pytesseract import image_to_string from PIL import Image from PIL import ImageGrab #截图,获取需要识别的区域 x = 345 y = 281 m = 462 n = 327 k = 54 for i in rang
-

微信跳一跳python辅助软件思路及图像识别源码解析
本文将梳理github上最火的wechat_jump_game的实现思路,并解析其图像处理部分源码 首先废话少说先看效果 核心思想 获取棋子到下一个方块的中心点的距离 计算触摸屏幕的时间 点击屏幕 重要方法 计算棋子到下一个方块中心点的距离 使用 adb shell screencap -p 命令获取手机当前屏幕画面 再通过图像上的信息找出棋子的坐标和下一个方块中心点的坐标 然后通过两点间距离公式计算出距离 计算触摸屏幕的时间 T=A * S 其中S为上步算出的像素距离,T为按压时间(ms),A
-
Python图像识别+KNN求解数独的实现
Python-opencv+KNN求解数独 最近一直在玩数独,突发奇想实现图像识别求解数独,输入到输出平均需要0.5s. 整体思路大概就是识别出图中数字生成list,然后求解. 输入输出demo 数独采用的是微软自带的Microsoft sudoku软件随便截取的图像,如下图所示: 经过程序求解后,得到的结果如下图所示: 程序具体流程 程序整体流程如下图所示: 读入图像后,根据求解轮廓信息找到数字所在位置,以及不包含数字的空白位置,提取数字信息通过KNN识别,识别出数字:无数字信息的在list中
-
python实现连连看辅助之图像识别延伸
python实现连连看辅助–图像识别延伸(百度AI),供大家参考,具体内容如下 百度AI平台提供图片相似检索API接口,并有详细的API文档说明,可以更好的实现图片识别. from aip import AipImageSearch """ 你的 APPID AK SK """ APP_ID = '***' API_KEY = '***' SECRET_KEY = '***' client = AipImageSearch(APP_ID, API
-
python实现图像识别功能
本文实例为大家分享了python实现图像识别的具体代码,供大家参考,具体内容如下 #! /usr/bin/env python from PIL import Image import pytesseract url='img/denggao.jpeg' image=Image.open(url) #image=image.convert('RGB') # RGB image=image.convert('L') # 灰度 image.load() text=pytesseract.image_
-
用Python进行简单图像识别(验证码)
这是一个最简单的图像识别,将图片加载后直接利用Python的一个识别引擎进行识别 将图片中的数字通过 pytesseract.image_to_string(image)识别后将结果存入到本地的txt文件中 #-*-encoding:utf-8-*- import pytesseract from PIL import Image class GetImageDate(object): def m(self): image = Image.open(u"C:\\a.png") text
-
python实现图像识别的示例代码
一.安装库 首先我们需要安装PIL和pytesseract库. PIL:(Python Imaging Library)是Python平台上的图像处理标准库,功能非常强大. pytesseract:图像识别库. 我这里使用的是python3.6,PIL不支持python3所以使用如下命令 pip install pytesseract pip install pillow 如果是python2,则在命令行执行如下命令: pip install pytesseract pip install PI
-
Python Flask基础教程示例代码
本文研究的主要是Python Flask基础教程,具体介绍如下. 安装:pip install flask即可 一个简单的Flask from flask import Flask #导入Flask app = Flask(__name__) #创建一个Flask实例 #设置路由,即url @app.route('/') #url对应的函数 def hello_world(): #返回的页面 return 'Hello World!' #这个不是作为模块导入的时候运行,比如这个文件为aa.py,
-
Python安装OpenCV的示例代码
OpenCV介绍 OpenCV是一个基于BSD许可(开源)发行的跨平台计算机视觉库,可以运行在Linux.Windows.Android和Mac OS操作系统上.它轻量级而且高效--由一系列 C 函数和少量 C++ 类构成,同时提供了Python.Ruby.MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法. OpenCV用C++语言编写,它的主要接口也是C++语言,但是依然保留了大量的C语言接口.该库也有大量的Python.Java and MATLAB/OCTAVE(版本
-
利用python生成照片墙的示例代码
PIL(Python Image Library)是python的第三方图像处理库,但是由于其强大的功能与众多的使用人数,几乎已经被认为是python官方图像处理库了.其官方主页为:PIL. PIL历史悠久,原来是只支持python2.x的版本的,后来出现了移植到python3的库pillow,pillow号称是friendly fork for PIL,其功能和PIL差不多,但是支持python3.本文只使用了PIL那些最常用的特性与用法,主要参考自:http://www.effbot.org
-
Python无损压缩图片的示例代码
每个设计师.摄影师或有图片处理需求小编,都会面临批量高清大图的困扰. 因为高清大图放到网站上会严重拖慢加载速度,或是有的地方明确限制了图片大小,因此,为了完成工作,他们总是需要先把图片压缩,再上传. 当需要处理的图片多至十张.百张.千张,则严重影响工作效率.这时候,就可以交给Python啦! 只需要20行Python代码,就可以批量帮你无损压缩数张照片. ---1--- 前期工作 安装Python中现成的图片处理模块,然后将图片打包好导入,用循环的方式自动化处理图片就可以了! ---2--- 运
-
python操作链表的示例代码
class Node: def __init__(self,dataval=None): self.dataval=dataval self.nextval=None class SLinkList: def __init__(self): self.headval=None # 遍历列表 def traversal_slist(self): head_node=self.headval while head_node is not None: print(head_node.dataval)
-
python调用摄像头的示例代码
一.打开摄像头 import cv2 import numpy as np def video_demo(): capture = cv2.VideoCapture(0)#0为电脑内置摄像头 while(True): ret, frame = capture.read()#摄像头读取,ret为是否成功打开摄像头,true,false. frame为视频的每一帧图像 frame = cv2.flip(frame, 1)#摄像头是和人对立的,将图像左右调换回来正常显示. cv2.imshow("vi
-
Python进行特征提取的示例代码
#过滤式特征选择 #根据方差进行选择,方差越小,代表该属性识别能力很差,可以剔除 from sklearn.feature_selection import VarianceThreshold x=[[100,1,2,3], [100,4,5,6], [100,7,8,9], [101,11,12,13]] selector=VarianceThreshold(1) #方差阈值值, selector.fit(x) selector.variances_ #展现属性的方差 selector.tra
-
Python调用Redis的示例代码
#!/usr/bin/env python # -*- coding:utf-8 -*- # ************************************* # @Time : 2019/8/12 # @Author : Zhang Fan # @Desc : Library # @File : MyRedis.py # @Update : 2019/8/23 # ************************************* import redis class MyR
-
Python 实现二叉查找树的示例代码
二叉查找树 所有 key 小于 V 的都被存储在 V 的左子树 所有 key 大于 V 的都存储在 V 的右子树 BST 的节点 class BSTNode(object): def __init__(self, key, value, left=None, right=None): self.key, self.value, self.left, self.right = key, value, left, right 二叉树查找 如何查找一个指定的节点呢,根据定义我们知道每个内部节点左子树的