python之cur.fetchall与cur.fetchone提取数据并统计处理操作
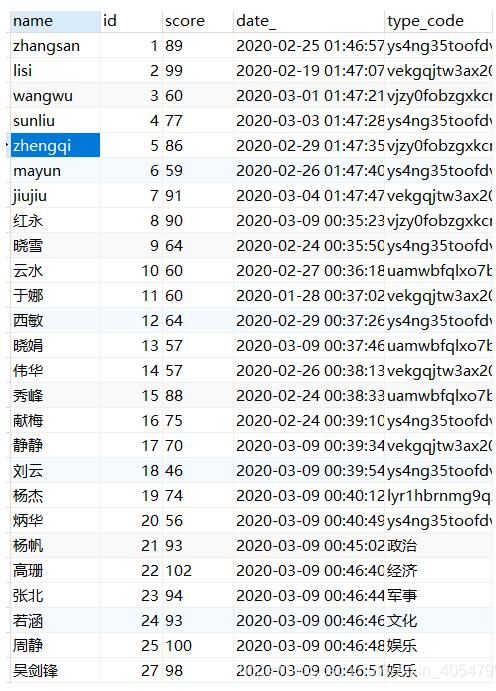
数据库中有一字段type_code,有中文类型和中文类型编码,现在对type_code字段的数据进行统计处理,编码对应的字典如下:
{'ys4ng35toofdviy9ce0pn1uxw2x7trjb':'娱乐',
'vekgqjtw3ax20udsniycjv1hdsa7t4oz':'经济',
'vjzy0fobzgxkcnlbrsduhp47f8pxcoaj':'军事',
'uamwbfqlxo7bu0warx6vkhefigkhtoz3':'政治',
'lyr1hbrnmg9qzvwuzlk5fas7v628jiqx':'文化',
}
其中数据库的32位随机编码生成程序如下:
string.ascii_letters 对应字母(包括大小写), string.digits(对应数字) ,string.punctuation(对应特殊字符)
import string
import random
def get_code():
return ''.join(random.sample(string.ascii_letters + string.digits + string.punctuation, 32))
print(get_code())
def get_code1():
return ''.join(random.sample(string.ascii_letters + string.digits, 32))
testresult= get_code1()
print(testresult.lower())
print(type(testresult))
结果:
)@+t37/b|UQ[K;!spj<(>%r9"PokwTe= igwle98kgqtcprke7byvq12xnhucmz4v <class 'str'>
cur.fetchall:
import pymysql import pandas as pd conn = pymysql.Connect(host="127.0.0.1",port=3306,user="root",password="123456",charset="utf8",db="sql_prac") cur = conn.cursor()
print("连接成功")
sql = "SELECT type_code,count(1) as num FROM test GROUP BY type_code ORDER BY num desc"
cur.execute(sql)
res = cur.fetchall()
print(res)
(('ys4ng35toofdviy9ce0pn1uxw2x7trjb', 8), ('vekgqjtw3ax20udsniycjv1hdsa7t4oz', 5), ('vjzy0fobzgxkcnlbrsduhp47f8pxcoaj', 3), ('uamwbfqlxo7bu0warx6vkhefigkhtoz3', 3), ('娱乐', 2), ('lyr1hbrnmg9qzvwuzlk5fas7v628jiqx', 1), ('政治', 1), ('经济', 1), ('军事', 1), ('文化', 1))
res = pd.DataFrame(list(res), columns=['name','value'])
print(res)

dicts = {'ys4ng35toofdviy9ce0pn1uxw2x7trjb':'娱乐',
'vekgqjtw3ax20udsniycjv1hdsa7t4oz':'经济',
'vjzy0fobzgxkcnlbrsduhp47f8pxcoaj':'军事',
'uamwbfqlxo7bu0warx6vkhefigkhtoz3':'政治',
'lyr1hbrnmg9qzvwuzlk5fas7v628jiqx':'文化',
}
res['name'] = res['name'].map(lambda x:dicts[x] if x in dicts else x)
print(res)
name value 0 娱乐 8 1 经济 5 2 军事 3 3 政治 3 4 娱乐 2 5 文化 1 6 政治 1 7 经济 1 8 军事 1 9 文化 1
#分组统计 result = res.groupby(['name']).sum().reset_index() print(result) name value 0 军事 4 1 娱乐 10 2 政治 4 3 文化 2 4 经济 6
#排序 result = result.sort_values(['value'], ascending=False) name value 1 娱乐 10 4 经济 6 0 军事 4 2 政治 4 3 文化 2
#输出为list,前端需要的数据格式
data_dict = result.to_dict(orient='records')
print(data_dict)
[{'name': '娱乐', 'value': 10}, {'name': '经济', 'value': 6}, {'name': '军事', 'value': 4}, {'name': '政治', 'value': 4}, {'name': '文化', 'value': 2}]
cur.fetchone
先测试SQL:
代码:
import pymysql
import pandas as pd
conn = pymysql.Connect(host="127.0.0.1",port=3306,user="root",password="123456",charset="utf8",db="sql_prac")
cur = conn.cursor()
print("连接成功")
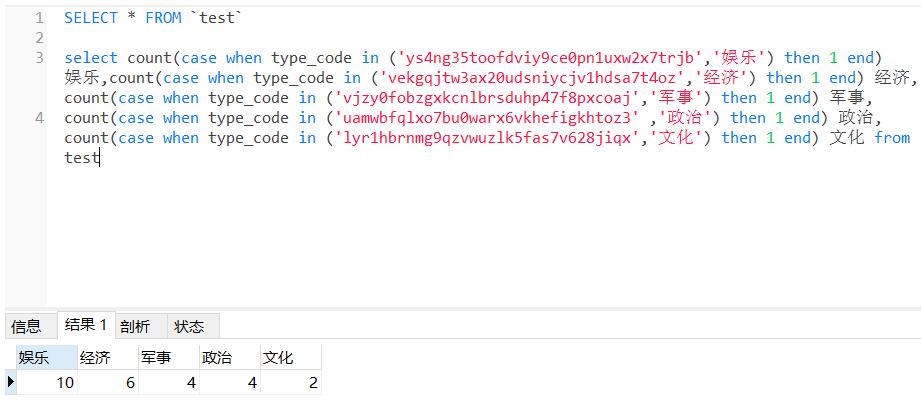
sql = "select count(case when type_code in ('ys4ng35toofdviy9ce0pn1uxw2x7trjb','娱乐') then 1 end) 娱乐," \
"count(case when type_code in ('vekgqjtw3ax20udsniycjv1hdsa7t4oz','经济') then 1 end) 经济," \
"count(case when type_code in ('vjzy0fobzgxkcnlbrsduhp47f8pxcoaj','军事') then 1 end) 军事," \
"count(case when type_code in ('uamwbfqlxo7bu0warx6vkhefigkhtoz3' ,'政治') then 1 end) 政治," \
"count(case when type_code in ('lyr1hbrnmg9qzvwuzlk5fas7v628jiqx','文化') then 1 end) 文化 from test"
cur.execute(sql)
res = cur.fetchone()
print(res)
返回结果为元组:
(10, 6, 4, 4, 2)
data = [
{"name": "娱乐", "value": res[0]},
{"name": "经济", "value": res[1]},
{"name": "军事", "value": res[2]},
{"name": "政治", "value": res[3]},
{"name": "文化", "value": res[4]}
]
result = sorted(data, key=lambda x: x['value'], reverse=True)
print(result)
结果和 cur.fetchall返回的结果经过处理后,结果是一样的:
[{'name': '娱乐', 'value': 10}, {'name': '经济', 'value': 6}, {'name': '军事', 'value': 4}, {'name': '政治', 'value': 4}, {'name': '文化', 'value': 2}]
补充:今天做测试,用django.db 的connection来执行一个非常简单的查询语句:
sql_str = 'select col_1 from table_1 where criteria = 1' cursor = connection.cursor() cursor.execute(sql_str) fetchall = cursor.fetchall()
fetchall的值是这样的:
(('101',), ('102',), ('103',),('104',))
上网搜索了一下资料:
首先fetchone()函数它的返回值是单个的元组,也就是一行记录,如果没有结果,那就会返回null
其次是fetchall()函数,它的返回值是多个元组,即返回多个行记录,如果没有结果,返回的是()
举个例子:cursor是我们连接数据库的实例
fetchone()的使用:
cursor.execute(select username,password,nickname from user where id='%s' %(input)
result=cursor.fetchone(); 此时我们可以通过result[0],result[1],result[2]得到username,password,nickname
fetchall()的使用:
cursor.execute(select * from user)
result=cursor.fetchall();此时select得到的可能是多行记录,那么我们通过fetchall得到的就是多行记录,是一个二维元组
((username1,password1,nickname1),(username2,password2,nickname2),(username3,password3,nickname))
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
python 爬虫基本使用——统计杭电oj题目正确率并排序
python爬虫主要用两个库:Urllib和BeautifulSoup4.一个用来爬取网页,一个用来解析网页. Urllib是Python内置的HTTP请求库,它包含四个模块: 1.request,最基本的 HTTP 请求模块,用来模拟发送请求,就像在浏览器里输入网址然后敲击回车一样,只需要给库方法传入 URL 与额外的参数,就可以模拟这个过程. 2.error ,异常处理模块,如果出现请求错误,我们可以捕获这些异常,然后进行重试或其他操作保证程序不会意外终止. 3.parse ,工具模块,提供
-
利用python汇总统计多张Excel
为什么越来越多的非程序员白领都开始学习 Python ?他们可能并不是想要学习 Python 去爬取一些网站从而获得酷酷的成就感,而是工作中遇到好多数据分析处理的问题,用 Python 就可以简单高效地解决.本文就通过一个实际的例子来给大家展示一下 Python 是如何应用于实际工作中高效解决复杂问题的. 背景 小明就职于一家户外运动专营公司,他们公司旗下有好多个品牌,并且涉及到很多细分的行业.小明在这家公司任数据分析师,平时都是通过 Excel 来做数据分析的.今天老板丢给他一个任务:下班前筛
-
python统计mysql数据量变化并调用接口告警的示例代码
统计每天的数据量变化,数据量变动超过一定范围时,进行告警.告警通过把对应的参数传递至相应接口. python程序如下 #!/usr/bin/python # coding=utf-8 import pymysql as mdb import os import sys import requests import json tar_conn = mdb.connect(host='192.168.56.128',port=3306,user='xxx',passwd='xxx123',db='b
-
Python代码覆盖率统计工具coverage.py用法详解
1.安装coverage pip install coverage 安装完成后,会在Python环境下的\Scripts下看到coverage.exe: 2.Coverage 命令行 coverage run 运行一个.py的文件方式:python test.py 现在使用coverage执行.py的文件方式:coverage run test.py 会自动生成一个覆盖率统计结果文件(data file):.coverage,这个文件在你的test.py的文件对应目录下. coverage re
-

Python 统计列表中重复元素的个数并返回其索引值的实现方法
需求:统计列表list1中元素3的个数,并返回每个元素的索引 list1 = [3, 3, 8, 9, 2, 10, 6, 2, 8, 3, 4, 5, 5, 4, 1, 5, 9, 7, 10, 2] 在实际工程中,可能会遇到以上需求,统计元素个数使用list.count()方法即可,不做多余说明 返回每个元素的索引需要做一些转换,简单整理了几个实现方法 1 list.index()方法 list.index()方法返回列表中首个元素的索引,当有重复元素时,可以通过更改index()方法__s
-
用python实现监控视频人数统计
一.图示 客户端请求输入一段视频或者一个视频流,输出人数或其他目标数量,上报给上层服务器端,即提供一个http API调用算法统计出人数,最终http上报总人数 二.准备 相关技术 python pytorch opencv http协议 post请求 Flask Flask是一个Python实现web开发的微框架,对于像我对web框架不熟悉的人来说还是比较容易上手的. Flask安装 sudo pip install Flask 三.一个简单服务器应用 为了稍微了解一下flask是如何使用的,
-
Python统计列表元素出现次数的方法示例
1. 引言 在使用Python的时候,通常会出现如下场景: array = [1, 2, 3, 3, 2, 1, 0, 2] 获取array中元素的出现次数 比如,上述列表中:0出现了1次,1出现了2次,2出现了3次,3出现了2次. 本文阐述了Python获取元素出现次数的几种方法.点击获取完整代码. 2. 方法 获取元素出现次数的方法较多,这里我提出如下5个方法,谨供参考.下面的代码,传入的参数均为 array = [1, 2, 3, 3, 2, 1, 0, 2] 2.1 Counter方法
-
Python统计可散列的对象之容器Counter详解
一.初始化Counter Counter支持3种形式的初始化,比如提供一个数组,一个字典,或单独键值对"="式赋值.具体初始化的代码如下所示: import collections a = collections.Counter(['a', 'a', 'b', 'b', 'b', 'c']) b = collections.Counter({"a": 2, "b": 3, "c": 1}) c = collections.Co
-
使用Python 统计文件夹内所有pdf页数的小工具
1.首先安装 PyPDF2 库: pip install PyPDF2 2.然后保存下面文件(已带注释,具体实现请自己思考) import os import PyPDF2 #获取文件夹内所有pdf文件,以及打印文件数量 def GetFileInfo(path, fileType=()): fileList = [] # root 表示当前正在访问的文件夹路径 # dirs 是 list , 表示该文件夹中所有的目录的名字(不包括子目录) # files 是 list , 表示内容是该文件夹中
-
python自动统计zabbix系统监控覆盖率的示例代码
脚本主要功能: 1)通过zabbix api接口采集所有监控主机ip地址: 2)通过cmdb系统(蓝鲸)接口采集所有生产主机IP地址.主机名.操作系统.电源状态: 3)以上2步返回数据对比,找出未监控主机ip地址,生成csv文件: 4)发送邮件. 脚本如下: #!/usr/bin/python #coding:utf-8 import requests import json import re import time import csv from collections import Cou
-
Python jieba 中文分词与词频统计的操作
我就废话不多说了,大家还是直接看代码吧~ #! python3 # -*- coding: utf-8 -*- import os, codecs import jieba from collections import Counter def get_words(txt): seg_list = jieba.cut(txt) c = Counter() for x in seg_list: if len(x)>1 and x != '\r\n': c[x] += 1 print('常用词频度统
-
python 统计代码耗时的几种方法分享
时间戳相减 在代码执行前后各记录一个时间点,两个时间戳相减即程序运行耗时. 获取时间戳time.time() import time start_time = time.time() sum = 0 for i in range(100000000): sum += i print(sum) end_time = time.time() print("耗时: {:.2f}秒".format(end_time - start_time)) 输出: 4999999950000000
-
Python实战之单词打卡统计
前言 观前提醒:因为是代码控制统计,所以操作每一个步骤都很重要,否则就会报错. 操作步骤 1.将在线编辑文档导入本地. 为了方便代码处理,将导出的excel表统一放在D盘直路径下,如果没懂,你可以查看文件属性,文件属性应该是这样: 2.打开excel表,将你要统计的那天的日期改为中文(这一步很重要,因为数字索引无法进行定位,所以要改,不改就用不了) 3.因为QQ的安全防范机制做的太好了,爬虫和抓包工具都无法获取QQ信息,所以我只能采用最原始的方法进行数据获取. 你想的没错,就是复制粘贴.用电脑打
-
python统计RGB图片某像素的个数案例
1.对于RGB三通道图片,直接用两层for循环的话,效率比较低 2.可以先将RGB图片转为灰度图片,再利用numpy.where的广播机制统计像素个数.这里有一个前提是提前知道与灰度图片的像素值相对应RGB颜色. 代码如下: from PIL import Image import numpy as np import cv2 img_L = np.array(Image.open('test.png').convert("L")) img_RGB = np.array(Image.o
-
利用Python3实现统计大量单词中各字母出现的次数和频率的方法
首先以只读方式打开单词文件,利用列表推导式创建两个列表 列表sta记录各单词出现的次数,列表freq记录各单词出现的频率 f = open('5500词.txt','r',encoding='utf-8') sta = [0 for i in range(26)] freq = [0 for i in range(26)] 单词格式如下所示: a [ei] art.一(个):每一(个):(同类事物中)任一个 abandon [ə'bændən] vt.离弃,丢弃:遗弃,抛弃:放弃 abdomen
-
Python 统计数据集标签的类别及数目操作
看了大神统计voc数据集标签框后,针对自己标注数据集,灵活应用 ,感谢! 看代码吧~ import re import os import xml.etree.ElementTree as ET class1 = 'answer' class2 = 'hand' class3 = 'write' class4 = 'music' class5 = 'phone' '''class6 = 'bus' class7 = 'car' class8 = 'cat' class9 = 'chair' cl
-
python 统计list中各个元素出现的次数的几种方法
利用字典dict来完成统计 举例: a = [1, 2, 3, 1, 1, 2] dict = {} for key in a: dict[key] = dict.get(key, 0) + 1 print dict 输出结果: >>>{1: 3, 2: 2, 3: 1} 利用Python的collection包下Counter的类 举例: from collections import Counter a = [1, 2, 3, 1, 1, 2] result = Counter(a)
-
python调用百度AI接口实现人流量统计
百度AI接口的调用方法不必多介绍. 官网地址 人流量统计 新建AipBodyAnalysis from aip import AipBodyAnalysis """ 你的 APPID AK SK """ APP_ID = '你的 App ID' API_KEY = '你的 Api Key' SECRET_KEY = '你的 Secret Key' client = AipBodyAnalysis(APP_ID, API_KEY, SECRET_K